
zx说了吗?一个基于文本库的文本对比程序
数据来源:
代码获取见文章最后 存在识别过于灵敏问题,即便是几个字有可能会被判定为数据库里面的,后面再改
思路来源
相信不少人在写论文的时候遇到过一个问题,我们主席说过的话必须标注出来,一篇文章几万个字,那些是引用那这不是,简直是大海捞针,于是就有了这个主席说过识别系统。
功能
导入word文档:必须是最新的.docx格式否者无效
系统会自动进行分句并识别,自动导出一个基于源文档的说明文档,其中包含讲话和会议或者讲话的标题
原文档——结果文档对比
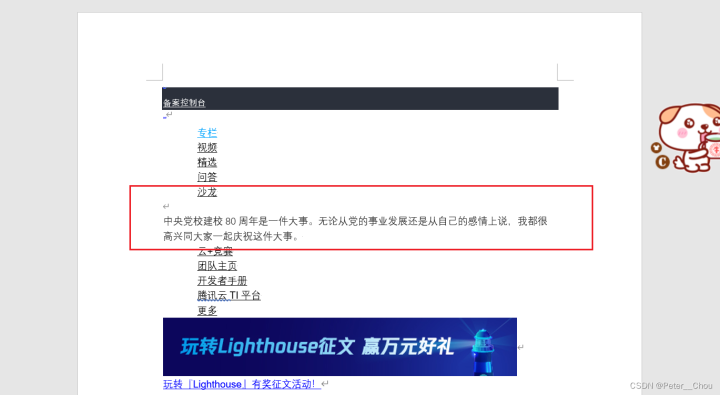
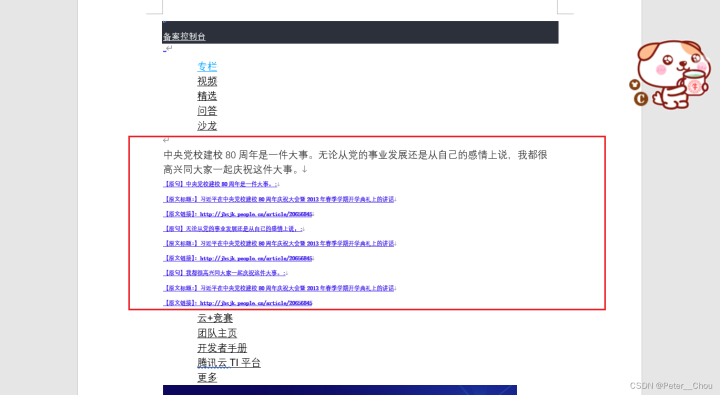
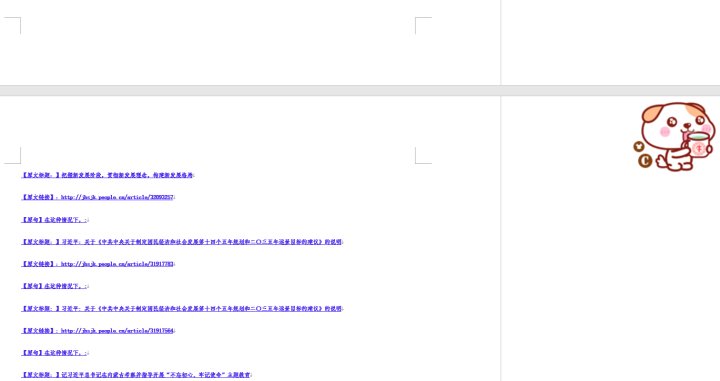
实战

实现方法
爬虫和数据获取部分省略
1.用到的库
json用于读取数据
re用于匹配数据
python-docx用于修改文档添加批注
2.函数功能说明:
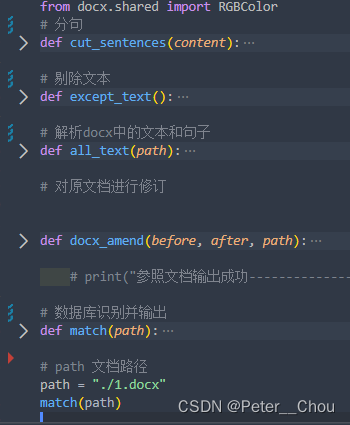
全部代码
全部代码点击展开🤷♂️打包文件获取方 https://www.123pan.com/s/UqzA-0kdr3 提取码 私聊回复
#!/usr/bin/python
# -*- coding: utf-8 -*-
'''
@File : index.py
@Time : 2022/04/27 21:06:59
@Author : chou
@Contact : chou2079986882@gmail.com
@Version : 0.1
@Desc : None
'''
import json
import re
# 用于文档处理
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
# from docx.enum.style import WD_STYLE_TYPE
def cut_sentences(content):
# 分句
# end_flag = ['?', ',', '!', '.', '?', '!', '。', '…', "\n"]
end_flag = ['?', '!', '.', '?', '!', '。', '…', "\n", ":", ","]
content_len = len(content)
sentences = []
tmp_char = ''
for idx, char in enumerate(content):
# 拼接字符
tmp_char += char
# 判断是否已经到了最后一位
if (idx + 1) == content_len:
sentences.append(tmp_char)
break
# 判断此字符是否为结束符号
if char in end_flag:
# 再判断下一个字符是否为结束符号,如果不是结束符号,则切分句子
next_idx = idx + 1
if not content[next_idx] in end_flag:
sentences.append(tmp_char)
tmp_char = ''
return sentences
# print(cut_sentences(test_text))
def except_text():
ls = []
with open("./except.txt", "r", encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
ls.append(line.strip("\n"))
# print(ls)
return ls
# except_text()
def all_text(path):
# 获取文档内容别分句
doc = Document(path)
all_text = ""
for p in doc.paragraphs:
all_text += str(p.text).strip("\n")
# print(all_text)
print("文档读取成功——————")
sentence = cut_sentences(all_text)
print("分句成功——————")
# print(sentence)
return sentence
# 对原文档进行修订
def docx_amend(before, after, path):
global tag
tag = 0
if tag == 0:
doc = Document(path)
for i, p in enumerate(doc.paragraphs): # 遍历所有的段落
if before in p.text:
# before是某一句
p.runs[-1].add_break() # 添加一个折行
# after需要修改的内容
run = p.add_run(after)
run.bold = True
font = run.font
font.name = '宋体'
font.underline = True
font.size = Pt(6)
font.color.rgb = RGBColor(0x42, 0x24, 0xE9)
# p.add_run('测试')
doc.save(path)
tag += 1
doc = Document(path)
else:
doc = Document(path)
for i, p in enumerate(doc.paragraphs): # 遍历所有的段落
if before in p.text:
p.runs[-1].add_break() # 添加一个折行
# after需要修改的内容
run = p.add_run(after)
run.bold = True
font = run.font
font.name = '宋体'
font.underline = True
font.size = Pt(6)
font.color.rgb = RGBColor(0x42, 0x24, 0xE9)
# p.add_run('测试')
doc.save(path)
tag += 1
# print("参照文档输出成功--------------")
# all_text()
def match(path):
most_sort = 6 # 默认最小识别句子必须有6个字
all_sentences = all_text(path)
# test_text = "基础设施是经济社会发展的重要支撑,要统筹发展和安全"
with open("./data.json", "r", encoding="utf-8") as f:
data = json.load(f)
# 剔除部分句子
exc = except_text()
# 循环检测所有文本t
for test_text in all_sentences:
if test_text in exc:
continue
elif len(test_text) <= most_sort:
# 四个字一下判定不是句子
continue
else:
text = data["正文"]
title = data["标题"]
link = data["标题链接"]
source = data["来源"]
key = [] # 匹配到的句子编号
# text、title、link是字典类型,键是数据序号
for k_t, v_t in text.items():
if test_text in v_t:
key.append(k_t)
print("数据库匹配中————————")
for i in key:
# 每一个i对应一句主席语录
print(
f"【原句】{test_text}:\n【原文标题:】{title[i]}\n【来源时间信息:】{source[i]}")
print(f"【原文链接】:{link[i]}")
print("\n")
before = test_text
after = f"【原句】{test_text}:\n【原文标题:】{title[i]}\n【原文链接】:{link[i]}"
docx_amend(before=before, after=after, path=path)
print("参照文档输出成功--------------")
# path 文档路径
path = "./1.docx"
match(path)

无事生非

 浙公网安备 33010602011771号
浙公网安备 33010602011771号