
从数据类型上理解深浅拷贝
拷贝不能脱离数据类型来谈
数据类型
除ES6引入的Symbol和BigInt数据类型,JS数据可大致分为:基本数据类型(String、 Number、Boolean、Null、Undefined)和引用数据类型(统称为Object,包括Array、Function...)。
-
基本数据类型的特点:直接存储在栈(stack)中的数据。
- 引用数据类型的特点:存储的是该对象在栈中引用,真实的数据存放在堆内存里。
引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
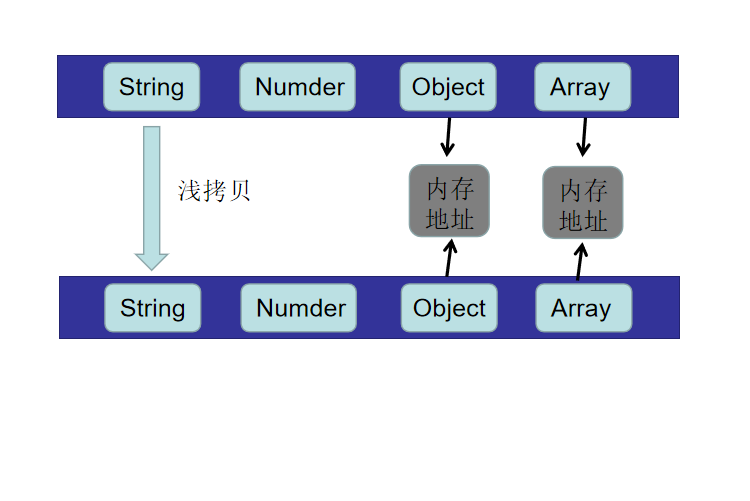
浅拷贝
这里有两个注意点:
- 引用数据类型:对象,数组,函数等,这些拷贝的是地址。
- 基本数据类型:数字,字符串,布尔值这些是拷贝值。
赋值是浅拷贝
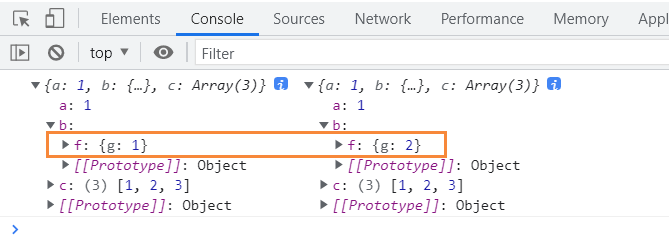
比如我们定义一个变量为 obj1 的对象,然后我们把他赋值给另一个变量obj2,这个过程就会涉及到浅拷贝问题,另一个变量只是之前变量的一份拷贝,前后两个变量的存储地址是公用的。改变obj2的属性值,obj1的属性值也会发生改变。你可以这么认为,赋值实际上是将地址绑定在一起。
var obj1 = { a: 1, b: { f: { g: 1 } }, c: [1, 2, 3] }; let obj2 = obj1; obj2.b.f.g = 2; console.log(obj1, obj2);
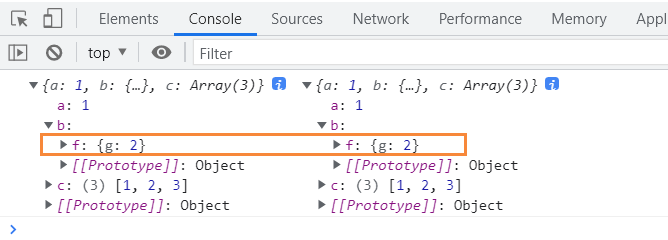
这里得注意一下,Array类提供的API:concat、slice是返回一个浅拷贝。这两个方法都会返回一个新数组,所以一开始误以为这是属于深拷贝的,其实不然。MDN中关于它们的描述非常清楚:这两个方法不会改变 this 或任何作为参数提供的数组,而是返回一个浅拷贝,它包含与原始数组相结合的相同元素的副本。
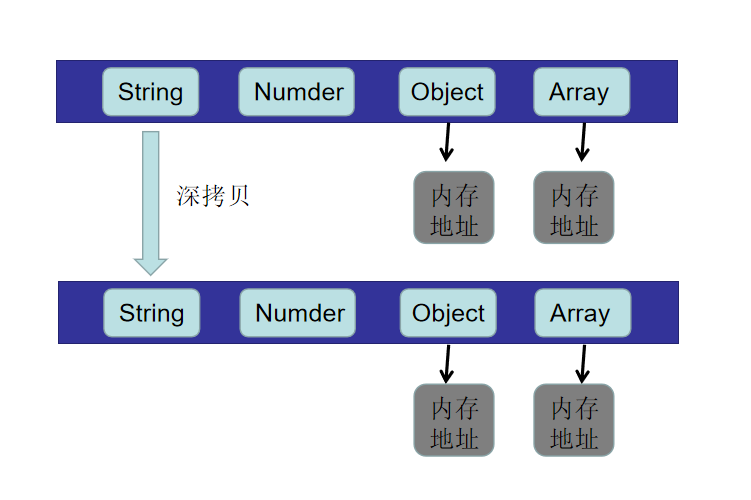
深拷贝
深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象。
JSON.parse(JSON.stringify())
var obj1 = { a: 1, b: { f: { g: 1 } }, c: [1, 2, 3] }; let obj2 = JSON.parse(JSON.stringify(obj1)); obj2.b.f.g = 2; console.log(obj1, obj2);
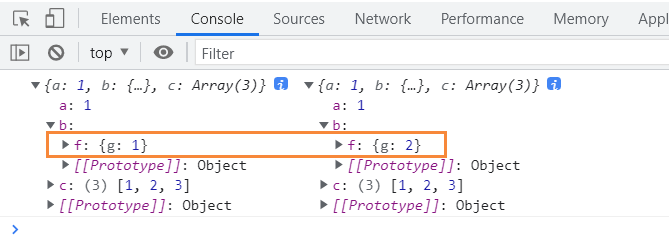
原理: 用JSON.stringify将对象转成JSON字符串,再用JSON.parse()把字符串解析成对象,一去一来,新的对象产生了,而且对象会开辟新的栈,实现深拷贝。
这种方法虽然可以实现数组或对象深拷贝,但不能处理函数。因为JSON.stringify() 方法是将一个JavaScript值(对象或者数组)转换为一个 JSON字符串,不能接受函数。
函数库lodash
该函数库也有提供_.cloneDeep用来做 Deep Copy。
require('lodash') 是nodejs里面的写法,在HTML中引用应该使用<script src=''lodash.js''>标签引入。
var _ = require('lodash'); var obj1 = { a: 1, b: { f: { g: 1 } }, c: [1, 2, 3] }; var obj2 = _.cloneDeep(obj1); obj2.b.f.g = 2; console.log(obj1, obj2);
除此之外,还有一种方法就是手写递归
通过遍历对象、数组不断进行拷贝,直到里边都是基本数据类型。
具体代码及分析过程,请看我后续写的 '理解并手写深拷贝函数'
本文来自博客园,作者:辉太狼`,转载请注明原文链接:https://www.cnblogs.com/HuiTaiLang1216/p/15354967.html
