

消息中间件学习八--SpringBoot整合redis
1.SpringBoot整合redis:
第一步:引入依赖jar
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>27.0.1-jre</version> </dependency>
<!--json工具-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.9.8</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.8</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.8</version>
</dependency>
第二步:配置application.properties
# Redis数据库索引(默认为0)redis一共有16个库 这儿使用0号库 spring.redis.database=0 # Redis服务器地址 写你的ip spring.redis.host=192.168.1.154 # Redis服务器连接端口 spring.redis.port=6379 # Redis服务器连接密码(默认为空) spring.redis.password= # 连接池最大连接数(使用负值表示没有限制 类似于mysql的连接池 spring.redis.jedis.pool.max-active=200 # 连接池最大阻塞等待时间(使用负值表示没有限制) 表示连接池的链接拿完了 现在去申请需要等待的时间 spring.redis.jedis.pool.max-wait=-1 # 连接池中的最大空闲连接 spring.redis.jedis.pool.max-idle=10 # 连接池中的最小空闲连接 spring.redis.jedis.pool.min-idle=0 # 连接超时时间(毫秒) 去链接redis服务端 spring.redis.timeout=6000 #druid spring.druid.url=jdbc:mysql://192.168.1.154:3306/redis?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT spring.druid.driverClassName=com.mysql.cj.jdbc.Driver spring.druid.username=root spring.druid.password=root #最大链接数 spring.druid.maxActive=30 #最小链接数 spring.druid.minIdle=5 #获得链接的最大等待时间 spring.druid.maxWait=10000 #指定mybatis配置文件地址 mybatis.config-location=classpath:mybatis/mybatis-config.xml
第三步:创建redis配置类(config.java)
package com.xmcc.redis01.config; @Configuration//表示该类为配置类 public class RedisConfig { /** * 新建restTemplate交给spring容器管理 * 注意: * springboot其实已经自动注入了RedisTemplate, * 但是泛型是RedisTemplate<Object,Object>,而且没有指定序列化的方式 * 而我们需要key都是string类型的 ,避免频繁类型转换,所以重写 * 当手动去注入一个RedisTemplate后 springboot将不会自动注入 *RedisConnectionFactory:springboot自动读取配置文件然后注入 */ @Bean public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory factory){ RedisTemplate<String, Object> template = new RedisTemplate<>(); //设置连接工厂,工厂用于创建连接 template.setConnectionFactory(factory); //设置自定义序列化方式 setSerializeConfig(template,factory ); return template; } /** * 为什么要序列化? *序列化能加快网络传输,而且redis的value都是字符串, * 我们希望value放入任意的数据,就需要手动去序列化为字符串,这儿直接配置了, * 以后传入任意value的时候,就会自动序列化 * * 大家如果不能理解下面的配置,只需要记住是为了以后设置任意值的时候方便就可以了,以后再说 * 比如:我们现在想保存一个student对象到redis,但是redis只能存字符串,那么我们需要把对象通过json工具类转换为字符串 * 再去存入,写了这个就不需要转了,传入student对象,内部自动帮助我们转换为字符串 */ private void setSerializeConfig(RedisTemplate<String, Object> redisTemplate, RedisConnectionFactory redisConnectionFactory) { //设置链接工厂 redisTemplate.setConnectionFactory(redisConnectionFactory); //对字符串采取普通的序列化方式 适用于key 因为我们一般采取简单字符串作为key StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); //普通的string类型的key采用 普通序列化方式 redisTemplate.setKeySerializer(stringRedisSerializer); //普通hash类型的key也使用 普通序列化方式 redisTemplate.setHashKeySerializer(stringRedisSerializer); //解决查询缓存转换异常的问题 大家不能理解就直接用就可以了 这是springboot自带的jackson序列化类,但是会有一定问题 Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper om = new ObjectMapper(); om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(om); //普通的值采用jackson方式自动序列化 redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); //hash类型的值也采用jackson方式序列化 redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer); //属性设置完成afterPropertiesSet就会被调用,可以对设置不成功的做一些默认处理 redisTemplate.afterPropertiesSet(); } }
第四步:redis工具类(针对value为string类型)
package com.xmcc.redis01.util; import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.stereotype.Component; import org.springframework.util.CollectionUtils; import java.util.concurrent.TimeUnit; @Component @Slf4j public class RedisUtils { @Autowired private RedisTemplate<String,Object> redisTemplate; public Object get(String key){ return key==null?null:redisTemplate.opsForValue().get(key ); } public boolean set(String key,Object value){ try { redisTemplate.opsForValue().set(key, value); return true; }catch (Exception e){ log.error("redis set value exception:{}",e ); return false; } } public boolean setex(String key,Object value,long expire){ try { redisTemplate.opsForValue().set(key,value ,expire , TimeUnit.SECONDS ); return true; }catch (Exception e){ return false; } } public boolean expire(String key,long expire){ try{//这儿没有ops什么的是因为每种数据类型都能设置过期时间 redisTemplate.expire(key,expire,TimeUnit.SECONDS); return true; }catch (Exception e){ log.error("redis set key expire exception:{}",e); return false; } } /** * * @param key * @return 获取key的过期时间 */ public long ttl(String key){ return redisTemplate.getExpire(key); } /** * * @param keys 删除key 可变参数 */ public void del(String ...keys){ if(keys!=null&&keys.length>0) { redisTemplate.delete(CollectionUtils.arrayToList(keys)); } } /** * * @param key * @param step 传入正数 就是加多少 传入负数就是减多少 * @return */ public long incrBy(String key,long step){ return redisTemplate.opsForValue().increment(key,step); } /** * * @param key * @param value * @return 如果该key存在就返回false 设置不成功 key不存在就返回ture设置成功 */ public boolean setnx(String key,Object value){ return redisTemplate.opsForValue().setIfAbsent(key,value); } /** * 原子操作 * @param key * @param value * @param expire 在上面方法加上过期时间设置 * @return */ public boolean setnxAndExpire(String key,Object value,long expire){ return redisTemplate.opsForValue().setIfAbsent(key,value,expire,TimeUnit.SECONDS); } /** * * @param key * @param value * @return 如果该key存在就返回之前的value 不存在就返回null */ public Object getAndSet(String key,Object value){ return redisTemplate.opsForValue().getAndSet(key,value); } /** * * @param key * @return 判断key是否存在 */ public boolean hasKey(String key){ return redisTemplate.hasKey(key); } }
第五步:redis的使用
在需要redis的地方,将redisutil注入,调用对应的方法即可。
2.redis进阶问题
redis键过期处理机制
1.定期删除+惰性删除是如何工作的呢? 定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。
需要说明的是,redis不是每个100ms将所有的key检查一次,
而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。
因此,如果只采用定期删除策略,会导致很多key到时间没有删除。 于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,
这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。 --》采用定期删除+惰性删除就没其他问题了么? 不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。
这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
2.内存淘汰机制 **在redis.conf中有一行配置 maxmemory-policy volatile-lru 该配置就是配内存淘汰策略的** 1)noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。 2)allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,大部分情况适用。 3)allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。 4)volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐 5)volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐 6)volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。 不推荐 常见选择: allkeys-lru:如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),
或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择allkeys-lru策略。 allkeys-random:如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。 volatile-ttl:这种策略使得我们可以向Redis提示哪些key更适合被移除
3.为什么不用定时删除策略? 定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。
在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
redis持久化
1 RDB Redis持久化方案: 1.RDB(默认的持久化方案:推荐使用的)Redis DataBase 生成快照文件xxx.rdb保存到磁盘 1)自动执行 a)需要查看配置文件 i.save 900 1 ii.save 300 10 iii.save 60 10000 满足三个条件中一个触发生成快照rdb文件 b)启动服务器的时候,需要通过命令行启动 i.进入reids的安装目录 ii.Redis-server.exe redis.windows.conf 2)save命令 3)bgsave命令 其它配置(了解) stop-writes-on-bgsave-error yes 后台备份进程出错时,主进程停不停止写入? rdbcompression yes 导出的rdb文件是否压缩 Rdbchecksum yes 导入rbd恢复时数据时,要不要检验rdb的完整性 dbfilename dump.rdb 生成的rdb文件名 dir ./ rdb文件的放置路径 save “” 在那三个save下面加save “”表示禁用rdb
2.AOF AOF是AppendOnly File的缩写,是Redis系统提供了一种记录Redis操作的持久化方案,
在AOF生成的文件中,将真实记录发生在Redis上的操作,从而达到在Redis服务器重启或者当机之后,
继续恢复之前数据状态的机制。 1)打开AOF redis.conf中的appendonly yes就可以打开AOF功能 appendfsync no: 当设置appendfsync为no的时候,Redis不会主动调用fsync去将AOF日志内容同步到磁盘,
所以这一切就完全依赖于操作系统的调试了。对大多数Linux操作系统,是每30秒进行一次fsync,
将缓冲区中的数据写到磁盘上。 appendfsync everysec 当设置appendfsync为everysec的时候,Redis会默认每隔一秒进行一次fsync调用,
将缓冲区中的数据写到磁盘。但是当这一次的fsync调用时长超过1秒时。
Redis会采取延迟fsync的策略,再等一秒钟。也就是在两秒后再进行fsync,
这一次的fsync就不管会执行多 长时间都会进行。
这时候由于在fsync时文件描述符会被阻塞,
所以当前的写操作就会阻塞。
结论就是,在绝大多数情况下,Redis会每隔一秒进行一 次fsync。
在最坏的情况下,两秒钟会进行一次fsync操作。
这一操作在大多数数据库系统中被称为group commit,
就是组合多次写操作的数据,一次性将日志写到磁盘。 appendfsync always 设置appendfsync为always时,每一次写操作都会调用一次fsync,
这时数据是最安全的,当然,由于每次都会执行fsync, 所以其性能也会受到影响 2)AOF重写 因为 AOF 持久化是通过保存被执行的写命令来记录数据库状态的,
那么就会涉及到很多无用的命令,比如: set a b set a c set a d 其实就最后一条有意义 Redis会fork一个进程来读取现在redis生成的AOF文件,然后在内存中去除冗余命令, 在此过程中不会影响原来AOF文件的继续写入,如果有新的命令,会缓存在重写缓冲中,
当重写完全结束后会替换掉原来的AOF文件 重写触发条件: 1.手动命令BGREWRITEAOF 配置自动调用
3.RDB、AOF的选择 1.宕机后,会优先加载AOF文件 2.RDB保存的数据,AOF保存的命令,RDB文件比AOF小 3.恢复速度RDB小,更快 4.RDB一次写入的数据较多,时间间隔会比AOF长,出现宕机丢失的数据会更多 各有优劣,如果能综合就好了,所幸的是在redis4.0后,通过下面配置 aof-use-rdb-preamble就可以开启两者混合持久化,取长补短
redis、mysql双写一致性
解决方案: ** 先更新数据库,再删缓存,同时,利用消息队列,防止删缓存失败导致的脏数据**。步骤如下: (1)更新数据库数据 (2)数据库会将操作信息写入binlog日志当中 (3)订阅程序提取出所需要的数据以及key (4)另起一段非业务代码,获得该信息 (5)尝试删除缓存操作,发现删除失败 (6)将这些信息发送至消息队列 (7)重新从消息队列中获得该数据,重试操作。 可参考:https://blog.csdn.net/hjm4702192/article/details/80518922
缓存相关术语
1.缓存雪崩 缓存雪崩我们可以简单的理解为:由于原有缓存失效,新缓存未到期间
(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),
所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,
严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
解决办法: 1、并发量较小时,在从数据库获取数据的时候加锁排队 2、高并发时,给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。 3.由于redis过期时间设置得比较统一,导致缓存大面积过期 这个就对缓存失效时间进行考虑,比如多少秒加个随机数等,避免大面积失效就可以了
2.redis缓存穿透 redis在项目中是作为缓存使用,核心目的降低后台压力,增加响应速度。
更极端的说在项目中设计redis的的初衷就是用来抗并发压力的,
举例说明 比如:现在项目有100万并发量的可能,那么从成本考虑,会让mysql承担5万并发量,
redis来承担剩下的95万并发。大家结合之前练习中想象一下缓存步骤: 1.查询数据先从缓存中获取,获取为null; 2.进入mysql查询,然后再缓存起来 假如第二步在mysql中也没查询到呢,也就是查询到为null值,那么缓存的就是null值,下次再来查询依然得去数据库查询,
如果超过5万个请求都是这样的情况,那么凉了,直接击垮mysql服务器,或者响应效率低,用户的查询请求直接打到mysql服务器。 ** 解决方案:** 一、如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),
我们仍然把这个空结果(value值使用自定义默认值代替)进行缓存,
但它的过期时间会很短,最长不超过五分钟。通过这个直接设置的默认值存放到缓存,
这样第二次到缓存中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴! 二、降级: 当系统承受不住外界的压力,可以通过限流的方式,保证核心业务的运行 当系统承受不住外界的压力,可以通过关闭非核心服务的方式,保证核心业务的运行 三、布隆过滤器 将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,
从而避免了对底层存储系统的查询压力。
3.缓存预热 缓存预热就是系统上线后,提前将相关的缓存数据直接加载到缓存系统。
避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!
用户直接查询事先被预热的缓存数据! 缓存预热解决方案: (1)直接写个缓存刷新页面,上线时手工操作下; (2)数据量不大,可以在项目启动的时候自动进行加载; (3)定时刷新缓存;
redis布隆过滤器
首先布隆过滤器是一种数据结构,类似于set、hash表等-->是完成在海量数据来判断某个值一定不存在,或者判断很大可能存在 安装使用 插件在github上面有现成的,所以我们需要在linux先安装git,按命令做就行了,不需要记 yum -y install git useradd -m -d /home/git -s /usr/bin/git-shell git mkdir -p /data/git cd /data/git git init --bare project1.git chown git.git project1.git –R cd /home/git mkdir .ssh chmod 700 .ssh touch .ssh/authorized_keys chmod 600 .ssh/authorized_keys chown git.git .ssh –R 安装bloom filter: cd /usr/local git clone git://github.com/RedisLabsModules/rebloom cd rebloom make 然后再redis的redis.conf配置文件中添加 loadmodule /usr/local/rebloom/rebloom.so
如何从海量数据查询某一个前缀的key
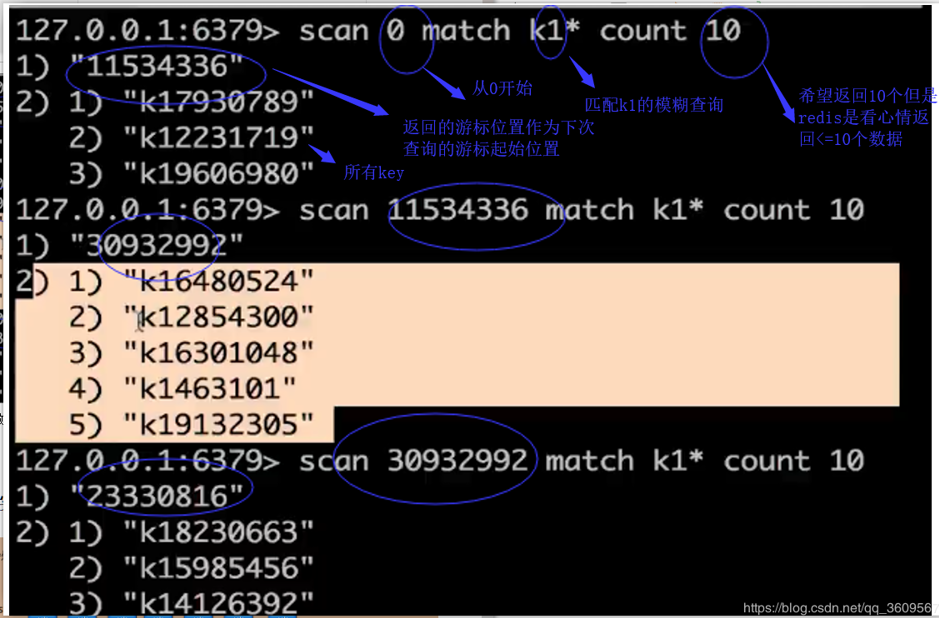
keys 正则表达式:会返回所有匹配的key 但是数据量过大的情况下会造成服务卡顿、阻塞服务器,海量数据不能使用 可以用scan命令来代替keys* 命令: SCAN cursor [MATCH pattern] [COUNT count] 当游标数据返回0,则表示遍历结束
redis的主从、读写
与mysql相同,redis也提供了主从的功能,更加非常简单。Mysql的一主多从不能达到主高可用,
只能提高并发,高可用需要mysql集群,redis的主从通过哨兵机制可以达到高可用
高并发:单位时间类,可以接收的请求数量 高可用:mysql服务器的质量
场景:
1.在生产中难以避免单台redis出现故障,保证高可用可以用主从 2.单台redis官网说能抗住10w并发量,超过了10w,高并发,就可以主从
3.QPS瓶颈 Qps:每秒处理的查询次数 TPS:每秒处理的事务数(从请求到获得数据,称为一个完整事务过程) 大家记住第一个单词,Q就是query缩写,T就是transaction缩写
3.注意 1.一个master可以有多个slave 2.一个slave只能有一个master 3.数据流向是单向的,master到slave
redis的哨兵机制
概述:
前面学习了redis的读写分离,主从复制, 读写分离,利用从节点来减轻主节点的压力。
但是如果主节点因为一些原因,发生故障宕机,那么写操作就无法完成。
这个时候可以考虑集群方式来保证主节点的高可用,
也可以在很多从节点中选择一个来作为新的主节点(故障迁移)。
redis就提供了哨兵机制(sentinel),来自动完成故障迁移,
就是就是当主节点发生故障时,自动在从节点中选取一个作为主节点。
哨兵最好为奇数个:找到哨兵的配置文件(注意:哨兵跟redis是独立的,这儿只是在一台机器上配置)
哨兵(sentinel)的三个定时任务
1.每10秒每个sentinel对master与slave节点执行info,
通过info能发现master的slave节点确定主从关系
2.每2秒各个sentinel会交换对节点的看法以及sentinel自身的信息 原理:在master中会有一个频道 _sentinel:hello 每个sentinel都订阅了该频道,就会通过该频道发送对节点的
看法以及sentinel自身的信息,也能搜到其他sentinel发送的信息
3.每一秒sentinel对其他sentinel以及主从中所有节点发送ping,
心跳检测,作为正常或者宕机的判断依据
主客观下线
主观下线:第二句配置的30000,表示sentinel在每秒的定时任务发送ping以后,
30秒都没有回复,那么sentinel就会认为该节点失败,这是它一个人的看法,所以叫主观下线 客观下线:在第一行配置的2,表示所有sentinel中有2个都认为该redis节点失败(主观下线),
那么就认为真的失败了,就可以继续后续操作了 原理就是发送sentinel is-master-down-by-addr(地址)
到_sentinel:hello,其它订阅的就可以获得信息
领导的选举 目的:只需要一个sentinel完成故障转移就够了 上面的sentinel is-master-down-by-addr(地址)还有一个作用,
就是sentinel节点告诉其它sentinel我要当领导。 规则: 1.每个做主观下线的sentinel发送命令到其它sentinel告知master节点信息,
以及要求其它sentinel设置发送该命令的sentinel成为领导 2.每个sentinel只会统一收到第一个命令的发送者成为领导,投一票 3.如果有一个sentinel发现自己的票数超过sentinel集合
半数并且超过了之前配置中的2,那么就会成为领导 4.该算法可能会有多个sentinel被选为领导,
这个时候就会过一段时间从新选举
故障的转移 1.sentinel会在slave中选取一个来做为新的master 选择依据:(了解) 1.会查看slave中是否配置的优先级slave-priority,
选择优先级高的(运维人员可以根据机器的配置高低去配置优先级) 2. 如果都没有配置那么就是相同的,会选择偏移量最大的slave节点(了解即可) 3.选择runid最小的(就是redis运行的id,相当于一个标识符)
2.选择了新的master,sentinel就会对剩下的slave发送命令,
去复制新的master,复制规则,如图,下面就是表示一个一个来 3.sentinel还会继续监控挂掉的master,
如果master复活了,会命令master去从属于新选举的master
redis为什么是单线程?
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽。
(以上主要来自官方FAQ)既然单线程容易实现,而且CPU不会成为瓶颈,
那就顺理成章地采用单线程的方案了。
redis与mysql
在使用mysql的时候,可以手动新建数据库,来分类存储不同的业务数据,
同样的redis默认就有0-15的16个库,默认使用0号库 切库操作: select 0……15 dbsize:查看当前库中多少个key flushall:清空当前库 也可以在配置文件配置个数:databases 16
1.为什么需要redis 先看mysql的执行流程: 1.有sql语句请求查询的时候,首先到查询缓存cache中查找,如果有立刻返回,这是速度最快查询,因为查询缓存在内存中, 2.如果缓存没有,进入查询解析器,生成解析树(了解即可) 3.查询优化器(mysql对一些sql语句进行优化,比如我们之前的join驱动表) 4.生成执行计划(explain) 5.进入存储引擎,索引是存储引擎决定的,如果索引能返回数据就不需要去表里面查询了。 6.没有找到,进入表中全表扫描 结论: 通过mysql的执行流程可以看出,如果在内存中存在数据返回,是效率最高、速度最快的。
因为mysql的核心是注重于数据的持久安全,
因此能够基于内存的数据库(nosql)应运而生,我们学习其中最流行的redis。
2 有了redis还需要mysql么? 1.在之前介绍redis时候,redis既能基于内存,也能持久化到磁盘,但是主打内存效率的redis,
持久化功能远远比不上mysql。而大量数据都放入内存,需要很高的硬件支持,不太现实 2.Mysql有完善的事务机制,能满足项目需求,redis虽然也有事务,但是很多场景无法满足 3.Redis虽然有5种数据结构,但是过于复杂的数据关系,还是无法清晰表现,
mysql通过行和列、表与表的关系,让数据与数据直接之间的关系一目了然。
所以在使用中都是redis+mysql。redis主管数据缓存到内存,
用于提高查询效率,mysql主管数据存储到磁盘,用于保存重要不能丢失的数据
redis的分布式锁
利用setex的原子操作(在分布式环境中,redis是共用的,
所以可以使用setex的成功作为获得锁的标志)
@Scheduled(cron="0 */1 * * * ?") public void cancelOrder(){ log.info("定时任务启动..................当前时间:{}",new Date()); //因为setnxAndExpire方法设置值与设置时间是原子操作,所以就可以达到分布式锁的目的 //大家如果去看到另外的版本 setnx与expire两个方法 是分开的那么就不是原子操作,这两个方法,执行期间可能会出现服务器宕机什么的造成死锁 boolean flag = redisUtils.setnxAndExpire(LOCK_KEY,String.valueOf(System.currentTimeMillis() + 50000), EXPIRE); if(flag) { try { log.info("获得分布式锁..."); 进行对应的操作 }finally { //不管时间到没到,业务做完了就可以释放锁了 释放分布式锁 redisUtils.del(LOCK_KEY); }
学习来源:https://www.jianshu.com/p/60b9e30c6cf1
[缓存相关术语](http://www.cnblogs.com/leeSmall/p/8594542.html)

