

消息中间件学习七--Redis(基础知识)
1.官网:https://www.redis.net.cn/
2.概述
1.Redis是一个开源(BSD许可),内存数据结构存储,用作数据库,缓存和消息代理
2.它支持数据结构,如字符串,散列,列表,集合,带有范围查询的排序集,
位图,超级日志,具有半径查询和流的地理空间索引
3.Redis具有内置复制,Lua脚本,LRU驱逐,事务和不同级别的磁盘持久性,
并通过Redis Sentinel和Redis Cluster自动分区
4.您可以对这些类型运行原子操作,例如附加到字符串;递增哈希值;
将元素推送到列表中;计算集合交集, 并集和差异;
或者在排序集中获得排名最高的成员
5.为了实现其出色的性能,Redis使用内存数据集。
根据您的使用情况,您可以通过 每隔一段时间将数据集转储到磁盘或
通过将每个命令附加到日志来保留它
如果您只需要功能丰富的网络内存缓存,则可以选择禁用持久性
6.Redis还支持简单到设置的主从异步复制,
具有非常快速的非阻塞第一次同步,
自动重新连接以及在网络分割上的部分重新同步。
其他功能包括:交易发布/订阅、Lua脚本、钥匙的生存时间有限、LRU逐出钥匙、自动故障转移
7.您可以使用大多数编程语言中的Redis
Redis是用ANSI C编写的,适用于大多数POSIX系统,如Linux,* BSD,OS X,
没有外部依赖性。Linux和OS X是Redis开发和测试的两个操作系统,
我们建议使用Linux进行部署。
ps:lua脚本可以将redis客户端的多个命令打包送到服务器一起执行,保证原子性
3.redis为什么这么快?
1.纯内存操作
2.单线程操作,避免了频繁的上下文切换(多线程需要占用更多的CPU资源)
3.采用了非阻塞I/O多路复用机制
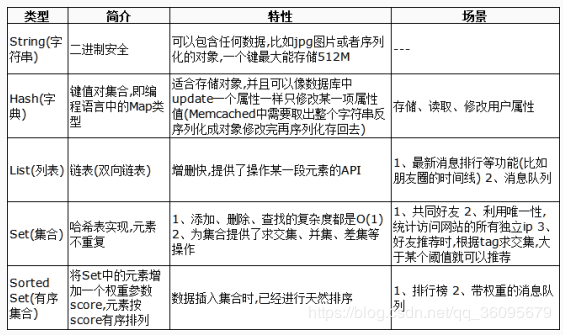
4.redis的数据结构
redis的数据结构为key---value存储,Key:是String,Value有5个数据类型
1.String: 字符串 2.Hash: 类似于map、可以放对象 3.List:linkedlist格式 支持重复的元素 4.Set:不允许重复且无序
5.Sortedset:不允许重复,且元素有顺序
5.应用场景
1.缓存数据(数据查询,商品内容……)
2.任务队列(秒杀、抢购、12306……)
3.应用排行榜、热门列表、 最新动态
4.数据过期处理
5.分布式集群架构中session的处理
6.时效性、访问频率、计数器
7.社交列表、记录用户判定信息
8.交集、并集和差集、消息队列
6.redis在Linux中的操作
启动方式:
cd /usr/local cd redis-4.0.8 cd src
1.src目录下的./redis-server,这个需要一直保持启动,
当其他操作的时候,ctrl+c退出,redis也退出了。不太方便
2.后台启动 1)到redis目录 2)vim redis.conf 将daemonize no该为yes 3)到src目录 :通过配置文件启动redis: ./redis-server ../redis.conf
3.使用redis脚本设置开机自动启动:启动脚本 redis_init_script 位于Redis的 /utils/ 目录下。
了解就可以了,我们学习使用第二种就够了
关闭:
在src目录下:
./redis -cli -p 6379 shutdown
当然也可以用kill -9 进程号
redis的指令
通用指令
keys *
查看所有key
flushall
情况数据库
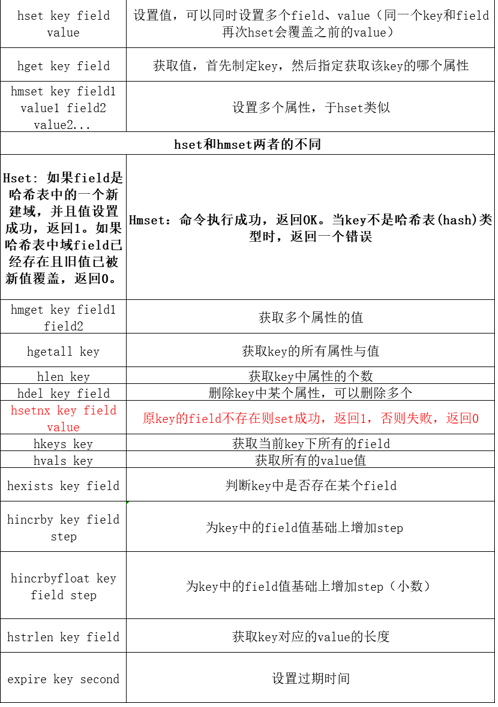
value为String类型

value为hash类型
value为list类型
lpush key value [value...] : l是left的缩写 表示从链表左边(链表头)放入数据 lrange key start end : 查看start---end中的数据,左包右包 end -1表示到最后 rpush key value [value...] :右边插入数据 r是right的缩写 lpop key : 弹出左边第一个元素 rpop key : 弹出右边第一个元素 llen key : 查看链表的总长度 blpop key [key...] timeout : 左侧阻塞式弹出 brpop key [key...] timeout : 右侧阻塞式弹出 lpushx : 和lpush类似,但是lpushx会校验key是否存在,若key不存在则不进行任何操作 rpushx : 和rpush类似,但是lpushx会校验key是否存在,若key不存在则不进行任何操作 rpoplpush key1 key2 : 弹出key1的右边的元素 放入key2左边(医院体检业务,排队做了一项,继续排队做第二项) brpoplpush : 阻塞版本 lindex key index : 获取key中index位置的值,负数就反过来数,-1为最后一个 lrem key count value :
count>0从左边删除count个value count<0从右边删除count个value count=0删除所有的value
value为set类型
sadd key element [element...] : set集合中添加元素
smembers key : 查看集合所有的元素
sismember key element : 查看元素是否属于该集合,1存在 0不存在
srem key element [element...] : 删除集合元素 |
scard key : 查看集合元素数量
srandmember key [n] :
随机获取集合中某一个元素
n是正数:返回n个不重复的数
n是负数:返回n个可能重复的数 |
spop key [n] : 默认弹出一个元素,或者弹出指定个数的元素
sinter key1 key2 : 多个集合的交集
sdiff key1 key2.... : 返回第一个集合有 后面集合都没有的元素(差集)
sunion key1 key2 key3…. : 所有集合的并集
sinterstore set set1 set2 : 找到set1与set2的交集 存放在set中
value为zset(sortedset)类型
zadd key score member1 score member2 : 添加元素 每个元素都会携带一个分数 zrange key start end [withscores] : 根据下标查看元素 默认分数升序排序 zrevrange key start end [withscores] : 类似上面,反取 zrangebyscore key score1 socre2 : 取score1到score2分数 之间的元素 zrevrangebyscore key max min [withscores] : 反取 zrem key member : 删除元素
**zcard key ** 个数 zscore key member :查看某个元素的分数 zrank key member :查看某个元素在集合中的排名,默认按分数升序(排名从0开始的) zrevrank key member : 反排名 zincrby key increment member: 为某个元素加分 **zcount key min max ** : 统计min到max分数间的个数 zremrangebyscore key min max : 根据分数段删除 zremrangebyrank key start end : 根据排名删除 zinterstore destination numkeys key [key...]:这里numkeys表示需要做交集的key的个数 zunionstore destination numkeys key [key...]:这里numkeys代表需要做并集的key的个数 |
学习来源:https://www.jianshu.com/p/60b9e30c6cf1
//Linux的五种IO模型(形象实例详解)
https://blog.csdn.net/qq_36095679/article/details/89641867
https://www.cnblogs.com/jasonZh/p/9513948.html

