
pandas排序以及获取序号
参考:https://blog.csdn.net/qq_22238533/article/details/72395564
如果不考虑序号问题,要直接排序则使用pandas sort_values函数
df.sort_values(by='排序字段',axis=0,ascending=True, inplace=False, na_position=‘last’)
参数 说明
by 指定列名(axis=0或’index’)或索引值(axis=1或’columns’)
axis 若axis=0或’index’,则按照指定列中数据大小排序;若axis=1或’columns’,则按照指定索引中数据大小排序,默认axis=0
ascending 是否按指定列的数组升序排列,默认为True,即升序排列
inplace 是否用排序后的数据集替换原来的数据,默认为False,即不替换
na_position {‘first’,‘last’},设定缺失值的显示位置
====如果要获取序号👇
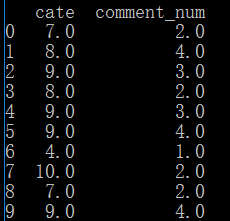
#进行对comment_num排序得出sort_num列的序号
data['sort_num']=data['comment_num'].rank(ascending=0,method='dense')
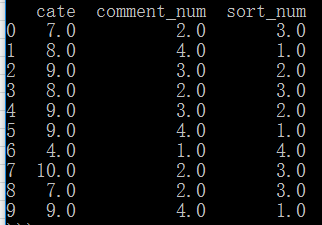
rank()中两个参数:
ascending,就是选择是升序还是降序排列。
method较重要,上图排序后结果,发现如果相同则并列排序,method则为控制排序方法
method='first' 如果出现相等,则取最先出现的值序号为“最小”,其他相同值依次按1递增
data['sort_num']=data['comment_num'].rank(ascending=0,method='first')
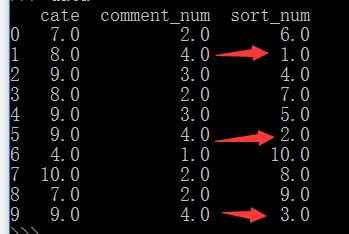
method='min' 相等则序号一样,新增一个相同序号,下一个排名序号则会推后+1
data['sort_num']=data['comment_num'].rank(ascending=0,method='min')

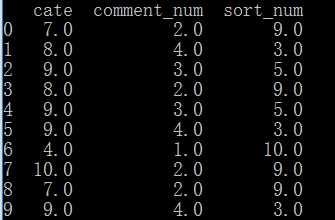
method='max'
data['sort_num']=data['comment_num'].rank(ascending=0,method='max')
---------------------------------组内排序-----------------------------
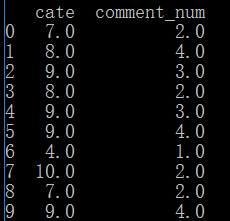
以cate字段为一组,对comment排序
data['group_sort']=data['comment_num'].groupby(data['cate']).rank(ascending=0,method='dense')
本文章仅供学习参考,如有版权侵犯,请联系作者修改,转载请注明出处!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号