寒假作业(2/2)
| 这个作业属于哪个课程 | 2021春软件工程实践 | W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 体验软件开发过程 |
| 其他参考文献 | 无 |
阅读《构建之法》并提问
我的问题
1. 第二章 个人技术和流程
单元测试必须有最熟悉代码的人(程序的作者)来写。代码的作者最了解代码的目的、特点和实现的局限性。所以,写单元测试没有比作者更适合的人选了。
一开始我是赞成这段话的,但后来上了软件质量测试课,认识到专业的测试人员不仅有编写代码的能力,而且掌握测试思想,在专业程度上会比开发人员更胜一筹。当对程序的熟悉程度与测试的专业程度无法兼顾时,是否可以通过在开发人员里培养测试人员解决矛盾?
当开发人员与专业测试人员一起进行测试时,你将更清楚全面地了解与产品发布相关的业务风险。同时,在用户遇到高风险问题之前,你将有机会去解决掉这些麻烦。这也正是测试的最终目标——它需要多个角色之间更多的协作,而不是针对开发人员 / 测试人员谁该承担测试任务争论不休。
以上时我在一篇文章中看到的说法。但是这又引出一个新问题,让开发人员接手多少测试工作才会不影响他的精力,又同时保证测试的高质量?
2. 第四章 两人合作
结对编程
对“结对编程”这个模式的可行性还是有些疑惑的,如果当两个人的价值理念与目标期待产生强烈冲突时,这个模式还能顺利进行下去吗?如果在原则上,比如这个软件的最终呈现形式等出现观念的对立,我不认为通过交流技巧就可以达成一致。结对编程是否只能用在简单的程序编写和单元测试上呢?进行结对的时候是否需要一个两人之外的统领者?
3. 第八章 需求分析
市场分析者:代表“典型用户”的需求,他们或是市场部分的成员,或者是独立的市场分析人士。
这是在“软件产品的利益相关者”中提到的,只有寥寥几笔,没有多余的描述了,但我有些好奇。在网络上搜索了一下“市场分析”,发现涵盖的范围比我想象中的广很多,看了几篇报告后,发现报告涵盖了产品竞争格局、市场供需状况、市场规模分析与行业政策法规等方面的内容。既然市场分析者对整个市场有较清晰的把控,能代表“典型用户”的需求,相较于普通用户又能够与开发团队进行更专业的沟通交流,那可不可以说市场分析人士的意见比普通用户的更有建设性?
4. 第八章 需求分析 & 第九章 项目经理
PM做开发和测试之外的所有事情。
看完第八章,感叹需求分析这么重要也这么复杂的任务要交由谁来完成,然后就看到了第九章的“项目经理”这一角色。私以为,“开发和测试之外的所有事情”都交由一个人来做有些可怕了,毕竟开发团队不只有“程序员”,也有专职开发的与专门测试的,专业的事由专业的人来做。而PM却要完成需求分析、项目计划、风险把控、资源统筹等多项任务,工作是否过于繁重?如果PM中也适当分职会有更高的效率和更出色的完成度吗?
带着这一问题去查阅资料,发现有时一个团队也会同时又产品经理与项目经理,但如果两人的方案产生冲突无法协调,这个产品又怎么做好呢?
5. 第十一章 软件设计与实现
写好代码后,小飞对照设计文档和代码指南进行自我复审,重构代码。
“重构代码”这一概念让我有些在意,以为我一直以为程序的基本架构在一开始就是设计好的,至少后期不能修改。我查阅了一些资料,有这样的定义:
关于代码重构的理解:在不改变软件系统/模块所具备的功能特性的前提下,遵循/利用某种规则,使其内部结构趋于完善。其在软件生命周期中的价值体现主要在于可维护性和可扩展性。
根据一些实例来看,似乎小至“函数命名不规范,缺少注释,尤其是函数功能、返回值及参数说明”,大到“系统技术架构无法满足业务发展需求,如性能瓶颈频现,无法快速进行新业务逻辑的添加/修改”都算作需要重构。前者可以理解,也让我意识到我确实在时时进行重构,而后者的修改就显得有些困难。当软件出现性能、架构上的瓶颈时,该如何跨越这一难点?如果无法解决、且计划好的交付时间临近,程序要强行在原架构上继续扩展吗?
软件工程发展过程中的小故事
史上第一位程序员是名贵族小姐,且这位贵族小姐来头不小,是19世纪英国著名诗人拜伦的女儿。她是一名数学家,也是世界上第一位程序员。她的名字是Ada Lovelace。
阿达一生做出的成就不少。她设计了巴贝奇分析机上解伯努利方程的一个程序,证明了计算机狂人巴贝奇的分析其可以用于许多问题的求解。
后来她在1843年发表的论文里提到了一个叫循环和子程序的概念,并且她相信以后创作复杂音乐、制图和科学研究是可以通过机器来创作的,这在当时是大胆的预见,但在今天都逐渐成为了现实。
现在看来,阿达首先为计算机拟定的“算法”,以及写作的那份“程序设计流程图”都是极为难得和珍贵的,也是史上第一件计算机程序。
后来据说国防部花了10年时间,把所需软件的全部功能混合在一种计算机语言里,为的是想让它能成为军方数千种电脑的标准。
于是在1981年,为了纪念这位程序员,这种语言被正式命名为ADA(阿达)语言,艾达·洛夫雷斯也被公认为“世界上第一位软件工程师”。
没想到在一个以男性工作者占比大而闻名的领域中,第一位闻名的工作者居然是一名女性。这个故事激励着我,无论以后成功还是失败,别将结果归因于性别。
参考链接:https://blog.csdn.net/XVJINHUA954/article/details/110266902
WordCount程序
Github项目地址
PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | 7 | 7 |
| 估计这个任务需要多少时间 | 7 | 7 |
| 开发 | 620 | 535 |
| 需求分析 (包括学习新技术) | 30 | 20 |
| 生成设计文档 | 40 | 25 |
| 设计复审 | 10 | 5 |
| 代码规范 | 20 | 30 |
| 具体设计 | 30 | 25 |
| 具体编码 | 300 | 210 |
| 代码复审 | 40 | 40 |
| 测试 | 150 | 180 |
| 报告 | 60 | 50 |
| 测试报告 | 15 | 10 |
| 计算工作量 | 15 | 10 |
| 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 687 | 592 |
解题思路描述
解题思路描述。即刚开始拿到题目后,如何思考,如何找资料的过程。
一开始拿到题目时先进行需求分析,最先关注主要实现什么功能,其次再看看是否有另外的要求,如此次要求对核心功能进行封装。简单查阅了Java的文件读写相关API后,确定了在统计字符数时逐字符读取,统计行数时逐行读取,在统计单词数的同时记录单词与其出现次数,之后实现排序。在对比多个数据结构后,考虑到查找的方便,选择用map来存储单词及其词频。至于封装,决定采用一名为CoreCount的类来包装核心功能的函数。
代码规范制定链接
设计与实现过程
设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(展示出项目关键代码),并解释思路,以及独到之处。
设计
- WordCount类
该类包含一个main函数。main函数负责从命令行获取输入的文件名,将输入文件的文件名传给核心功能类,获取返回结果后,生成格式化的内容并写入输出文件。 - CoreCount类
该类的数据成员有字符数charCount、单词数wordCount、行数lineCount和一个map存储的单词表wordsMap,前三个成员类型为Long。该类的成员函数有上述数据成员的get方法,有三个实现核心功能的方法——countChars()统计字符数,countWordsAndLines()统计单词数与行数,同时也生成未排序的单词表,sortWordsMap()对单词表进行排序。其中,sortWordsMap()在countWordsAndLines()中被最后调用。此外还有一个count()函数,集中调用了countChars()与countWordsAndLines()两个方法,供外部程序一次性调用所有核心方法,实现全部功能。
WordCount类的main函数在获取了输入文件的文件名之后,通过该文件名new一个CoreCount类的实例对象,调用该对象的count()方法让其实现统计功能。接下来,main函数再依次调用CoreCount实例对象的各个getXXX()方法,获取统计数据,生成格式化字符串并写入输出文件。对于词频统计,调用getWordsList()方法获取一个wordsMap排序后的entry list。遍历该list,输出前十个单词及其出现次数。
实现
- 统计字符数
用BufferdReader的read()方法逐字符读取,读取的同时charCount加一。while (reader.read() != -1) { charCount += 1; } reader.close(); - 判断是否为正确格式的单词
逐个判断读取的字符,若字符为字母或数字,将其存入临时字符串word中,并读取下一个。而这个动作将在遇到一个非字母数字字符时被打断。当遇到一个非字母数字字符时,判断由其之前若干个字母数字字符组成的字符串word是否为一个格式正确的单词。若是,则对该单词进行处理,若不是,将该字符串置空,继续读取下一个字符。int len = line.length(); //line为用BufferdReader的readLine()方法读取的字符串 for (int i = 0; i < len; i++) { ch = line.charAt(i); //逐个字符 if (Character.isLetterOrDigit(ch)) { //判断是否为字母数字字符 word += ch; } else { if (!"".equals(word)) { if (isProperWord(word)) { //若格式正确,处理该单词 } } // end if word = ""; //重置词组 } // end if } // end for - 生成单词表
若是格式正确的单词,就将其加入单词表。首先要将该单词转为小写格式,然后在单词表wordsMap中按键查找该单词,若未找到,说明这是它第一次出现,则put(word, 1L),若找到,则取出value值(即单词出现次数),然后put(word, ++value)。if (isProperWord(word)) { wordCount += 1; word = word.toLowerCase(); if (wordsMap.get(word) == null) { wordsMap.put(word, 1L); } else { value = wordsMap.get(word); wordsMap.put(word, ++value); } } - 对单词表进行排序
用Collections.sort方法对wordsMap进行排序。重写比较器中的compare方法,按照value值由大到小进行排列,若value值相同,再对比key,若字典序靠前则排位靠前,这可通过String的compareTo方法实现。wordsList = new ArrayList<Map.Entry<String, Long>>(wordsMap.entrySet()); Collections.sort(wordsList, new Comparator<Map.Entry<String, Long>>() { public int compare(Map.Entry<String, Long> o1, Map.Entry<String, Long> o2) { if (o1.getValue() == o2.getValue()) { return o1.getKey().compareTo(o2.getKey()); } else { return (int)(o2.getValue() - o1.getValue()); } } }); - 统计行数
该功能在countWordsAndLines函数中实现,BufferedReader每读取一行,lineCount加一。while ((line = reader.readLine()) != null) { if (! line.trim().equals("")) { lineCount += 1; } }
性能改进
展示出项目性能测试截图并描述;记录在改进计算模块性能上所花费的时间,描述你改进的思路。
在countWordsAndLines方法中,有一for循环逐个读取字符串的字符。原先的代码如下:
for (int i = 0; i < line.length(); i++) {
//……
}
这意味着每进行一次循环,都要调用一次length()方法,这将产生不必要的开销。于是将代码改为只调用一次length()方法:
int len = line.length();
for (int i = 0; i < len; i++) {
//……
}
性能有所提升:
修改前的运行时间

修改后的运行时间

单元测试
展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中;如何优化覆盖率?
CoreCount的测试
CoreCount测试未另写测试用例,主要通过程序输入。
- 统计字符数功能的测试
输入所有ASCII码字符,测试是否能全部统计。@Test void testCountChars() throws IOException { BufferedWriter writer = new BufferedWriter(new FileWriter(file)); for (int i = 0; i < 128; i++) { writer.append((char)i); } writer.close(); coreCount.countChars(); assertEquals(128, coreCount.getCharCount()); } - 统计行数功能的测试
在几百条格式正确的行中,插入7条仅仅包含空白字符但字符组成方式不同的空行,测试程序是否能准确排除空白行。@Test void testCountLines() throws IOException { BufferedWriter writer = new BufferedWriter(new FileWriter(file)); for (int i = 0; i < 700; i++) { if(i == 0) writer.append("\n\n"); else if(i == 100) writer.append("\r\n"); else if(i == 200) writer.append("\t\n"); else if(i == 300) writer.append("\f\n"); else if(i == 400) writer.append("\0\n"); else if(i == 500) writer.append("\0\f\t\r\n"); else if(i == 600) writer.append(" \n"); else writer.append(" Here are some meaningful words, and this is a proper line. \n"); } writer.close(); coreCount.countWordsAndLines(); assertEquals((700 - 7), coreCount.getLineCount()); } - 统计单词数功能的测试
依次输入格式不正确的词组与正确形式的单词。格式不正确的词组包括以数字开头的词组、以小于4个英文单词开头的词组,以及穿插非字母数字字符的单词。测试程序是否能排除格式不正确的词组,只统计正确的单词。@Test void testCountWords() throws IOException { BufferedWriter writer = new BufferedWriter(new FileWriter(file)); //测试词组以数字开头的情况,如"7word" for (int i = 0; i < 11; i++) { writer.append(Integer.toString(i) + "word" + "\n"); } //测试词组以<4个英文字母开头的情况,如"wor7d"或"war" for (int i = 0; i < 21; i++) { writer.append("wor" + Integer.toString(i) + "d" + "\t"); } for (int i = 0; i < 31; i++) { writer.append("war" + "\r"); } //测试当正确的单词中穿插非字母数字字符时,程序是否能正确识别 for (int i = 0; i < 41; i++) { writer.append("w[or]d" + " "); } //正确的单词 for (int i = 0; i < 51; i++) { writer.append("word" + Integer.toString(i) + "&"); } writer.close(); coreCount.countWordsAndLines(); assertEquals(51, coreCount.getWordCount()); } - 生成有序单词表功能的测试
输入多组相互对比的单词,比如word19与word2、a与aaa,abcde与bcdef,这些单词出现频率相同,以此测试单词排序的正确性。同时也输入一些出现次数大于1的单词,测试词频排序的正确性。再输入已知次数的同一单词,但单词的大小写形式不断变化,以此测试程序在存储单词时是否完成小写转换,并对同一单词的不同形式正确计数。
测试时,遍历排序后的单词表wordsMap,对比前一组与后一组的频率与单词。若后一组的频率高于前一组,或频率相同时,后一组的单词字典序更靠前,则fail测试。@Test void testSortWordsMap() throws IOException { BufferedWriter writer = new BufferedWriter(new FileWriter(file)); //检查是否对同一频率的单词按照字典序正确排序,如word19比word2排序更前 for (int i = 0; i < 100; i++) { writer.append("word" + Integer.toString(i) + " "); } //如a比aaa排序更前 String str = ""; for (int i = 0; i < 10; i++) { for (int j = i; j < 15; j++) { str += 'a'; } writer.append(str + "\r"); str = ""; } //如abcde比bcdef排序更前 char[] array = "abcde".toCharArray(); writer.append(String.copyValueOf(array) + "\t"); for (int i = 0; i < 20; i++) { for (int j = 0; j < array.length; j++) { array[j] = (char)(array[j] + 1); } writer.append(String.copyValueOf(array) + "\t"); } writer.flush(); //检查频率排序的正确性,随意添加几个出现次数>1的单词 for (int i = 0; i < 30; i++) { writer.append(" your opal eyes areall Iwish tosee "); if (i < 1) writer.append(" opal eyes areall Iwish tosee "); if (i < 2) writer.append(" areall Iwish tosee "); if (i < 3) writer.append(" Iwish tosee "); if (i < 4) writer.append(" tosee "); } writer.append("\n"); writer.flush(); //检查是否正确识别变换大小写形式的同一单词,同时测试同一单词的计数功能 char[] word = "champagne".toCharArray(); for (int i = 0; i < word.length; i++) { word[i] = Character.toUpperCase(word[i]); writer.append(String.copyValueOf(word) + "\n"); } word = "champagne".toCharArray(); writer.close(); //开始测试,当value或key的排列顺序不符合规定时,fail the test coreCount.countWordsAndLines(); Iterator<Map.Entry<String, Long>> iterator = coreCount.getWordsList().iterator(); Map.Entry<String, Long> entry = null; String key, preKey; key = preKey = ""; Long value = 0L, preValue = 0L; while (iterator.hasNext()) { entry = (Map.Entry<String, Long>) iterator.next(); key = entry.getKey(); value = entry.getValue(); if (value < 0) fail("出现错误!单词 " + key + " 的频率为 " + value + " ,小于0"); if (key.isEmpty()) fail("出现错误!单词为空"); if ((preValue != 0) && (value > preValue)) fail(preKey + "-" + preValue + " 与 " + key + "-" + value + " 的频率排序错误"); else if (value == preValue) { if (key.toString().compareTo(preKey.toString()) <= 0) fail(preKey + "-" + preValue + " 与 " + key + "-" + value + " 的单词字典序排序错误"); } preKey = key; preValue = value; } assertEquals(word.length, coreCount.getWordsMap().get(String.copyValueOf(word))); } - 输入内容为空的测试
@Test void testCount() throws IOException { //测试输入为空的情况 BufferedWriter writer = new BufferedWriter(new FileWriter(file)); writer.append(""); writer.close(); coreCount.count(); assertEquals(0, coreCount.getCharCount()); assertEquals(0, coreCount.getWordCount()); assertEquals(0, coreCount.getLineCount()); }
WordCount的测试
WordCount测试包含各类异常的测试、文件中没有内容的测试,与一个传入正常文件的测试。因为几个测试大致相同,故只贴出传入正常文件的测试的代码:
void testMain() {
String[] files = {"input.txt", "output.txt"};
WordCount.main(files);
}
其中,测试用例input.txt的内容如下:
forever&sad&sdark2 dGIGsede| dy77dew(((finsha435 9
782* 324**de forever==56yuyu ewyuD-hu 7-daRk2
love story the STORY OF us
everything has changed yooou said forever
wonderland blank space spacE SPAce[SpAce]space@space1{space2&SPACE1&&spa\Space2021}space#forever$story
56yuyu+is+dGIGsede ewyuD-hu-ewyuD-hu
everything everything everything 1everything
alltoowell all1-too20-well
rever= =56y( ) changed
测试覆盖率
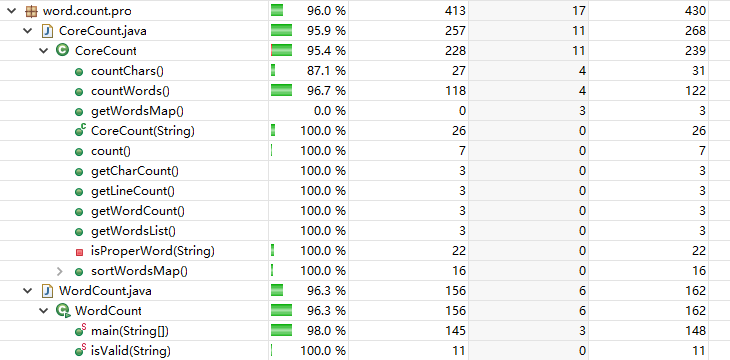
优化覆盖率时应充分考虑各种分支,因为分支中可能存在导致错误发生的边界情况。
异常处理说明
在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
- FileNotFoundException
当输入不规范、当前目录中不包含输入文件名的文件时,会抛出FileNotFoundException并打印异常信息。
测试如下:@Rule public ExpectedException expectedEx = ExpectedException.none(); @Test void testFileNotFound() { expectedEx.expect(FileNotFoundException.class); expectedEx.expectMessage("3"); String[] files = {"3", "output.txt"}; WordCount.main(files); } - NullPointerException
main函数中有一条语句:
用于获取单词表wordsMap排序后的entry list。但在CoreCount中,该list的初值设为null。故此处要包装在try-catch语句中,抛出一个NullPointerException并打印异常信息。Iterator<Map.Entry<String, Long>> iterator = coreCount.getWordsList().iterator(); - IOException
BufferedReader的读写异常。
心路历程与收获
- 体验了软件开发过程,结合书本知识,通过实践,加深了对“软件=程序+软件工程”这一概念的理解,为后续的团队开发奠定基础。
- 需求分析一定不能马虎,不能只关注核心功能而疏忽一些其他要求,要面面俱到。此次在程序基本完成后才注意到要求不是从控制台输入而是以命令行输入,若没有助教提醒可能会直接提交一个错误的程序上去。也幸好程序不复杂,获取输入的模块独立性强,改动时不影响其他功能的性能。
- 以后可以考虑边写代码边复审,以便性能改进。这次等具体编码完成后才统一复审并进行性能改进,本来想试试将程序中的部分String类型数据换成StringBuffer,但由于改动太大,会牵涉到其他功能,于是放弃了。
- 代码更新的同时,注释和测试用例也要及时更新,把多次更新积攒在一起的话,之后会很麻烦。
- 完成程序时进行详细的总结对学习和进步有很大帮助。
- 经历一整个开发过程的软件与以前一拿到题目就闷头写代码得到的软件有很大不同,至少我对于程序架构的把握更清晰,也比较清楚程序的性能和正确性。
- 第一次写测试,发现测试真的很有帮助,不仅可以实现自动化、不用一次次在控制台输入、同时对比输出,而且可以照亮程序的死角。
- 不太理解为什么不让贴大段代码,个人认为只要辅以恰当的注释说明,代码并不会给读者太差的观感,至少我还是挺乐意看到代码的,毕竟代码段行数多并不一定等于内容杂或结构差。
- 一定要备份!也不要把VS Code的工作区建在安装目录下!!!要不然就可能像我今天这样,ddl当天VS Code更新、工作区被覆盖,被迫成为一个无情的打字机器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号