数据集划分
构建和训练机器学习模型是希望对新的数据做出良好预测 如何去保证训练的实效,可以应对以前未见过的数据呢?
一种方法是将数据集分成两个子集:
训练集-用于训练模型的子集
测试集-用于测试模型的子集
通常,在测试集上表现是否良好是衡量能否在新数据上表现良好的有用指标,前提是:
测试集足够大
不会反复使用相同的测试集来作假
将单个数据集拆分为一个训练集和一个测试集,确保测试集满足以下两个条件:
规模足够大,可产生具有统计意义的结果
能代表整个数据集,测试集的特征应该与训练集的特征相同

思考:
使用测试集和训练集来推动模型开发迭代的流程。
在每次迭代时,都会对训练数据进行训练并评估测试数据,并以基于测试数据的评估结果为指导来选择和更改各种模型超参数,例如学习速率和特征。这种方法是否存在问题?
多次重复执行该流程可能导致模型不知不觉地拟合了特定测试集的特性
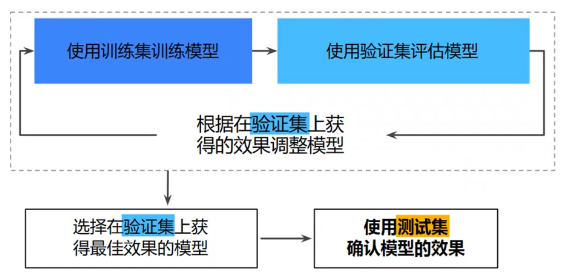
改进——新的数据划分
通过将数据集划分为三个子集,可以大幅降低过拟合的发生几率:

使用验证集评估训练集的效果。
在模型“通过”验证集之后,使用测试集再次检查评估结果

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步