mysql 的语句的执行顺序
1: select from where group by having order by 的执行顺序
首先 要先查询那张表 from , 在对这些表进行条件过滤 where, 过滤完成后进行分组 group by , select 显示要查询的哪些字段,having对查询出来的字段进行一个二次过滤,最后排序展示
mysql 存储引擎选择:
Innodb mysql 5.5以上的版本默认的存储引擎,支持事务,行级锁,适合高并发,支持物理外键,不过现在设计表一般都是使用逻辑外键,也就是在一张表里面添加外键的字段,读写均衡,不支持全文索引,但现在很少在数据库中去操作,大部分是使用ElasticSearch去实现

常见的索引类型:
普通索引:用来提高查询速度
组合索引:对经常查询的多字段设置索引,提高查询速度,多组合查询
唯一索引:唯一性,列值唯一性,可以为空,比如用户账号等
主键索引: 列值唯一,只能有一个,加速查询,不能为空,表ID
全文索引:对内容进行分词的搜索,只支持Myisam
索引不是越多越好,一张表索引过多,会影响插入的性能,后期索引维护会比较麻烦,如果一张表的数据不是很大,就没必要用索引了,当然也不是用了索引就有用,很多时候索引也会失效,比如 查询语句用了 like %% 索引就会失效,可以考虑用 like ' %',在索引列使用一些运算符,也会使索引失效, 组合索引的时候 如果没有用到组合索引中的第一个字段,索引也会失效, 使用 or 语句的时候,两边都要有索引,不然会失效
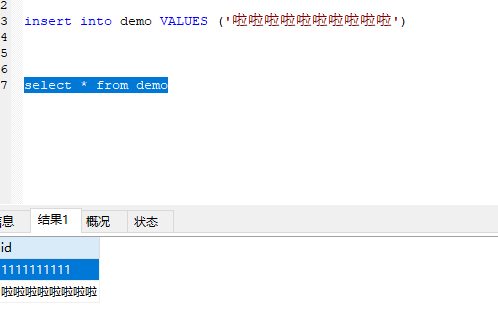
char(20) 和 varchar(20)的区别:
两个字段都是存储的都是字符,比如存储中文最多只能存储20个,mysql把中文看做一个字符,
char 插入时如果没有达到长度,会使用空格填充. varchar保存长度多少就多少,不会使用空格进行填充. char长度固定,varchar长度可变的,效率方面的话char会比varchar效率更高一点,
char取值时会把后面的空格去除,varchar不会
一般固定的UUID, base64的加密,手机号码可以用char, varchar 存储一些不可控的字符 比如收货地址,审核原因等
datetime 和 timestamp 的区别
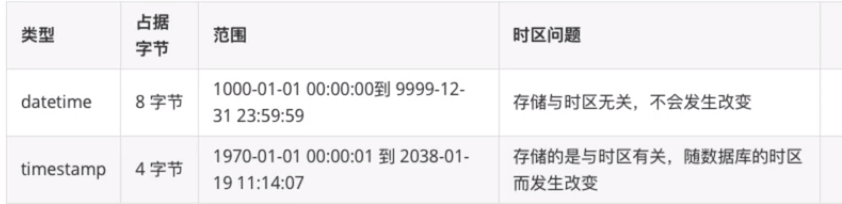
也就是说 使用timestamp只能用到2038-01-19号
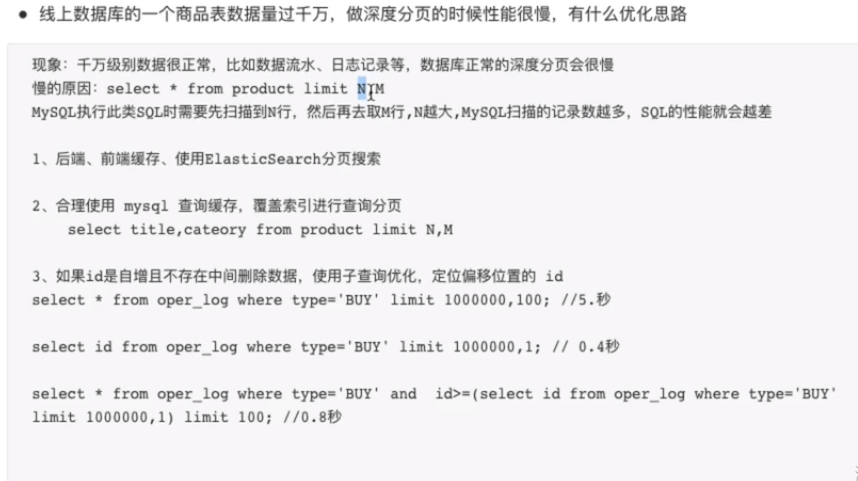
分页优化查询
分页 limit n,m 如果N越大,扫描表的记录就会越多.速度就越慢,可以使用子查询优化
一张200万数据的表
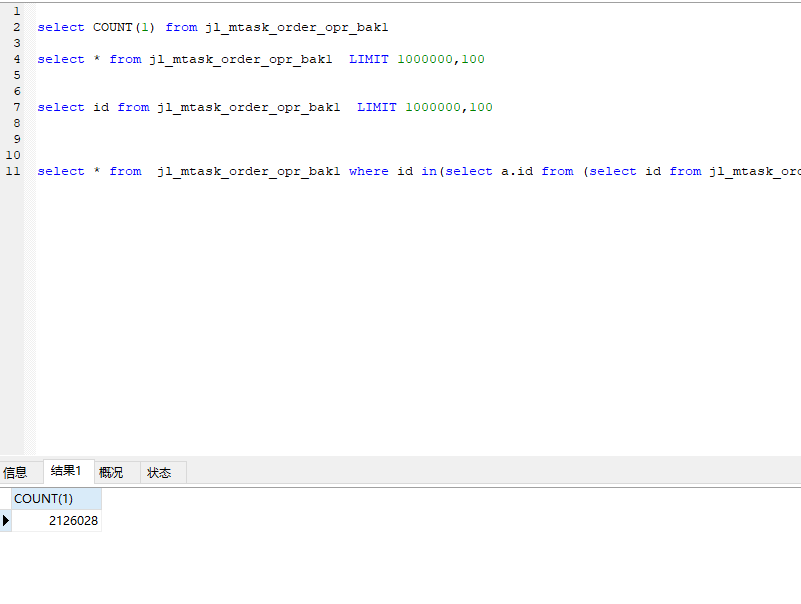
使用普通分页查询
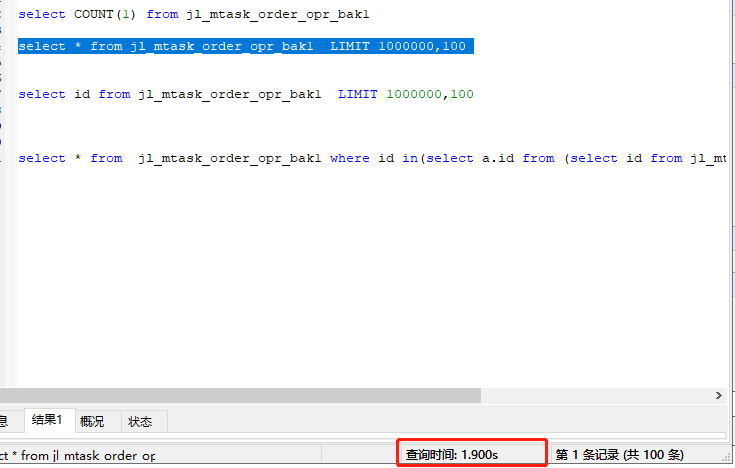
查询 主键 id
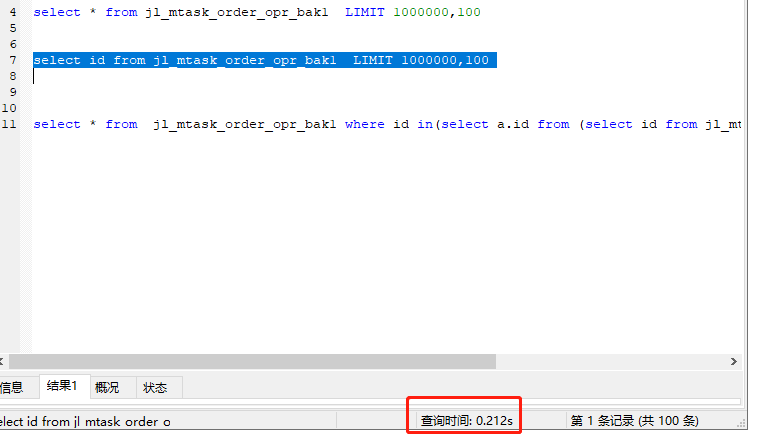
使用子查询优化,快了1.6秒
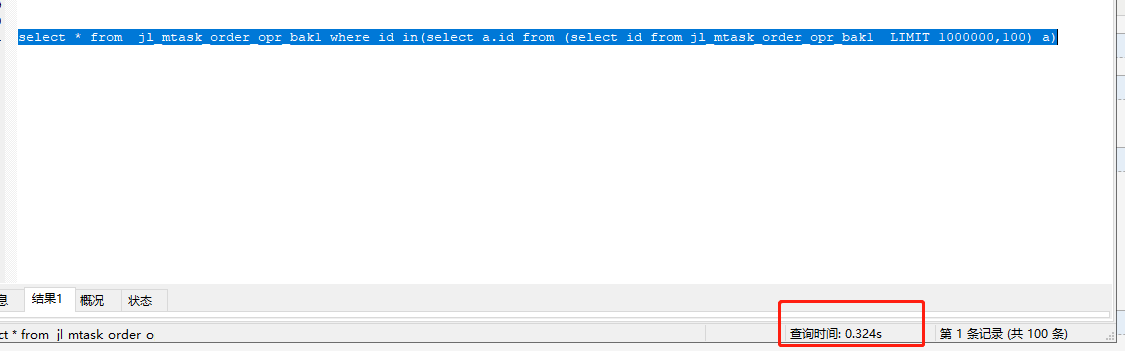
其他方法: