数据分析---《Python for Data Analysis》学习笔记【01】
《Python for Data Analysis》一书由Wes Mckinney所著,中文译名是《利用Python进行数据分析》。这里记录一下学习过程,其中有些方法和书中不同,是按自己比较熟悉的方式实现的。
第一个实例:1.usa.gov data from bit.ly
简介:2011年,URL缩短服务bit.ly和美国政府网站usa.gov合作,提供了一份从生成.gov或.mil短链接用户那里收集来的匿名数据
数据下载地址:https://github.com/wesm/pydata-book/blob/2nd-edition/datasets/bitly_usagov/example.txt
准备工作:导入pandas和matplotlib,因为需要读取JSON格式的文件,因此这里还需要导入json模块
import pandas as pd import json import matplotlib.pyplot as plt fig,ax=plt.subplots()
首先,读取文件: (读取example文件后,file为由字符串组成的列表,然后我们再用json模块将file转换成JSON格式)
with open (r"...\example.txt") as f: file=f.readlines() records=[json.loads(line) for line in file]
注:
json.load()是用来读取文件的
json.loads()是用来读取字符串的
看一下records的前5项:
[{'a': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11', 'c': 'US', 'nk': 1, 'tz': 'America/New_York', 'gr': 'MA', 'g': 'A6qOVH', 'h': 'wfLQtf', 'l': 'orofrog', 'al': 'en-US,en;q=0.8', 'hh': '1.usa.gov', 'r': 'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf', 'u': 'http://www.ncbi.nlm.nih.gov/pubmed/22415991', 't': 1331923247, 'hc': 1331822918, 'cy': 'Danvers', 'll': [42.576698, -70.954903]}, {'a': 'GoogleMaps/RochesterNY', 'c': 'US', 'nk': 0, 'tz': 'America/Denver', 'gr': 'UT', 'g': 'mwszkS', 'h': 'mwszkS', 'l': 'bitly', 'hh': 'j.mp', 'r': 'http://www.AwareMap.com/', 'u': 'http://www.monroecounty.gov/etc/911/rss.php', 't': 1331923249, 'hc': 1308262393, 'cy': 'Provo', 'll': [40.218102, -111.613297]}, {'a': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; InfoPath.3)', 'c': 'US', 'nk': 1, 'tz': 'America/New_York', 'gr': 'DC', 'g': 'xxr3Qb', 'h': 'xxr3Qb', 'l': 'bitly', 'al': 'en-US', 'hh': '1.usa.gov', 'r': 'http://t.co/03elZC4Q', 'u': 'http://boxer.senate.gov/en/press/releases/031612.cfm', 't': 1331923250, 'hc': 1331919941, 'cy': 'Washington', 'll': [38.9007, -77.043098]}, {'a': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/534.52.7 (KHTML, like Gecko) Version/5.1.2 Safari/534.52.7', 'c': 'BR', 'nk': 0, 'tz': 'America/Sao_Paulo', 'gr': '27', 'g': 'zCaLwp', 'h': 'zUtuOu', 'l': 'alelex88', 'al': 'pt-br', 'hh': '1.usa.gov', 'r': 'direct', 'u': 'http://apod.nasa.gov/apod/ap120312.html', 't': 1331923249, 'hc': 1331923068, 'cy': 'Braz', 'll': [-23.549999, -46.616699]}, {'a': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.79 Safari/535.11', 'c': 'US', 'nk': 0, 'tz': 'America/New_York', 'gr': 'MA', 'g': '9b6kNl', 'h': '9b6kNl', 'l': 'bitly', 'al': 'en-US,en;q=0.8', 'hh': 'bit.ly', 'r': 'http://www.shrewsbury-ma.gov/selco/', 'u': 'http://www.shrewsbury-ma.gov/egov/gallery/134127368672998.png', 't': 1331923251, 'hc': 1273672411, 'cy': 'Shrewsbury', 'll': [42.286499, -71.714699]}]
可以看到,records是由字典组成的列表,字典由key和value组成。每一个用户信息是一个字典,每一个字典的key代表一个特征,比如说tz就是时间区域。
接下来把records转换成pandas的DataFrame格式:
data=pd.DataFrame(records)
来看一下data的前5行:
_heartbeat_ a \ 0 NaN Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKi... 1 NaN GoogleMaps/RochesterNY 2 NaN Mozilla/4.0 (compatible; MSIE 8.0; Windows NT ... 3 NaN Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)... 4 NaN Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKi... al c cy g gr h hc \ 0 en-US,en;q=0.8 US Danvers A6qOVH MA wfLQtf 1.331823e+09 1 NaN US Provo mwszkS UT mwszkS 1.308262e+09 2 en-US US Washington xxr3Qb DC xxr3Qb 1.331920e+09 3 pt-br BR Braz zCaLwp 27 zUtuOu 1.331923e+09 4 en-US,en;q=0.8 US Shrewsbury 9b6kNl MA 9b6kNl 1.273672e+09 hh kw l ll nk \ 0 1.usa.gov NaN orofrog [42.576698, -70.954903] 1.0 1 j.mp NaN bitly [40.218102, -111.613297] 0.0 2 1.usa.gov NaN bitly [38.9007, -77.043098] 1.0 3 1.usa.gov NaN alelex88 [-23.549999, -46.616699] 0.0 4 bit.ly NaN bitly [42.286499, -71.714699] 0.0 r t \ 0 http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/... 1.331923e+09 1 http://www.AwareMap.com/ 1.331923e+09 2 http://t.co/03elZC4Q 1.331923e+09 3 direct 1.331923e+09 4 http://www.shrewsbury-ma.gov/selco/ 1.331923e+09 tz u 0 America/New_York http://www.ncbi.nlm.nih.gov/pubmed/22415991 1 America/Denver http://www.monroecounty.gov/etc/911/rss.php 2 America/New_York http://boxer.senate.gov/en/press/releases/0316... 3 America/Sao_Paulo http://apod.nasa.gov/apod/ap120312.html 4 America/New_York http://www.shrewsbury-ma.gov/egov/gallery/1341...
每一个用户是一行,每一个特征为一列。
假如我们想知道哪个地区的用户最多,该怎么做呢?
思路:提取tz(时间区域)这一列(当然不要忘了去除NA值和空值),然后用计数函数统计每个时间区域的数量。
time_zone=data['tz'] #提取tz列 time_zone_data=time_zone[time_zone!=''] #去除空值 time_zone_data=time_zone_data.dropna() #再去除无效值 time_zone_counts=time_zone_data.value_counts() #计数
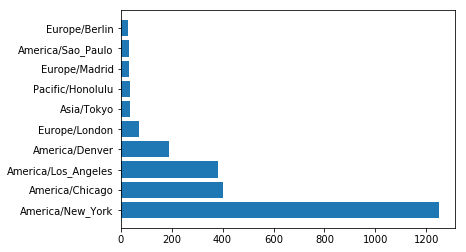
让我们看一下前10位的时间区域:
America/New_York 1251 America/Chicago 400 America/Los_Angeles 382 America/Denver 191 Europe/London 74 Asia/Tokyo 37 Pacific/Honolulu 36 Europe/Madrid 35 America/Sao_Paulo 33 Europe/Berlin 28 Name: tz, dtype: int64
可以看到,美国纽约的用户最多,美国芝加哥其次。。。
用图画出来:
ax.barh(range(10), time_zone_counts[:10]) ax.set_yticks(range(10)) ax.set_yticklabels(time_zone_counts[:10].index.values)
让我们再来看一下data文件,可以看到,a这一列包含用户使用的浏览器、计算机系统等信息。同理,我们也可以把用户使用哪种浏览器最多统计出来。
首先,提取a这一列,清洗数据,由于浏览器数据是a这一列的其中一部分,因此把提取出的a这一列信息分隔开,提取其首项数据,也就是浏览器数据,然后用计数函数统计每个浏览器的数量。
browser=data['a'].dropna() browser_data=pd.Series([i.split()[0] for i in browser]) browser_counts=browser_data.value_counts()
来看一下前10位的浏览器:
Mozilla/5.0 2594 Mozilla/4.0 601 GoogleMaps/RochesterNY 121 Opera/9.80 34 TEST_INTERNET_AGENT 24 GoogleProducer 21 Mozilla/6.0 5 BlackBerry8520/5.0.0.681 4 Dalvik/1.4.0 3 BlackBerry8520/5.0.0.592 3 dtype: int64
上面说到,a这一列还包含有用户的计算机系统信息,如果我们想知道使用Windows系统和不使用Windows系统的用户分别是多少(按时区划分),该如何做呢?
首先,对数据进行清洗,提取a和tz列的有效值和非空值:
data=data[data['a'].notnull()] #提取a列有效值 data=data[data['tz'].notnull()] #提取tz列有效值 data=data[data['tz']!=''] #提取tz列非空值
然后,用numpy的where函数来对数据进行分类:
import numpy as np data["operating_system"]=np.where(data['a'].str.contains("Windows"),"Windows","Not Windows") #如果a这一列包含有Windows字样,则用户使用Windows系统
现在再来看一下data数据的前5行:
_heartbeat_ a \ 0 NaN Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKi... 1 NaN GoogleMaps/RochesterNY 2 NaN Mozilla/4.0 (compatible; MSIE 8.0; Windows NT ... 3 NaN Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8)... 4 NaN Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKi... al c cy g gr h hc \ 0 en-US,en;q=0.8 US Danvers A6qOVH MA wfLQtf 1.331823e+09 1 NaN US Provo mwszkS UT mwszkS 1.308262e+09 2 en-US US Washington xxr3Qb DC xxr3Qb 1.331920e+09 3 pt-br BR Braz zCaLwp 27 zUtuOu 1.331923e+09 4 en-US,en;q=0.8 US Shrewsbury 9b6kNl MA 9b6kNl 1.273672e+09 hh kw l ll nk \ 0 1.usa.gov NaN orofrog [42.576698, -70.954903] 1.0 1 j.mp NaN bitly [40.218102, -111.613297] 0.0 2 1.usa.gov NaN bitly [38.9007, -77.043098] 1.0 3 1.usa.gov NaN alelex88 [-23.549999, -46.616699] 0.0 4 bit.ly NaN bitly [42.286499, -71.714699] 0.0 r t \ 0 http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/... 1.331923e+09 1 http://www.AwareMap.com/ 1.331923e+09 2 http://t.co/03elZC4Q 1.331923e+09 3 direct 1.331923e+09 4 http://www.shrewsbury-ma.gov/selco/ 1.331923e+09 tz u \ 0 America/New_York http://www.ncbi.nlm.nih.gov/pubmed/22415991 1 America/Denver http://www.monroecounty.gov/etc/911/rss.php 2 America/New_York http://boxer.senate.gov/en/press/releases/0316... 3 America/Sao_Paulo http://apod.nasa.gov/apod/ap120312.html 4 America/New_York http://www.shrewsbury-ma.gov/egov/gallery/1341... operating_system 0 Windows 1 Not Windows 2 Windows 3 Not Windows 4 Windows
可以看到,已经出现了对应的操作系统这一列。
接下来,我们需要对数据进行分组: (按a列和operating_system列分组,对operating_system列计数)
by_tz_os=data.groupby(["tz","operating_system"])["operating_system"].count()
让我们来看一下by_tz_os的前10行:
tz operating_system Africa/Cairo Windows 3 Africa/Casablanca Windows 1 Africa/Ceuta Windows 2 Africa/Johannesburg Windows 1 Africa/Lusaka Windows 1 America/Anchorage Not Windows 4 Windows 1 America/Argentina/Buenos_Aires Not Windows 1 America/Argentina/Cordoba Windows 1 America/Argentina/Mendoza Windows 1
这里已经列出了各个时区使用Windows系统的人数和不使用Windows系统的人数。但是这个格式不是我们想要的,我们想要Windows和Not Windows变成单独的两列。
因此,我们把by_tz_os展开,并把缺失值变为0:
tz_os_counts=by_tz_os.unstack().fillna(0)
现在tz_os_counts已经成为了我们想要的格式:
operating_system Not Windows Windows tz Africa/Cairo 0.0 3.0 Africa/Casablanca 0.0 1.0 Africa/Ceuta 0.0 2.0 Africa/Johannesburg 0.0 1.0 Africa/Lusaka 0.0 1.0 America/Anchorage 4.0 1.0 America/Argentina/Buenos_Aires 1.0 0.0 America/Argentina/Cordoba 0.0 1.0 America/Argentina/Mendoza 0.0 1.0 America/Bogota 1.0 2.0
接下来,我们对tz_os_counts进行排序(把使用Windows系统和不使用Windows系统人数最多的时区放在最前面):
tz_os_counts.sort_values(by=['Windows','Not Windows'], inplace=True, ascending=False)
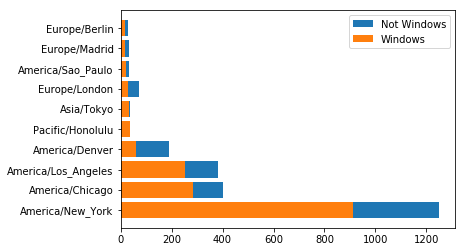
排序完成:
operating_system Not Windows Windows tz America/New_York 339.0 912.0 America/Chicago 115.0 285.0 America/Los_Angeles 130.0 252.0 America/Denver 132.0 59.0 Pacific/Honolulu 0.0 36.0 Asia/Tokyo 2.0 35.0 Europe/London 43.0 31.0 America/Sao_Paulo 13.0 20.0 Europe/Madrid 16.0 19.0 Europe/Berlin 9.0 19.0
用堆积条形图画出来:
ax.barh(range(10), tz_os_counts["Not Windows"][:10]+tz_os_counts["Windows"][:10], label="Not Windows") ax.barh(range(10), tz_os_counts["Windows"][:10], label="Windows") ax.set_yticks(range(10)) ax.set_yticklabels(tz_os_counts[:10].index.values) ax.legend() plt.show()
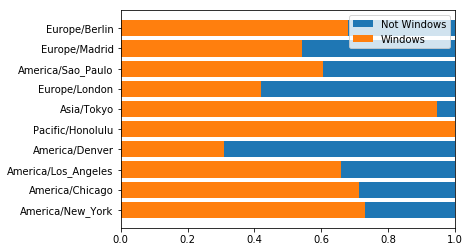
把图变成百分比形式:
ax.barh(range(10), (tz_os_counts["Not Windows"][:10]+tz_os_counts["Windows"][:10])/(tz_os_counts["Not Windows"][:10]+tz_os_counts["Windows"][:10]), label="Not Windows") ax.barh(range(10), (tz_os_counts["Windows"][:10])/(tz_os_counts["Not Windows"][:10]+tz_os_counts["Windows"][:10]), label="Windows") ax.set_yticks(range(10)) ax.set_yticklabels(tz_os_counts[:10].index.values) ax.set_xlim(0,1) ax.legend() plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号