假设检验(Hypothesis Testing)
假设检验的定义
假设检验:先对总体参数提出某种假设,然后利用样本数据判断假设是否成立。在逻辑上,假设检验采用了反证法,即先提出假设,再通过适当的统计学方法证明这个假设基本不可能是真的。(说“基本”是因为统计得出的结果来自于随机样本,结论不可能是绝对的,所以我们只能根据概率上的一些依据进行相关的判断。)
假设检验依据的是小概率思想,即小概率事件在一次试验中基本上不会发生。
如果样本数据拒绝该假设,那么我们说该假设检验结果具有统计显著性。一项检验结果在统计上是“显著的”,意思是指样本和总体之间的差别不是由于抽样误差或偶然而造成的。
假设检验的术语
零假设(null hypothesis):是试验者想收集证据予以反对的假设,也称为原假设,通常记为 H0。
例如:零假设是测试版本的指标均值小于等于原始版本的指标均值。
备择假设(alternative hypothesis):是试验者想收集证据予以支持的假设,通常记为H1或 Ha。
例如:备择假设是测试版本的指标均值大于原始版本的指标均值。
双尾检验(two-tailed test):如果备择假设没有特定的方向性,并含有符号“≠”,这样的检验称为双尾检验。
例如:零假设是测试版本的指标均值等于原始版本的指标均值,备择假设是测试版本的指标均值不等于原始版本的指标均值。
单尾检验(one-tailed test):如果备择假设具有特定的方向性,并含有符号 “>” 或 “<” ,这样的检验称为单尾检验。单尾检验分为左尾(lower tail)和右尾(upper tail)。
例如:零假设是测试版本的指标均值小于等于原始版本的指标均值,备择假设是测试版本的指标均值大于原始版本的指标均值。
检验统计量(test statistic):用于假设检验计算的统计量。
例如:Z值、t值、F值、卡方值。
显著性水平(level of significance):当零假设为真时,错误拒绝零假设的临界概率,即犯第一类错误的最大概率,用α表示。
例如:在5%的显著性水平下,样本数据拒绝原假设。
置信度(confidence level):置信区间包含总体参数的确信程度,即1-α。
例如:95%的置信度表明有95%的确信度相信置信区间包含总体参数(假设进行100次抽样,有95次计算出的置信区间包含总体参数)。
置信区间(confidence interval):包含总体参数的随机区间。
功效(power):正确拒绝零假设的概率,即1-β。当检验结果是不能拒绝零假设,人们又需要进行决策时,需要关注功效。功效越大,犯第二类错误的可能性越小。
临界值(critical value):与检验统计量的具体值进行比较的值。是在概率密度分布图上的分位数。这个分位数在实际计算中比较麻烦,它需要对数据分布的密度函数积分来获得。
临界区域(critical region):拒绝原假设的检验统计量的取值范围,也称为拒绝域(rejection region),是由一组临界值组成的区域。如果检验统计量在拒绝域内,那么我们拒绝原假设。
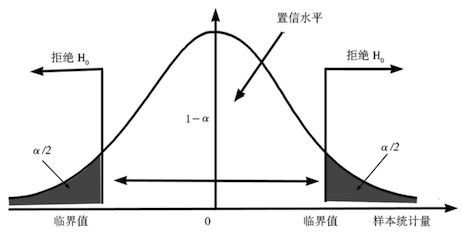
p值(p-value):在零假设为真时所得到的样本观察结果或获得更极端结果的概率。也可以说,p值是当原假设为真时,错误拒绝原假设的实际概率。
左尾检验的P值为检验统计量x小于样本统计值C的概率,即:p = P( x < C)
右尾检验的P值为检验统计量x大于样本统计值C的概率,即:p = P( x > C)
双尾检验的P值为检验统计量x落在样本统计值C为端点的尾部区域内的概率的2倍,即:p = 2P( x > C) (当C位于分布曲线的右端时) 或p = 2P( X< C) (当C 位于分布曲线的左端时) 。
效应量(effect size):样本间差异或相关程度的量化指标。效应量越大,两组平均数离得越远,差异越大。如果结果具有统计显著性,那么有必要报告效应量的大小。效应量太小,意味着即使结果有统计显著性,也缺乏实用价值。
假设检验的两类错误
第 I 类错误(弃真错误):零假设为真时错误地拒绝了零假设。犯第 I 类错误的最大概率记为 α(alpha)。
第 II 类错误(取伪错误):零假设为假时错误地接受了零假设。犯第 II 类错误的最大概率记为 β(beta)。
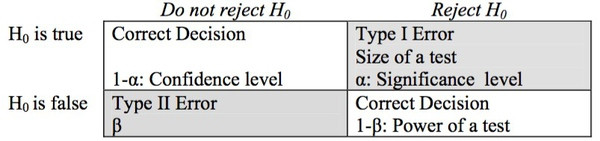
在假设检验中,我们可能在决策上犯这两类错误。一般来说,在样本量确定的情况下,任何决策无法同时避免这两类错误的发生,即在减少第一类错误发生的同时,会增大第二类错误发生的几率,或者在减少第二类错误发生的同时,会增大第一类错误发生的几率。
在大多数情况下,人们会控制第一类错误发生的概率。在进行假设检验时,人们通过事先给定显著性水平α的值来控制第一类错误发生的概率,常用的 α 值有 0.01,0.05,0.1。如果犯第一类错误的成本不高,那么可以选择较大的α值;如果犯第一类错误的成本很高,则选择较小的α值。
注:人们将只控制第一类错误的假设检验称为显著性检验,许多假设检验的应用都属于这一类型。
假设检验的步骤
假设检验的决策标准
由于检验是利用事先给定显著性水平的方法来控制犯错概率的,所以对于两个数据比较相近的假设检验,我们无法知道哪一个假设更容易犯错,即我们通过这种方法只能知道根据这次抽样而犯第一类错误的最大概率,而无法知道具体在多大概率水平上犯错。计算P值有效的解决了这个问题,P值其实就是按照抽样分布计算的一个概率值,这个值是根据检验统计量计算出来的。通过直接比较P值与给定的显著性水平α的大小就可以知道是否拒绝原假设,显然这就可以代替比较检验统计量的具体值与临界值的大小的方法。而且通过这种方法,我们还可以知道在P值小于α的情况下犯第一类错误的实际概率是多少。假如P=0.03<α(0.05),那么拒绝假设,这一决策可能犯错的概率就是0.03。
因此假设检验的第7,8步可以改成:7,利用检验统计量的具体值计算p值;8,将给定的显著性水平α与p值比较,作出结论:如果p值<=α,则拒绝原假设。
附:用于解读p值的指导意见:p值小于0.01---强有力的证据判定备择假设为真;
p值介于0.01~0.05---有力的证据判定备择假设为真;
p值介于0.05~0.1---较弱的证据判定备择假设为真;
p值大于0.1---没有足够的证据判定备择假设为真。
需要指出的是,如果p>α,那么原假设不被拒绝,在这种情况下,实际上是无法做出决策的。如果我们需要做出决策,那么此时就需要关注犯第二类错误的概率。当同时控制第一类错误和第二类错误发生的概率时,假设检验的结论就是:拒绝原假设或接受原假设。
假设检验的种类
主要包括:Z检验,t检验,卡方检验,F检验。
下面分别来看一下这四种假设检验:
Z检验(Z test):需要事先知道总体方差,另外,如果总体不服从正态分布,那么样本量要大于等于30,如果总体服从正态分布,那么对样本量没有要求。
Z检验用于比较样本和总体的均值是否不同或者两个样本的均值是否不同。检验统计量z值的分布服从正态分布。
由于总体方差一般都是未知的,并且Z检验只适合大样本的情况,而t检验同时适用于大样本和小样本的情况(至于为什么,请看:https://www.cnblogs.com/HuZihu/p/9442316.html),因此用t检验比较多。
t检验(t test):事先不知道总体方差,另外,如果总体不服从正态分布,那么样本量要大于等于30,如果总体服从正态分布,那么对样本量没有要求。
t检验分为单样本t检验,配对t检验和独立样本t检验。
单样本t检验(One Sample T-Test):用样本均值和总体均值进行比较,来检验样本与总体之间的差异性。
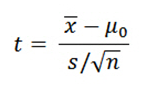
(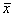 是随机样本均值,μ0是总体均值,s是样本标准差,n是样本中的观察值数量,自由度为n-1)
是随机样本均值,μ0是总体均值,s是样本标准差,n是样本中的观察值数量,自由度为n-1)
配对t检验(Paired Sample T-Test):用两个配对样本中各对观测值的差值均数和假设的差值进行比较,来检验以下几种情形: 1,同一受试对象或两个同质受试对象接受两种不同处理后的差异;2,同一受试对象接受处理前后的差异。
配对t检验的本质是先计算成对观测值之间的差异的均值,之后执行单样本t检验。
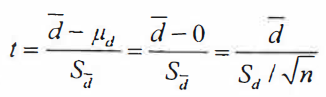
(d为每对数据的差值,d¯为样本差值的均数,Sd¯为样本差值均数的标准差,即样本差值的标准误差,Sd为样本差值的标准差,n为成对观测值的对数,自由度为n-1)
独立样本t检验(Independent Samples T-Test):用从两个不同总体抽取出的样本的均值进行比较,来检验两个总体之间的差异性。其又分为方差相等和方差不相等这两种情况。
方差相等(Equal Variance or pooled T-Test):每组数据的样本数量相同,或者两组数据的方差相差不大。
方差不相等(Unequal Variance T-Test):每组数据的样本数量不同,并且两组数据的方差相差较大。此假设检验亦称为Welch's t-test。
卡方检验(chi-square test):卡方检验属于非参数检验,不存在具体参数,且不需要有总体服从正态分布的假设。
卡方检验分为拟合优度检验和独立性检验。
拟合优度检验(Goodness-of-Fit Test):用样本中各个变量的观察频数与期望频数进行比较,来检验总体的概率分布是否服从理论概率分布。
拟合优度检验的H0是:总体服从某个概率分布。
建立四格表,表里填写相应的观察频数和期望频数。
计算χ2值: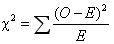 (O代表观察频数,E代表期望频数)。如果统计量(χ2)的值很小,说明观察频数和期望频数之间的差别不显著,统计量越大,差别越显著。
(O代表观察频数,E代表期望频数)。如果统计量(χ2)的值很小,说明观察频数和期望频数之间的差别不显著,统计量越大,差别越显著。
根据χ2分布及自由度可以确定在H0假设成立的情况下获得当前检验统计量的值及更极端情况的概率P。如果P值很小,说明观察值与理论值偏离程度太大,应当拒绝原假设;否则不能拒绝原假设。
独立性检验(Independence Test):用样本中两个类别型变量的观察频数与期望频数进行比较,来检验样本中两个类别型变量是否相互独立。
独立性检验的H0是:两个类别型变量相互独立。
建立列联表,一个变量作为行,另一个变量作为列。例如:
| 猫 | 狗 | 合计 | |
| 男 | 207 | 282 | 489 |
| 女 | 231 | 242 | 473 |
| 合计 | 438 | 524 | 962 |
(表里填写的是分别喜欢猫或狗的男女人数)
计算出期望频数,期望频数=第i行合计数*第j列合计数/样本量。(比如,喜欢猫的男性期望频数就是489*438/962=222.6。)
计算χ2值:![]() (O代表观察频数,E代表期望频数),df=(行数 − 1)*(列数 − 1)
(O代表观察频数,E代表期望频数),df=(行数 − 1)*(列数 − 1)
根据χ2分布及自由度可以确定在H0假设成立的情况下获得当前统计量及更极端情况的概率P。如果P值很小,说明两个类别变量之间有关联,应当拒绝原假设。
F检验分为方差齐性检验和方差分析。
方差齐性检验(F-Test for Equality of Variances):用从两个不同总体抽取出的样本的方差进行比较,来检验两个总体的方差是否相同。

(s2 是样本方差:^2 / (n-1)")
如果这两个样本来自于方差差不多大的总体,那么F值就会接近于1;相反,如果F值非常大,那就说明两个总体差异较大。
方差齐性检验的前提:两组样本均取自正态分布的总体。(注:由于F检验对于数据的正态性非常敏感,因此在检验方差齐性的时候,Levene检验的稳健性要优于F检验。Levene检验也可用于多个样本方差的比较。)
方差分析(Analysis of Variance,ANOVA):用从两个或两个以上不同总体(各个总体的方差差不多大 )抽取出的样本的组内方差和组间方差进行比较,来检验多个总体均值的差异性。其又分为单因素方差分析和多因素方差分析。
这里主要说一下单因素方差分析: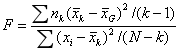 ,即将多个样本之间的均方差(组间均方差)除以样本内部的均方差(组内均方差)。(其中
,即将多个样本之间的均方差(组间均方差)除以样本内部的均方差(组内均方差)。(其中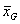 是总均值,
是总均值,![]() ,k是样本数量,N是k个样本的总观察值的数量)
,k是样本数量,N是k个样本的总观察值的数量)
方差分析的前提:总体需要满足正态性和方差齐性。如果总体方差不齐,可以用Welch's ANOVA,具体请见:http://www.real-statistics.com/one-way-analysis-of-variance-anova/welchs-procedure/。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号