分类模型的性能评价指标(Classification Model Performance Evaluation Metric)
二分类模型的预测结果分为四种情况(正类为1,反类为0):
- TP(True Positive):预测为正类,且预测正确(真实为1,预测也为1)
- FP(False Positive):预测为正类,但预测错误(真实为0,预测为1)
- TN(True Negative):预测为负类,且预测正确(真实为0,预测也为0)
- FN(False Negative):预测为负类,但预测错误(真实为1,预测为0)
TP+FP+TN+FN=测试集所有样本数量。
分类模型的性能评价指标(Performance Evaluation Metric)有:
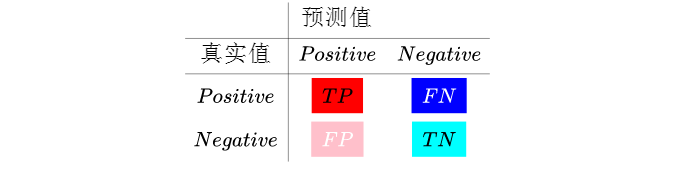
准确率(Accuracy):所有分类正确的样本数量除以总样本数量
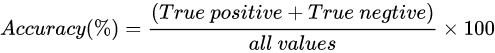
错误率(Error Rate):所有分类错误的样本数量除以总样本数量
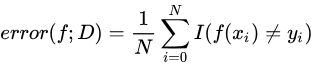 (其中
(其中为指示函数,满足要求则为1,不满足为0)
错误率等于一减准确率:。
混淆矩阵(Confusion Matrix):把真实值和预测值相对应的样本数量列出来的一张交叉表。这样,所有正确的预测结果都在其对角线上,所以从混淆矩阵中可以很直观地看出哪里有错误。


准确率或错误率是最基本的分类模型性能评价指标。但是有时候各类别样本数量不均衡,比如说,在一共100个测试样本中,正类样本有98个,负类样本只有2个,那么我们只需要把模型做成把所有样本都判为正类即可,这样准确率可以达到98%。但是这样的模型毫无意义。
即使各类别样本数量比较均衡,但如果我们更关心其中某个类别,那么我们就需要选择我们感兴趣的类别的各项指标来评价模型的好坏。因此,人们又发明出了查全率和查准率等指标。
精确度(Precision):在所有预测为正类的样本中,预测正确的比例,也称为查准率

召回率(Recall):在所有实际为正类的样本中,预测正确的比例,也称为查全率
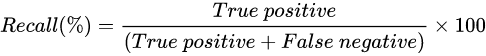
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。如果对这两个指标都有要求,那么可以计算模型的F1值或查看PR曲线。
F1值(F1 Score):查准率和查全率的调和平均值
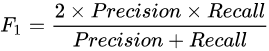
P-R曲线(Precision-Recall Curve):以precision为y轴,以recall为x轴,取不同的分类阈值,在此基础上画出来的一条曲线就叫做PR曲线。PR曲线越接近右上角(precision=1, recall=1),代表模型越好。若一个模型的PR曲线被另一个模型的PR曲线完全“包住”,则可断言后者的性能优于前者;但若二者的曲线发生了交叉,则难以一般性地断言两者孰优孰劣,只能在具体查准率或查全率条件下比较。一般而言,比较 P-R 曲线下面积的大小,可一定程度上表征模型在查准率和查全率上取得相对 “双高”的比例,但该值不太容易计算。因此其它相对容易计算的性能度量被提出。
真正率(True Positive Rate,TPR):TPR = TP/(TP+FN),TPR越大越好,1为理想状态
假正率(False Positive Rate,FPR):FPR = FP/(TN+FP),FPR越小越好,0为理想状态
灵敏性(Sensitivity): True Positive Rate,等同于召回率
特异性(Specificity): True Negative Rate,Specificity = 1- False Positive Rate,SPC = TN/(FP + TN)
这几个性能指标不受不均衡数据的影响。若要综合考虑TPR和FPR,那么可以查看ROC曲线。
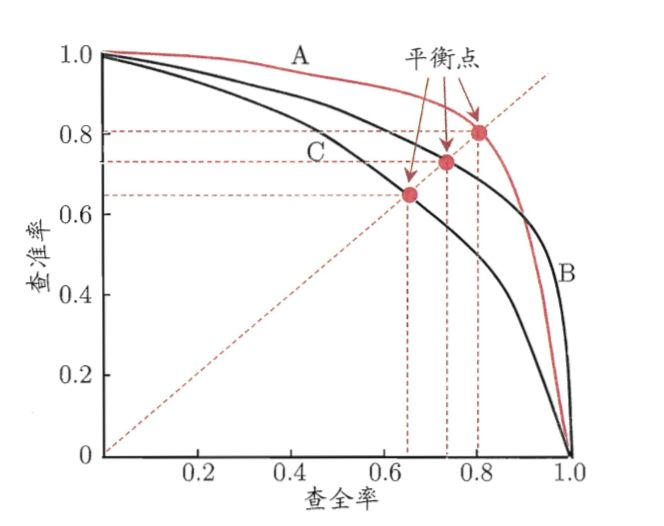
ROC曲线(Receiver Operating Characteristic Curve):全称“受试者工作特征”曲线。以“真正率”(True Positivate Rate,简称 TPR)为y轴,以“假正例”(False Positive Rate,简称 FPR)为x轴,取不同的分类阈值,在此基础上画出来的一条曲线就叫做ROC曲线。ROC曲线越接近左上角(true positive rate=1, false positive rate=0),代表模型性能越好。与 P-R 曲线一样,若一个模型的 ROC 曲线被另一个模型的曲线完全“包住”,则断言后者的性能优于前者;若有交叉,则难以一般断言,此时可通过比较ROC曲线下的面积来判断。
AUC(Area Under Curve):曲线下面积。AUC越大,代表模型性能越好。若AUC=0.5,即ROC曲线与上图中的虚线重合,表示模型的区分能力与随机猜测没有差别。
以上说的是二分类的场景。对于多分类问题,有两种方法计算其性能评价指标:
方法一:将多分类问题拆解成n个一对其余的二分类问题,这样可以得到n个混淆矩阵,分别计算出每个类别的precision和recall,再将其平均,即得到”宏查准率“(macro-P),”宏查全率“(macro-R),相应计算出的的F1值称为”宏F1“(macro-F1)。对每个类别计算出样本在各个阈值下的假正率(FPR)和真正率(TPR),从而绘制出一条ROC曲线,这样总共可以绘制出n条ROC曲线,对n条ROC曲线取平均,即可得到最终的ROC曲线。

方法二:将多分类问题拆解成n个一对其余的二分类问题,这样可以得到n个混淆矩阵,把所有混淆矩阵中的TP,NP,FP,FN计算平均值 ,再用这些平均值计算出查准率和查全率,称为”微查准率“(micro-P),”微查全率“(micro-R),由微查准率和微查全率计算出的F1值称为 ”微 F1“(micro-F1)。
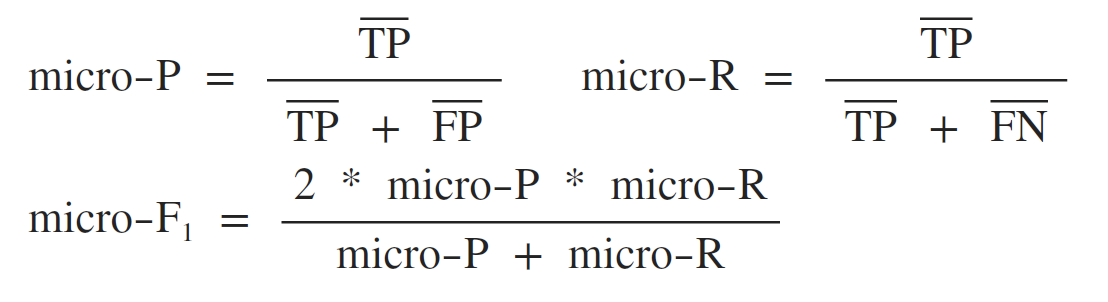
对于多分类问题,macro-average(宏平均) 要比 micro-average(微平均) 好,因为宏平均受样本数量少的类别影响较大。
参考:https://www.zhihu.com/question/30643044

 浙公网安备 33010602011771号
浙公网安备 33010602011771号