Matplotlib学习---用matplotlib画误差线(errorbar)
误差线用于显示数据的不确定程度,误差一般使用标准差(Standard Deviation)或标准误差(Standard Error)。
标准差(SD):是方差的算术平方根。如果是总体标准差,那么用σ表示,如果是样本标准差,那么用s表示。标准差反映数据集的离散程度,标准差越小,就说明数据越集中在其平均值附近。公式:![]() (总体),
(总体),![{\displaystyle s={\sqrt {\frac {\sum _{i=1}^{N}(x_{i}-{\overline {x}})^{2}}{N-1}}}.}]() (样本)
(样本)
 (总体),
(总体), (样本)
(样本)标准误差(SE):是样本分布的标准差。如果是样本平均数分布的标准差,那么就称为SEM(standard error of the mean),就是说每次从总体中抽取n个样本,抽取很多次后,每次抽样的平均值(![]() )就形成了一个数据分布,这个数据分布有自己的平均值和标准差。抽样的平均值分布的平均数应该接近总体平均数( μ)。标准误差反映样本(sample)对于总体(population)的差异性,每次抽样的样本数越多,标准误差就越小。公式:
)就形成了一个数据分布,这个数据分布有自己的平均值和标准差。抽样的平均值分布的平均数应该接近总体平均数( μ)。标准误差反映样本(sample)对于总体(population)的差异性,每次抽样的样本数越多,标准误差就越小。公式:![{\displaystyle {\sigma }_{\bar {x}}\ ={\frac {\sigma }{\sqrt {n}}}}]()

下面利用Nathan Yau所著的《鲜活的数据:数据可视化指南》一书中的数据,学习画图。
数据地址:http://datasets.flowingdata.com/crimeRatesByState2005.csv
以下是这个数据文件的前5行:
state murder forcible_rape robbery aggravated_assault \ 0 United States 5.6 31.7 140.7 291.1 1 Alabama 8.2 34.3 141.4 247.8 2 Alaska 4.8 81.1 80.9 465.1 3 Arizona 7.5 33.8 144.4 327.4 4 Arkansas 6.7 42.9 91.1 386.8 burglary larceny_theft motor_vehicle_theft population 0 726.7 2286.3 416.7 295753151 1 953.8 2650.0 288.3 4545049 2 622.5 2599.1 391.0 669488 3 948.4 2965.2 924.4 5974834 4 1084.6 2711.2 262.1 2776221
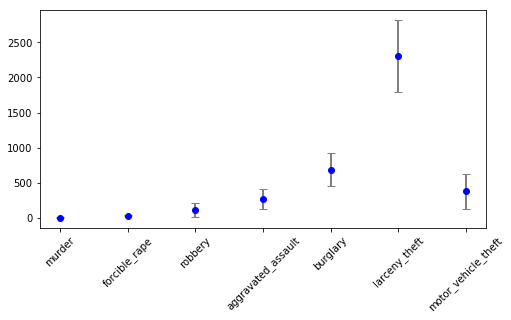
这是美国各州各种犯罪行为的发生率(每10万人口)。
让我们画一个图,把全美各犯罪率的平均数,标准差展现出来。
误差线: ax.errorbar(x,y,yerr=error size in y axis,xerr=error size in x axis)
代码如下:
import numpy as np import pandas as pd from matplotlib import pyplot as plt crime=pd.read_csv(r"http://datasets.flowingdata.com/crimeRatesByState2005.csv") fig,ax=plt.subplots(figsize=(8,4)) col=crime.columns.astype(str) #提取列名,将来做x轴刻度标签 crime=crime[1:] #把第一行US的数据去除 data=crime.loc[:,"murder":"motor_vehicle_theft"] #提取数据部分,以便将来进行计算 crime.loc["mean"]=data.apply(np.mean) #增加一行,为数据每列的均值,apply函数用于数据每一列 crime.loc["standard deviation"]=data.apply(np.std) #增加一行,为数据每列的标准差,apply函数用于数据每一列 #画误差线,x轴一共7项,y轴显示平均值,y轴误差为标准差 ax.errorbar(np.arange(7),crime.loc["mean","murder":"motor_vehicle_theft"],\ yerr=crime.loc["standard deviation","murder":"motor_vehicle_theft"],\ fmt="o",color="blue",ecolor='grey',elinewidth=2,capsize=4) ax.set_xticklabels(col,rotation=45) #设置x轴刻度标签,并使其倾斜45度,不至于重叠 plt.show()
图像如下:
另外,还可以在柱形图或条形图上画误差线,分别在ax.bar命令里加上yerr参数,或在ax.barh命令里加上xerr参数即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号