random模块
# 随机数模块
import random
# 返回0到1之间的随机小数
print(random.random()) # 0.6502700763969521
# 返回1到6之间的随机整数 掷色子游戏
print(random.randint(1,6)) # 3
# 随机抽选一个列表内的值
print(random.choice(['月薪30000','月薪99999','年薪百万'])) # 年薪百万
# 随机抽样 样本数自定义
print(random.sample(['月薪19999','离家近','早点毕业','买房全款','做梦都能笑醒'],3)) # ['做梦都能笑醒', '买房全款', '早点毕业']
# 随机顺序(洗牌) 扑克牌
l1 = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A', '大王', '小王']
random.shuffle(l1)
print(l1) # ['A', '大王', 9, 10, 'J', '小王', 4, 6, 5, 7, 3, 8, 'Q', 2, 'K']
随机数面试题
# 编写python代码 产生五位随机验证码(数字、小写字母、大写字母)
eg1:
import random
# 先定义一个全局变量
code = ''
for i in range(5):
# 每次循环产生小写字母大写字母数字
res1 = str(random.randint(0,9))
res2 = chr(random.randint(97,122)) # 随机小写字母
res3 = chr(random.randint(65,90)) # 随机大写字母
random_num = random.choice([res1,res2,res3])
code += random_num
print(code) # 4W1XH
------------
eg2:
import random
def get_num(n):
code = ''
for i in range(n):
# 每次循环产生小写字母大写字母数字
res1 = str(random.randint(0, 9))
res2 = chr(random.randint(97, 122)) # 随机小写字母
res3 = chr(random.randint(65, 90)) # 随机大写字母
random_num = random.choice([res1, res2, res3])
code += random_num
return code
num = get_num(5)
print(num) # IMXS8
num2 = get_num(10)
print(num2) # EB9g4C22oZ
# 包装成函数的好处就是可以指定获得想要获取的随机数个数
hashlib模块
加密模块介绍
1.什么是加密
将明文数据(看得懂)经过处理之后变成密文数据(看不懂)的过程
2.为什么要加密
不想让敏感的数据轻易的泄露
3.如何判断当前数据值是否已经加密
一般情况下如果是一串没有规则的数字字母符合的组合一般都是加密之后的结果
4.加密算法
就是对明文数据采用的加密策略
不同的加密算法复杂度不一样 得出的结果长短也不一样
通常情况下加密之后的结果越长 说明采用的加密算法越复杂
5.常见加密算法
md5 sha系列 hmac base64
模块案例
import hashlib
# 选择md5加密算法为数据加密
md5 = hashlib.md5()
# 往里面添加明文数据必须是bytes类型
md5.update(b'summer321')
# 获取加密之后的结果
res = md5.hexdigest()
print(res) # b7ed228b1d60a0407fec036da0e1e953
****加密之后的结果一般情况下不能反解密**
加密的三种方式
目的是为了让密文安全性更高
1.分段加密
import hashlib
md5 = hashlib.md5()
md5.update(b'hello')
md5.update(b'summer')
md5.update(b'321')
res = md5.hexdigest()
print(res) # 4b88fd1da2ae23f2fea719cadbed100e
# 只要明文数据是一样的那么采用相同的算法得出的密文肯定一样
md5.update(b'hellosummer321')
res = md5.hexdigest()
print(res) # 4b88fd1da2ae23f2fea719cadbed100e
------------
2.加盐处理
password = input('password>>>:').strip()
md5.update('公司设置的盐(干扰项)'.encode('utf8'))
md5.update(password.encode('utf8'))
res = md5.hexdigest()
print(res) # c82d34f999874af5a72f1a7ef72de0eb
------------
3.动态加盐
干扰项每次都不一样
eg:每次获取当前时间 每个用户用户名截取一段
加密常见应用场景
1.用户密码加密
注册存储密文 登录也是比对密文
2.文件安全性校验
正规的软件程序写完之后做一个内容的加密
网址提供软件文件记忆该文件内容对应的密文
用户下载完成后不直接运行 而是对下载的内容做加密
然后比对两次密文是否一致 如果一致表示文件没有被改
不一致则表示改程序有可能被植入病毒
3.大文件加密优化
程序文件100G
一般情况下读取100G内容然后全部加密 太慢
不对100G所有的内容加密 而是截取一部分加密
eg:每隔500M读取30bytes
# 获取文件bytes数
import os
os.path.getsize()
subprocess模块
# 模拟计算机cmd命令窗口
import subprocess
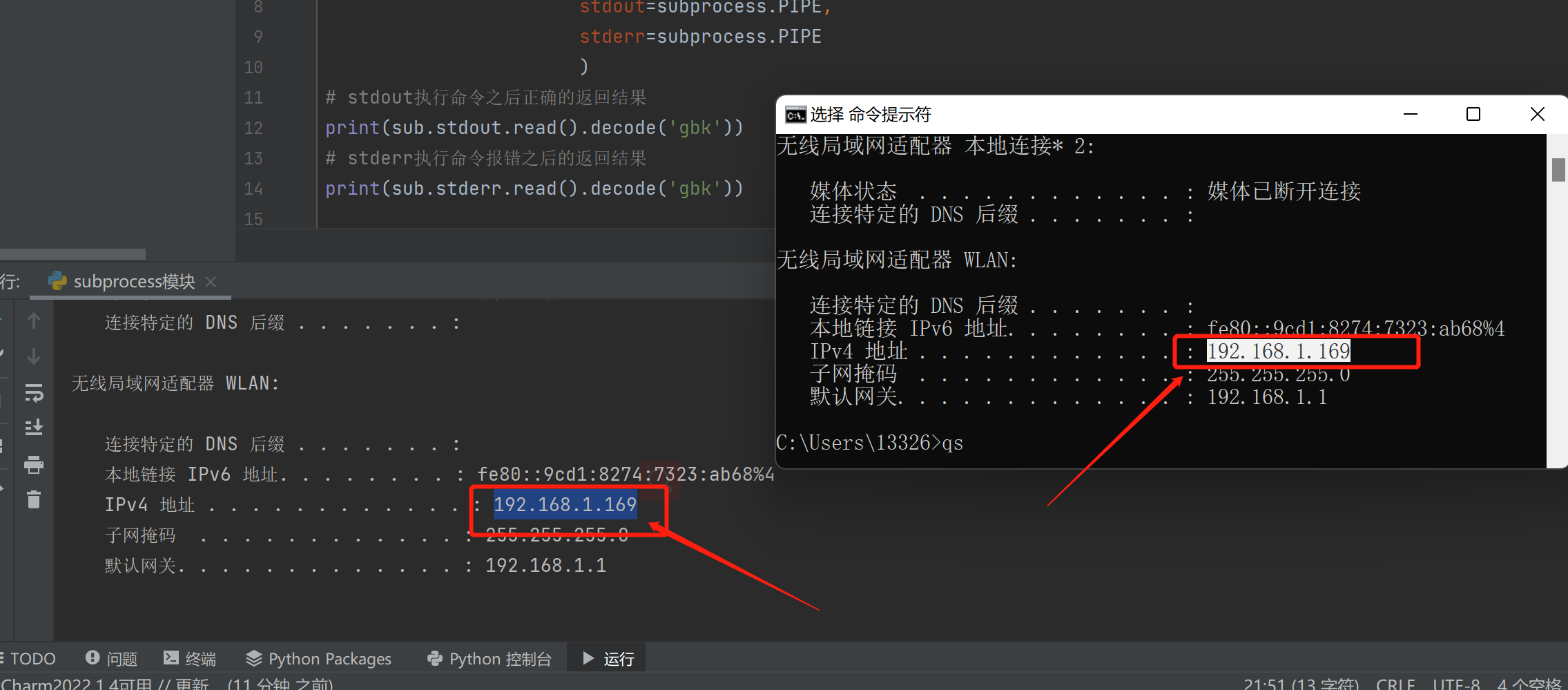
cmd = input('请输入您的指令>>>:').strip() # ipconfig
sub = subprocess.Popen(cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
# stdout执行命令之后正确的返回结果
print(sub.stdout.read().decode('gbk'))
# stderr执行命令报错之后的返回结果
print(sub.stderr.read().decode('gbk'))
![image]()
logging模块
logging模块说明
1.什么是日志
日志就类似于是历史记录
2.为什么要使用日志
为了记录事物发生的事实(史官)
3.如何使用日志
3.1.日志等级
import logging
logging.debug('debug等级') # 10
logging.info('info等级') # 20
logging.warning('warning等级') # 30 默认从warning级别开始记录日志
logging.error('error等级') # 40
logging.critical('critical等级') # 50
模块使用
import logging
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('我不好!!!')
![image]()
日志模块组成
import logging
# 1.日志的产生(准备原材料) logger对象
logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) format对象
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('写了半天 好累啊 好热啊')
![image]()
![image]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号