对解决粘包问题的理解
【一】什么是粘包问题
- 想象你正在通过一条很窄的管道(网络连接)发送一串珠子(数据包)。在管道的另一端,有人(接收方)正在接收这些珠子。为了让对方知道每串珠子的开始和结束,你决定在每串珠子之间放一小块纸条(数据包的边界标记)。
- 但是,如果这些珠子和纸条在管道中相互挤压,可能会导致纸条丢失或珠子串连在一起,使得接收方无法区分哪些珠子是一组。这就好比在网络传输过程中,原本独立的数据包因为紧密相连,而在接收端被误认为是一个连续的数据流,这就是所谓的“粘包”。
- 在现实的网络通信中,由于TCP协议是基于流的,它只保证数据的顺序和完整性,而不保证数据包之间的界限。因此,如果发送方连续快速发送多个数据包,接收方可能会一次性接收到这些数据包的合并结果,而无法区分它们原来的界限。这就需要通过某些机制(如在每个数据包前添加长度信息)来明确标记数据包的界限,以避免粘包问题。
【二】TCP协议解决粘包问题思路
-
将数据拆分出来一个头部,头部内容写了数据的大小,以及其他信息
-
这里以一个传输视频的功能作为例子
-
服务端
# 创建对象
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定IP,端口
server.bind(('127.0.0.1', 8080))
# 创建半连接池
server.listen(5)
# 获取连接对象
obj, addr = server.accept()
# 接收文件名
file_name = obj.recv(1024).decode('utf8')
# 由一个字典装头部信息
header = {
'file_name': file_name, # 文件名称
'file_size': os.path.getsize(file_name) # 文件大小
}
# 用json把header变成json字符串格式
header_json = json.dumps(header)
# 转换成二进制
header_bytes = header_json.encode('utf-8')
# 计算头部长度
header_h = bytes(str(len(header_bytes)).encode('utf8')).zfill(2)
# 发送头部长度给客户端
obj.send(header_h)
# 发送头部数据给客户端
obj.send(header_bytes)
with open(file_name, 'rb') as fp:
data = fp.read()
obj.send(data)
obj.close()
server.close()
- 客户端
import socket
import json
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
file_name = input('请输入文件名:>>>>').strip()
client.send(file_name.encode('utf8'))
new_file_name = f'new_{file_name}'
header_size = int(client.recv(2).decode('utf8'))
header_json = client.recv(header_size).decode('utf8')
header = json.loads(header_json)
file_size = header.get('file_size')
res_size = 0
with open(new_file_name, 'wb') as fp:
while res_size < file_size:
data = client.recv(1024)
fp.write(data)
res_size += len(data)
client.close()
- 服务端将文件的信息如文件名,文件大小存放在字典里作为头部信息
- 并且把头部的长度也发送给客户端
- 客户端收到头部的长度后,再继续以头部的长度精准接收到头部信息,也就是服务端发送的第二个内容
- 然后客户端再起一个变量来记录收到数据的大小,直到收到数据的大小等于头部信息里面的文件大小,才会断开连接
- 这样就解决了粘包问题
【三】远程执行命令案例
- 服务端
import socket
import struct
import subprocess
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('127.0.0.1', 8080))
server.listen(5)
coon, addr = server.accept()
cmd = coon.recv(1024).decode('utf-8')
obj = subprocess.Popen(
cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
data_true = obj.stdout.read() # gbk编码的二进制格式
data_false = obj.stderr.read()
data_len = len(data_true) + len(data_false)
header = struct.pack('i', data_len)
coon.send(header)
coon.send(data_true)
coon.send(data_false)
coon.close()
server.close()
- 客户端
import socket
import struct
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
cmd = input('请输入命令:>>>>').strip().encode('utf-8')
client.send(cmd)
header = client.recv(4)
data_len = struct.unpack('i', header)[0]
data_from_server = b''
res_len = 0
while res_len < data_len:
data = client.recv(1024)
data_from_server += data
res_len += len(data)
print(data_from_server.decode('gbk'))
client.close()
- 这个案例用到了struct模块,利用这个模块打包的特性,将发送给客户端的结果打包在一个长度为4的包里面
- 在客户端就可以准确的接收长度为4的包,再进行解包,得到真实数据的长度
- 最后在进行迭代输出数据,以此解决粘包问题
【四】struct模块补充
-
struct.pack()是Python内置模块
struct中的一个函数
- 它的作用是将指定的数据按照指定的格式进行打包,并将打包后的结果转换成一个字节序列(byte string)
- 可以用于在网络上传输或者储存于文件中。
-
struct.pack(fmt, v1, v2, ...)- 其中,
fmt为格式字符串,指定了需要打包的数据的格式,后面的v1,v2,...则是需要打包的数据。 - 这些数据会按照
fmt的格式被编码成二进制的字节串,并返回这个字节串。
- 其中,
-
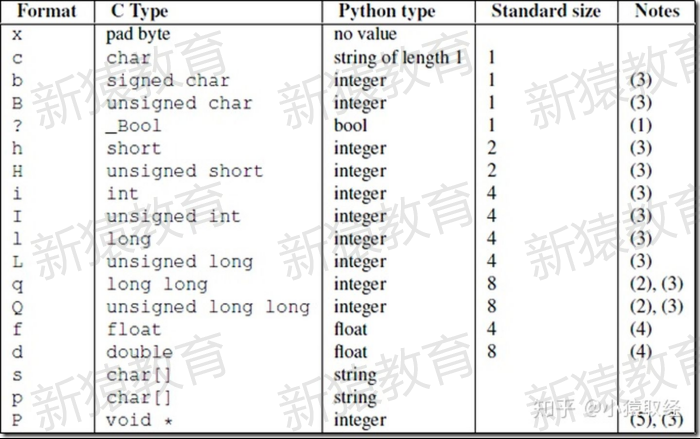
fmt的常用格式符如下:
x--- 填充字节c--- char类型,占1字节b--- signed char类型,占1字节B--- unsigned char类型,占1字节h--- short类型,占2字节H--- unsigned short类型,占2字节i--- int类型,占4字节I--- unsigned int类型,占4字节l--- long类型,占4字节(32位机器上)或者8字节(64位机器上)L--- unsigned long类型,占4字节(32位机器上)或者8字节(64位机器上)q--- long long类型,占8字节Q--- unsigned long long类型,占8字节f--- float类型,占4字节d--- double类型,占8字节s--- char[]类型,占指定字节个数,需要用数字指定长度p--- char[]类型,跟s一样,但通常用来表示字符串?--- bool类型,占1字节
-
具体的格式化规则可以在Python文档中查看(链接)。
import json
import struct
# 为避免粘包,必须自定制报头
# 1T数据,文件路径和md5值
header = {'file_size': 1073741824000, 'file_name': '/a/b/c/d/e/a.txt',
'md5': '8f6fbf8347faa4924a76856701edb0f3'}
# 为了该报头能传送,需要序列化并且转为bytes
# 序列化并转成bytes,用于传输
head_bytes = bytes(json.dumps(header), encoding='utf-8')
# 为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节
# 这4个字节里只包含了一个数字,该数字是报头的长度
head_len_bytes = struct.pack('i', len(head_bytes))
print(f"这是原本的数据 :>>>> {header}")
print(f"这是json序列化后的数据 :>>>> {head_bytes}")
print(f"这是压缩后的数据 :>>>> {head_len_bytes}")
# 这是原本的数据 :>>>> {'file_size': 1073741824000, 'file_name': '/a/b/c/d/e/a.txt', 'md5': '8f6fbf8347faa4924a76856701edb0f3'}
# 这是json序列化后的数据 :>>>> b'{"file_size": 1073741824000, "file_name": "/a/b/c/d/e/a.txt", "md5": "8f6fbf8347faa4924a76856701edb0f3"}'
# 这是压缩后的数据 :>>>> b'h\x00\x00\x00'




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!