

3分钟带你彻底搞懂Java泛型背后的秘密
转载自:《Java之间》
这一节主要讲的内容是java中泛型的应用,通过该篇让大家更好地理解泛型,以及面试中经常说的泛型类型擦除是什么概念,今天就带着这几个问题一起看下:
举一个简单的例子:
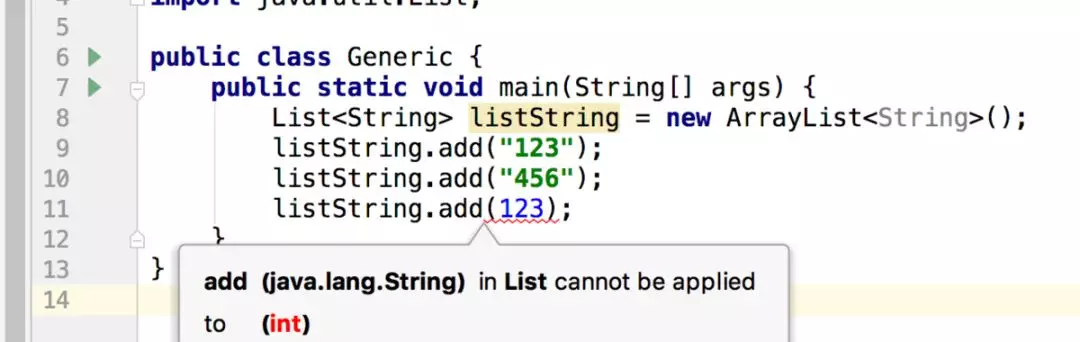
这里可以看出来在代码编写阶段就已经报错了,不能往string类型的集合中添加int类型的数据。
那可不可以往List集合中添加多个类型的数据呢,答案是可以的,其实我们可以把list集合当成普通的类也是没问题的,那么就有下面的代码:
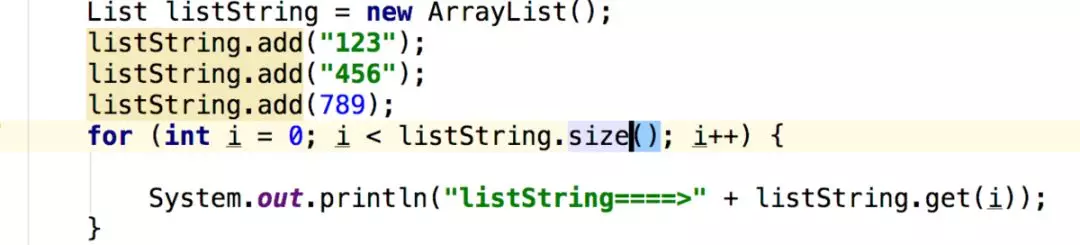
从这里可以看出来,不定义泛型也是可以往集合中添加数据的,所以说 泛型只是一种类型的规范,在代码编写阶段起一种限制。
下面我们通过例子来介绍泛型背后数据是什么类型
public class BaseBean<T> {
T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
上面定义了一个泛型的类,然后我们通过反射获取属性和getValue方法返回的数据类型:
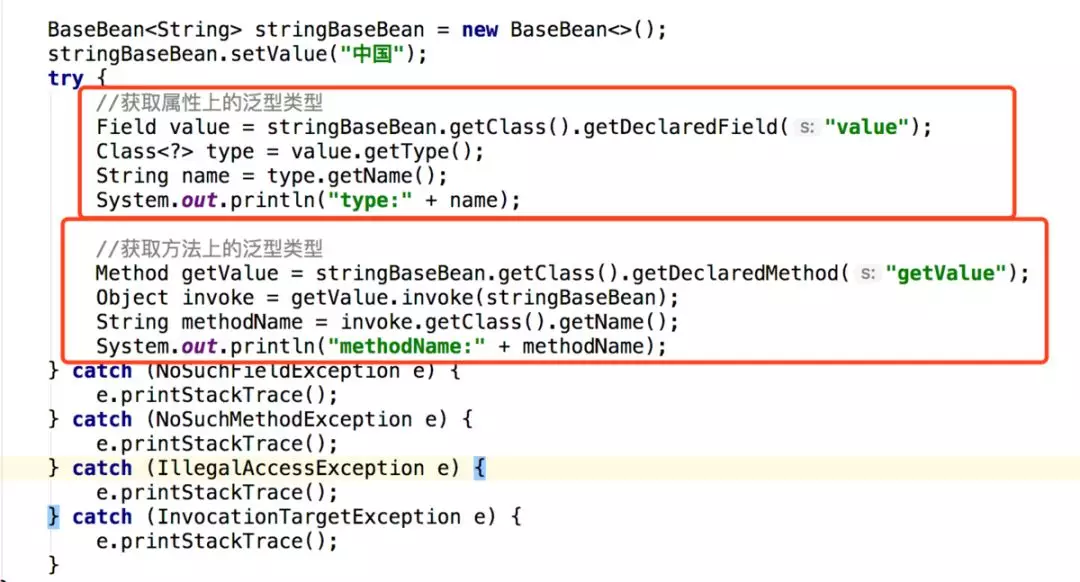
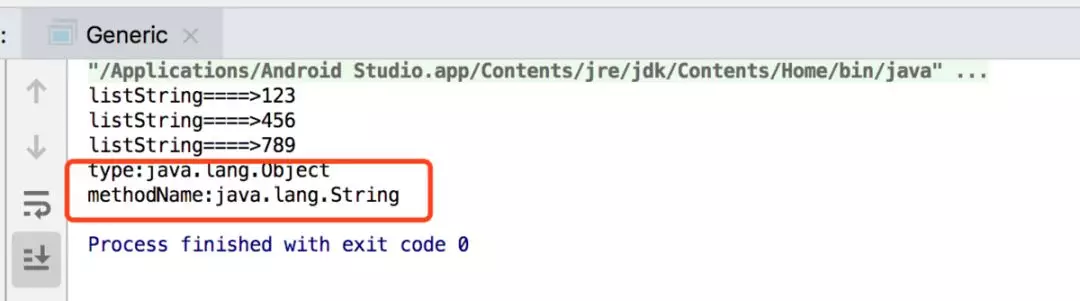
从日志上看到通过反射获取到的属性是Object类型的,在方法中返回的是string类型,因此咋们可以思考在getValue方法里面实际是做了个强转的动作,将object类型的value强转成string类型。是的,没错,因为泛型只是为了约束我们规范代码,而对于编译完之后的class交给虚拟机后,对于虚拟机它是没有泛型的说法的,所有的泛型在它看来都是object类型,因此泛型擦除是对于虚拟机而言的。
下面我们再来看一种泛型结构:
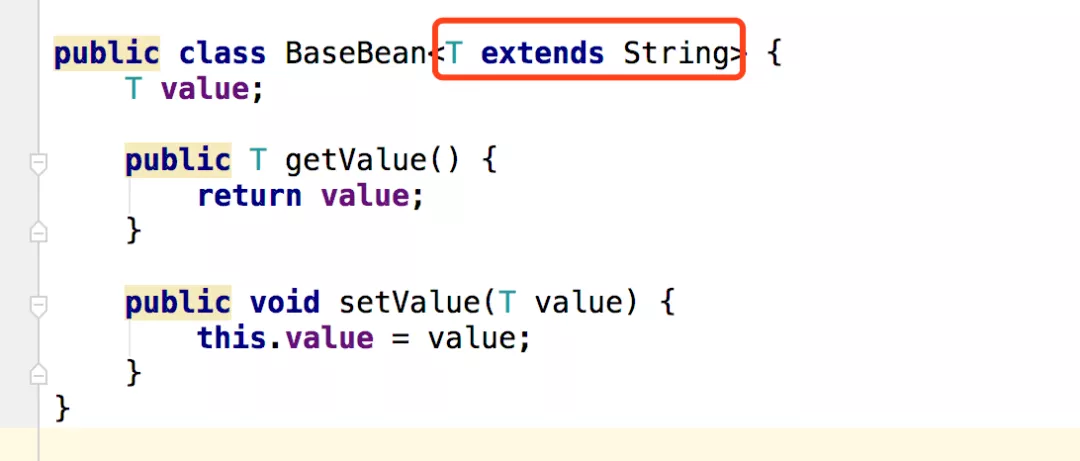
这里我将泛型加了个关键字extends,对于泛型写得多的伙伴们来说,extends是约束了泛型是向下继承的,最后我们通过反射获取value的类型是String类型的,因此这里也不难看出,加extends关键字其实最终目的是约束泛型是属于哪一类的。所以我们在编写代码的时候如果没有向下兼容类型,会警告错误的:

大家有没有想过为啥要用泛型呢,既然说了泛型其实对于jvm来说都是Object类型的,那咱们直接将类型定义成Object不就是的了,这种做法是可以,但是在拿到Object类型值之后,自己还得强转,因此泛型减少了代码的强转工作,而将这些工作交给了虚拟机。
比如下面我们没有定义泛型的例子:

势必在getValue的时候代码有个强转的过程,因此在能用泛型的时候,尽量用泛型来写,而且我认为一个好的架构师,业务的抽取是离不开泛型的定义。
常见的泛型主要有作用在普通类上面,
作用在抽象类、接口、静态或非静态方法上。
类上面的泛型
比如实际项目中,我们经常会遇到服务端返回的接口中都有errMsg、status等公共返回信息,而变动的数据结构是data信息,因此我们可以抽取公共的BaseBean:
public class BaseBean<T> {
public String errMsg;
public T data;
public int status;
}
抽象类或接口上的泛型
//抽象类泛型
public abstract class BaseAdapter<T> {
List<T> DATAS;
}
//接口泛型
public interface Factory<T> {
T create();
}
//方法泛型
public static <T> T getData() {
return null;
}
多元泛型
public interface Base<K, V> {
void setKey(K k);
V getValue();
}
泛型二级抽象类或接口
public interface BaseCommon<K extends Common1, V> extends Base<K, V> {
}
//或抽象类
public abstract class BaseCommon<K extends Common1, V> implements Base<K, V> {
}
抽象里面包含抽象
public interface Base<K, V> {
// void setKey(K k);
//
// V getValue();
void addNode(Map<K, V> map);
Map<K, V> getNode(int index);
}
public abstract class BaseCommon<K, V> implements Base<K, V> {
//多重泛型
LinkedList<Map<K, V>> DATAS = new LinkedList<>();
@Override
public void addNode(Map<K, V> map) {
DATAS.addLast(map);
}
@Override
public Map<K, V> getNode(int index) {
return DATAS.get(index);
}
}
<?>通配符
通配符和//定义了一个普通类
public class BaseBean<T> {
T value;
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
//用来定义泛型的
public class Common1 extends Common {
}
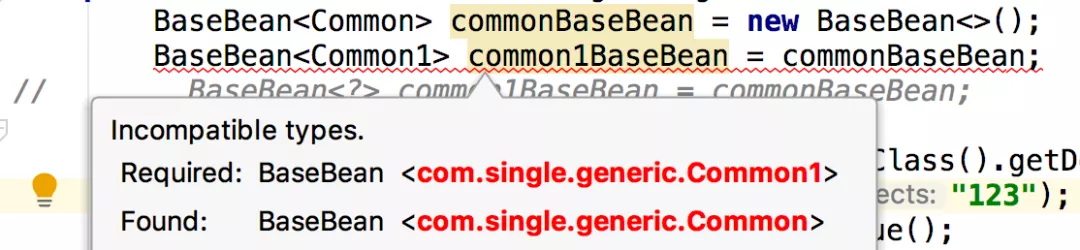
在定义的时候将Common的泛型指向Common1的泛型,可以看到直接提示有问题,这里可以想,虽然Common1是继承自Common的,但是并不代表BaseBean之间是等量的,在开篇也讲过,如果泛型传入的是什么类型,那么在BaseBean中的getValue返回的类型就是什么,因此可以想两个不同的泛型类肯定是不等价的,但是如果我这里写呢:
public static void main(String[] args) {
BaseBean<Common> commonBaseBean = new BaseBean<>();
//通配符定义就没有问题
BaseBean<?> common1BaseBean = commonBaseBean;
try {
//通过反射猜测setValue的参数是Object类型的
Method setValue = common1BaseBean.getClass().getDeclaredMethod("setValue", Object.class);
setValue.invoke(common1BaseBean, "123");
Object value = common1BaseBean.getValue();
System.out.println("result:" + value);
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
在上面如果定义的泛型是通配符是可以等价的,因为此时的setValue的参数是Object类型,所以能直接将上面定义的泛型赋给通配符的BaseBean。
通配符不能定义在类上面、接口或方法上,只能作用在方法的参数上
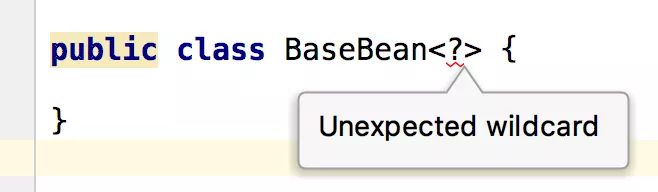
其他的几种情况自己去尝试,正确的使用通配符:
public void setClass(Class<?> class){
//todo
}
<T extends **>表示上限泛型、<T super **>表示下限泛型
为了演示这两个通配符的作用,增加了一个类:

//新增加的一个BaseCommon
public class Common extends BaseCommon{
}

第二个定义的泛型是不合法的,因为BaseCommon是Common的父类,超出了Common的类型范围。
在BaseBean里面定义了个方法:
public void add(Class<? super Common> clazz) {
}

可以看到当传进去的是Common1.class的时候是不合法的,因为在add方法中需要传入Common父类的字节码对象,而Common1是继承自Common,所以直接不合法。
在实际开发中其实知道什么时候定义什么类型的泛型就ok,在mvp实际案例中泛型用得比较广泛,大家可以根据实际项目来找找泛型的感觉,只是面试的时候需要理解类型擦除是针对谁而言的。
类型擦除
其实在开篇的时候已经通过例子说明了,通过反射绕开泛型的定义,也说明了类中定义的泛型最终是以Object被jvm执行。所有的泛型在jvm中执行的时候,都是以Object对象存在的,加泛型只是为了一种代码的规范,避免了开发过程中再次强转。
泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号