剑指Offer_#38_字符串的排列(LeetCode#47_全排列 II)
剑指Offer_#38_字符串的排列(LeetCode#47_全排列 II)
Contents
题目
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
示例:
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]限制:
1 <= s 的长度 <= 8思路分析
全排列
根据高中数学学过的排列组合相关知识,n个元素的所有排列数是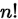 。
。
推导思路很简单,就是一位一位地去固定元素,第1个位置有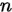 种可能,第2个位置有
种可能,第2个位置有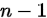 种可能,...最后1位有一种可能。把这些乘起来就得到
种可能,...最后1位有一种可能。把这些乘起来就得到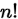 。
。
这个思路可以直接应用到这题上面,下图很好的展示了这个思路。

得到所有排列的过程
- 先固定第1位,有3个选择:与自己交换(即保持不变),与第2位交换,与第3位交换
- 然后固定第2位,有2个选择:与自己交换,与第3位交换
- 固定最后一位,只有1个选择:与自己交换。因为前面2个位置已经固定,最后1位只能是剩下的那个
总结规律
这是一个递归的过程
- 递推过程
- 每一次需要将当前位置字符和后面的所有字符交换
- 每一次待固定的位置向后移一位
- 终止条件
- 当固定到最后一位的时候,得到一个排列
重复字符的处理
设想输入的字符串当中包含了重复字符的情况,那么最后得到的结果也会有重复。如何解决这一问题呢?
设当前位置的字符为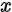 ,在当前位置与后边所有位的字符交换位置,假如在这个范围内(从当前位置到末尾的范围),有两个相同的字符
,在当前位置与后边所有位的字符交换位置,假如在这个范围内(从当前位置到末尾的范围),有两个相同的字符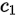 和
和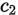 ,那么
,那么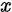 与
与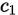 和
和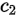 进行交换的结果是一样的。
进行交换的结果是一样的。
所以当第二次遇到某个字符时,就不必要再进行交换了,这个过程就是剪枝,下图很好的展示了这个过程。

代码实现:
维护一个HashSet变量,每次将遇到的字符存入,第二次遇到相同字符时,跳过本轮循环。
方法1:交换元素
这种方法感觉技巧性较强,作为参考。
class Solution {
List<String> res = new LinkedList<>();
char[] c;
public String[] permutation(String s) {
c = s.toCharArray();
recur(0);
//参数是为了指定返回数组的类型String[res.size()]
return res.toArray(new String[res.size()]);
}
//在x位置处尝试所有可能的字符(和后边的所有字符交换位置)
void recur(int x){
//终止条件
if(x == c.length - 1){
res.add(String.valueOf(c));
//递归终止
return;
}
HashSet<Character> set = new HashSet<>();
//递推过程:将x后面的所有字符交换到x处
for(int i = x;i <= c.length - 1;i++){
//在循环中,如果遇到重复字符,剪枝
if(set.contains(c[i])) continue;
//不是重复字符,则继续
set.add(c[i]);
swap(i,x);
//开启递归子函数,去尝试下一位的所有可能
recur(x+1);
//恢复交换
swap(i,x);
}
}
//交换索引indexA和索引indexB位置的字符
void swap(int indexA,int indexB){
char tmp = c[indexA];
c[indexA] = c[indexB];
c[indexB] = tmp;
}
}方法2:全排列II
相比方法1,这种写法更为通用,复习时优先记忆/练习这种方法。
这题和全排列II很相似,实测以下代码可以通过。
class Solution {
List<String> res = new ArrayList<>();
public String[] permutation(String s) {
char[] array = s.toCharArray();
Arrays.sort(array);
StringBuilder perm = new StringBuilder();
boolean[] visited = new boolean[s.length()];
backtrack(perm, array, visited);
return (String[])res.toArray(new String[res.size()]);
}
private void backtrack(StringBuilder perm, char[] array, boolean[] visited){
if(perm.length() == array.length) res.add(new String(perm));
for(int i = 0; i < array.length; i++){
if(visited[i]) continue;
if(i > 0 && array[i] == array[i - 1] && !visited[i - 1]) continue;
perm.append(array[i]);
visited[i] = true;
backtrack(perm, array, visited);
perm.deleteCharAt(perm.length() - 1);
visited[i] = false;
}
}
}上述方法中需要提前对数组排序,使得相同字母放到一起,相当于增加了一个排序的时间复杂度。
受到方法1代码的启发,我们可以用HashSet进行剪枝。
class Solution {
List<String> res = new ArrayList<>();
public String[] permutation(String s) {
char[] array = s.toCharArray();
StringBuilder perm = new StringBuilder();
boolean[] visited = new boolean[s.length()];
backtrack(perm, array, visited);
return (String[])res.toArray(new String[res.size()]);
}
private void backtrack(StringBuilder perm, char[] array, boolean[] visited){
if(perm.length() == array.length) res.add(new String(perm));
HashSet<Character> set = new HashSet<>();
for(int i = 0; i < array.length; i++){
if(visited[i]) continue;
if(set.contains(array[i])) continue;
perm.append(array[i]);
visited[i] = true;
set.add(array[i]);
backtrack(perm, array, visited);
perm.deleteCharAt(perm.length() - 1);
visited[i] = false;
}
}
}方法3:HashSet暴力去重(不推荐)
最简单的方法是直接用HashSet存储所有的结果,最后自然是不包含重复元素的,但是这样做效率很低,相当于在决策树当中把一些本不应该遍历的路径都遍历了一遍。
class Solution2 {
public static void main(String[] args) {
String[] res = new Solution2().permutation("aab");
for(String s: res) System.out.println(s);
}
public String[] permutation(String s) {
Set<String> list = new HashSet<>();
char[] arr = s.toCharArray();
boolean[] visited = new boolean[arr.length];
dfs(arr, "", visited, list);
return list.toArray(new String[0]);
}
public void dfs(char[] arr, String s, boolean[] visited, Set<String> list) {
if (s.length() == arr.length) {
list.add(s);
return;
}
for (int i = 0; i < arr.length; i++) {
if (visited[i]) continue;
visited[i] = true;
//这里很有意思的一点是,s是不可变的,通过字符串拼接的方式,并不会改变s,所以不需要写撤销选择的语句
dfs(arr, s + arr[i], visited, list);
visited[i] = false;
}
}
}总结
本题的难点在于对决策树当中可能出现重复排列的情况进行剪枝。剪枝分为两个部分:
- 不同层当中,同一元素只被选择一次,之后如果再出现,就剪枝。
- 方法:使用
visited[]数组标记每个元素是否已经被选择过了,记得递归调用之后要进行撤销选择。
- 方法:使用
- 同层当中,值相同的元素(值相同但可能不是同一个元素,比如aab当中的前两个a)只出现一次,第二次之后出现就被剪枝。
- 方法1:先对原始数组排序,然后利用
if(i > 0 && array[i] == array[i - 1] && !visited[i - 1]) continue;
进行剪枝,这个条件的意思是,array[i]是重复出现的,并且i-1元素并没有在更上层出现过,说明这两个元素出现在同层,而非是情况1 - 方法2:HashSet
每次进入一层的决策的for循环之前,新建一个HashSet,每次选择元素之后加入到HashSet,之后如果遇到重复的,就跳过本轮循环。由于这个HashSet不作为递归调用参数传入下一层递归,所以也没必要进行撤销选择。
- 方法1:先对原始数组排序,然后利用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号