李宏毅2022机器学习CP1-9
第一讲、机器学习概念
一、直观理解
机器学习≈寻找一个人类写不出来的复杂函数。比如声音识别、图像识别,人无法描述出这样的函数,所以需要机器学习完成这个任务。
二、深度学习
机器学习的子类,函数为类神经网络,其输入为vector、matrix(e.g.图片)、sequence(e.g.音频);其输出为scalar(即regression)、classes(即classification,e.g.是否垃圾邮件,下围棋 )、text or image。
- 有监督学习
- 自监督学习(需要pre-train)
- 无监督学习
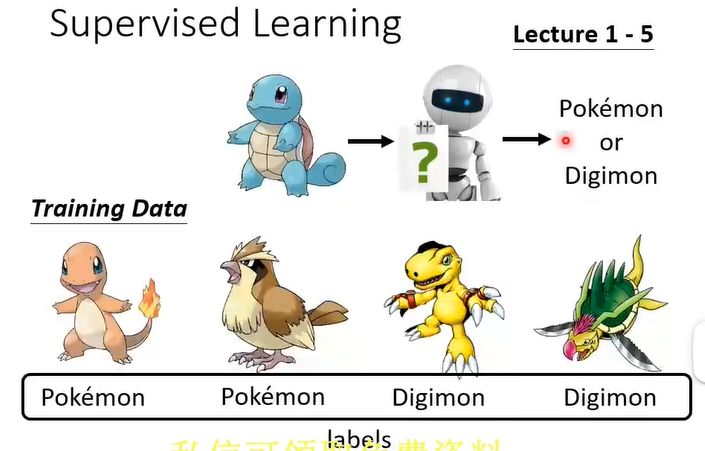
疑问:在有监督学习时,比如我们要判断是自行车还是小汽车,它们具有明显的特征区别,人工给予label后,机器通过学习不同的特征就可以分别出来,但是宝可梦和数码宝贝也具有明显的这种区别吗?
解释:宝可梦是动物风格,数码宝贝是机甲风格。
三、机器学习步骤
(一)、Function with unknown & (二)、Define Loss from training data
如果函数为 \(y=b+wx\),则Loss为 \(L(b,w)\)(括号里为未知参数)。比如做N次预测,可取
对于\(e_n\),可以用如\(MAE:e=\left\vert y-\hat{y} \right\vert\)或者\(MSE:e=(y-\hat{y})^2\)。
由于定义方式不同,Loss可以为负。疑问 什么情况为负?解答:交叉熵?
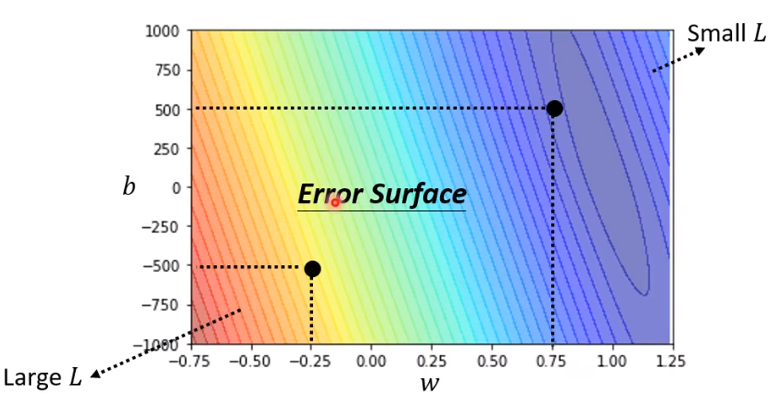
且可以取不同的b和w,做出一个b-w图,从而直观看出哪组值最好。
(三)、Optimization
找出最好的一组w和b。(假设w为横坐标,loss为纵坐标,只有一个参数w)(两个参数则求偏导)
方法 梯度下降Gradient Descent
-
(1)随机选一个值 (2)计算微分,为负则Increase w,为正则Decrease w,而增大或减小的幅度由斜率大小和设定的学习率learning rate确定。(3)更新w,直到微分为0.
超参数 batch,epoch,update
疑问:学习率可以设置多个吗?对每一个参数都单独设置一个学习率?
解释:是的,在下文中就用到了,不同的参数设置不同的学习率。
-
缺点是找到的可能是局部最小值local minima,而不是全局最小值global minima.
四、更复杂的函数
Linear model不能满足所有情况,此时需要更复杂的函数,比如用piecewise linear curve(曲线可以用直线近似)叠加。
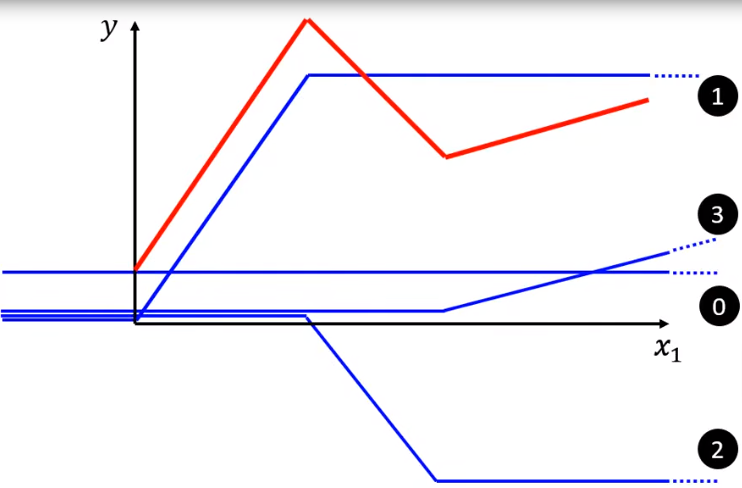
而上面的蓝色曲线可用sigmoid函数表示。
- Sigmoid函数(重要 学完后面再来反复理解下列过程)
(疑问:c为1,b为0,w为1时是Sigmoid函数?)
通过改变c,b,w可以得到不同的形状:
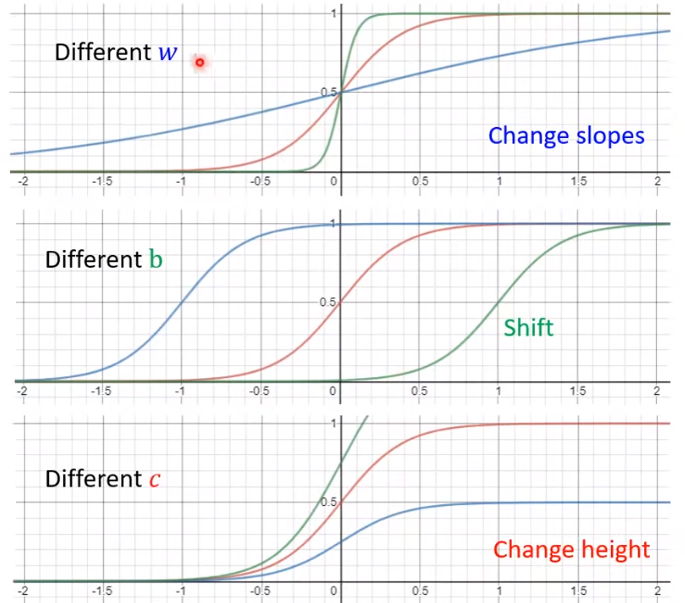
上面的红色曲线,可以用四条(或更多)蓝色曲线合成(其中三个sigmoid函数,一个constant<图片中b>)
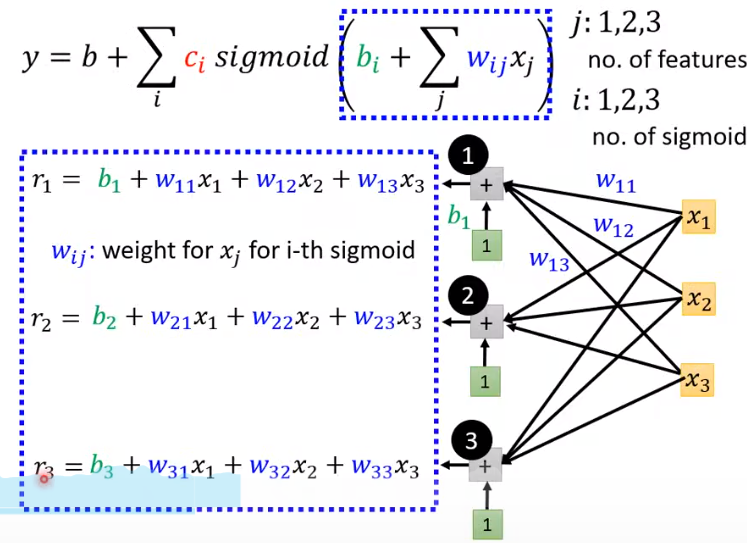

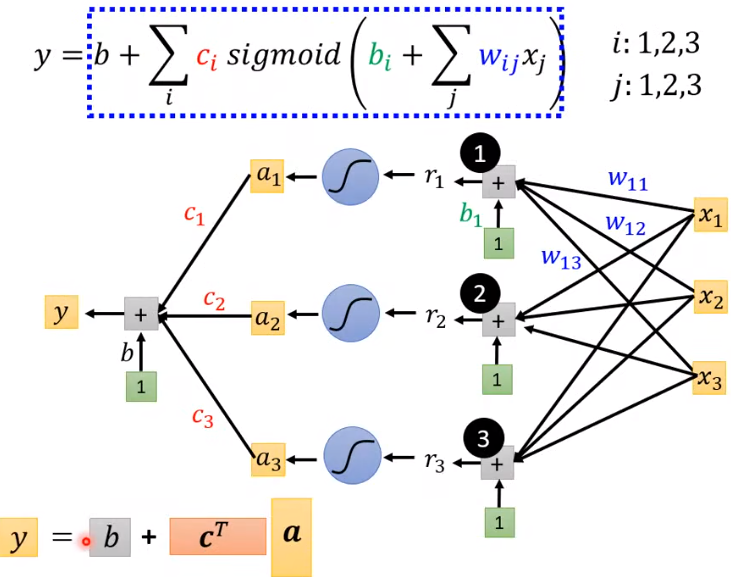
绿色的方框里为1,这样使得\(b_i\)和\(w_{ij}\)处于同样地位,都是超参数,总不能绿方框里放\(b_i\)。在后面的Neural Network里面都是同样的做法。
- ReLU函数
这里的sigmoid也可以换成max,也就是ReLU函数。它们都是激活函数Activation function。
疑问:什么是hard sigmoid?
将上图中的\(a\) 视为 \(x\) ,再套一层,即再加一层layer。这就是神经网络Neural Network。而更多的layers意味着deep,即深度学习Deep Learning。
注意: layers并不是越多越好,可能过拟合Overfitting(训练集上表现好,预测集上表现不好;与之相反是欠拟合Underfitting)
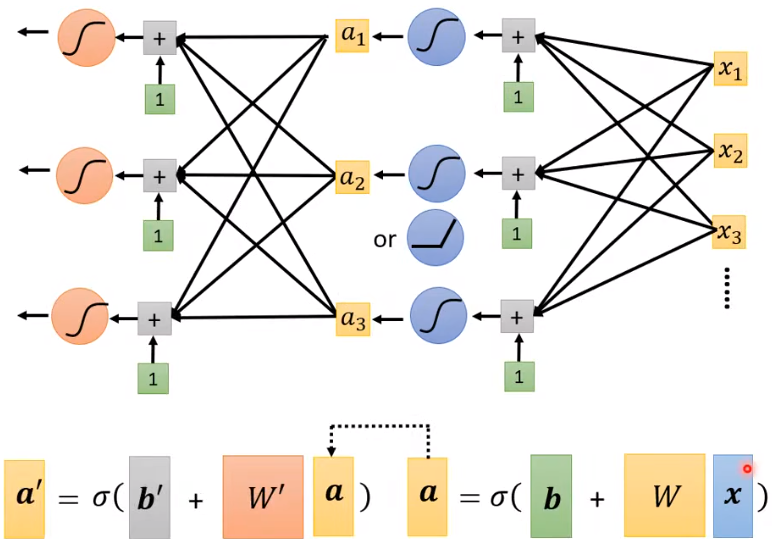
疑问:大概知道如何做,但不知道为什么要这样做:为什么加layer效果会更好呢?
第二讲、模型的优化
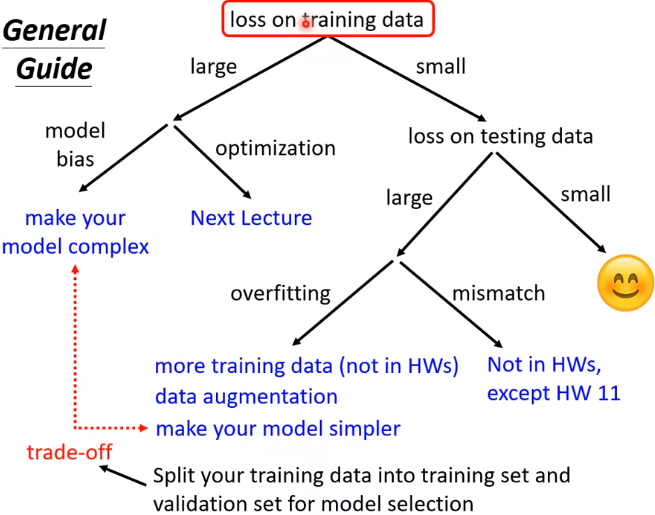
一、Loss不够小
(一)可能性一
疑问:什么是模型弹性?model bias是什么?
-
Model bias:原因:model太小。解决方法:增加feature(增大弹性),从而囊括最优解(针不在海里)
-
Optimization:原因:可能得到了局部最优而不是全局最优(针在海里但捞不到)解决方法:见下文
问:如何判断是model bias还是optimization issue?
答:下图中训练集上56层的弹性明明比20层更大(因为多出的36层什么也不做就可以达到20层的效果),它不可能做不到20层可以做到的事,结果它的loss反而更大,说明这不是过拟合,是optimization issue。
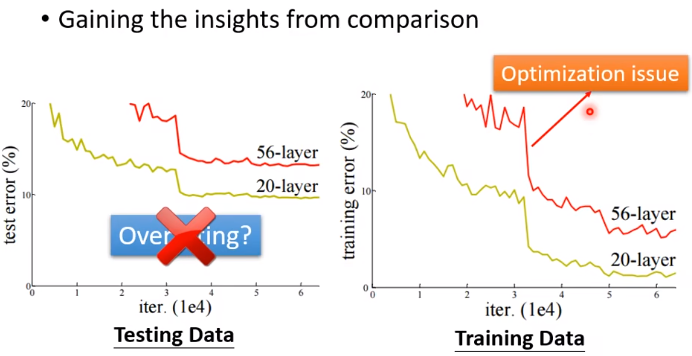
(二)可能性二
Overfitting:模型的参数越多,弹性越大,越可能overfitting。判断:training data的loss小,testing data的loss大(上面第二个图的两条线交换)
-
比如训练集\((x^i,\hat y^i)\),预测 \(f(x)=\begin{cases}\hat y^i &\exists x^i=x\\randown&\text{otherwise}\end{cases}\),此时函数有 zero training loss,but large testing loss,这是一个“一无是处的模型”。
注解:这门课程中正确值是\(\hat y\),而预测值是\(y\)。可能与其他地方表示不同。
判断时不能一看testing data的loss大,就觉得是overfitting,还要看training data
解决办法:(1)增加训练集More training data (2)数据增强Data augmentation<比如对图像左右翻转,裁剪,但不会上下颠倒> (3)限制模型弹性constrained model<比如知道模型是二次函数,则不用选择更复杂的模型> 方法:更少的参数、共享参数。(4)Less features<之前用3天的数据,现在用2天的数据> (5)Early stopping (6)Regularization (7)Dropout
注意: 不要限制太多,否则导致model bias。
注意: 也不能只看在public testing set上的得分来选模型,不然就算一个“一无是处的模型”也可能得到非常好的结果,但是在private testing set上就不行了。理想上不用public testing set,而是在training set里面分出一部分做test。
由此引出:
二、Cross Validation
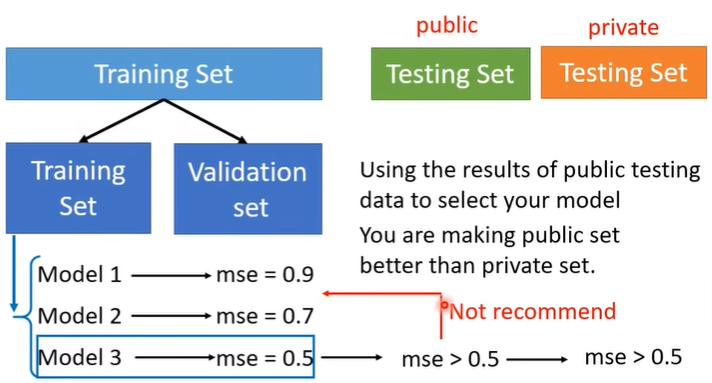
分原training set为training set和validation set时,可以采用k折交叉验证k-fold Cross Validation,即将原training set分成k份,每个模型都要跑遍所有的划分情况。
三、Optimization issue的原因
(一)critical point临界点的可能情况
-
Local minima
没办法了...(实际上很多时候并不是真的Local minima)
-
Saddle point
可以escape,因为周围还有路,可以让loss更低。
(二)如何判断critical point的类型
要判断,则需要知道loss function的形状,对于临界点\(L(\theta)\),可以用泰勒展开来近似得到该点周围的函数表达。
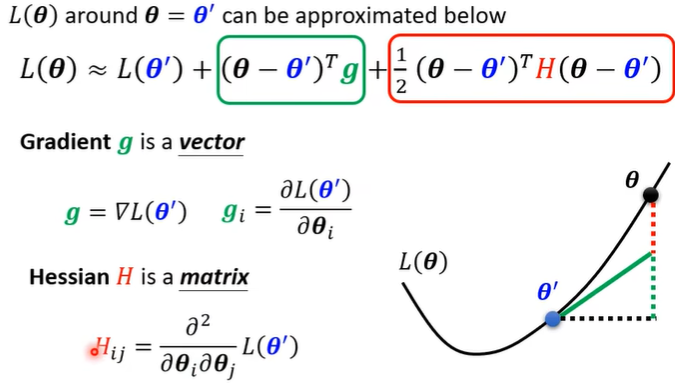
当在临界点时,绿色框为0:
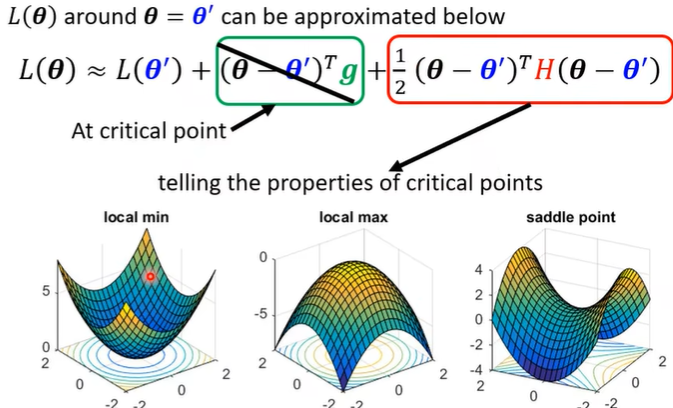
可以根据 \(v^THv\) 来判断是哪种点,实际上就是判断 $H $ 的正定情况。

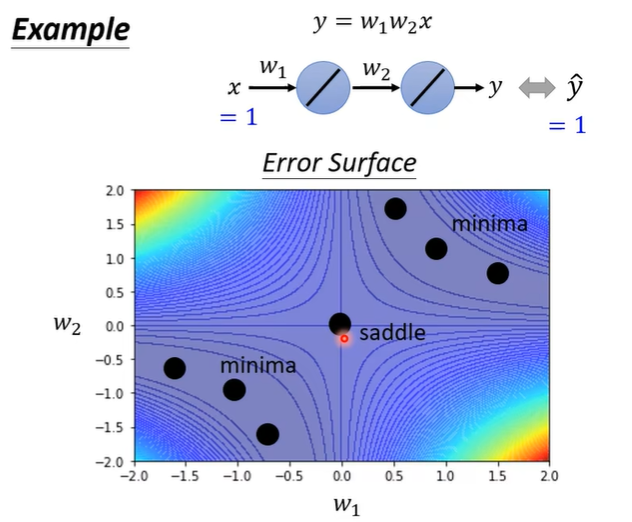
疑问1:如何看出来这六个点是minima的?
解释1:看等高线密度。以下方三个点为例,左下侧等高线和右上侧等高线都更密,loss更大。
(三)如何解决Saddle point问题(重要)

注意:这里的“绿色框”表示 \(\lambda\) 是 \(H\) 的特征值,且与 \(u\) 对应。
注意:由于这种方法计算复杂,不常用。
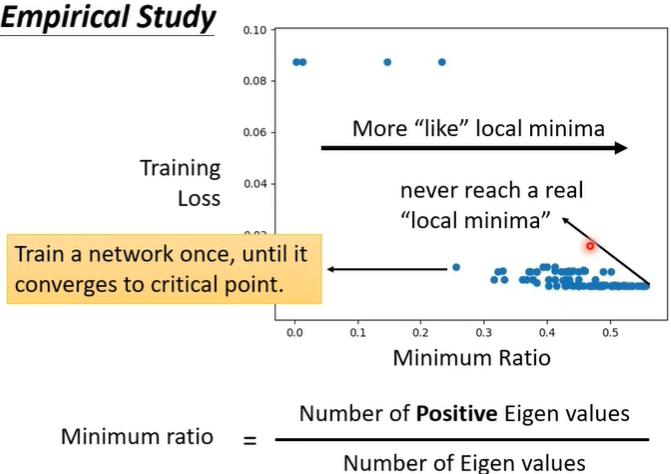
(四)Empirical Study
实际研究中,往往是更像local minima,而不是真的local minima。
Minimum ratio往往只会到0.5,而到1时才为真的local minima。
三、Optimization with Batch...
(一)Batch
update时不是用整个data,而是分成多个batch,依次计算每个batch的gradient进行更新,每计算完一轮,为一个epoch,并且下一个epoch要重新shuffle。
- 直观上以为batch size大的时候一个epoch需要的时间长

- 但是实际上,由于平行计算,batch size大的时候需要时间不一定就更长,
疑问:如何进行平行计算的?
- 反而一般来说,batch size小的时候,一个epoch需要的时间反而更长(它的一个update需要的时间短)
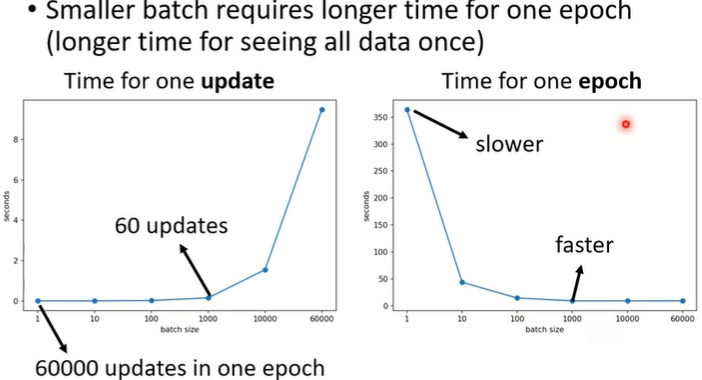
综上,大的Batch size在时间上并不吃亏,也即不是真的“Long time”。
所以,Batch size越大就越好吗?并不是。
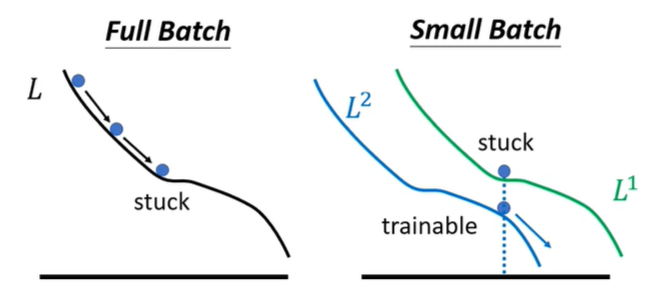
- 因为小的batch size反而有更高的Accuracy准确度。因为它有多条路去Gradient Decent,在某一个Loss stuck的时候,下一个batch在该参数处不一定stuck。
两者对比
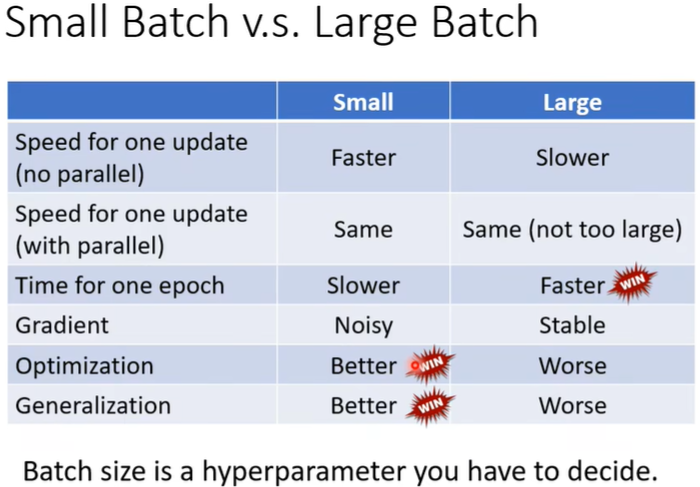
(二)Momentum
-
梯度下降通常为普通Vanilla Gradient Descent。
每计算完一个gradient,往它的反方向去update。
-
进阶为Vanilla Gradient+Momentum(当下的gradient+一个偏移值)
即反方向移动时加上一个movement of last step minus gradient at president。
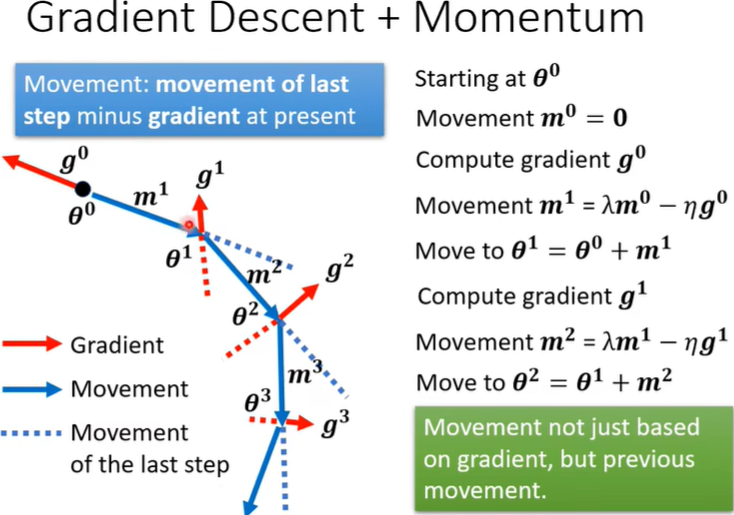
更通俗的解释:动量Momentum推动梯度下降法越过critical point。
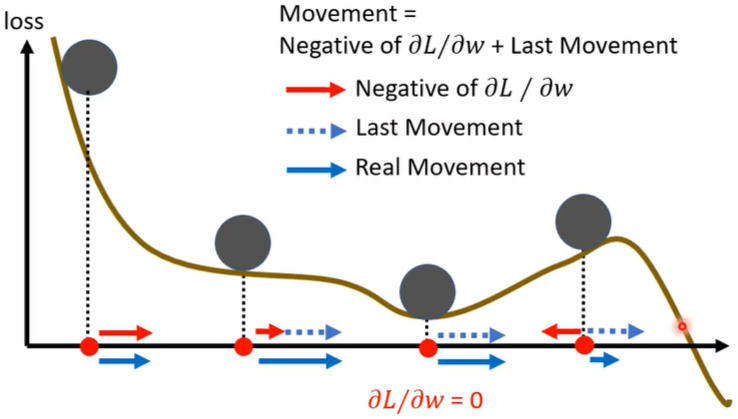
(三)Learning Rate
-
人工设置存在的问题
有时候根本就到达不了critical point,因为gradient descent步子太大(learning rate较大决定步子大)每次都跨过critical point。但是learning rate太小也不行,也会走不到critical point,如右图,因为每次迈的步子太小了。<\(\eta\) 为learning rate>
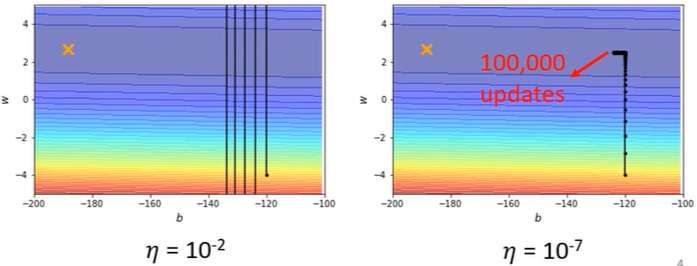
-
解决办法(疑问,关于具体如何设置学习率,如何变化?)
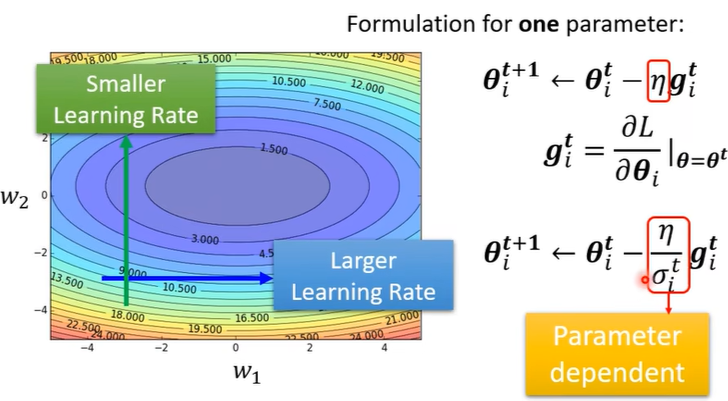
不同的参数设置不同的learning rate;同一个参数的learning rate也在变化!
t表示第t次iteration迭代,i表示第i个参数。\(\sigma_i^t\) 即为不同的参数设置不同的学习率。
-
求\(\sigma_i^t\) 的方法
(1)均方根Root Mean Square
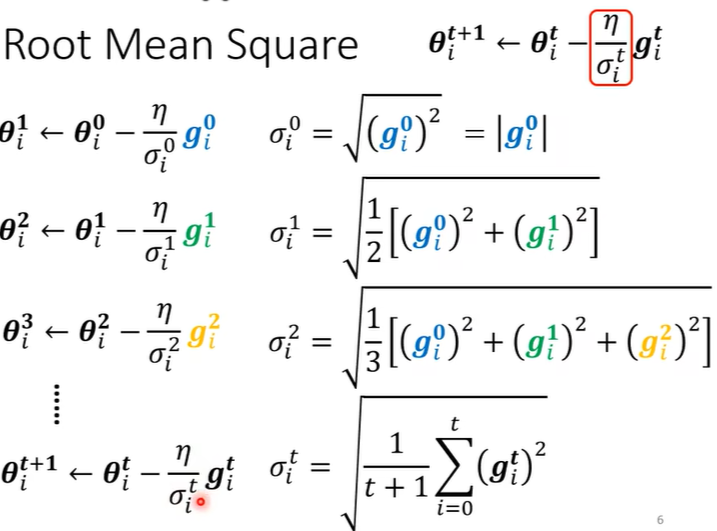
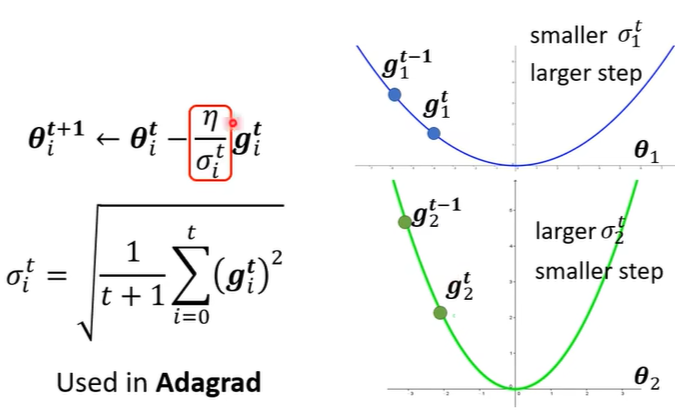
并且坡度大的时候learning rate减小,坡度小的时候learning rate增大,如下图。
此外,还有另一种方法,RMSProp。
(2)RMSProp
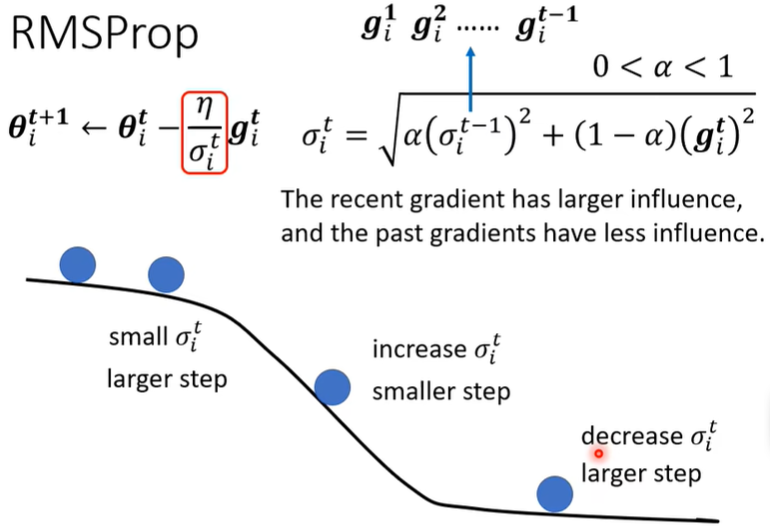
-
自适应学习率存在的问题(重要,疑问)
- learning rate可能会“爆炸”
解决办法:Learning Rate Scheduling
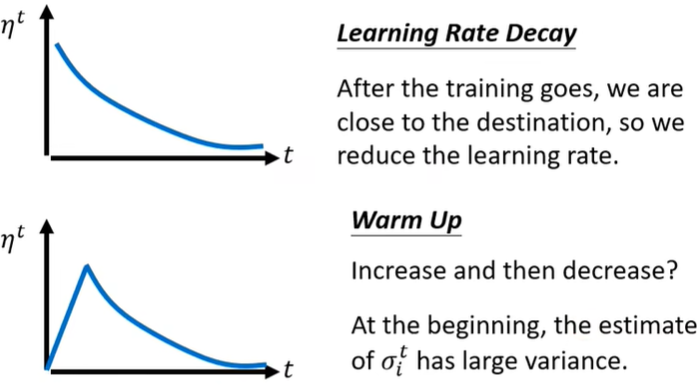
Bert、Transformer都用到Warm up。
(四)Classification issue
-
引言
(重要)遇到分类问题时,也可以当成回归问题来做,比如有3个class(下文均以此为例),数值化为1,2,3,但这种表示class的方式有时可能有非常严重的问题!!因为数值1和2之间的距离近,这是否意味着class 1和class 2之间更相似,class 1和class 3之间不那么相似呢?在class 1,2,3表示一、二、三年级时,这种设置可能说得过去,但是如果三种类别之间并没有关系,那么这样表示就不合适了!
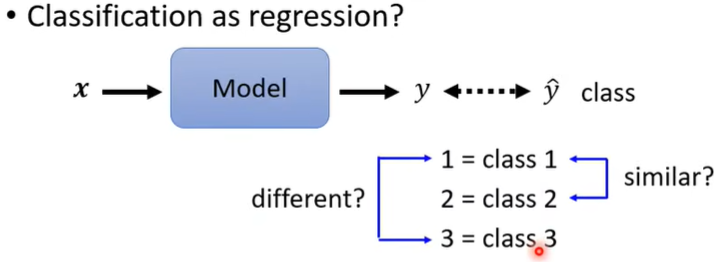
那怎么办呢?利用向量!
它们之间的距离一样!!!
解答:output三次,这样就是一个三维向量了。
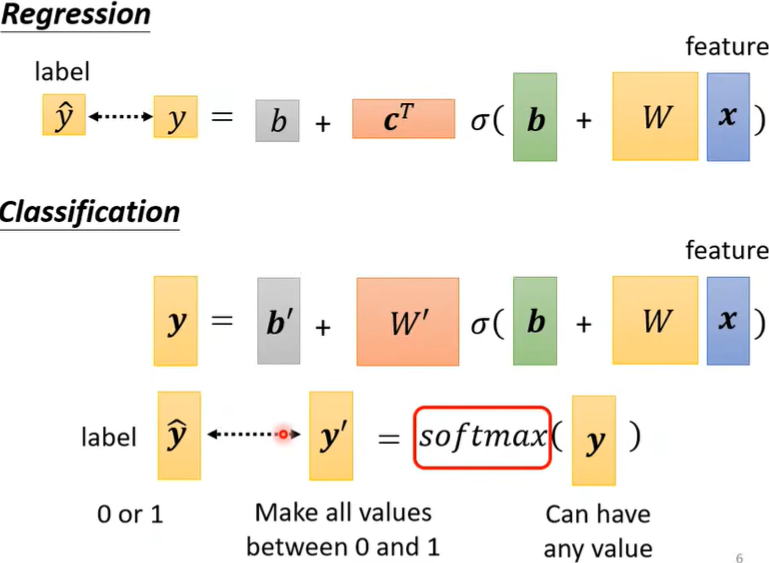
- Softmax函数
Softmax函数不仅进行了归一化,而且拉大了\(y_i\)间的差距。
两个class的时候可以直接Sigmoid,效果与套Softmax后一模一样。(疑问待推导)
-
Loss of Classification
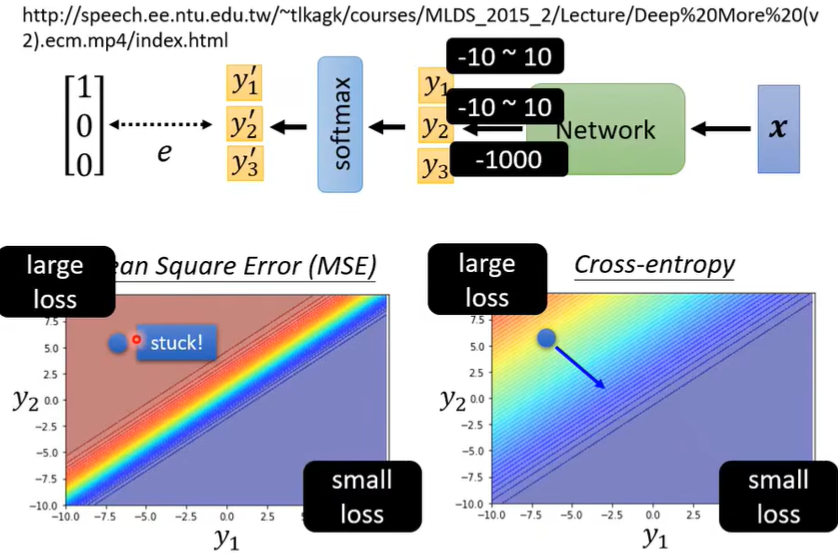
可以用MSE(\(e=\sum_i(\hat y_i-y_i')^2\)),更常用的是交叉熵Cross-entropy(\(e=-\sum_i \hat y_ilny_i'\))(是上面一张图里Classification的\(\hat y\) 和\(y'\))
Minimizing cross-entropy = maximizing likelihood
pytorch用cross-entropy时,已经自动加了一层softmax了。
注:为什么有时用Cross-entropy而不用MSE:
第三讲、CNN
[Designed for image]
一、简介
Convolution Neural Network,CNN,卷积神经网络。
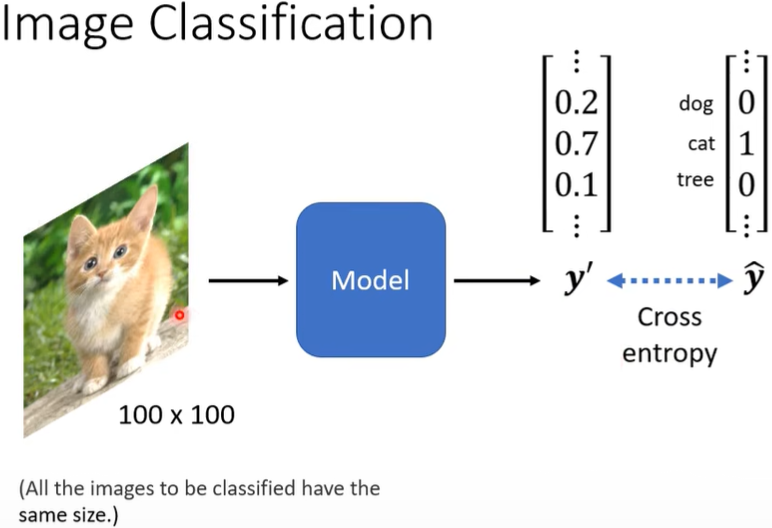
问:如何将图片信息输入模型?
答:假定图片的size相同,每图片由三层——RGB(即三个channel,注意黑白图片只有一层一个channel)构成,将每层拉直成一个向量,三个合成一个巨长的向量直接丢进模型。但每个neuron都要看整张图片,会导致模型异常复杂,参数非常多。因此有无简化的办法呢?
(一)简化1
让每个neuron只用关注整张图片的一小部分(可重叠)。
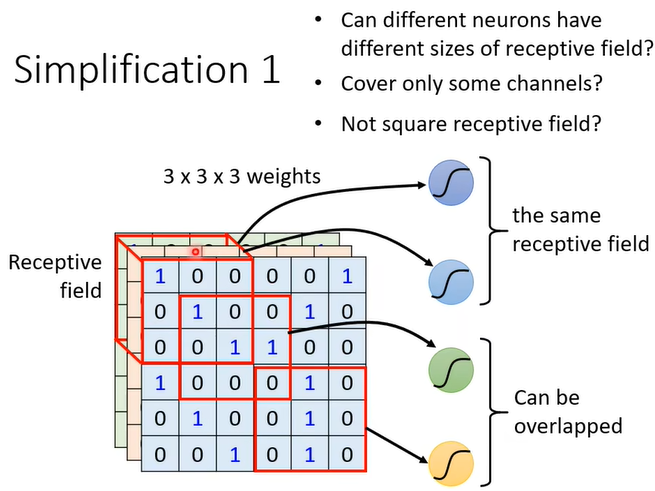
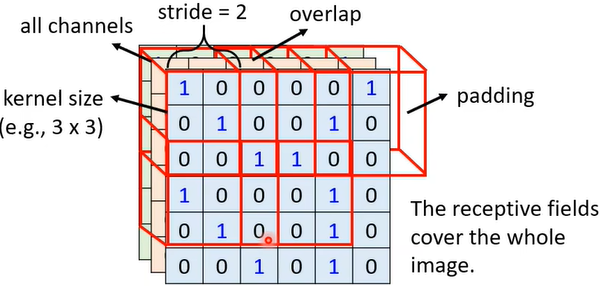
注意:通常Receptive field(or kernel size)为3×3,涵盖all channels。
注意:之所以有overlap重叠,是因为如果不重叠,那么若pattern刚好在两个receptive field的边界上,则就没有neuron能够完整侦测到了;当receptive field某边空白时,可以padding,其方法有多种,可以补0、均值等。
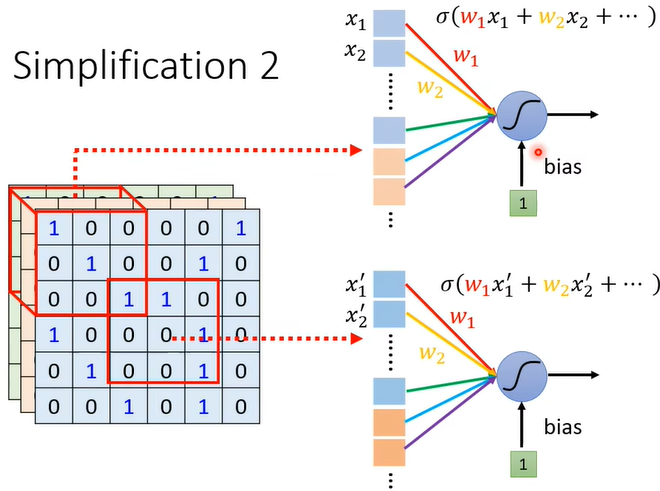
(二)简化2
鸟嘴可能会出现在不同的receptive field,需要让每个neuron都有侦测鸟嘴的功能吗?并不,neuron可以共享参数。并且由于每个neuron的输入不同,即使参数相同,输出也不会相同。
这种方法实践上是怎么运用的呢?
以下图为例,假设每个receptive field有64个neuron侦测(即彩色圈圈),每个receptive field共享一组参数,即对应的neuron参数相同(红对红,黄对黄...)。
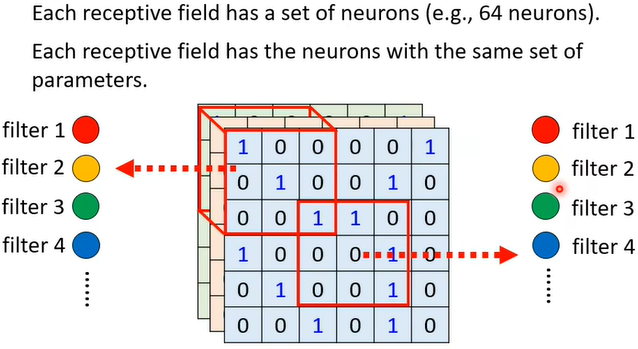
疑问:这个filter怎么算出来的?
(三)简化3
上面的convolution之后,往往会进行一次筛选,也就是把图片变小(比如4×4的变成2×2的,但channels不变),也就是池化Pooling。可以多次convolution后做一次Polling。
Polling的目的是减少运算量,但是会丢失信息,所以计算力提升后,Polling也可以不用。
如,当用CNN训练围棋时,不能把影像上的CNN直接套上去,因为不能用Polling,丢掉几行几列后已经不是原本的棋局了!所以考虑Neutral network architecture时,要明确研究问题的特性,做出适当变动,不能把知识学死!
(四)小结
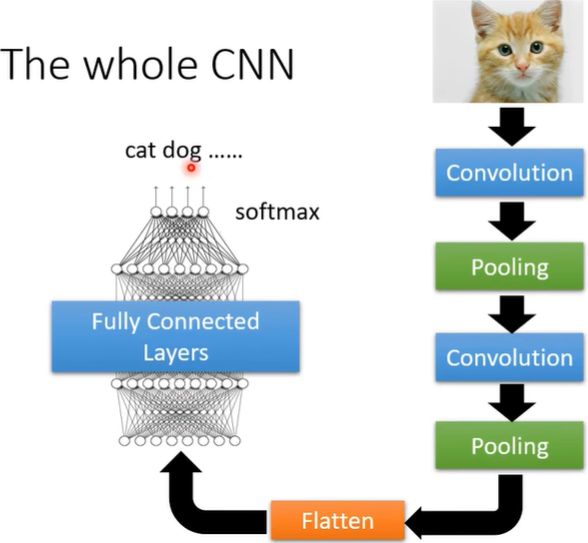
CNN不能处理影像放大缩小的问题,所以往往需要data augmentation(事先放大旋转后放进去训练)
第四讲、RNN
一、RNN简介
(一)RNN
Recurrent Neural Network,RNN,循环神经网络。
考虑到输入的顺序以及前置语句,因此同一个input的output不一定相同!
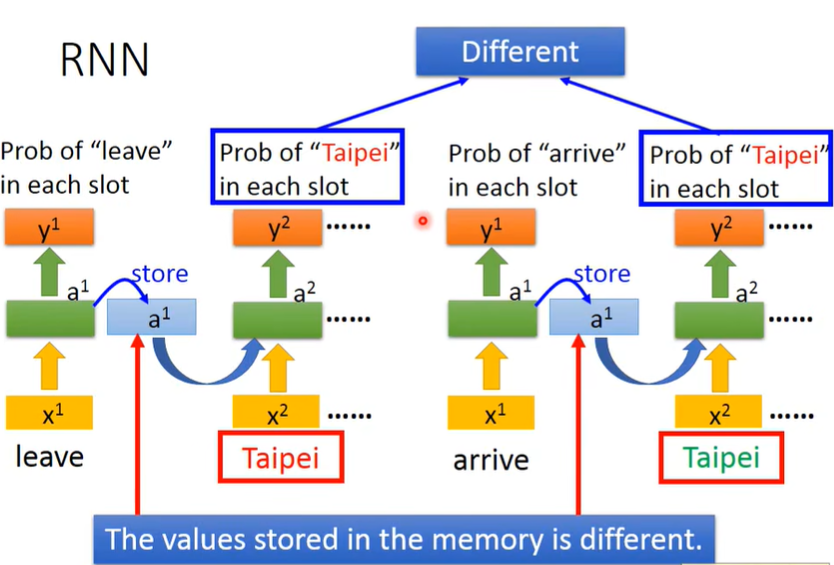
上面是最简单的RNN,而中间还可以叠更多层。此外,还可以变形成双向的RNN,Bidirectional RNN,即正向输入一次,再逆向输入一次,合并输出output。
结合上文和结合上下文的区别。
(二)LSTM
在RNN基础上加了一些Gate,有4个input,1个output。
(4个input不一样,因为有不一样的权重,所以参数也是RNN的四倍)
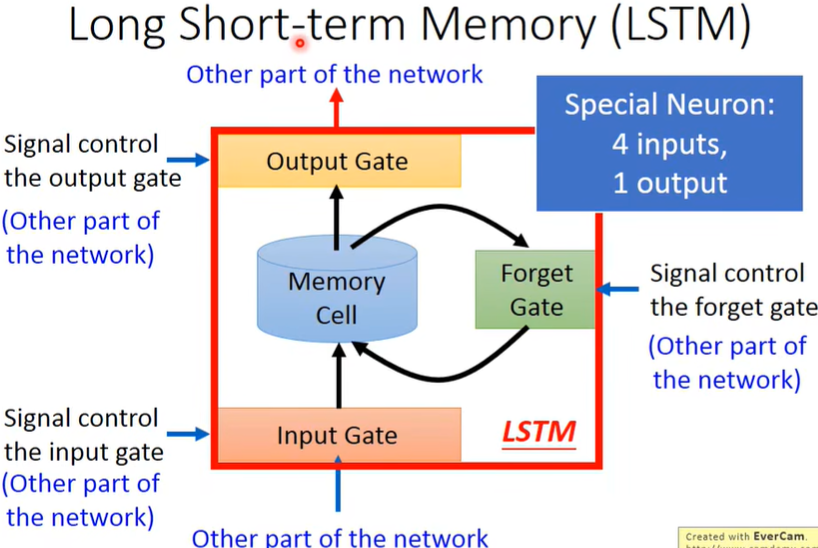
问:“-”应该放在Short和term之间,为什么呢?
答:因为在之前的RNN,Memory每次input后都会被更新,非常的short,而LSTM里只要Forget Gate不决定遗忘(打开表示记得,关闭表示遗忘),就可以一直记住,所以long。
关于Gate的具体运作:
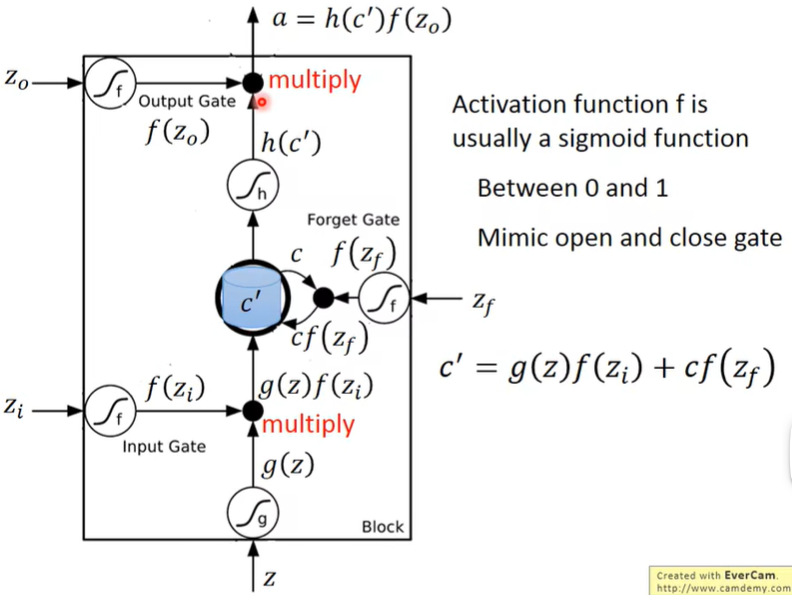
注解:疑问:这里的\(f(z_i)和f(z_f)\)既然不是非0即1,说明是给\(g(z)和c\)加了权重?所以它们是同时起着开关Gate和权重的作用?(视频里的例子都是近似0或者1,只起到开关作用)
(三)小结(重要)
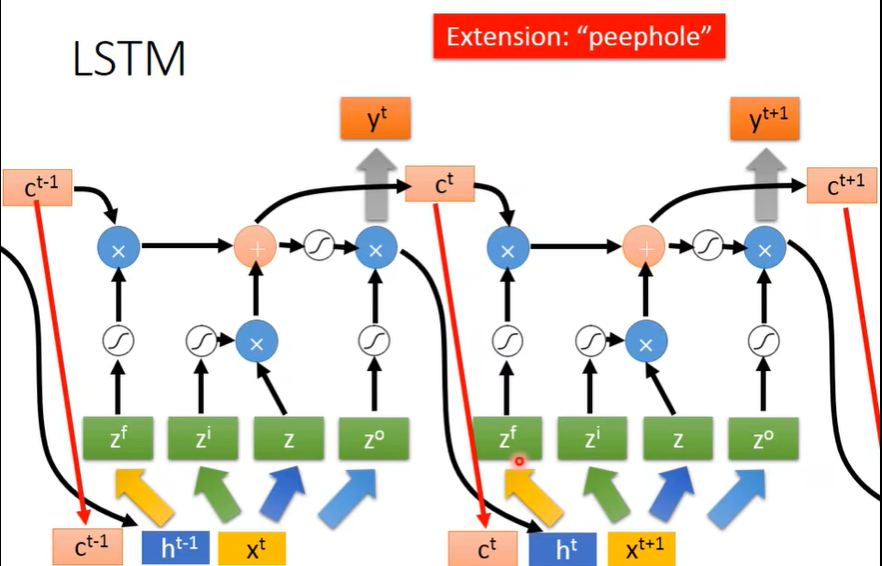
这里的\(x^t\) 就是原始的输入,而\(z^f,z^i,z,z^o\) 是\(x^t\) 处理后得到的,和上面“Gate具体运作”的图里的含义一样。
现在常讲的RNN实际上已经默认就是LSTM了,而如果要用最初的RNN,一般会说成SimpleRNN。
GRU比LSTM少了一个Gate,但是效果差不多。
二、RNN如何训练
(一)存在问题
要点:定义Loss function,寻找一组value,使Loss最小。
RNN有时比较难训练,因为它的error surface可能像下面这样:
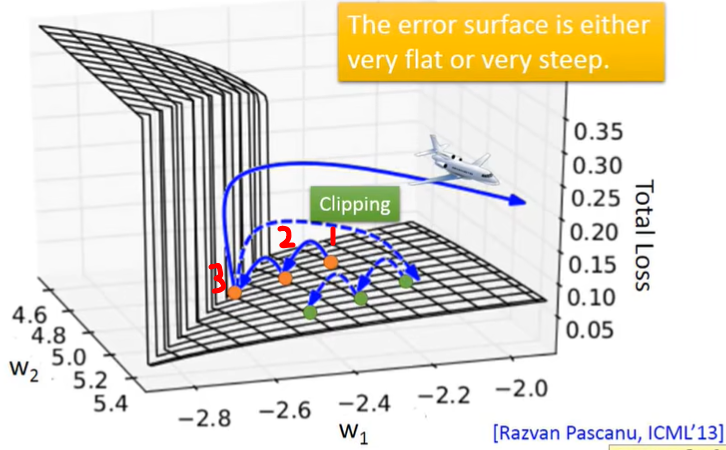
这就导致它的Loss会这样变化:
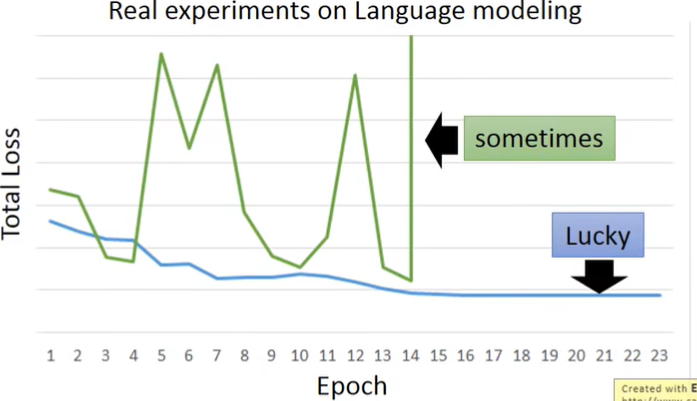
之所以这样,是因为从橙色点开始update时,它可能会直接跨过陡峭的“悬崖”,这就导致Loss突然变大。
而也有可能是刚好跨到了“悬崖”上,这时因为之前的步子小,learning rate大,此时突然gradient很大,而learning rate来不及减小,大的learning rate乘上大的gradient,结果参数就update特别大,直接飞出去了(“飞机图标”)。
疑问:为什么会出现这种error surface?(好像是循环的问题,同样的weight在不同时间点反复被使用,导致梯度爆炸或消失,并不是来自于Activation Function)
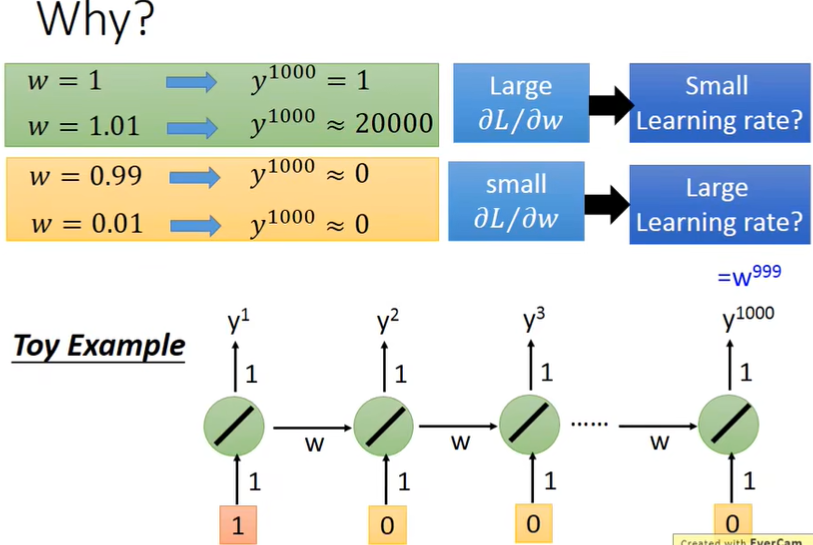
那么如何解决这个问题呢?
(二)解决办法(疑问)
- 对于梯度消失Gradient vanishing,可以用LSTM(这也是不用SimpleRNN而用LSTM的重要原因)
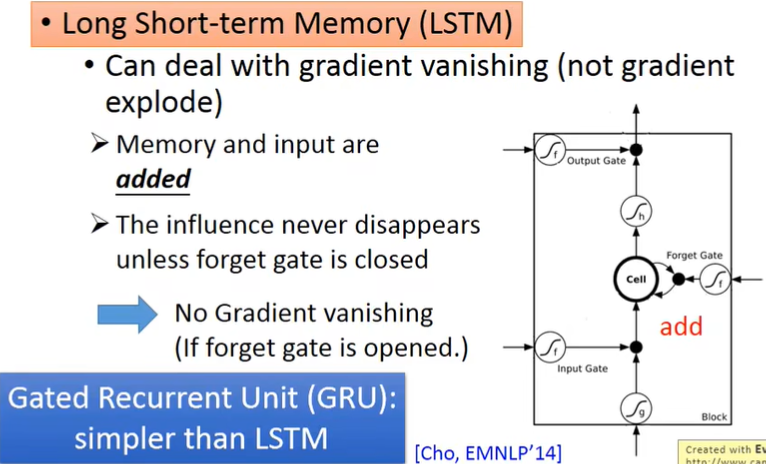
- 对于梯度爆炸Gradient exploded呢?
(三)应用
-
Many to One-情感分析
-
Many to Many-语音识别(CTC)、机器翻译(有研究表明只需要声音讯号和对应的翻译文字,就可以训练(语音)→(文本),比如不需要台语的文字材料,即不需要语音辨识,就可以直接进行台语翻译。因为有些方言从语音→文字并不好做,甚至没有对应的文字,这个研究就可以避开这个障碍)
(四)对比(疑问)

三、自注意力机制
(一)引言
在之前的CNN中,假定了每个输入的长度都一样,那么如果每次的输入可能会不一样怎么办?比如在输入句子时,每个句子的长度是不尽相同的。
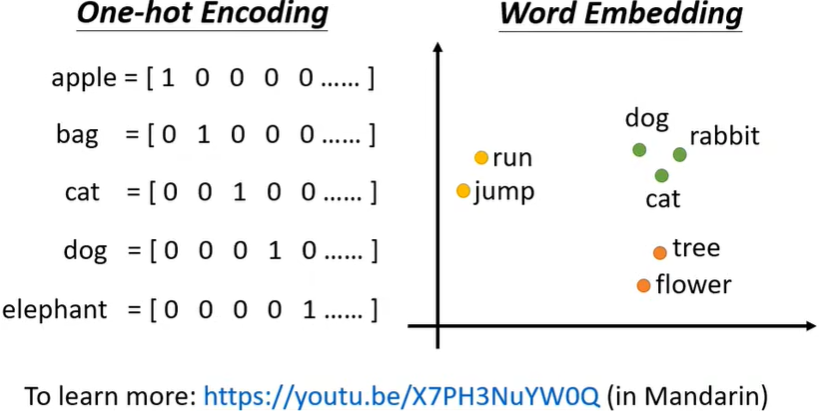
字符的编码方式:One-hot Encoding的严重问题在于假定了所有词汇直接是没有联系的,而实际上cat、dog之间应该是有关系的,因为都是动物。因此我们可以用Word Embedding。
首先,输入输出的关系有这几种:
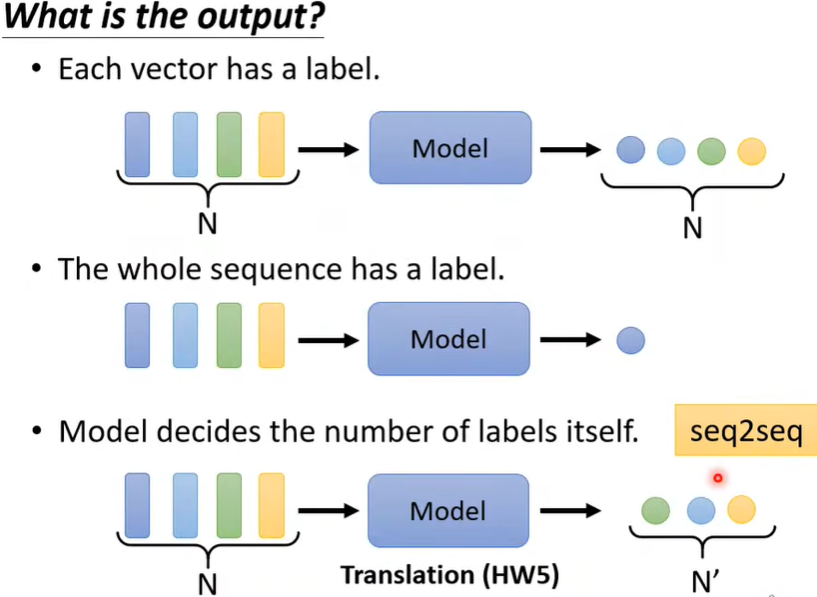
讨论第一种,又叫Sequence Labeling。
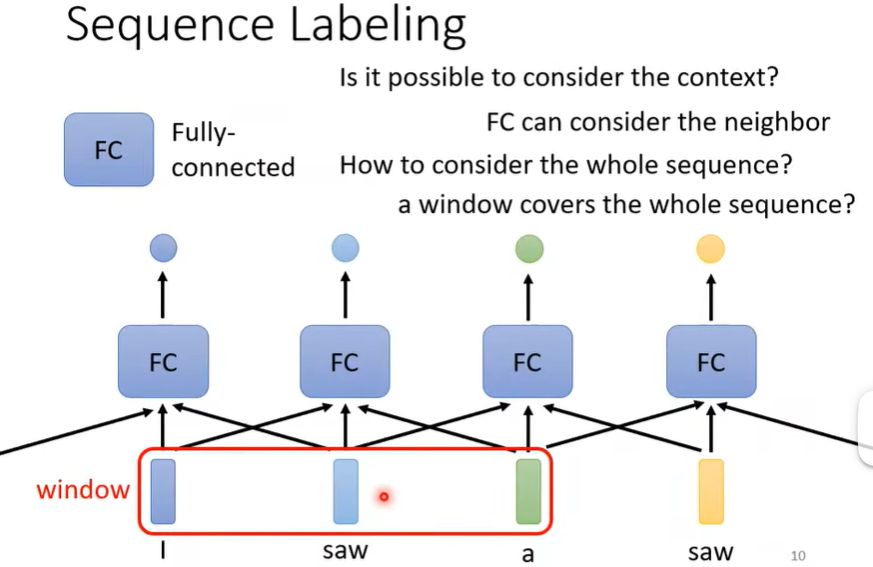
当我们需要判断单词的词性时,只单独看这个词是不行的,比如下面的两个saw,一个是动词,一个是名词,这时候需要看上下文,于是我们可以开一个window,将上下文一起input,但如果我们要考虑整个句子呢?难道把window开得和句子一样长吗?显然不行,因为每个句子的长度是不一样的!!那开一个很长的window,能够cover最长的句子?显然也不现实,因为很多句子没那么长,这白白浪费了很多计算资源,使得模型参数过多,还可能overfitting!如何解决?
这就需要用到自注意力机制Self-Attention.
(目的就是需要关注到整个句子,但是又不想把整个句子都包在window里面,于是用Self-Attention这个特别机制来找出句子里面哪些部分重要)
(二)原理
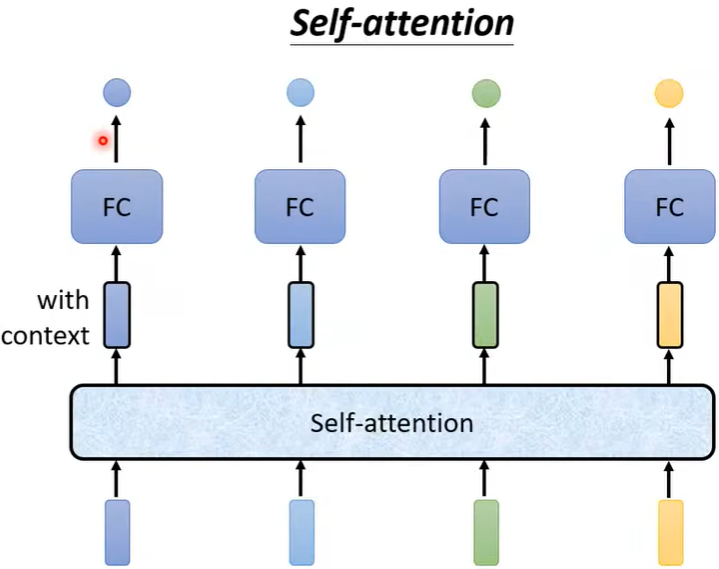
注意:self-Attention也可以叠加。
那么Self-Attention是怎么运作的呢?
下图为其核心内容,以如何从\(a^1,a^2,a^3,a^4\)得到\(b^1\)为例:
注意:\(b^1,b^2,b^3,b^4\)并不需要依次产生,可以并行计算。
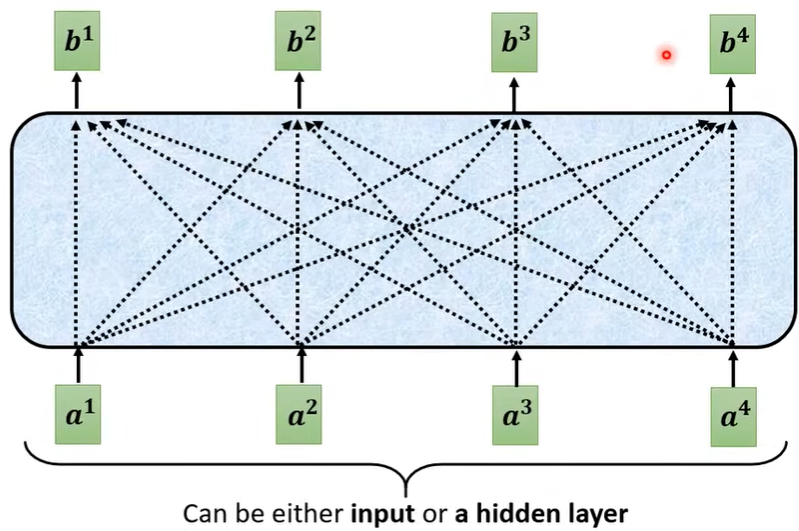
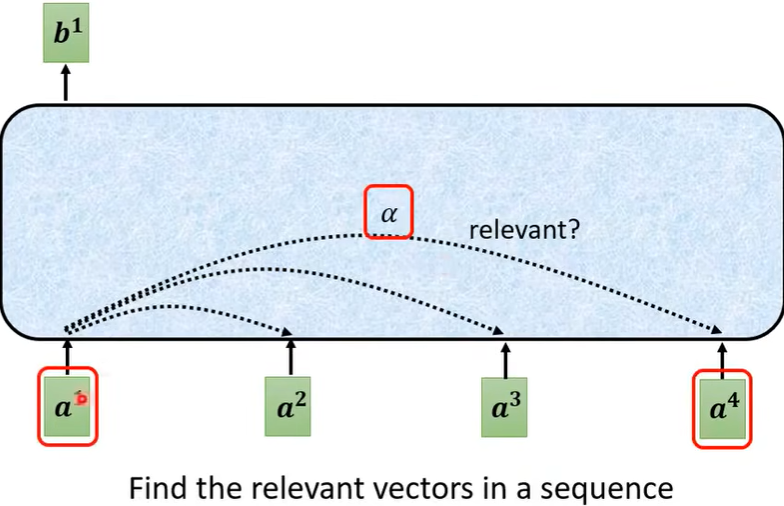
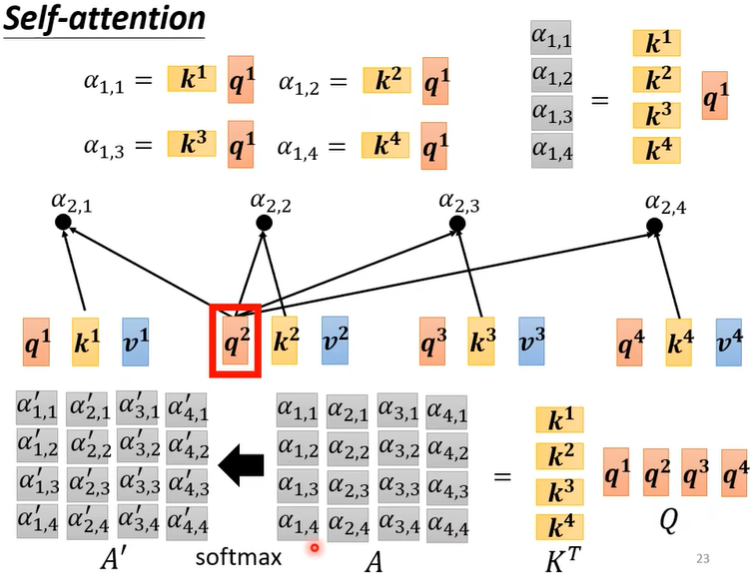
第一个步骤,根据\(a^1\) 这个向量,先找到\(a^2,a^3,a^4\) 与\(a^1\) 的关联程度,也就是下图的\(\alpha\) 。
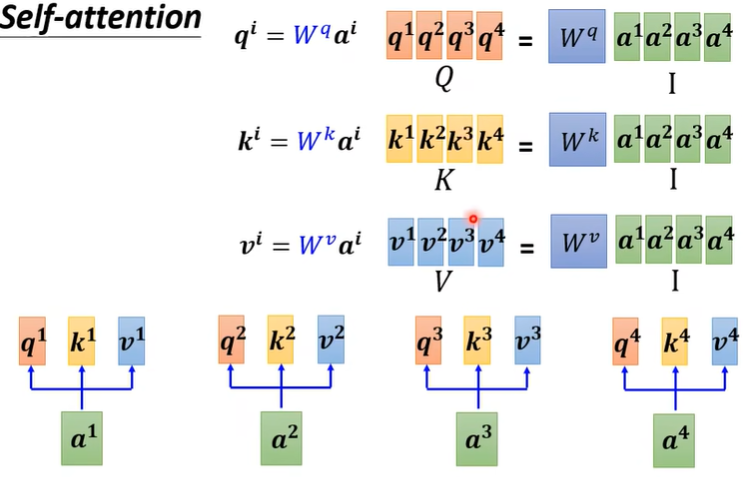
\(a^1\) 是向量,也就说Self-Attention的输入是一个vector set(与CNN输入有区别)。
那么如何计算\(\alpha\)呢?此时需要一个计算模组,如下图,其中点积Dot-product较常用。
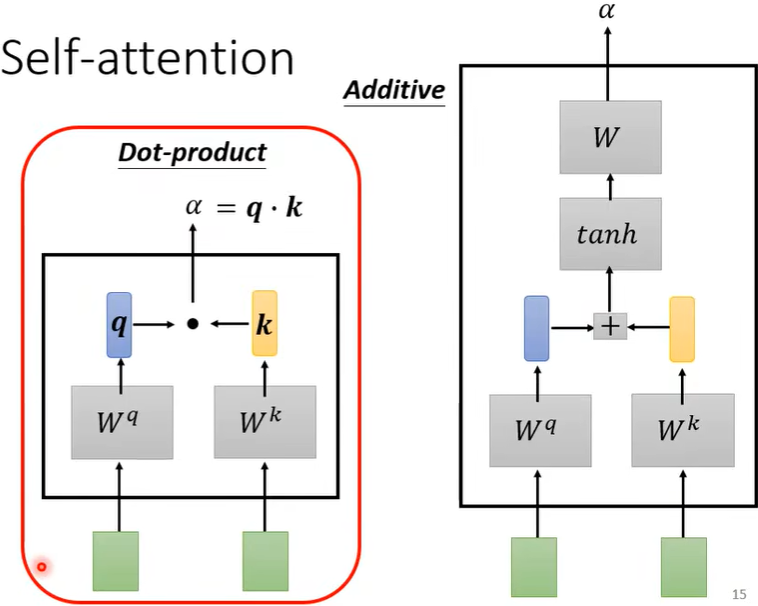
然后利用此计算模组,就可以计算出\(a^1\)与\(a^2,a^3,a^4\)之间的关联性,即\(\alpha _{1,2},\alpha_{1,3},\alpha_{1,4}\)。
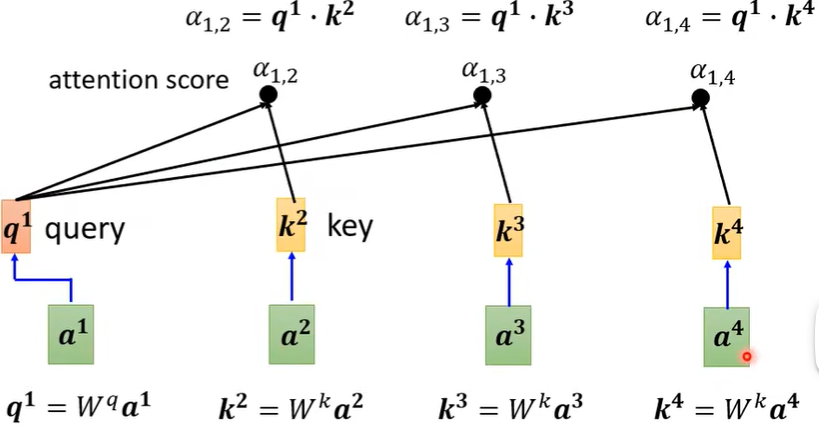
并且,\(a^1\)还会和自己计算关联性(疑问:为什么要计算和自己的关联性?),即下图中的\(q^1·k^1\),接着经过Soft-max(也可以是别的函数,比如ReLU,但效果不一定好)。
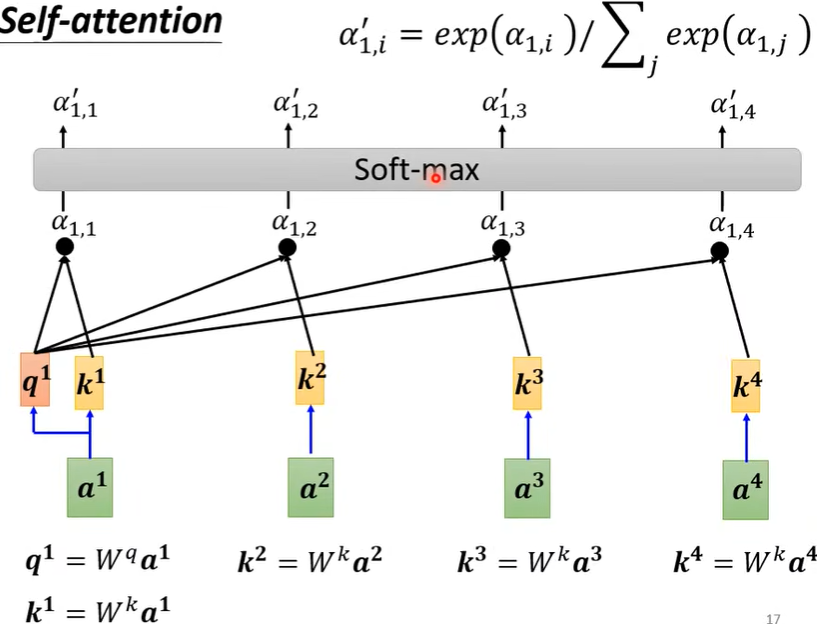
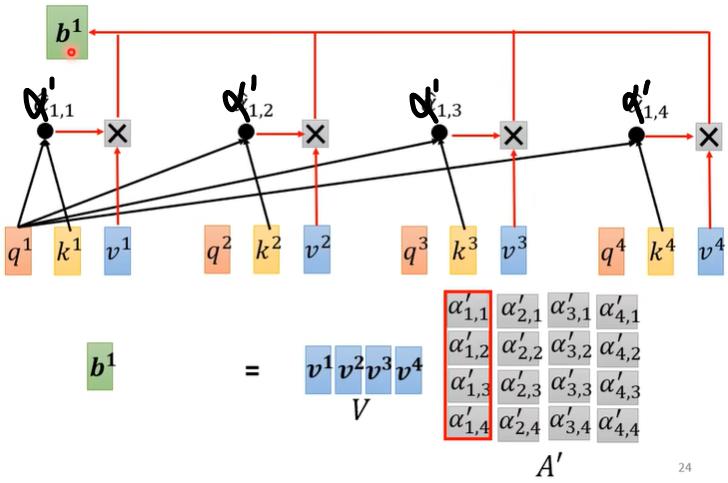
此时,我们已经知道其他向量与\(a^1\)的关联性差别了,接下来就要根据attention score来抽取重要信息了。
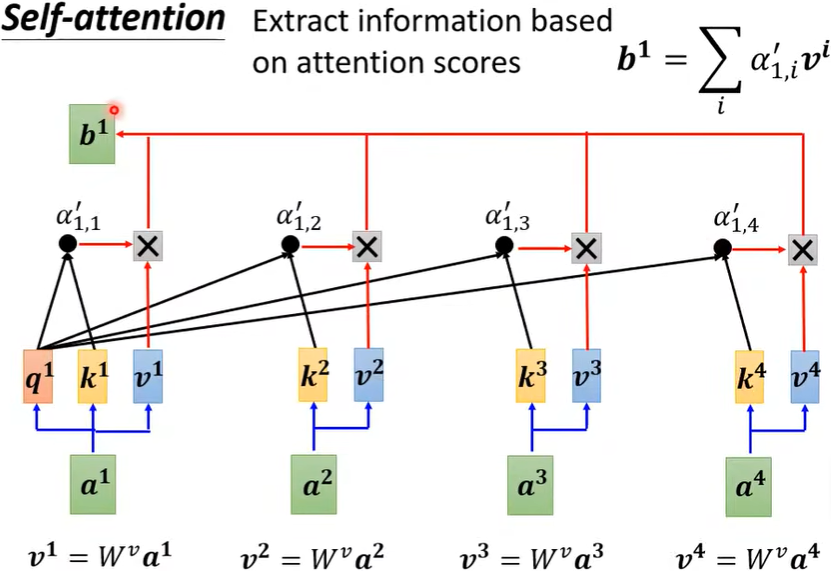
(三)小结
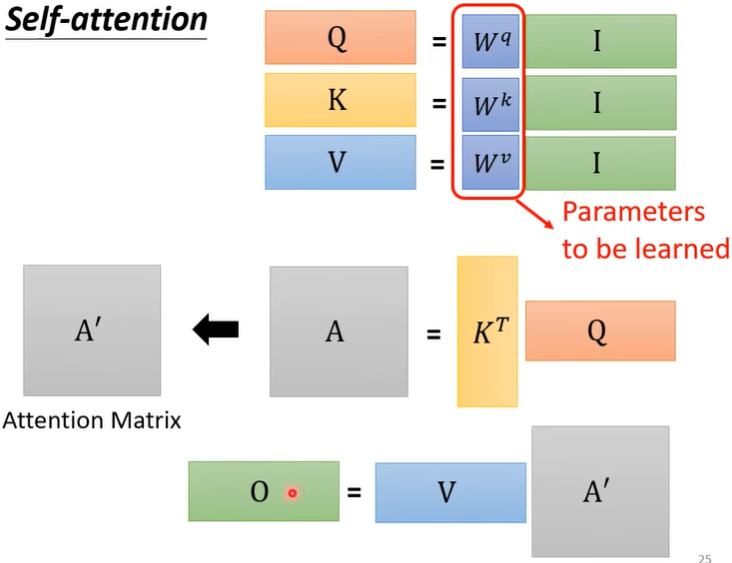
上一节单独介绍了如何用\(a^1,a^2,a^3,a^4\) 计算出\(b^1\),其实整体看待\(b^1,b^2,b^3,b^4\) 的产生过程,其实就是一连串矩阵乘法。
所以在整个过程中,其实只有\(W^q,W^k,W^v\) 是未知的,是需要training找出来的,其他变量的均已知。(\(I\)就是input,\(O\)就是output)
(四)多头自注意力机制
Multi-head Self-Attention。
前面都是单head的形式,而像翻译、语音辨识用更多的head可能有更好的结果。为什么需要比较多的head呢?
在上面的“(二)原理中”,我们用\(q\) 计算相关性(即\(q^1·k^1,q^1·k^2...\)),而相关这件事有不同定义,不同的形式,所以我们需要多个\(q\),不同的\(q\) 负责不同的相关性(比如鸡和鸭都是动物,也都有两只脚?)
以2 heads为例,与前面单head类似,但注意\(q^{i,2}\) 只用和\(k^{i,2}\) 和\(k^{j,2}\) 乘,多头也是一样。
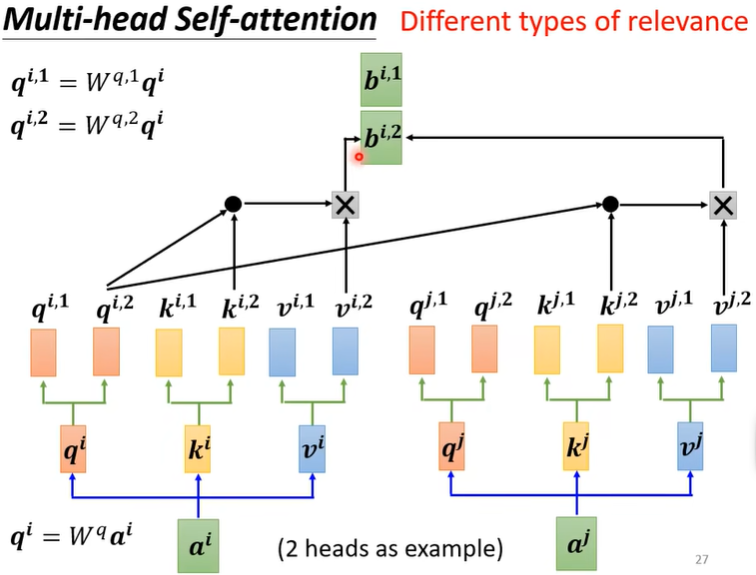
(五)位置编码
前面的所有注意力机制中,均没有考虑position information,但是比如在词性分析中,是需要position information的,这时怎么办呢?只需要给每一个\(a^i\) 加上一个唯一的位置编码\(e^i\) 就行。(疑问:这个位置咋编码的?)
(六)应用
-
NLP领域。
如Transformer,Bert。
-
Speech语音辨识。
如果直接把语音变成向量输入的话,这个向量会非常长,矩阵也就非常大,此时常对Self-Attention进行改动,即Truncated Self-Attention,不考虑整个句子,而只关注某个范围。
-
Image。
CNN需要人来划分receptive field, 每个neuron只考虑一个receptive field里的信息;而Self-Attention需要考虑整个图片的信息,receptive field是机器学出来的,所以CNN可视为简化版的Self-Attention。(疑问:怎么理解这段话?答:可看论文On the Relationship between Self-Attention and Convolutional Layers)
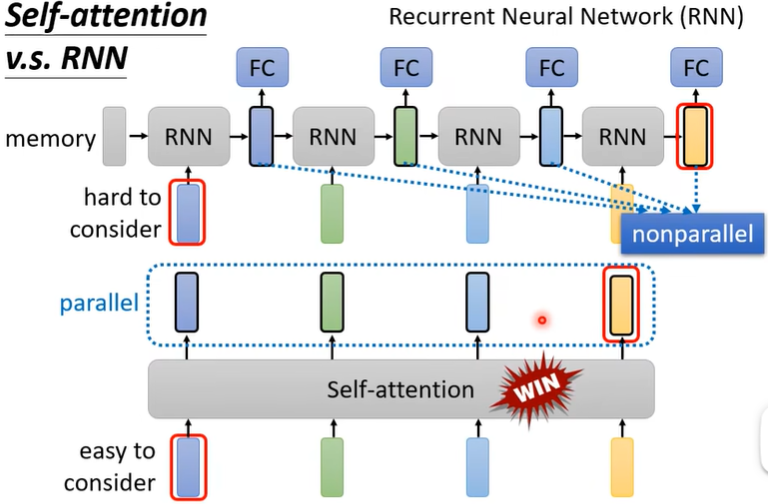
问:Self-Attention与RNN有什么不同?
答:Self-Attention里每个vector都考虑了整个input sequence,RNN只考虑了前面的vector(当然Bi-RNN也可视为考虑了整个sequence)。此外,如果RNN的最右边的vector要考虑最左边的vector时,需要最左边的vector一直被记住,而Self-Attention只需要一个q和k而已。最后,RNN不能并行计算。
-
Graph。(疑问)
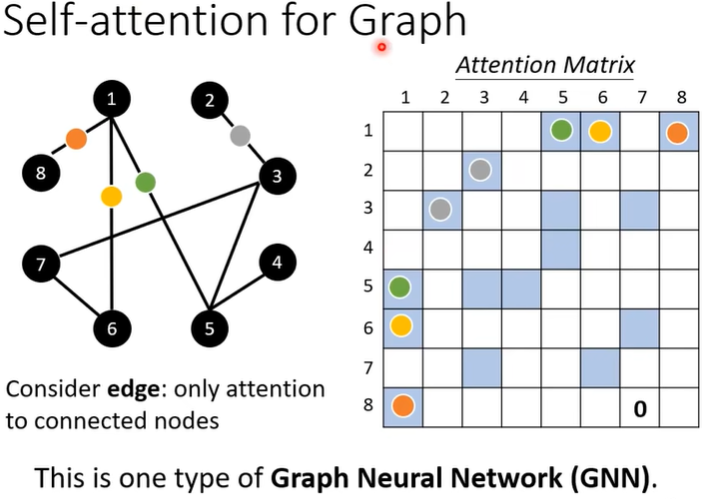
第五讲、Transformer
一、引言
这是一个Seq2Seq的模型,就是由机器自己决定output的长度,比如语音辨识、机器翻译。
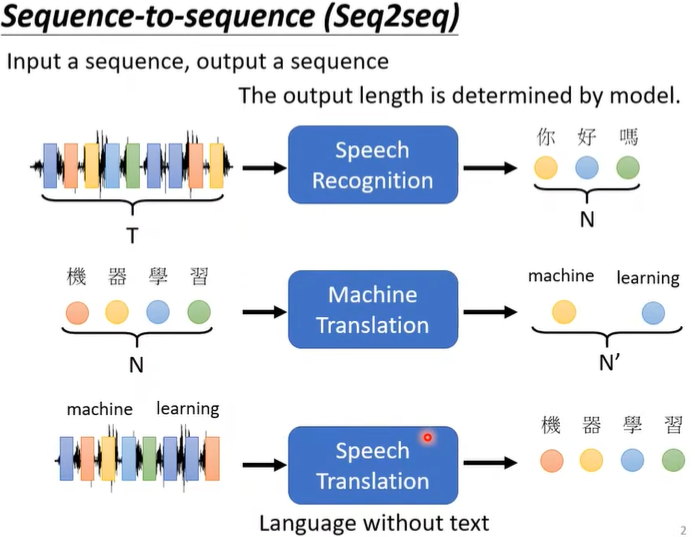
先进行Speech Recognition再进行Machine Translation不行吗?为什么还要有Speech Translation这个任务呢?这是因为世界上很多语音并没有文字,所以做不了语音辨识,因此才有了Speech Translation。
实际上,各种NLP问题(QA➡seq2seq)都能视为seq2seq问题,即可以用seq2seq model,但是对不同的任务运用特制化的模型效果会更好。
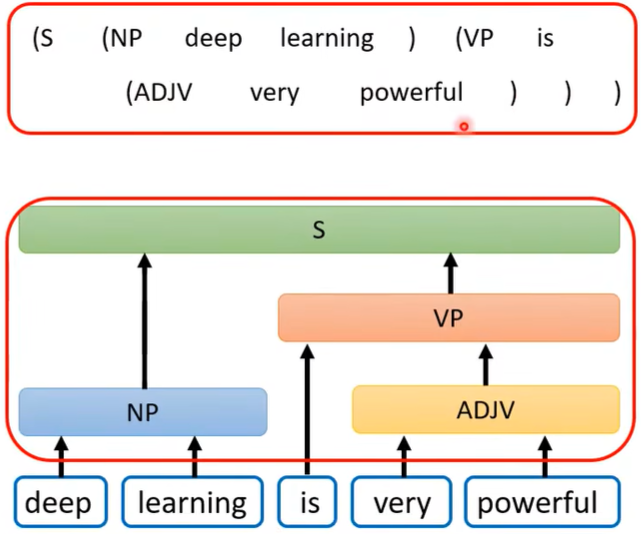
而一些看似不是seq2seq的问题,也可以用seq2seq模型解决,比如语法解析,将这棵语法树硬是转换为一个向量,这样就可以用seq2seq了。
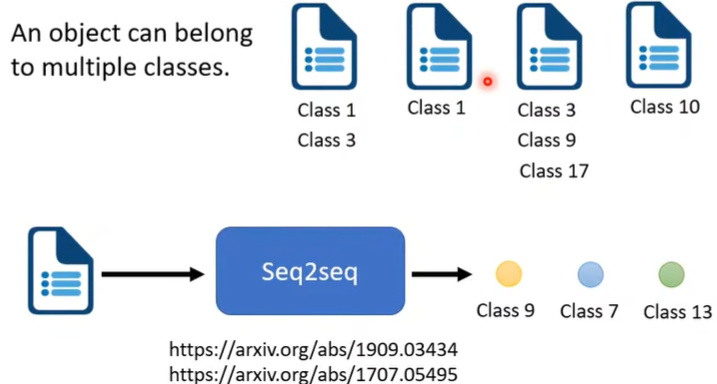
seq2seq还可以应用在Multi-label Classification(对比之前的Multi-class Classification,前者是从多个class中选出一个,后者是选出多个)
问:能用Multi-class Classification(假设MC)来做Multi-label Classification(假设ML)任务吗?
答:表面上看似乎可以,因为MC输出的结果是得分最高的那个,那么我如果设置为输出得分比如前三的class,不就能进行多分类吗?但每个object所属的label个数不一定都是三,有时是一,有时是二,这时需要机器自己判定到底要输出几个class,这刚好符合seq2seq,所以MC里的做法不能应用到ML上。
还能运用于object detection......所以seq2seq model是个很强大的model。
二、原理
Transformer的核心就是一个Encoder和一个Decoder.
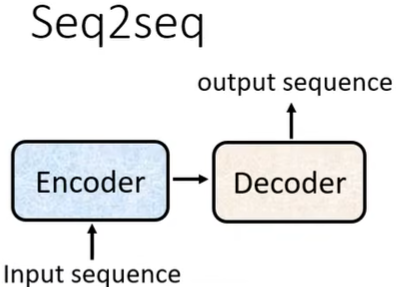
(一)Encoder
整个Encoder的大概结构是这样的:(即输入一排vector,输出一排vector。这里也可用CNN、RNN代替Self-Attention)
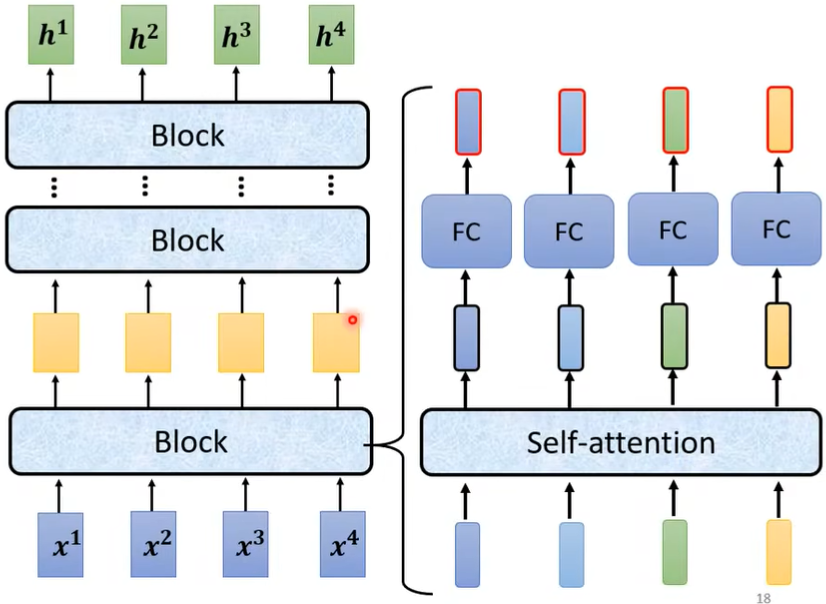
这里面是一个Block而不是一个layer,是因为它做了很多层layer做的事,将Block展开来就是这样的 :
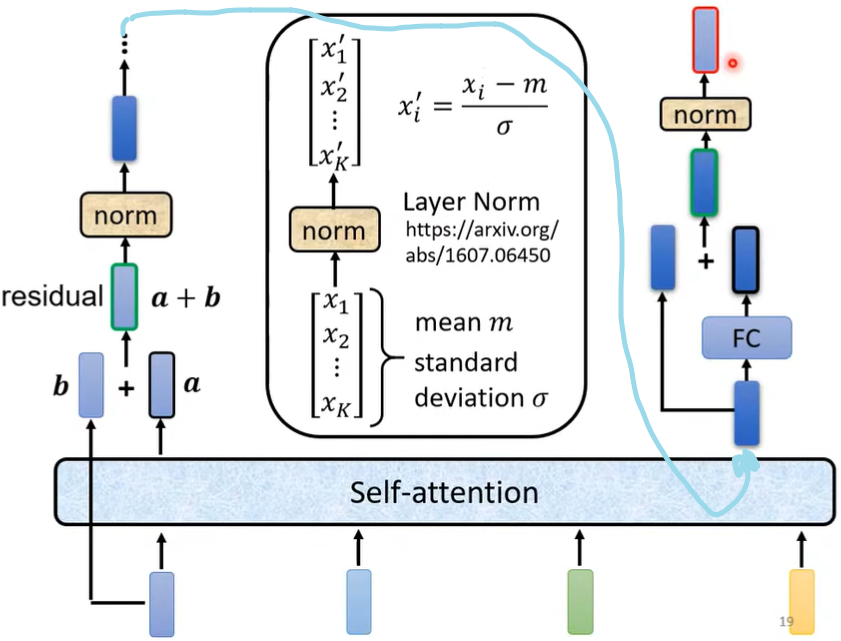
这样一整个Encoder也可描述成这样的形式:
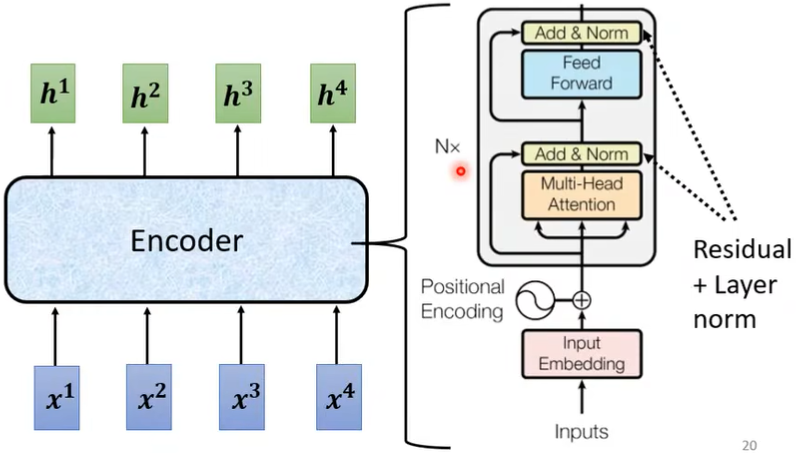
(二)Decoder
-
Autoregressive
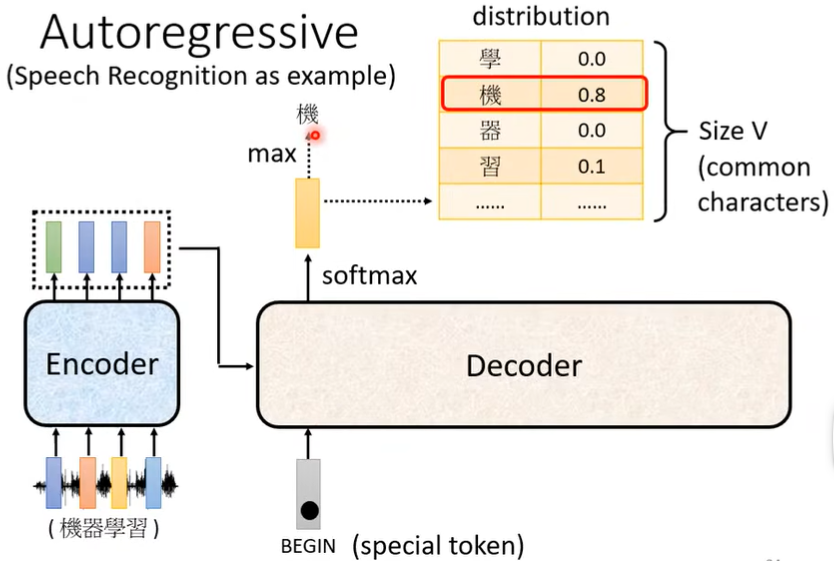
“Size V”即为希望机器可以输出的字的总个数,比如可以设置为所有常见中文字。
Decoder会把自己的输出看成下一个输入:
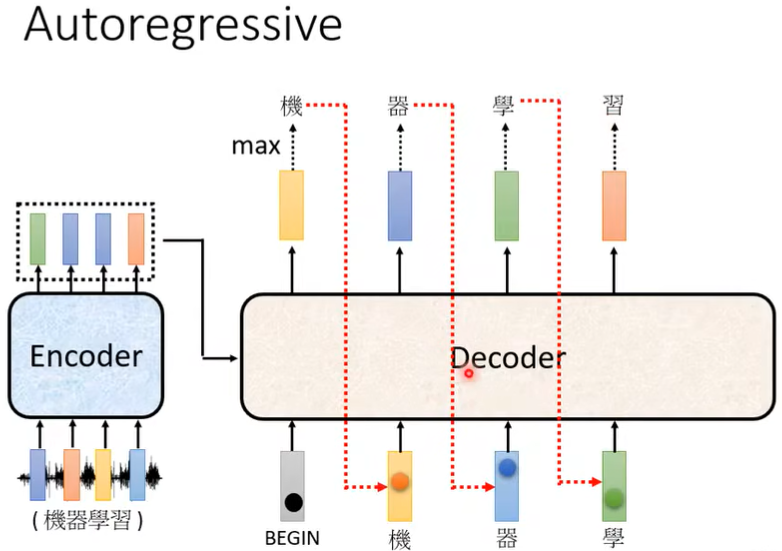
注意:需要加一个断字END,才能停止输出,和BEGIN性质一样。
-
Non-Autoregressive(NAT)
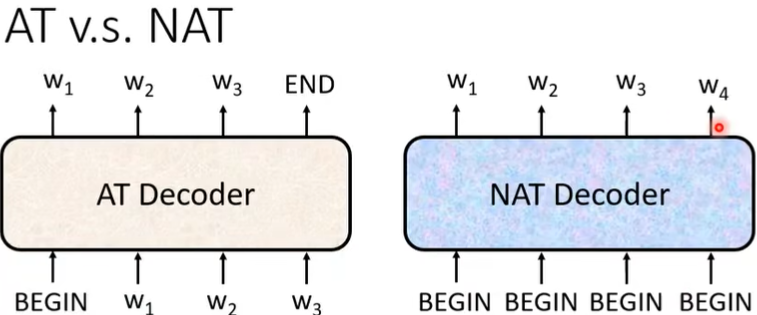
AT是一次产生一个字,NAT是一次产生整个句子。
NAT的好处在于平行计算,AT每次只能输出一个字,不断地Decoder输出一句话,所以NAT更快(Self-Attention后才有NAT,之前的LSTM不能做到平行输出)。
NAT的表现通常更差,因为有个Multi-modality问题。
问:NAT没有END,那么怎么知道有多少个BEGIN,也就是怎么知道输出多长呢?
答:可以learn一个classifier,输出decoder应该输出的长度,就可以知道需要几个BEGIN了。
也可以直接给一堆BEGIN,使其一定会超过应该输出句子的长度,然后找到输出中的END,右边的都是无效的可以去除。
(三)Encoder与Decoder之间的联系
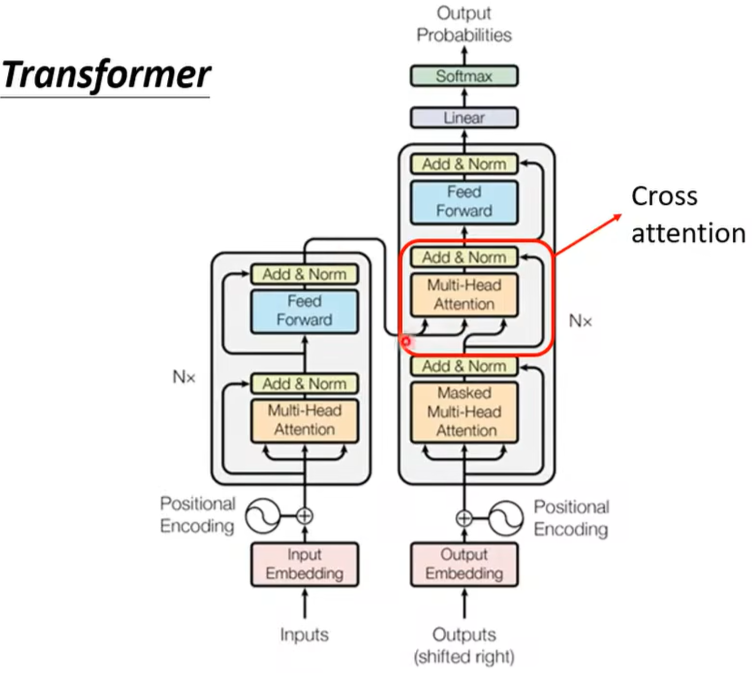
红框Cross attention如何运作呢?见下图,上面Multi-Head Attention的三个输入分别是左边两个\(k,v\),和右边一个\(q\)。
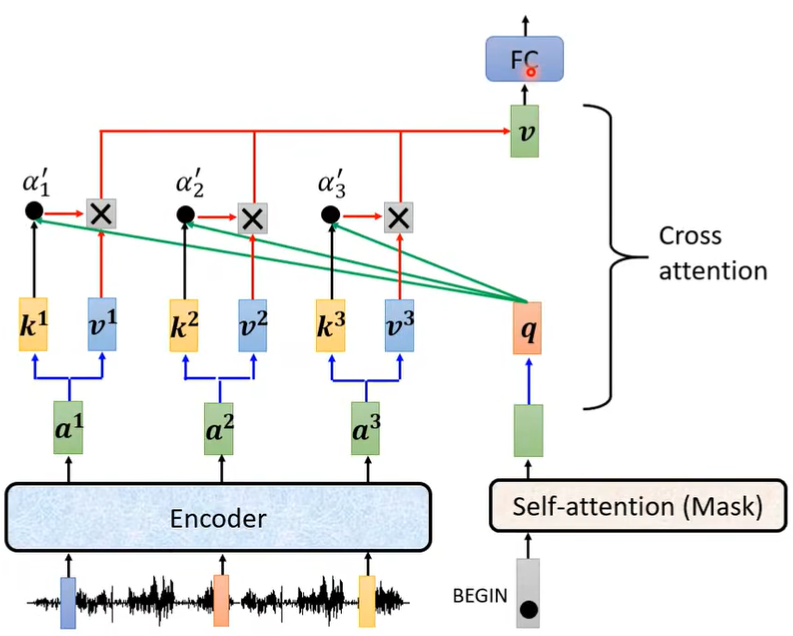
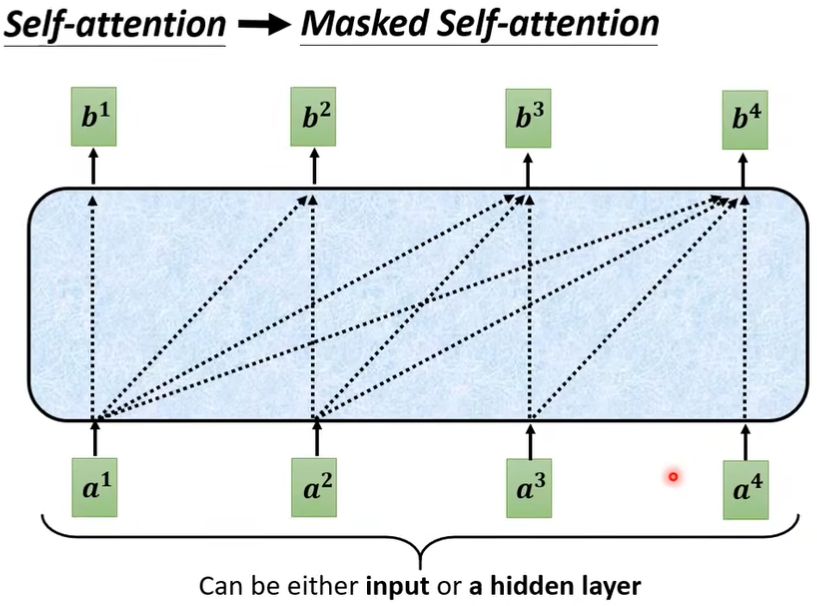
关于Masked Self-Attention和Self-Attention区别如下:
在前面,\(a^1,a^2,a^3,a^4\) 是一起输入产生\(b^1\)的,但这里面只能用\(a^1\),因为此时\(a^2,a^3,a^4\) 还没生成,所以不能看右边的\(a\)。
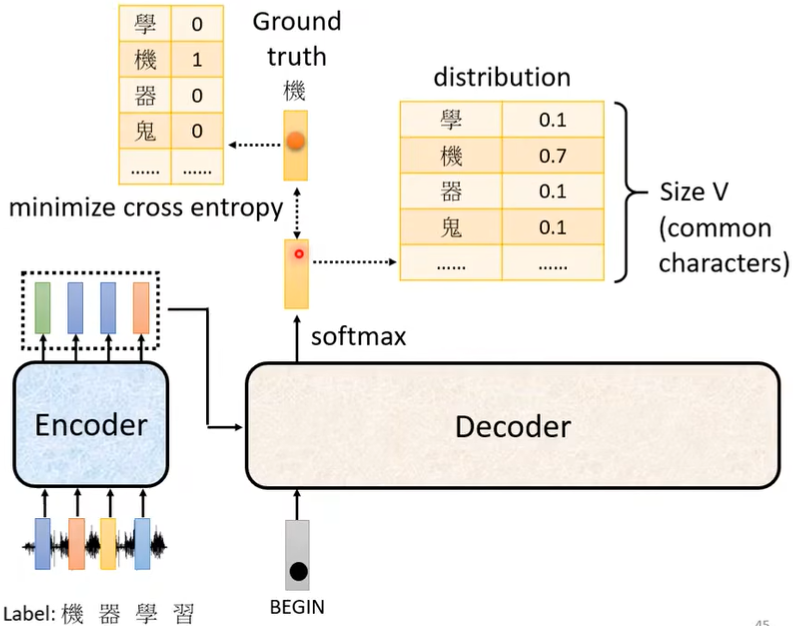
三、如何训练
(一)目标
每产生一个字,实际上就是做了一次分类的问题。Decoder输出的是distribution,每次输出都和ground truth有个cross entropy,我们希望所有cross entropy的总和最小。
最后还会输出一个END,它也要计算交叉熵。
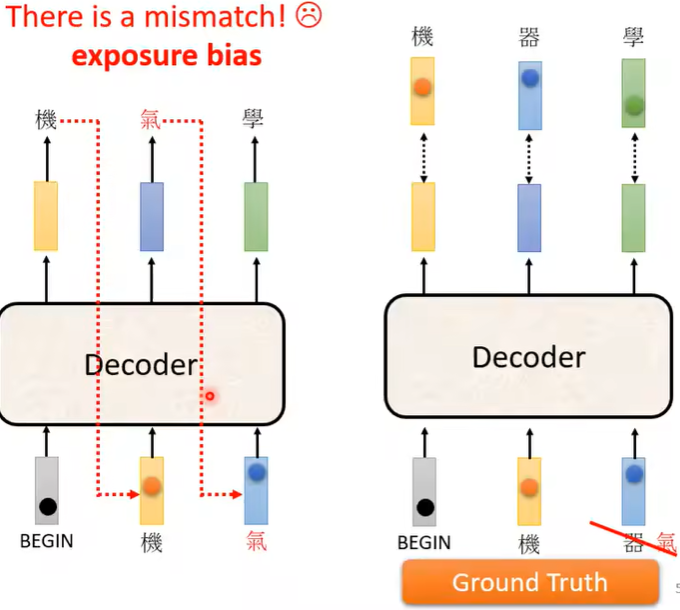
并且我们在训练的时候,还会给Decoder看正确答案,这种训练方法叫Teacher Forcing。但是这样也会存在问题,那就是如果训练的时候Decoder看到的都是完全正确的,那么在测试的时候如果看到了错误的东西,可能就会导致后面完全错掉,所以训练的时候适当投喂一些错误的东西也许会更好。这种做法就是Scheduled Sampling。
(二)技巧
1. Copy Mechanism复制机制
在训练的时候,并不是每次都需要机器输出新的东西,有时候只需要Decoder从输入中复制一些东西输出来。
(1)Chat-bot
比如机器并不需要学懂"库洛洛",并且也很难学懂,所以只需要复制过来就行。

(2)Summarization
摘要中很多词汇就是从文章中复制出来的。最早这样做的模型有Pointer Network。
2. Guided Attention
机器在如语音合成时,可能会漏字,因为它的attention可能是颠三倒四的,它并不是按顺序来attention,可以用一些方法如Monotonic Attention、Location-aware attention......
3. Beam Search
不太适合创造性任务。
在之前的模型中,每次都是选取score最大的那个,实际上这不一定是最优解,可能先选择score低的,但后续的score会非常高,整体效果也更好。当然我们总是很难选出最优解的。并且有时候的看似最优解也可能并非人们需要的。
第六讲、GAN
(疑问,重要,重温)
[生成式对抗网络,Generative Adversarial Network]
一、基础概念
(一)引言
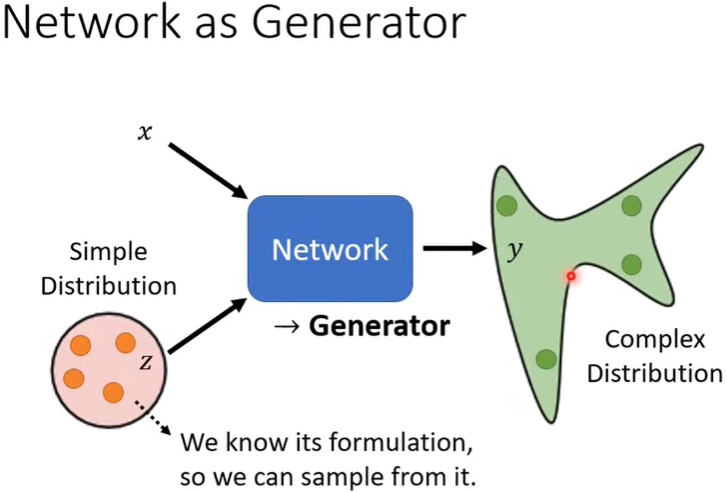
每次使用Network时,抽样获得的\(z\) 不尽相同,所以Network输出的结果也不唯一,表现为complex distribution。
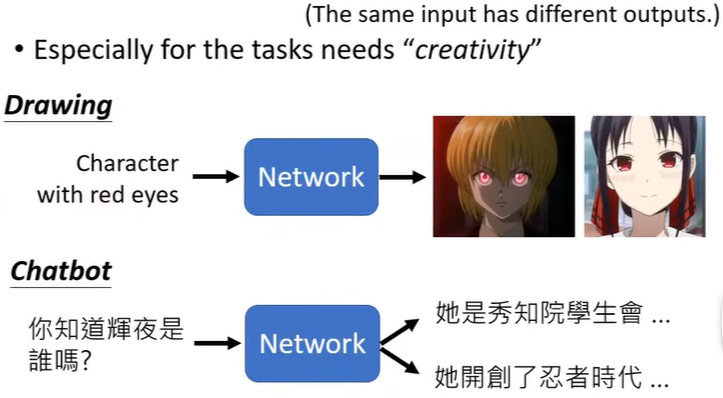
答:在以往的Network中,如果输入相同,输出应该也是相同的。但在一些任务中,相同的输入时可以有不同的输出的,也就是说同一个问题的答案是可以不唯一的,尤其是在具有创造力的任务中,比如Drawing,Chat-bot......所以加上\(z\) 来使相同的\(x\) 时\(y\) 也能不唯一。
这种 Generative model 中非常知名的就是GAN。
(二)Generator和Discriminator(重温)
-
引言
Discriminator判别器,output为scalar,越大说明生成图像越符合要求。
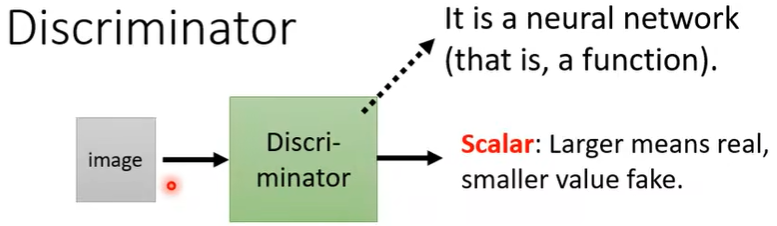
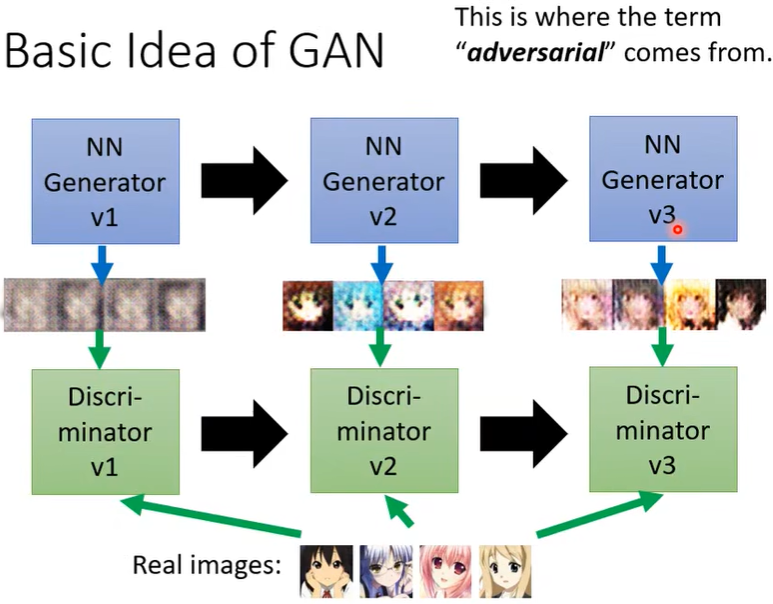
Discriminator的任务是分辨真的图片和生成的图片的差异,Generator的任务是产生假的图片骗过Discriminator。Generator和Discriminator的这种“对抗”关系,正是Adversarial的由来。
-
训练步骤
初始化\(G\) 和\(D\) 的参数后,反复地执行step1和step2。
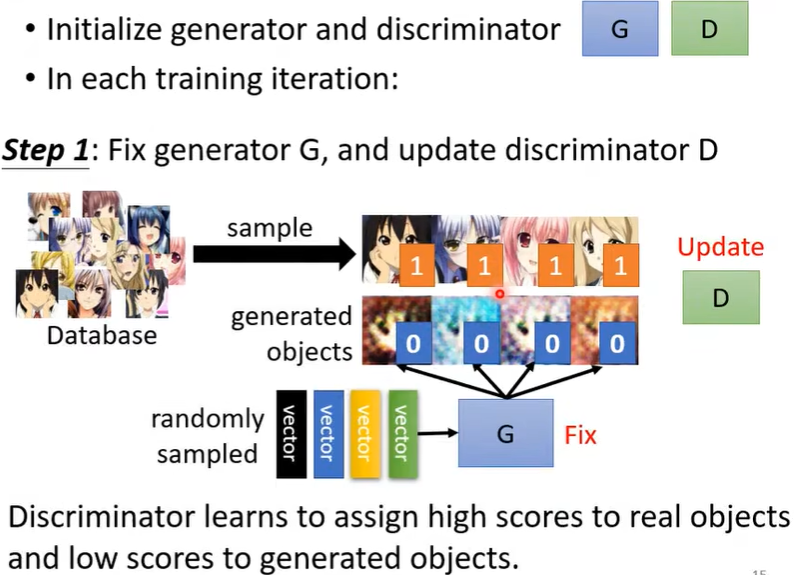
疑问:第二轮的step1时Discriminator是如何更新参数的?(好像会继承前一次update出来的参数)
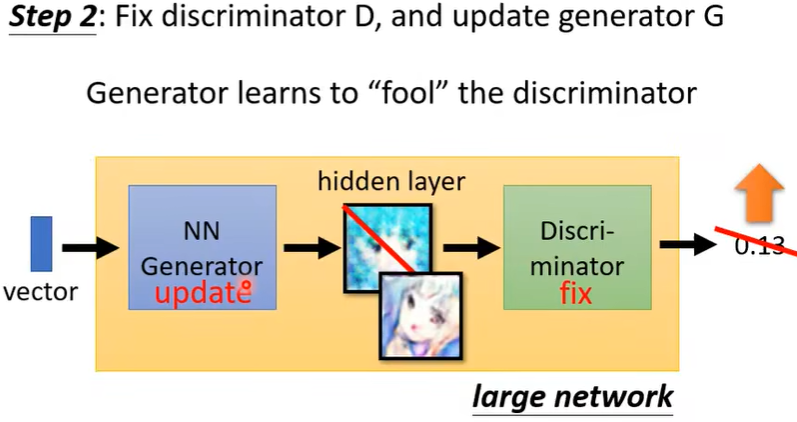
二、理论介绍
在训练Network时,实际上就是定义一个Loss function,然后用Gradient decent去调参数来minimize这个loss就结束了。
在Generator里面,minimize的对象是类似的,我们希望\(P_G\) 和\(P_{data}\) 的差异越小越好,如下图。
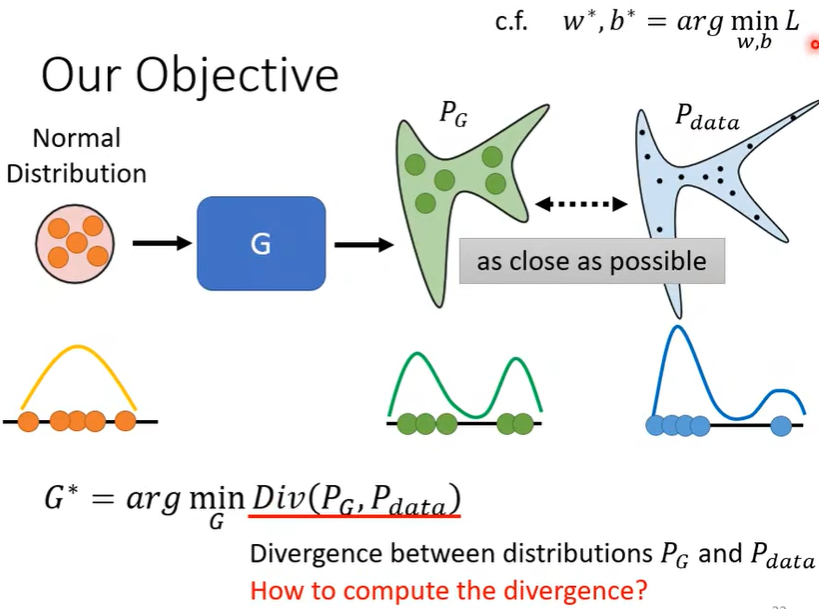
疑问:这里的Normal Distribution和\(P_{data}\) 的关系是不是被强行建立的?它怎么会和二次元图像有联系呢?
但是我们并不知道完整的\(P_G\) 和\(P_{data}\) 长什么样子,那\(Div(P_G,P_{data})\) 如何计算呢?有一种做法,那就是通过sample,如下图。

sample之后就要依赖Discriminator了(Discriminator如何训练出来的见上文,但注意这里面的数据均来源于抽样)。即我们train完Discriminator后看看它的Objective Function有多大,这个值就和divergence有关,如下图。
JS divergence:Jensen-Shannon散度。
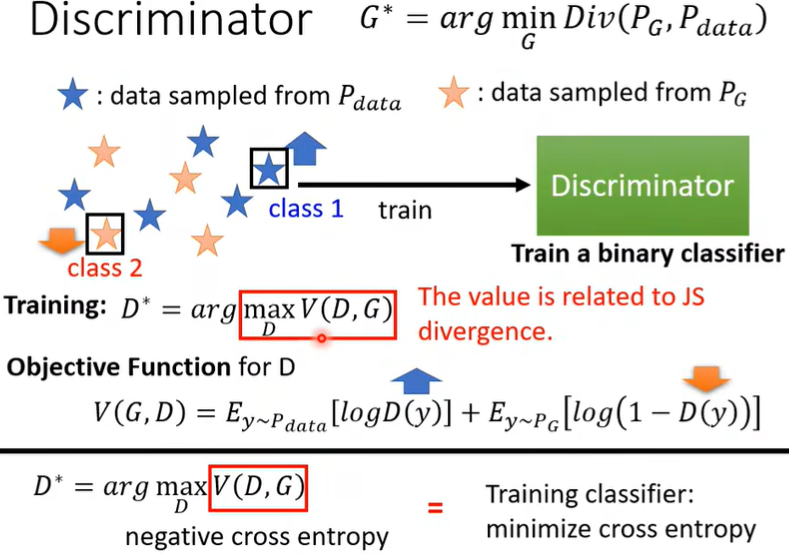
为什么会有关呢?可以直观理解,抽样出来的两组data,差距越小,即divergence越小时,Discriminator越难区分,\(D^*\) 的值越小;差距越大,即divergence越大时,\(D^*\) 的值越大。根据这种对应关系,可以间接的使\(G^*\) 达到我们的要求。
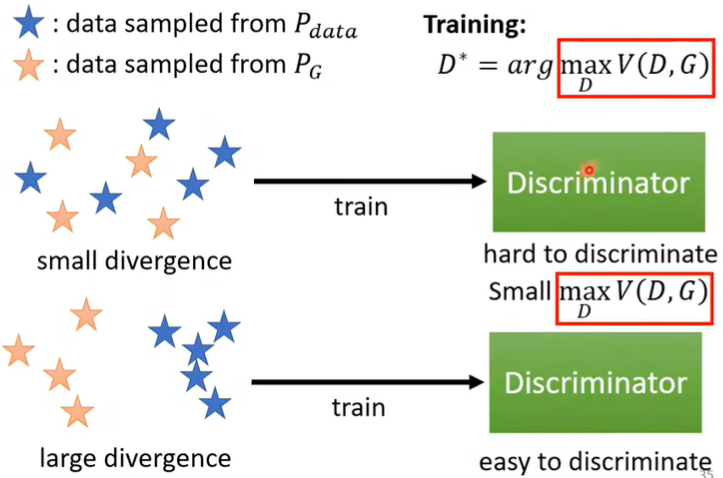
因此,在我们知道有这种对应关系后,干脆直接把\(Div(P_G,P_{data})\) 替换为\(max_D\,V(G,D)\),这样就可以解了。
疑问:为什么不是替换为\(V(G,D)\) 呢?解释:因为divergence是和\(max_D\,V(G,D)\) 对应,我们希望divergence最小,即\(max_D\,V(G,D)\) 最小,而不是\(V(G,D)\) 最小

三、训练问题和技巧
【GAN的training是很难的!】
(一)产生图像
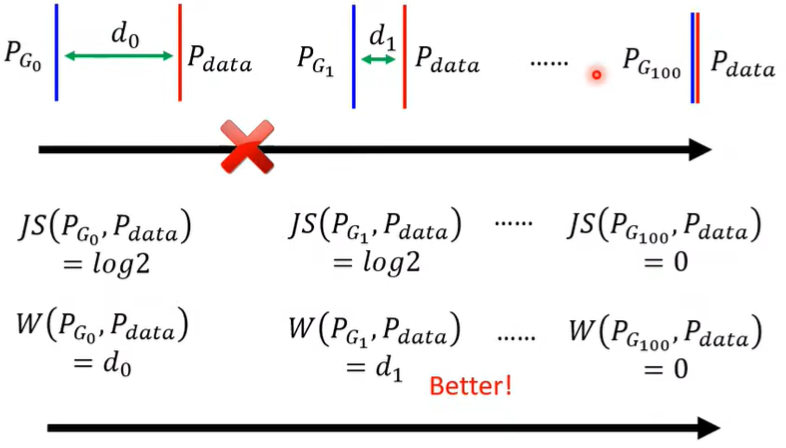
首先明确一点,JS divergence is not suitable。Why?有两个理由,分别来自data本身的特性和sampling,如下图。(疑问:这块没有太懂)
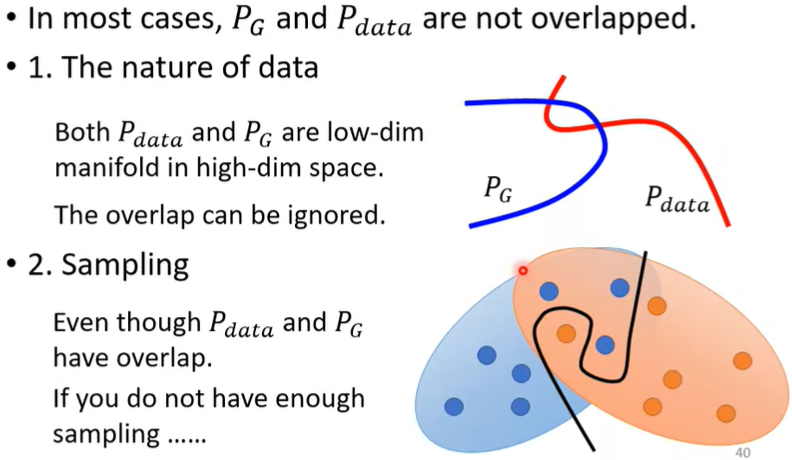
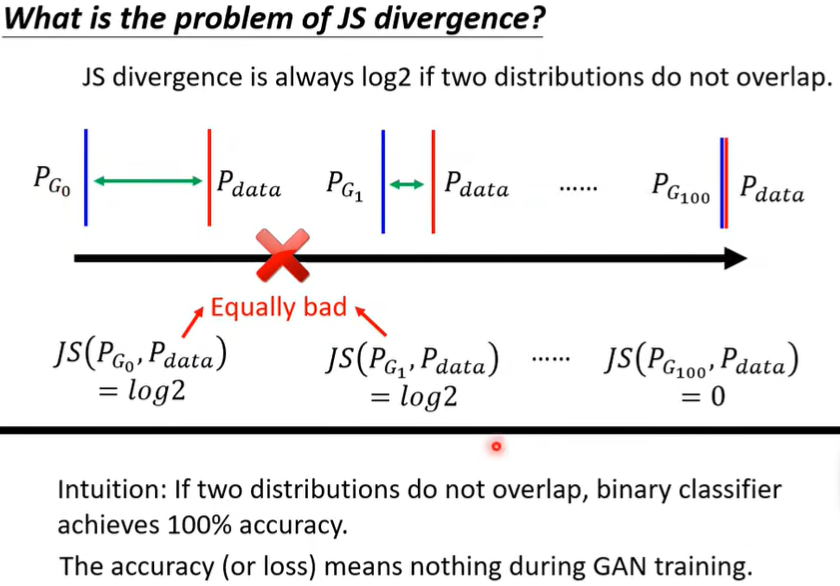
而如果两个distribution不重叠,那么计算的结果就总是log2,这时尽管Generator的效果在变好,JS divergence也看不出来。
那么怎么描述两个distribution之间的相似度呢?此时就出现了Wasserstein distance方法,如下图(图里P,Q视为分别集中在一点)。
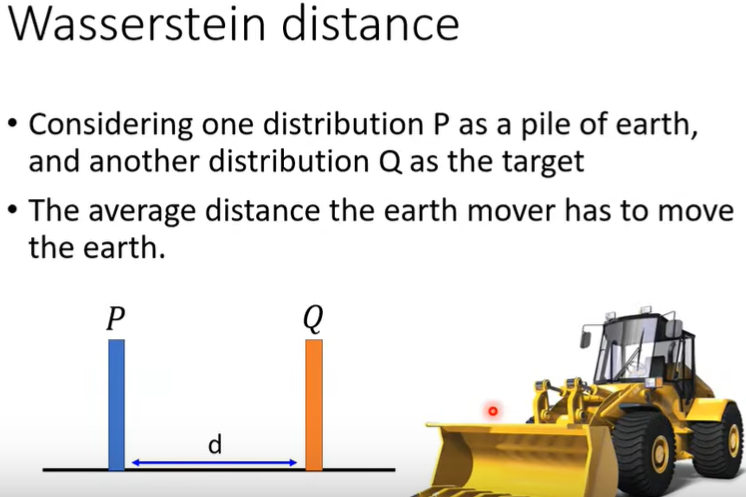
但是将P变成Q可能有多种plans,因此需要穷举出所有的plans,再选择distance最小的那一种。
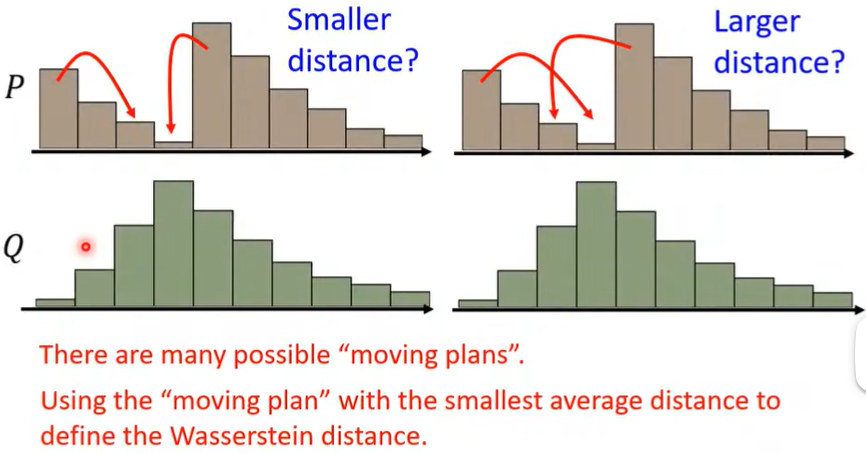
从而Wasserstein distance就能解决JS divergence可能带来的问题了。
(JS需要一次性从0到100才能看出差别,而W可以每次进步一点点,所以它可以找到参数更新的方向)
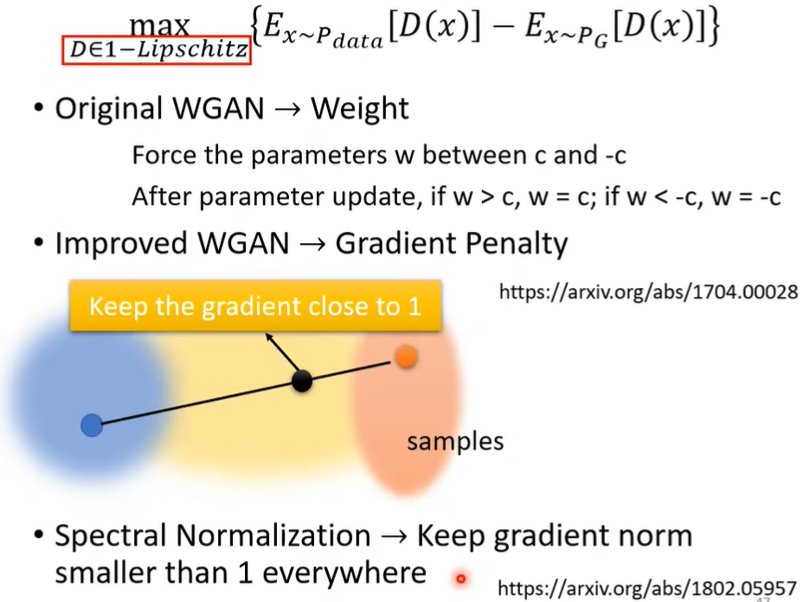
那么如何计算Wasserstein distance?即为计算下面的这个值:

公式注解:如果\(y\) 来自\(P_{data}\),则计算\(D(y)\) 的期望值,如果\(y\) 来自\(P_G\),则计算\(D(y)\) 的期望值并乘负号。我们希望前者期望尽量大,后者期望尽量小。但必须加一个限定条件,即要求\(D\) 必须是一个足够平滑的function!
如何实现\(D\) 足够平滑?WGAN中这样做。
(二)产生文字段落
之前Transformer里的Decoder在这里扮演了Generator的角色。现在,Discriminator的任务是分辨出是真正的文字还是机器产生出的文字,Generator的任务则是不断调整参数,来骗过Discriminator,使其以为它产生的是真正的文字段落。
那么Discriminator和Generator之间如何迭代呢?这里有一个问题,就是Decoder的参数有一点变化时,Discriminator的输出并不会改变,这就导致无法做Gradient decent。在实践中,我们往往会采取一些别的方法来训练。
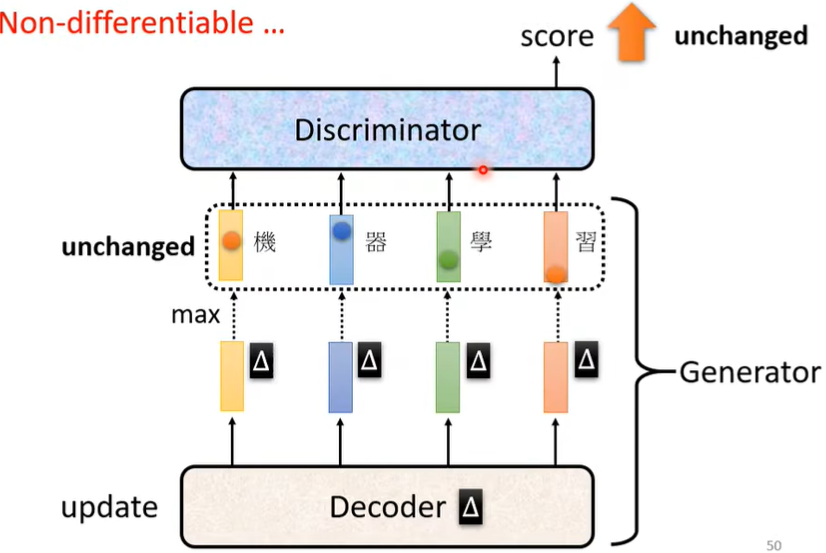
疑问:为什么这个max会导致无法Gradient decent?为什么CNN里面的max-polling还可以做Gradient decent呢?
四、Generator评估
(疑问:不是已经有Discriminator来判断Generator的效果了么,为什么此处需要新的评估方式?它们有什么不同?)
(一)Quality评估
1. Human evaluation
人来评估(昂贵,不客观,不稳定)
2. Image Classifier
训练一个Image Classifier影像辨识系统,GAN产生的图片作为输入,Classifier输出一个机率分布,如果机率分布越集中,则产生的图片越好。
疑问:这个class是什么分类?
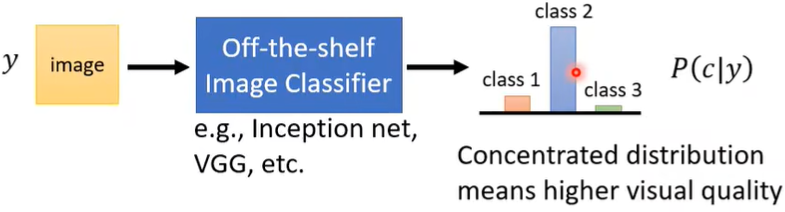
但是这种方法也存在如下问题。
(1)Mode Collapse
也就是Generator生成的图片总是那几张,虽然质量还不错。因为这些图刚好能骗过Discriminator。所以Generator总是在这一块生成。目前还没有很好的解决办法,常用的是在即将Mode Collapse时,便停下训练。

(2)Mode Dropping
也就是产生的资料的distribution只是真实资料distribution的一部分。

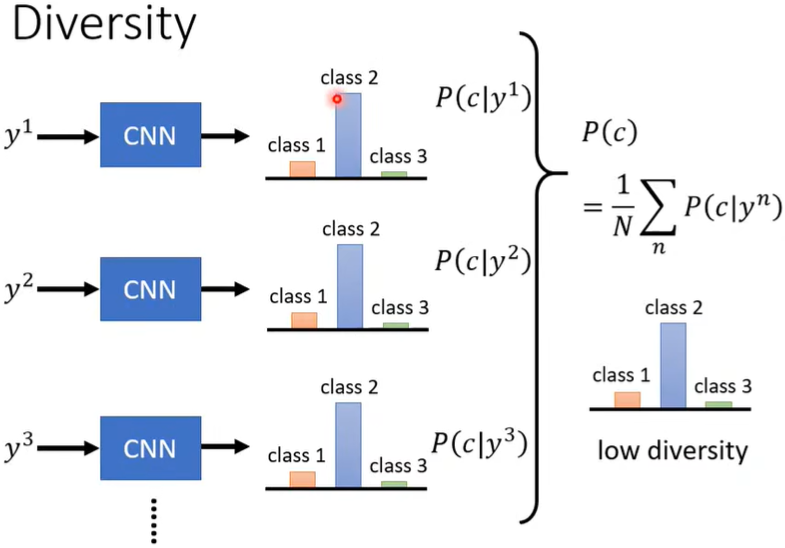
(二)Diversity评估
把生成的图片都丢到Image Classifier里,每张图片都有一个distribution,将所有的distribution平均起来,如果平均的distribution非常集中,则多样性不够,否则多一些足够。
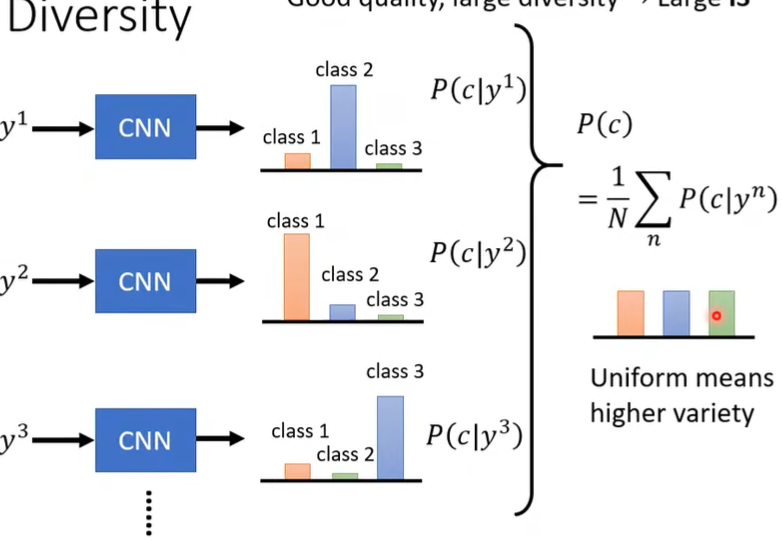
注意:Quality评估和Diversity评估看起来似乎是对立的(因为之前Quality说分布越集中越好,而在Diversity里说越平均、分散越好),其实不然,因为它们关注的对象是不同的!!!Quality关注单张图片,distribution越集中,说明越像某类图,Diversity关注所有图片,平均的distribution越发散,则所有图片的多样性足够。
(三)小结
常用的评估指标有IS,FID。

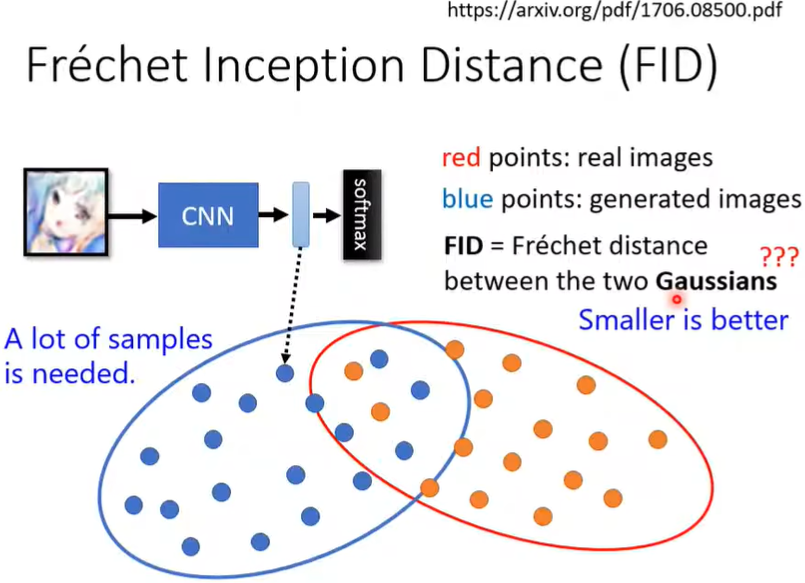
但是以输出全是人脸为例,如果采用IS,它的diversity可能很小(因为全是人脸),但是这却是我们满意的model。所以我们可以采用另一种方法,FID,即我们不拿最后类别的distribution来计算(class1,class2,class3...),而是拿softmax前一步的向量(即使它可能很长/维度高),这样虽然都是人脸,但前一步的向量也不尽相同(发色,瞳色...),此时,更小的值(即更小的distance)效果越好。
当然FID也存在问题,比如需要足够的抽样、两个vector的分布不一定是高斯分布。所以往往我们会同时看多个指标。
五、Conditional Generation
即加上最开始的\(x\),此时可以进行文生图。
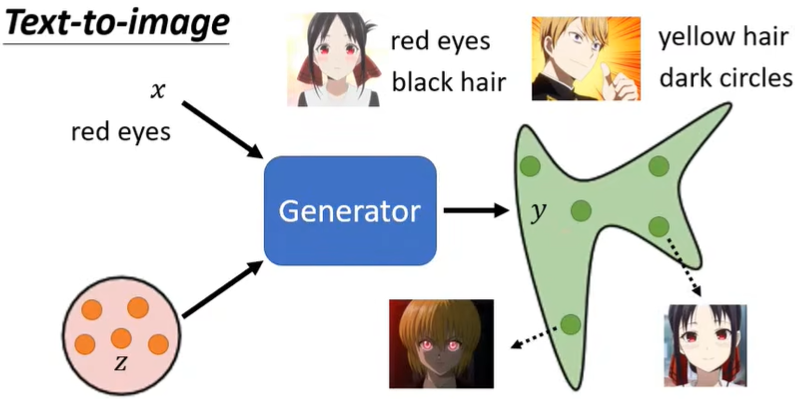
比\(x\) 为red eyes输入时(可以通过多种方法编码red eyes,比如RNN、Transformer),机器会画出红眼睛人物,每次画的都不一定相同,取决于sample到了什么样的\(z\)。
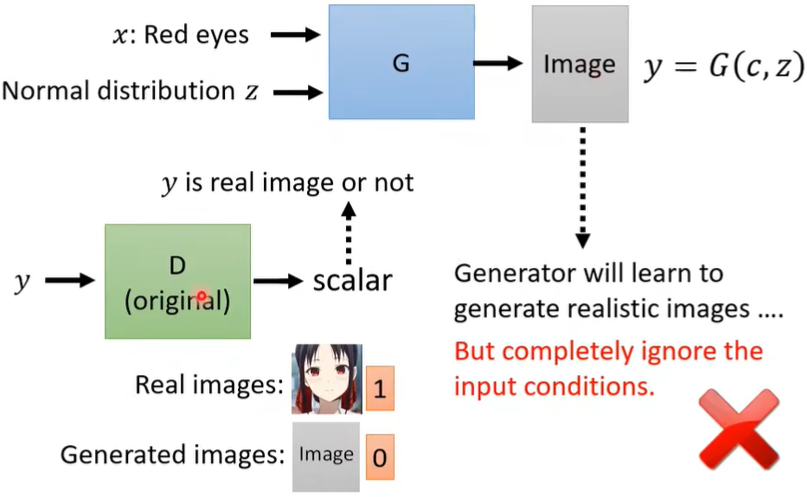
(一)如何训练
如果按照之前的训练方式,会存在一个问题,那就是G会学到如何使生成的图像更真实,也就是骗过D(只要图片像,D就给高分),但是它却可能会完全忽略我们的要求(也就是\(x\)),因为G和D在相互迭代的过程中并没有相关约束,只要足够真实就能得高分,何必再去管condition,如下图。
于是我们要对训练方法做一点改动。因为我们既要求图片好,也要求符合我们的condition,所以我们不仅要给Discriminator吃图片\(y\),还要给它吃condition,这样D的输入就变成了paired data,如(red eyes,image),见下图:
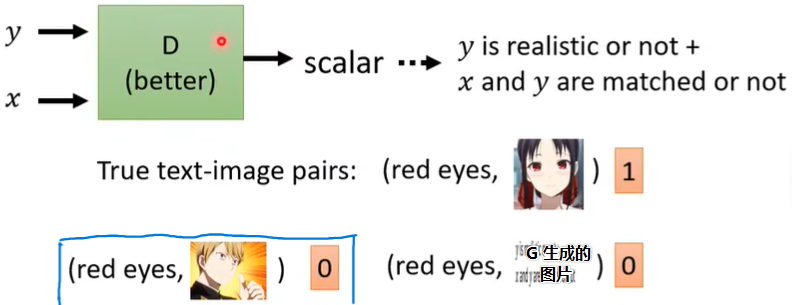
注意:我们还要额外喂蓝框里的,即(condition, 一张与condition不相干但很好的图片),告诉D即使生成了很好的图片,但不满足condition也是不行的,这样model的结果才会更好。
(二)拓展
Conditional GAN不仅可以文生图,也能图生图,或者对图进行一些操作。甚至还有人用声音生图!甚至是动图!
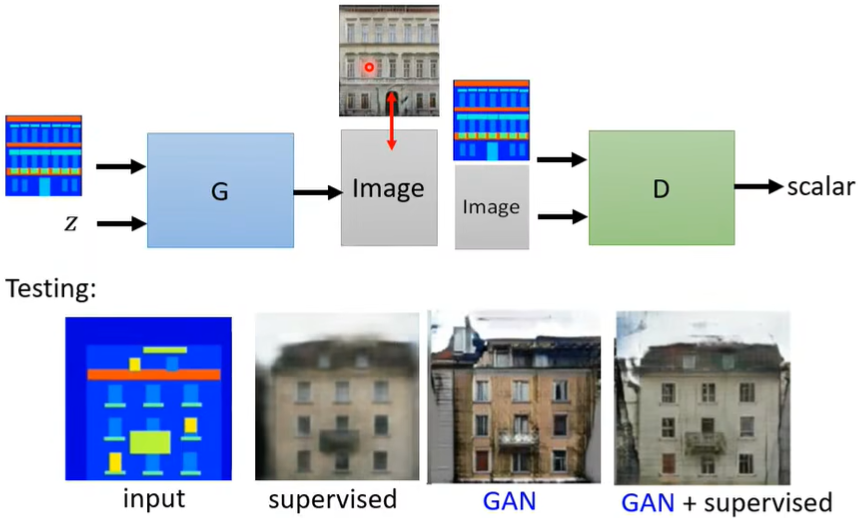
六、Cycle GAN
上面所讲的GAN都是supervised learning(比如我们会标注red eyes),如果没有paired data呢?(比如真人头像换成二次元头像,不会说先给新垣结衣拍个照片,然后把对应的二次元版本画出来,再让机器从中学习,这太麻烦了)
我们可以套用原来的GAN的方法,将原来的\(z\) 替换为Domain x,训练一个Network,使得输出为Domain y。
之前从\(z\) 里面sample,现在从Domain x里面sample。

但是我们会马上发现一个问题,虽然G学会了将Domian x转换为Domain y,但是不见得它们之间有联系,G完全可以把Domain x当作之前的\(z\) 一样,不管输入什么,它只要输出一个足够像二次元的图像就行了,而这两个图像之间并不是风格转换的关系。
这和之前在谈论Conditional GAN的训练问题时很类似,但是在那时我们可以拿出成对的训练资料(red eyes,image)来告诉D,可是在这里我们的数据都是unpaired data啊!!针对这种问题,便提出了Cycle GAN。
所谓Cycle GAN,就是加了一层Network(下图橙色部分),使得G的输出能再经过某种变化转化为原来的输入(越接近越好),这刚好形成了循环,也就是Cycle的由来。(Discriminator的任务不变)
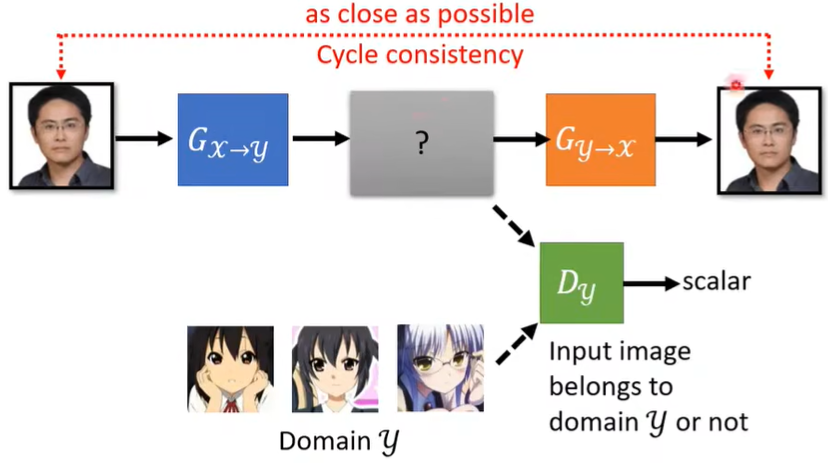
此时,蓝色Generator就不能乱输出了,比如下图的辉夜,否则橙色Generator就根本想象不出要如何将这个输出再还原为输入。
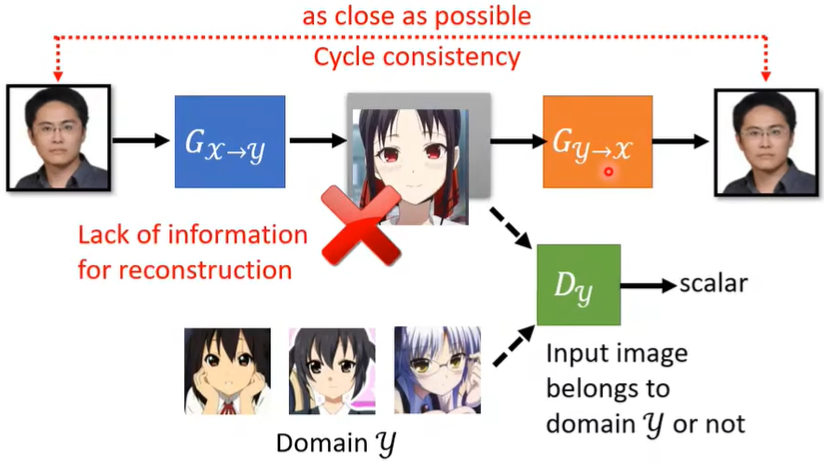
所以蓝色G输出的图片就不能和输入差太多,比如下面的眼镜人,即肯定要有一些关系,这样橙色G才能依据这个关系还原,如果是毫无关系,那橙色G根本无法下手。
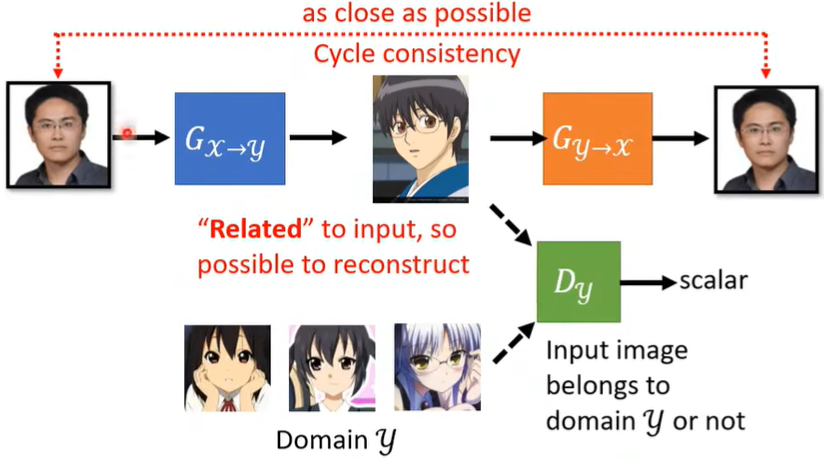
那么问题来了,蓝色G学习的这个关系,就一定是我们想要的那种关系吗?理论上不一定,因为两个G可能刚好学到一个奇怪的关系,使得蓝色G和橙色G都能进行。但实践上,这种现象是不常见的,我们的Network好像非常”懒惰“,它的第一反应就是生成相近的东西,不会说把”眼镜“转换为其他东西。所以Cycle GAN的结果还是比较好的。
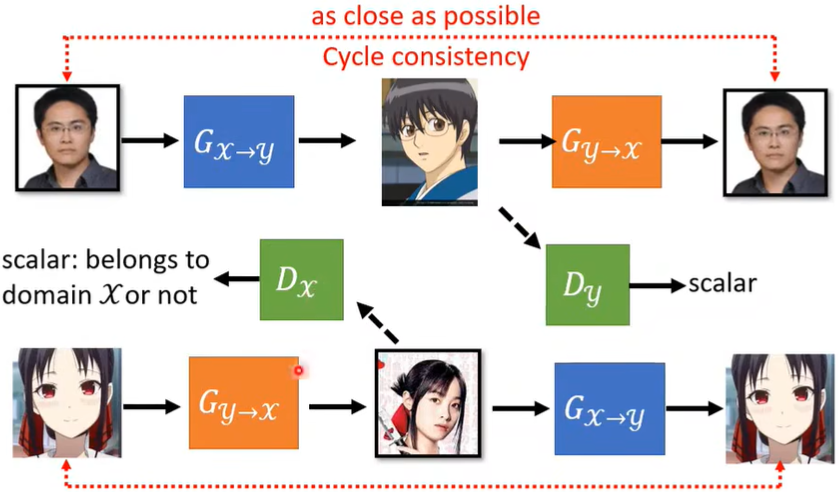
此外,Cycle GAN还可以是双向的,其实就是把之前的真人→二次元倒过来做一次。
Cycle GAN除了图片,也还可以作用于文字,其实研究任何Network时都应该发散思考下它还能不能做其他事?需要做什么变化?
第七讲、Self-supervised Learning
一、BERT
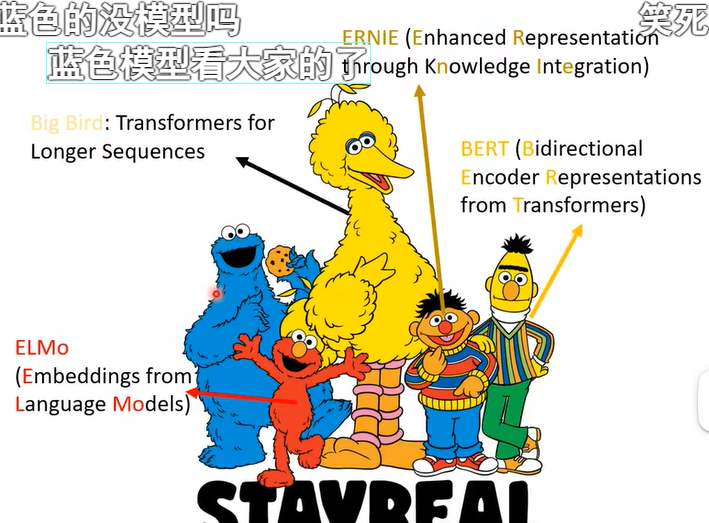
Supervised Learning:需要先标注label后再给机器训练。
Self-supervised Learning(属于Unsupervised Learning)
(一)BERT学习的目标
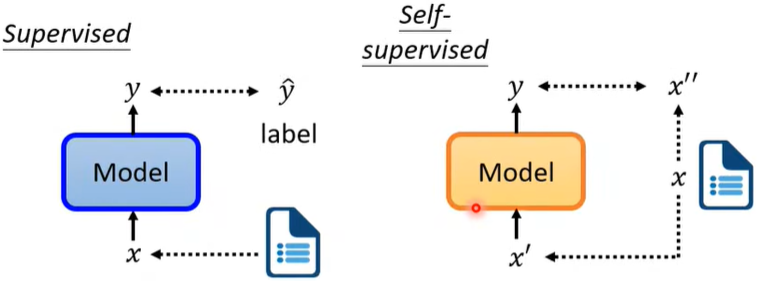
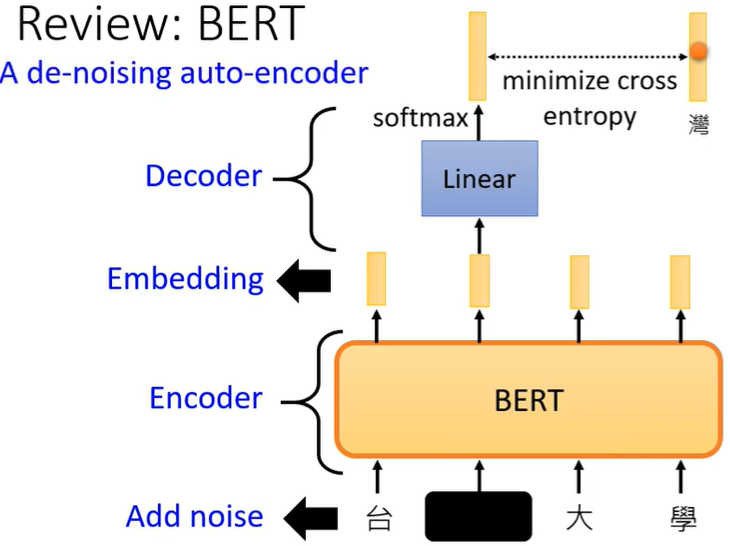
1. Masked token prediction
先随机决定要盖住(黑色部分)哪个字,再决定用两种方法的哪种盖,然后BERT(Transformer Encoding堆起来的参数)和Linear一起训练,学习的目标就是预测出被盖住的词汇是”湾“(我们刚刚把”湾“盖住了),表现为softmax后的输出和”湾“越接近越好(”湾“表示成vector,然后minimize cross entropy)。
其实就是学会做填空题。
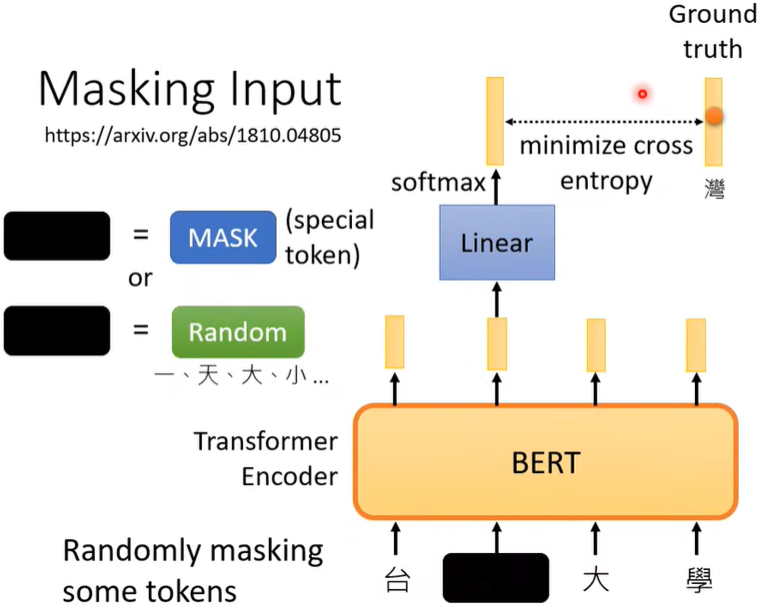
2. Next sentence prediction
判断两句是不是接在一起的,输出Yes/No(这个learning似乎没什么用)。
疑问:这个CLS、SEP是什么?
(二)BERT的应用
BERT进行微调Fine-tune后,就可以处理各式各样的任务,我们把这种任务叫做Downstream Tasks,而我们把在Fine-tune之前产生BERT的过程叫做Pre-train。整个BERT的使用过程其实是Pre-train+Fine-tune的过程。
在Pre-train的Self-supervised Learning阶段,使用大量无标记数据,而在应用到下游任务Downstrean Tasks时,用到少量的标记数据。整个过程可以视为一种半监督方法。
Case1:Seq→class
如情感分析。
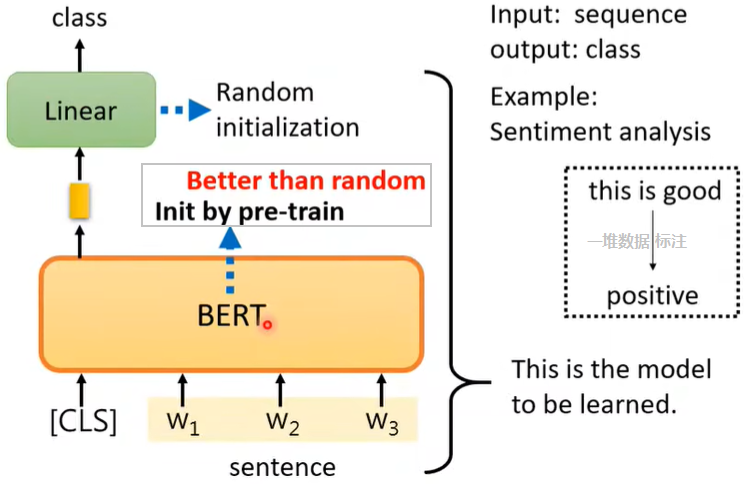
BERT的参数并不是随机初始化的,而是用之前Pre-train的参数。
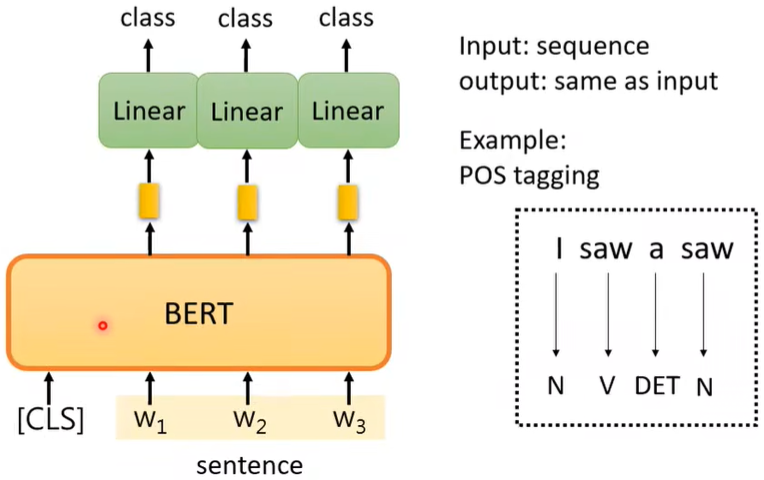
Case2:Seq→Seq
但这里输入输出相同,如词性标注。
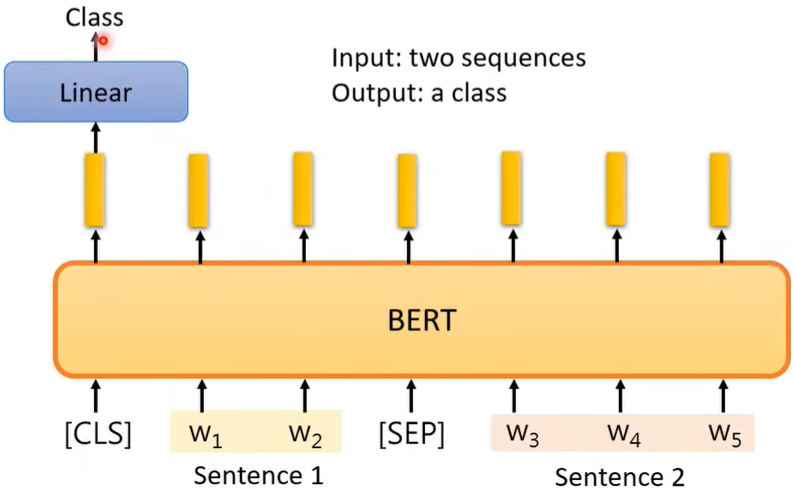
Case3:2Seq→1class
例如Natural Language Inference(NLI)。
比如丢进模型一篇文章以及相关的一个评论,判断这个评论是支持还是反对这篇文章,即输出的为一个class。
Case4:Extraction-based QA
给机器一篇文章,让他读完后问他问题,但是答案始终是文章里的内容。
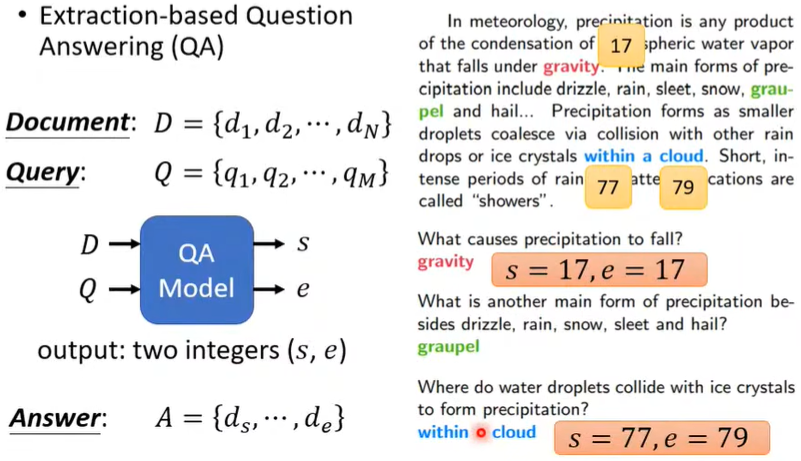
s,e为整数,代表从s到e的所有词汇就是答案
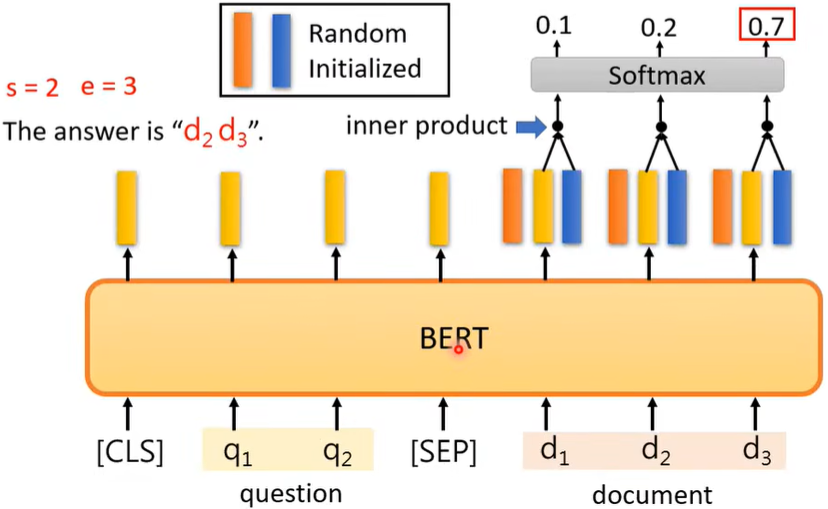
(三)BERT的原理
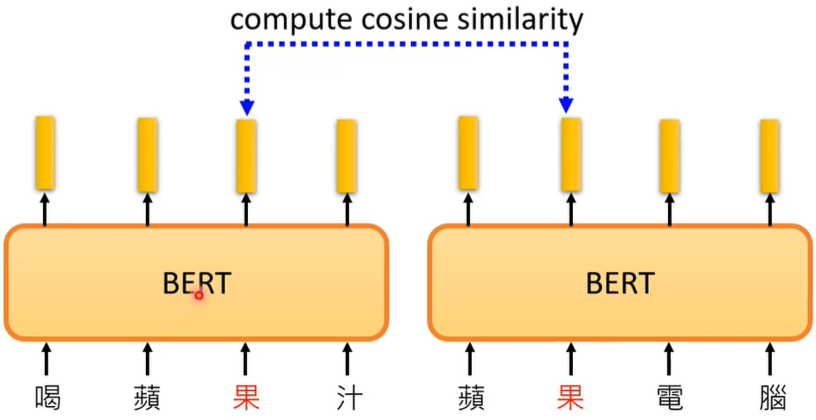
BERT里面的Self-Attention使得同一个字它的输出(vector)也可能不一样,所以BERT能够从上下文里面来学习这个字。
(四)BERT的评估
正如前面所言,BERT十分强大,所以我们往往会测试BERT在多个不同任务上(例如常用任务集GLUE测试得分)的能力,再取平均值来评估这个BERT模型。
(五)Multi-lingual BERT
它是由很多语言来训练的,比如中文、英文、德文、法文等等,通通拿来给它做填空题。
Zero-shot Reading Comprehension
拿英文的QA资料去训练BERT,结果它能够被直接拿来做中文QA,虽然在之前的Pre-train时BERT看过中文,但是只是学会了中文的填空,结果现在能做中文问答,非常的神奇。
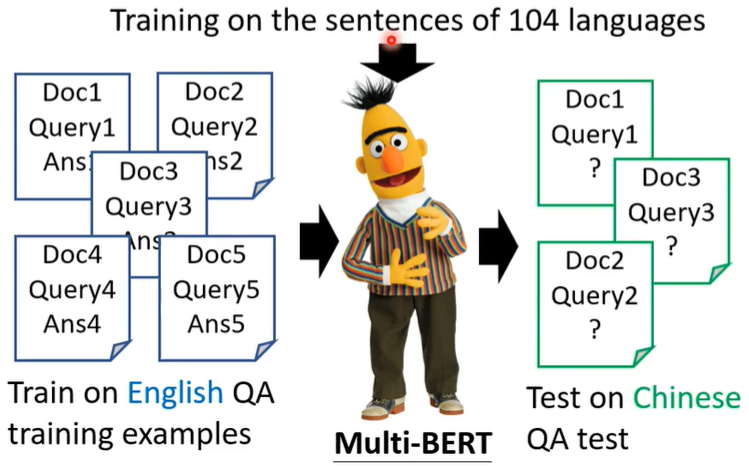
一个简单的解释是:也许对于多语言的BERT来说,不同的语言并没有那么大的差异。无论你用中文还是英文显示,对于具有相同含义的单词,它们的embedding都很接近。所以我们将中文和英文分别embedding后,在进行任意一种模型的训练时,只要加上英汉间的这种差距,就可以实现中文与英文间的转换,而其他地方均不用改变。
第八讲、Auto-encoder
[自编码器]
一、简介
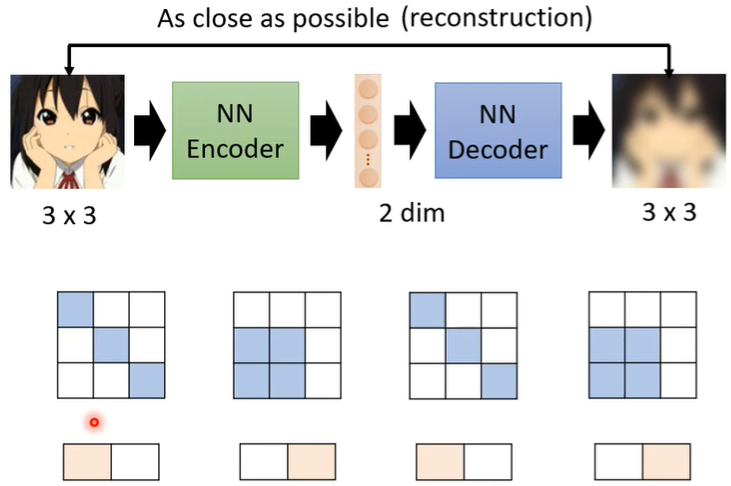
Auto-encoder架构里有一个Encoder和一个Decoder,以图像为例,输入一个image后,Encoder将其压缩为一个向量(编码),接着Decoder再将这个向量还原为image‘(解码),并希望两个image越接近越好。
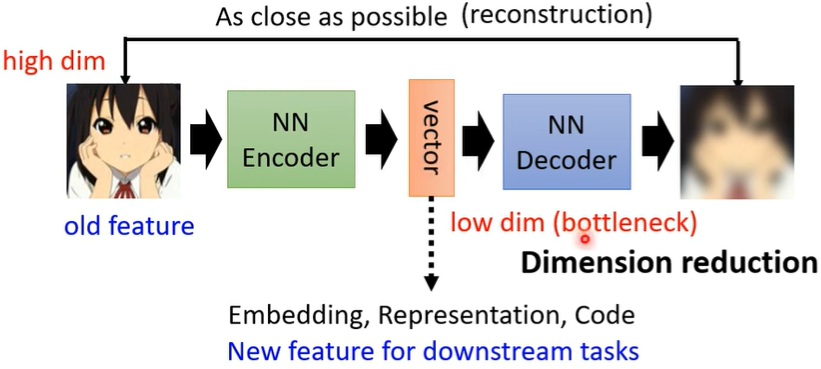
这和Cycle GAN有些相似,输入的图片经过两次的转换后和原来的越接近越好,不过这里是vector。
Encoder做的事是降维(Dimension reduction),Decoder做的事是升维。vector的前后图像都是高维度的,它自己是低维度的,因此把这个vector又叫做Embedding or Representation or Code。
还有一些不是深度学习的降维技术,比如PCA,t-SNE。
二、原理
问:为什么降维又升维后能成功呢?
答:图像的维度高,但很多信息是冗余的,所以我们抽取关键的低维信息,也能表示一张图片。(疑问:这里有待继续理解)
三、拓展
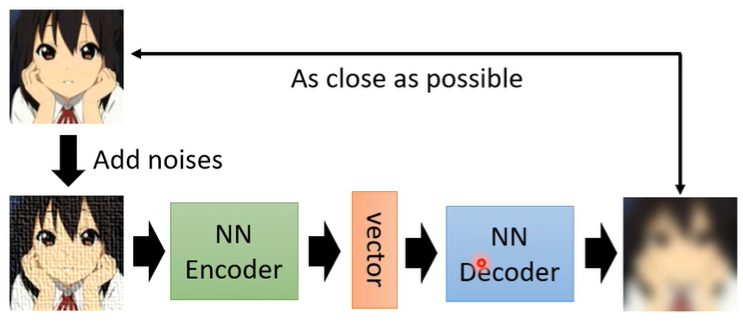
对Auto-encoder稍加改变,即在image上加个noises,再输入Encoder。这样做能使得Encoder-Decoder学会去除图片的杂讯。
这和BERT其实很像,我们进行MASK时其实就是增加了noise。
四、应用
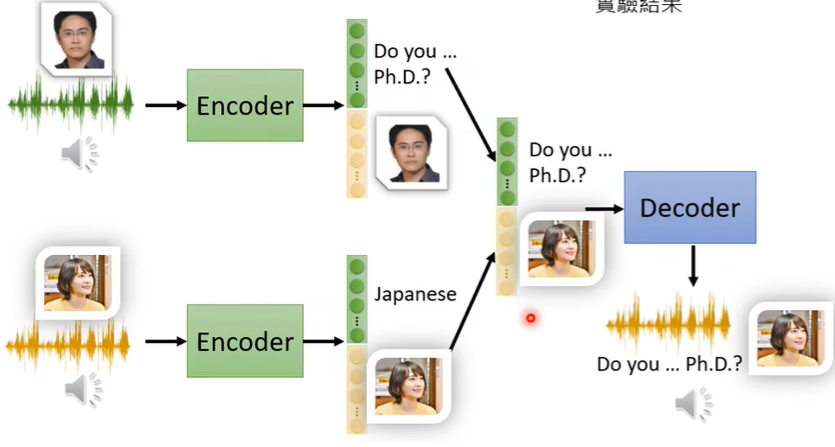
(一)Feature Disentangle
例如如果人的声音有两种信息(说话人的信息和具体内容信息),我们希望通过Auto-encoder分别提取出说话人信息、声音内容信息,借此,我们可以进行语音合成Voice Conversion。
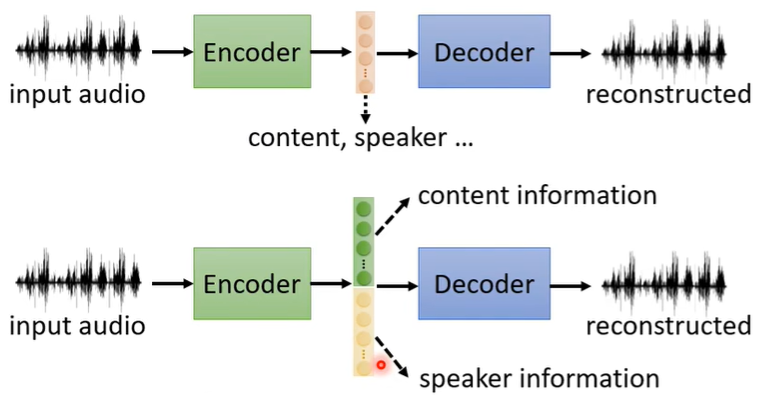
语音合成的方法也很显然,即将一个人的声音特征和另一个人的声音具体内容结合,就达到语音合成(变声器)的目的。
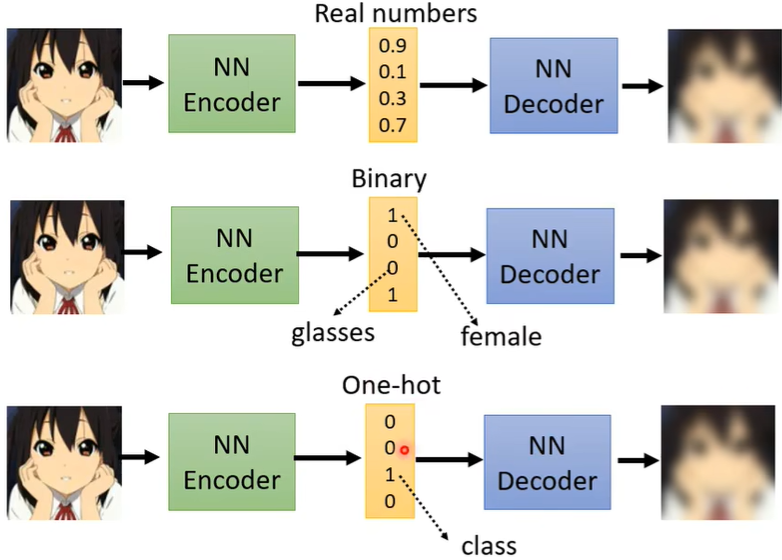
(二)Discrete Representation
[离散表示]
vector部分除了是向量,也可以是Binary(每一维代表了某种特征的有或无),甚至可以是One-hot(也就是强迫只有一个特征,比如做数字识别,将One-hot设置为10维,哪一维出现1就表示这是数字几)
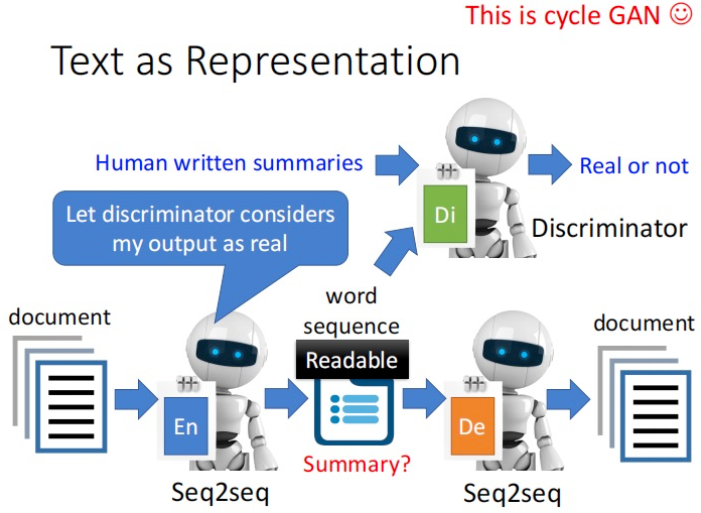
(三)Text as Representation
如果输入输出都为document,那中间的vector是否可以代表summary吗?理论上是可以的,只是直接encoder-decoder学到的摘要可能根本看不懂,因此有人利用GAN概念,加上了Discriminator,即让”vector"和人写的摘要尽可能像,而不是只要机器理解了就行。
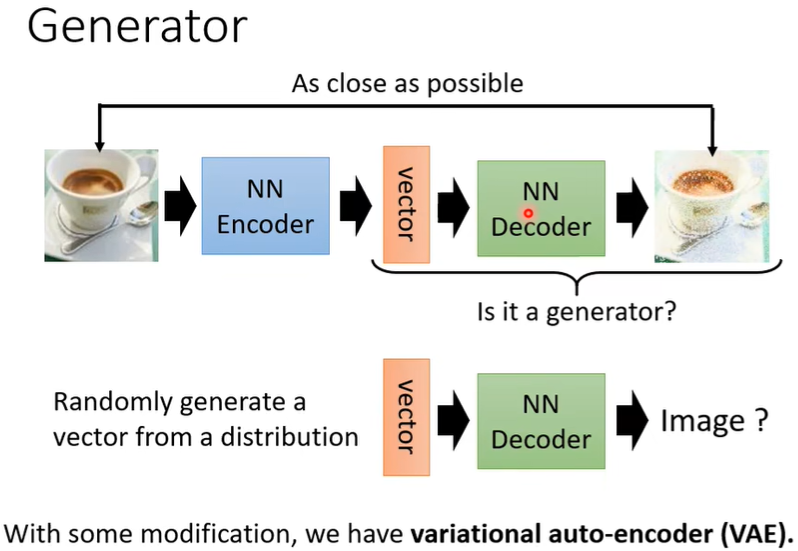
(四)Generator
将Auto-encoder里面的Decoder拿出来,当作Generator来用。
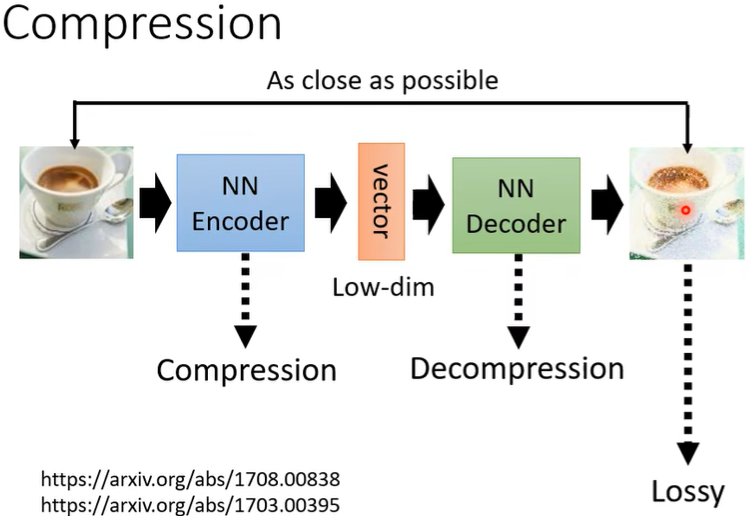
(五)Compression
[压缩]
在前面的介绍里,很容易理解其实Encoder就是压缩,Decoder就是解压,所以可以用Auto-encoder来做压缩,只不过这是有损压缩。
(六)Anomaly Detection
[异常检测]
是否是异常需要根据训练目标来具体决定,某些Data在这个任务里异常,在另一任务里可能不是异常。

例如可以用来做欺诈检测。
(1)比如正样本(正常类)图片,通过encoder编码和decoder解码,计算还原后的照片和原照片的差异,如果很小则认为是这类是在训练时看过的照片(正样本)。
(2)比如负样本(异常类)图片,因为这类照片在训练时没看过,经过encoder和decoder后很难还原回来,差异很大,则认为是异常情况。
如果将欺诈检测视为一个Binary Classification问题,那就需要收集大量的正样本(正常的)和负样本(异常记录)来给机器训练,但是实际上异常资料相较于正常资料是非常少的(比如信用卡交易的异常于正常),所以在收集资料这步就出现问题了。因此我们才用Auto-encoder,即用于只有一个calss的资料,但却想做二分类的时候。
第九讲、Explainable Machine Learning
[可解释的机器学习。不仅要答案,还要求输出得到答案的理由]
一、引言
为什么要Explainable?因为机器有时虽然能给出正确答案,但并不一定意味着它就是理解了问题。比如机器在一个例子里面是通过PNG和JPEG来区分的数码宝贝和宝可梦的,所以其实它根本没有学到什么是数码宝贝什么是宝可梦,但依然会有很高的正确率。
再者,假如我们将机器学习用于医疗诊断,但是如果它只是一个黑箱,没有诊断的理由,我们怎么会放心它的诊断呢?所以Explainable ML也是必要的。
其次,我们还可以根据机器给出的explanation来针对性的改进模型,这样更有效率。
实际上,人脑也是一个黑箱,我们并不完全了解人脑的运作原理,但是却相信他人做出的判断。所以对于Deep Learning的黑箱性质,我们往往不能接受,只是因为缺少一个理由而已,这也是有Explainable ML的一个原因。
具体而言,可以将Explainable ML分成两种:

二、Local Explanation
首先,是什么东西使机器觉得这时一只猫呢?我们可以通过两种方法找出是什么让机器做出了某种判断。
方法一:移除组成要素
如果我们删掉某个component后,Network输出有了巨大变化,说明这个component对机器的判断非常重要。
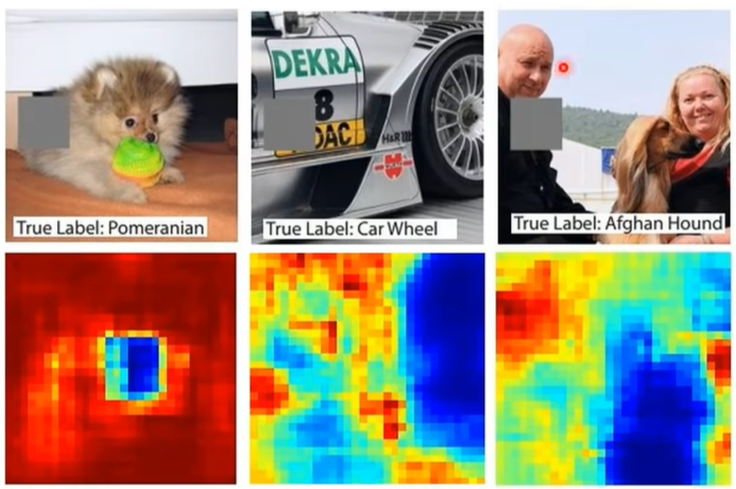
方法二:改变组成要素
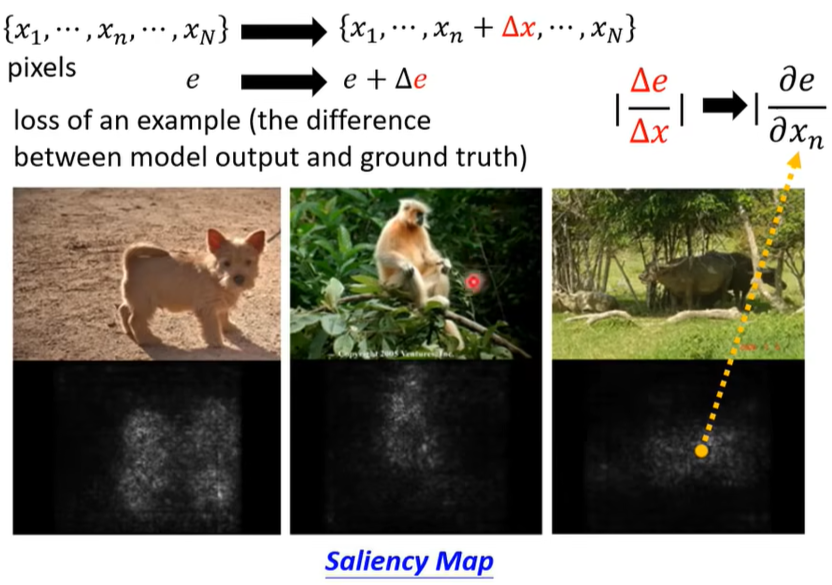
将某个pixels做出一点小变化后(如加个\(\vartriangle x\)),如果loss变化很大,说明这个pixels很重要。用\(\left\vert \frac{\vartriangle e}{\vartriangle x}\right\vert\) 来表示这种重要性,比值越大越重要。
(下面的\(e\) 表示loss of an example,图中越偏白色的部分代表比值越大)
三、Global Explanation
基本思路:当模型输出某一类别的可能的概率值最大时候,输入长什么样子?
假设我们是在识别手写数字,我们既然是想知道在机器眼中,每个数字的样子,那我们就完全可以把结果固定(比如是数字1),然后对输入通过梯度下降来得出,到底哪样的输入会使得结果最显著(即机器认为这张图片最像数字1)。但最后机器给我们的是杂讯(也就是它认为下图中的9张图最像1~9)。所以如果说想找一个图片,让image对应到某一个类别的输出越大越好这种方法来看到机器心里所想的object长什么样子并不容易(机器给我们的可能都是杂讯)。

那么如何让这些杂讯看起来更像我们人类所认为的数字的样子?我们可以加一些限制。例如找一个\(X^*\),既使\(y_i\) 最大,也使\(R(X)\) 最大。

当然这种方法产生的图片看起来还是没那么像,此时还可以利用Generator,将之前的\(X^*\) 替换为\(z^*\)。此时产生的图片已经比较像了。
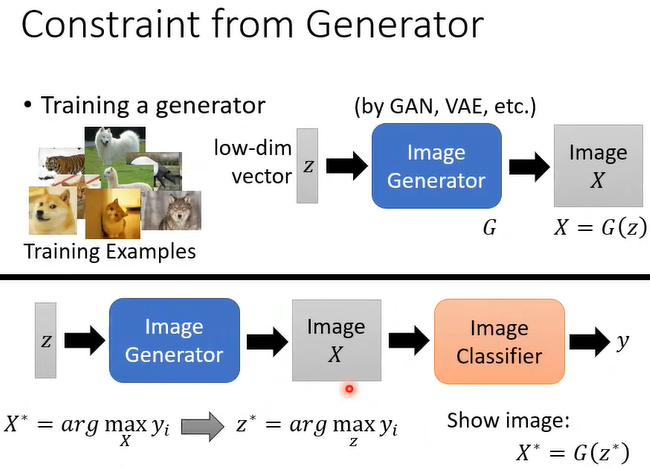
实际上,机器的认知里可能就是认为那样的杂讯就是数字1~9,只是人类无法理解所以不认可,于是想尽办法使机器想的图片和人的认知是一样的,这样人们就皆大欢喜了,Explainable ML其实有这种倾向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号