面试经历学习记录
一、jwt和session的区别
session:
1.用户输入其登录信息
2.服务器验证信息是否正确,并创建一个session,然后将其存储在数据库中
3.服务器为用户生成一个sessionId,将具有sesssionId的Cookie将放置在用户浏览器中
4.在后续请求中,会根据数据库验证sessionID,如果有效,则接受请求
5.一旦用户注销应用程序,会话将在客户端和服务器端都被销毁
jwt:(token(令牌)的用户认证) Java web token
1.用户输入其登录信息
2.服务器验证信息是否正确,并返回已签名的token
3.token储在客户端,例如存在local storage或cookie中
4.之后的HTTP请求都将token添加到请求头里
5.服务器解码JWT,并且如果令牌有效,则接受请求
6.一旦用户注销,令牌将在客户端被销毁,不需要与服务器进行交互一个关键是,令牌是无状态的。后端服务器不需要保存令牌或当前session的记录
区别和优缺点:
基于session和基于jwt的方式的主要区别就是用户的状态保存的位置,session是保存在服务端的,而jwt是保存在客户端的。
jwt的优点:
1. 可扩展性好
应用程序分布式部署的情况下,session需要做多机数据共享,通常可以存在数据库或者redis里面。而jwt不需要。
2. 无状态
jwt不在服务端存储任何状态。RESTful API的原则之一是无状态,发出请求时,总会返回带有参数的响应,不会产生附加影响。用户的认证状态引入这种附加影响,这破坏了这一原则。另外jwt的载荷中可以存储一些常用信息,用于交换信息,有效地使用 JWT,可以降低服务器查询数据库的次数。
jwt的缺点:
1. 安全性
由于jwt的payload是使用base64编码的,并没有加密,因此jwt中不能存储敏感数据。而session的信息是存在服务端的,相对来说更安全。
2. 性能
jwt太长。由于是无状态使用JWT,所有的数据都被放到JWT里,如果还要进行一些数据交换,那载荷会更大,经过编码之后导致jwt非常长,cookie的限制大小一般是4k,cookie很可能放不下,所以jwt一般放在local storage里面。并且用户在系统中的每一次http请求都会把jwt携带在Header里面,http请求的Header可能比Body还要大。而sessionId只是很短的一个字符串,因此使用jwt的http请求比使用session的开销大得多。
3. 一次性
无状态是jwt的特点,但也导致了这个问题,jwt是一次性的。想修改里面的内容,就必须签发一个新的jwt。
(1)无法废弃
通过上面jwt的验证机制可以看出来,一旦签发一个jwt,在到期之前就会始终有效,无法中途废弃。例如你在payload中存储了一些信息,当信息需要更新时,则重新签发一个jwt,但是由于旧的jwt还没过期,拿着这个旧的jwt依旧可以登录,那登录后服务端从jwt中拿到的信息就是过时的。为了解决这个问题,我们就需要在服务端部署额外的逻辑,例如设置一个黑名单,一旦签发了新的jwt,那么旧的就加入黑名单(比如存到redis里面),避免被再次使用。
(2)续签
如果你使用jwt做会话管理,传统的cookie续签方案一般都是框架自带的,session有效期30分钟,30分钟内如果有访问,有效期被刷新至30分钟。一样的道理,要改变jwt的有效时间,就要签发新的jwt。最简单的一种方式是每次请求刷新jwt,即每个http请求都返回一个新的jwt。这个方法不仅暴力不优雅,而且每次请求都要做jwt的加密解密,会带来性能问题。另一种方法是在redis中单独为每个jwt设置过期时间,每次访问时刷新jwt的过期时间。
可以看出想要破解jwt一次性的特性,就需要在服务端存储jwt的状态。但是引入 redis 之后,就把无状态的jwt硬生生变成了有状态了,违背了jwt的初衷。而且这个方案和session都差不多了。
二、vue和react的区别
相同点:
1.使用 Virtual DOM
2.提供了响应式(Reactive)和组件化(Composable)的视图组件。
3.将注意力集中保持在核心库,伴随于此,有配套的路由和负责处理全局状态管理的库。
区别:
1.vue使用了H5的模板语法,较React的jsx语法更简单方便、易上手
2.React组件中书写样式是用定义样式对象的方法引入,Vue可以直接书写css3语法
4.React社区比Vue社区繁荣,支持强大
三、http请求过程
第一步:建立TCP/IP连接,客户端与服务器通过Socket三次握手进行连接
第二步:客户端向服务端发起HTTP请求(例如:POST/login.html http/1.1)
第三步:客户端发送请求头信息,请求内容,最后会发送一空白行,标示客户端请求完毕
第四步:服务器做出应答,表示对于客户端请求的应答,例如:HTTP/1.1 200 OK
第五步:服务器向客户端发送应答头信息
第六步:服务器向客户端发送请求头信息后,也会发送一空白行,标示应答头信息发送完毕,接着就以Content-type要求的数据格式发送数据给客户端
第七步:服务端关闭TCP连接,如果服务器或者客户端增Connection:keep-alive就表示客户端与服务器端继续保存连接,在下次请求时可以继续使用这次的连接
四、vue2和vue3的区别
1、当前最小化并被压缩的 Vue 运行时大小约为 20kB(2.6.10 版为 22.8kB)。
Vue 3.0捆绑包的大小大约会减少一半,即只有10kB!
2.在 Vue2.x 中,在 Vue.prototype 定义了全局 API,导致 Vue 库的整体体积较大,部署生产时即使未用到的 API ,也会被打包。
在 Vue3.x 中,实行按需加载vue的函数API
3.由Option API 变为 Compostion API 结构,提高界面代码的易读性,减少耦合性
4.增强 TypeScript 语法,大大的简化了代码
5.允许组件有从多个根结点,允许在DOM的其它位置进行渲染,可以使用更多底层方法。如:h() 函数等
6.观察者机制的变化:
将vue2中 Object.defineProperty 换成了es6的 Proxy代理器,在目标对象前加了层拦截,将原本对对象属性的操作变为对整个对象的操作,减小data监听密度。
Object.defineProperty缺点:
无法监听数组的变化
需要深度遍历、浪费内存、性能开销大
Proxy可以用于更改方法的默认输出,比如get方法取不到值时不返回undefined,以及在set方法上加验证及数据绑定等。
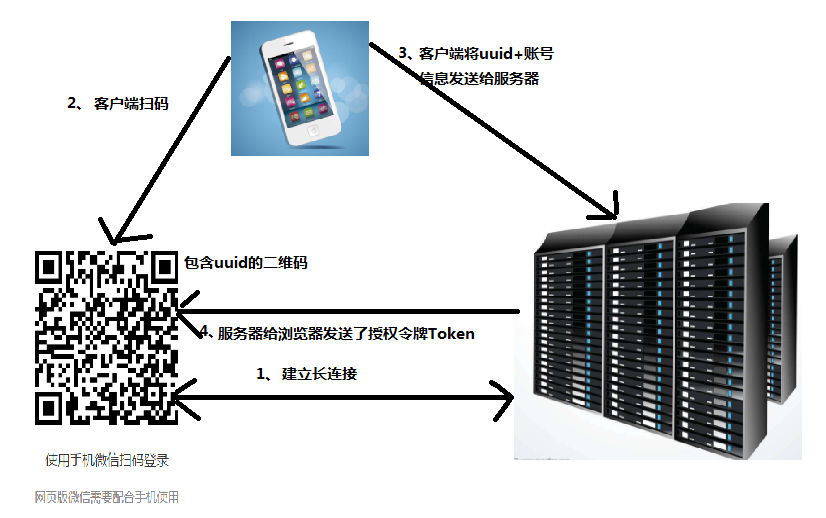
五、微信扫码登录的原理
第一步:用户 A 访问微信网页版,微信服务器为这个会话生成一个全局唯一的 ID,上面的 URL 中 obsbQ-Dzag== 就是这个 ID,此时系统并不知道访问者是谁。
第二步:用户A打开自己的手机微信并扫描这个二维码,并提示用户是否确认登录。
第三步:手机上的微信是登录状态,用户点击确认登录后,手机上的微信客户端将微信账号和这个扫描得到的 ID 一起提交到服务器
第四步:服务器将这个 ID 和用户 A 的微信号绑定在一起,并通知网页版微信,这个 ID 对应的微信号为用户 A,网页版微信加载用户 A 的微信信息,至此,扫码登录全部流程完成,流程图如下:
六、前端工程化
1.统一的开发规范
2.组件化开发
3.构建流程
1.要解决前端工程化的问题,可以从两个角度入手:开发和部署。
从开发角度,要解决的问题包括:
- 提高开发生产效率;
- 降低维护难度。
这两个问题的解决方案有两点:
- 制定开发规范,提高团队协作能力;
- 分治。软件工程中有个很重要的概念叫做模块化开发其中心思想就是分治。
从部署角度,要解决的问题主要是资源管理,包括:
- 代码审查;
- 压缩打包;
- 增量更新;
- 单元测试;
要解决上述问题,需要引入构建/编译阶段。
1-1 开发规范:
开发规范的目的是统一团队成员的编码规范,便于团队协作和代码维护。
1-2 模块、组件化开发:
用通俗的话讲,模块可以理解为零件,比如轮胎上的螺丝钉;而组件则是轮胎,是具备某项完整功能的一个整体。具体到前端领域,一个button是一个模块,一个包括多个button的nav是一个组件。
2. 构建&编译
严谨地讲,构建(build)和编译(compile)是完全不一样的两个概念。两者的颗粒度不同,compile面对的是单文件的编译,build是建立在compile的基础上,对全部文件进行编译。在很多Java IDE中还有另外一个概念:make。make也是建立在compile的基础上,但是只会编译有改动的文件,以提高生产效率。本文不探讨build、compile、make的深层运行机制,下文所述的前段工程化中构建&编译阶段简称为构建阶段。
2.1 构建在前端工程中的角色
在讨论具体如何组织构建任务之前,首先探讨一下在整个前端工程系统中,构建阶段扮演的是什么角色。
一个典型的web前后端协作模式
自Node.js问世以来,前端圈子一直传播着一个词:颠覆。前端工程师要借助Node.js颠覆以往的web开发模式,简单说就是用Node.js取代php、ruby、python等语言搭建web server,在这个颠覆运动中,JavaScript是前端工程师的信心源泉。
那么在大前端模式下,构建又是扮演什么角色呢?请看下图:
大前端体系下,前端开发人员掌握着Node.js搭建的web server层。与上文提到的常规前端开发体系下相比,省略了mock server的角色,但是构建在大前端体系下的作用并没有发生改变。也就是说,不论是大前端还是“小”前端,构建阶段在两种模式下的作用完全一致,构建的作用就是对静态资源以及模板进行处理,换句话说:构建的核心是资源管理。
2.2 资源管理要做什么?
前端的资源可以分为静态资源和模板。模板对静态资源是引用关系,两者相辅相成,构建过程中需要对两种资源使用不同的构建策略。
2.2.1 静态资源构建策略
静态资源包括js、css、图片等文件,目前随着一些新规范和css预编译器的普及,通常开发阶段的静态资源是:
- es6/7规范的文件;
- less/sass等文件(具体看团队技术选型);
- [可选]独立的小图标,在构建阶段使用工具处理成spirit图片。
构建阶段在处理这些静态文件时,基本的功能应包括:
- es6/7转译,比如babel;
- 将less/sass编译成css;
- spirit图片生成;
以上提到的几个功能可以说是为了弥补浏览器自身功能的缺陷,也可以理解为面向语言本身的,我们可以将这些功能统称为预编译。
除了语言本身,静态资源的构建处理还需要考虑web应用的性能因素。比如开发阶段使用组件化开发模式,每个组件有独立的js/css/图片等文件,如果不做处理每个文件独立上线的话,无疑会增加http请求的数量,从而影响web应用的性能表现。针对诸如此类的问题,构建阶段需要包括以下功能:
- 依赖打包。分析文件依赖关系,将同步依赖的的文件打包在一起,减少http请求数量;
- 资源嵌入。比如小于10KB的图片编译为base64格式嵌入文档,减少一次http请求;
- 文件压缩。减小文件体积;
- hash指纹。通过给文件名加入hash指纹,以应对浏览器缓存引起的静态资源更新问题;
- 代码审查。避免上线文件的低级错误;
以上几个功能除了压缩是完全自动化的,其他两个功能都需要人工的配置。比如为了提升首屏渲染性能,开发人员在开发阶段需要尽量减少同步依赖文件的数量。
以上提到的构建功能只是构建工具的基本功能。如果停留在这个阶段,那么也算是个及格的构建工具了,但也仅仅停留在工具层面。对比目前较流行的一些构建产品,比如fis,它具备以上所得的编译功能,同时提供了一些机制以提高开发阶段的生产效率。包括:
- 文件监听。配合动态构建、浏览器自动刷新等功能,提高开发效率;
- mock server。并非所有前端团队都是大前端(事实上很少团队是大前端),即使在大前端体系下,mock server的存在也是很有必要的;
2.2.2 模板的构建策略
模板与静态资源是容器-模块关系。模板直接引用静态资源,经过构建后,静态资源的改动有以下几点:
- url改变。开发环境与线上环境的url肯定是不同的,不同类型的资源甚至根据项目的CDN策略放在不同的服务器上;
- 文件名改变。静态资源经过构建之后,文件名被加上hash指纹,内容的改动导致hash指纹的改变。
对于模板的构建宗旨是在静态资源url和文件名改变后,同步更新模板中资源的引用地址。
现在有种论调是脱离模板的依赖,html由客户端模板引擎渲染,简单说就是文档内容由JavaScript生成,服务端模板只提供一个空壳子和基础的静态资源引用。这种模式越来越普遍,一些较成熟的框架也驱动了这个模式的发展,比如React、Vue等。但目前大多数web产品为了提高首屏的性能表现,仍然无法脱离对服务端渲染的依赖。所以对模板的构建处理仍然很有必要性。
具体的构建策略根据每个团队的情况有所差异,比如有些团队中模板由后端工程师负责,这种模式下fis的资源映射表机制是非常好的解决方案。本文不讨论具体的构建策略,后续文章会详细讲述。
2.2.3 小结
构建可以分为工具层面和平台层面的功能:
- 工具层面
- 预编译,包括es6/7语法转译、css预编译器处理、spirit图片生成;
- 依赖打包;
- 资源嵌入;
- 文件压缩;
- hash指纹;
- 代码审查;
- 模板构建。
- 平台层面
- 文件监听,动态编译;
- mock server。
七、服务端渲染和客户端渲染优缺点
互联网早期,用户使用的浏览器浏览的都是一些没有复杂逻辑的、简单的页面,这些页面都是在后端将 html 拼接好的,然后返回给前端完整的 html 文件,浏览器拿到这个 html 文件之后就可以直接解析展示了,这也就是所谓的服务器端渲染。而随着前端页面的复杂性提高,前端就不仅仅是普通的页面展示了,可能是添加更多功能的组件,复杂性更大,另外,此时 ajax 的兴起,使得页面就开始崇拜前后端分离的开发模式,即后端不提供完整的 html 页面,而是提供一些 api 使得前端可以获取 json 数据,然后前端拿到 json 数据之后再在前端进行 html 页面的拼接,然后展示在浏览器上,这就是所谓的客户端渲染,这样前端就可以专注 UI 的开发,后端专注与逻辑开发。
两者本质的区别?
客户端渲染和服务器端渲染的最重要的区别就是究竟是谁来完成html文件的完整拼接,如果是在服务器端完成的,然后返回给客户端,就是服务器端渲染,而如果是前端做了更多的工作完成了html的拼接,则就是客户端渲染。
服务器端渲染的优缺点是?
优点:
- 前端耗时少。因为后端拼接完了html,浏览器只需要直接渲染出来。
- 有利于SEO。因为在后端有完整的html页面,所以爬虫更容易爬取获得信息,更有利于seo。
- 无需占用客户端资源。即解析模板的工作完全交由后端来做,客户端只要解析标准的html页面即可,这样对于客户端的资源占用更少,尤其是移动端,也可以更省电。
- 后端生成静态化文件。即生成缓存片段,这样就可以减少数据库查询浪费的时间了,且对于数据变化不大的页面非常高效 。
缺点:
- 不利于前后端分离,开发效率低。使用服务器端渲染,则无法进行分工合作,则对于前端复杂度高的项目,不利于项目高效开发。另外,如果是服务器端渲染,则前端一般就是写一个静态html文件,然后后端再修改为模板,这样是非常低效的,并且还常常需要前后端共同完成修改的动作; 或者是前端直接完成html模板,然后交由后端。另外,如果后端改了模板,前端还需要根据改动的模板再调节css,这样使得前后端联调的时间增加。
- 占用服务器端资源。即服务器端完成html模板的解析,如果请求较多,会对服务器造成一定的访问压力。而如果使用前端渲染,就是把这些解析的压力分摊了前端,而这里确实完全交给了一个服务器。
客户端渲染的优缺点是?
优点:
- 前后端分离。前端专注于前端UI,后端专注于api开发,且前端有更多的选择性,而不需要遵循后端特定的模板。
- 体验更好。比如,我们将网站做成SPA或者部分内容做成SPA,这样,尤其是移动端,可以使体验更接近于原生app。
缺点:
- 前端响应较慢。如果是客户端渲染,前端还要进行拼接字符串的过程,需要耗费额外的时间,不如服务器端渲染速度快。
- 不利于SEO。目前比如百度、谷歌的爬虫对于SPA都是不认的,只是记录了一个页面,所以SEO很差。因为服务器端可能没有保存完整的html,而是前端通过js进行dom的拼接,那么爬虫无法爬取信息。 除非搜索引擎的seo可以增加对于JavaScript的爬取能力,这才能保证seo。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号