如何理解假设空间与版本空间?
 周志华的《机器学习》书第1章讲到“版本空间”概念,但是什么是版本空间?假设空间与版本空间有什么区别?看了一些博客后,我这里以书上一道题目为例作为理解。如有错误,还望指正!
周志华的《机器学习》书第1章讲到“版本空间”概念,但是什么是版本空间?假设空间与版本空间有什么区别?看了一些博客后,我这里以书上一道题目为例作为理解。如有错误,还望指正!
以书上P4页的表1.1为例:
我们有这样一个训练数据集:

这里假设空间是由形如 “(色泽= ?)(根蒂=?)(敲声=?)” 的可能取值所形成的假设组成。
- 这里“?”表示尚未确定的取值。
- 我理解是特征属性的所有可能取值组合成的假设集合就是假设空间。
假设空间由3部分组成:
- ① 属性(特征)色泽,根蒂,敲声的取值分别有2,3,3种选择;
- ② 色泽,根蒂,敲声也许无论取什么值都合适,我们分别用通配符“ * ”来表示,于是取值分别有1,1,1种选择;
例如:“ 好瓜<—>(色泽= *)^(根蒂=蜷缩)^(敲声=浊响)”,即“好瓜是根蒂蜷缩、敲声浊响的瓜,什么色泽都行” - ③ 还有一种极端情况,有可能“ 好瓜 ”这个概念根本就不成立,世界上压根就没有“好瓜”这种东西,我们用Ø表示这个假设。
所以,表1.1中,色泽有2中取值,根蒂有3中取值,敲声有3中取值,再加上各自的“通配项”,以及极端情况“好瓜概念根本不成立”的Ø,故假设空间规模大小为:(2+1) * (3+1) * (3+1)+ 1 = 49。
表1.1的训练数据集对应的假设空间具体内容如下:
1 色泽=*,根蒂=*,敲声=*
2 色泽=青绿,根蒂=*,敲声=*
3 色泽=乌黑,根蒂=*,敲声=*
4 色泽=*,根蒂=蜷缩,敲声=*
5 色泽=*,根蒂=硬挺,敲声=*
6 色泽=*,根蒂=稍蜷,敲声=*
7 色泽=*,根蒂=*,敲声=浊响
8 色泽=*,根蒂=*,敲声=清脆
9 色泽=*,根蒂=*,敲声=沉闷
10 色泽=青绿,根蒂=蜷缩,敲声=*
11 色泽=青绿,根蒂=硬挺,敲声=*
12 色泽=青绿,根蒂=稍蜷,敲声=*
13 色泽=乌黑,根蒂=蜷缩,敲声=*
14 色泽=乌黑,根蒂=硬挺,敲声=*
15 色泽=乌黑,根蒂=稍蜷,敲声=*
16 色泽=青绿,根蒂=*,敲声=浊响
17 色泽=青绿,根蒂=*,敲声=清脆
18 色泽=青绿,根蒂=*,敲声=沉闷
19 色泽=乌黑,根蒂=*,敲声=浊响
20 色泽=乌黑,根蒂=*,敲声=清脆
21 色泽=乌黑,根蒂=*,敲声=沉闷
22 色泽=*,根蒂=蜷缩,敲声=浊响
23 色泽=*,根蒂=蜷缩,敲声=清脆
24 色泽=*,根蒂=蜷缩,敲声=沉闷
25 色泽=*,根蒂=硬挺,敲声=浊响
26 色泽=*,根蒂=硬挺,敲声=清脆
27 色泽=*,根蒂=硬挺,敲声=沉闷
28 色泽=*,根蒂=稍蜷,敲声=浊响
29 色泽=*,根蒂=稍蜷,敲声=清脆
30 色泽=*,根蒂=稍蜷,敲声=沉闷
31 色泽=青绿,根蒂=蜷缩,敲声=浊响
32 色泽=青绿,根蒂=蜷缩,敲声=清脆
33 色泽=青绿,根蒂=蜷缩,敲声=沉闷
34 色泽=青绿,根蒂=硬挺,敲声=浊响
35 色泽=青绿,根蒂=硬挺,敲声=清脆
36 色泽=青绿,根蒂=硬挺,敲声=沉闷
37 色泽=青绿,根蒂=稍蜷,敲声=浊响
38 色泽=青绿,根蒂=稍蜷,敲声=清脆
39 色泽=青绿,根蒂=稍蜷,敲声=沉闷
40 色泽=乌黑,根蒂=蜷缩,敲声=浊响
41 色泽=乌黑,根蒂=蜷缩,敲声=清脆
42 色泽=乌黑,根蒂=蜷缩,敲声=沉闷
43 色泽=乌黑,根蒂=硬挺,敲声=浊响
44 色泽=乌黑,根蒂=硬挺,敲声=清脆
45 色泽=乌黑,根蒂=硬挺,敲声=沉闷
46 色泽=乌黑,根蒂=稍蜷,敲声=浊响
47 色泽=乌黑,根蒂=稍蜷,敲声=清脆
48 色泽=乌黑,根蒂=稍蜷,敲声=沉闷
49 Ø
- 1.我们可以把学习过程看作一个在假设(hypothesis)组成的空间中进行搜索的过程。搜索过程中可以不断删除与正例不一致的假设、和(或)与反例一致的假设。最终将会获得与训练集一致(即对所有训练样本能够进行正确判断)的假设,这就是我们学得的结果。
- 2.现实问题中我们常面临很大的假设空间,但学习过程是基于有限样本训练集进行的,因此有可能有多个假设与训练集一致,即存在着一个与训练集一致的“假设集合”,我们称之为“版本空间(version space)”。
版本空间定义1:
版本空间(version space)是概念学习中与已知数据集一致的所有假设(hypothesis)的子集集合。
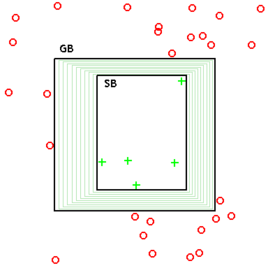
对于二维空间中的“矩形”假设(上图),绿色加号代表正类样本,红色小圈代表负类样本。 GB 是最大泛化正假设边界(maximally General positive hypothesis Boundary), SB 是最大精确正假设边界(maximally Specific positive hypothesis Boundary). GB与SB所围成的区域中的矩形即为版本空间中的假设,也即GB与SB围成的区域就是版本空间。
在一些需要对假设的泛化能力排序的情形下,就可以通过GB与SB这两个上下界来表示版本空间。在学习的过程中,学习算法就可以只在GB、SB这两个代表集合上操作。我理解的是,以表1.1为例,负类样本相当于在假设空间中,与表1.1与正例不一致的假设、和(或)与反例一致的假设(即与表1.1不吻合的假设)数据集,正类样本即是表1.1中的数据集。版本空间是边界GB和边界SB之间围成的区域。
按照上述过程进行学习:
(1,(色泽=青绿、根蒂=蜷缩、敲声=浊响),好瓜)
可以删除假设空间中的3、5、6、8、9、11-15、17-21、23-30、32-49
(2,(色泽=乌黑、根蒂=蜷缩、敲声=浊响),好瓜)
可以删除剩余假设空间中的2、10、16、31
(3,(色泽=青绿、根蒂=硬挺、敲声=清脆),坏瓜)
可以删除剩余假设空间中的1
(4,(色泽=乌黑、根蒂=稍蜷、敲声=沉闷),坏瓜)
剩余假设空间中无可删除的假设
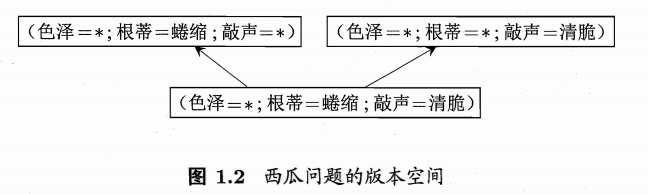
学习过后剩余的假设为:
4 色泽=*,根蒂=蜷缩,敲声=*
7 色泽=*,根蒂=*,敲声=浊响
22 色泽=*,根蒂=蜷缩,敲声=浊响
这就是最后的“假设集合”,也就是“版本空间”。
参考资料:
本文版权归作者和博客园共有,欢迎转载,转载请注明出处和链接来源。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号