基于pytorch的电影推荐系统
本文介绍一个基于pytorch的电影推荐系统。
代码移植自https://github.com/chengstone/movie_recommender。
原作者用了tf1.0实现了这个基于movielens的推荐系统,我这里用pytorch0.4做了个移植。
本文实现的模型Github仓库:https://github.com/Holy-Shine/movie_recommend_system
1. 总体框架
先来看下整个文件包下面的文件构成:
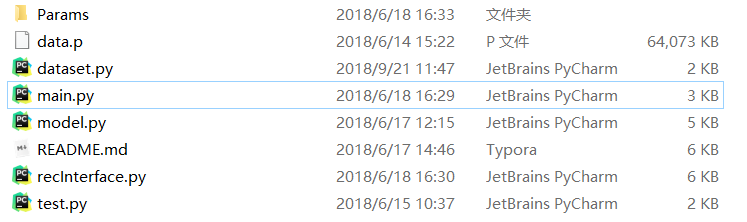
其中:
Params: 保存模型的参数文件以及模型训练后得到的用户和电影特征向量
data.p:保存了训练和测试数据
dataset.py:继承于pytorch的Dataset类,是一个数据batch的generator
model.py:推荐系统的pytorch模型实现
main.py:主要的训练过程
recInterface.py: 推荐系统训练完毕后,根据模型的中间输出结果作为电影和用户的特征向量,这个推荐接口根据这些向量的空间关系提供一些定向推荐结果
test.py: 无用,纯用来测试输入维度是否和模型match
2. 数据集接口dataset.py
dataset.py 加载 data.p 到内存,用生成器的方式不断形成指定batch_size大小的批数据,输入到模型进行训练。我们先来看看这个data.p 长什么样。
data.p 实际上是保存了输入数据的pickle文件,加载完毕后是一个pandas(>=0.22.0)的DataFrame对象(如下图所示)

用下面代码可以加载和观察数据集(建议使用 jupyternotebook )
import pickle as pkl
data = pkl.load(open('data.p','rb'))
data
下面来看看数据加载类怎么实现:
class MovieRankDataset(Dataset):
def __init__(self, pkl_file):
self.dataFrame = pkl.load(open(pkl_file,'rb'))
def __len__(self):
return len(self.dataFrame)
def __getitem__(self, idx):
# user data
uid = self.dataFrame.ix[idx]['user_id']
gender = self.dataFrame.ix[idx]['user_gender']
age = self.dataFrame.ix[idx]['user_age']
job = self.dataFrame.ix[idx]['user_job']
# movie data
mid = self.dataFrame.ix[idx]['movie_id']
mtype=self.dataFrame.ix[idx]['movie_type']
mtext=self.dataFrame.ix[idx]['movie_title']
# target
rank = torch.FloatTensor([self.dataFrame.ix[idx]['rank']])
user_inputs = {
'uid': torch.LongTensor([uid]).view(1,-1),
'gender': torch.LongTensor([gender]).view(1,-1),
'age': torch.LongTensor([age]).view(1,-1),
'job': torch.LongTensor([job]).view(1,-1)
}
movie_inputs = {
'mid': torch.LongTensor([mid]).view(1,-1),
'mtype': torch.LongTensor(mtype),
'mtext': torch.LongTensor(mtext)
}
sample = {
'user_inputs': user_inputs,
'movie_inputs':movie_inputs,
'target':rank
}
return sample
pytorch要求自定义类实现三个函数:
__init__()用来初始化一些东西__len__()用来获取整个数据集的样本个数__getitem(idx)__根据索引idx获取相应的样本
重点看下__getiem(idx)__,主要使用dataframe的dataFrame.ix[idx]['user_id']来获取相应的属性。由于整个模型是用户+电影双通道输入,所以最后将提取的属性组装成两个dict,最后再组成一个sample返回。拆解过程在训练时进行。(组装时提前用torch.tensor()将向量转为pytorch支持的tensor张量)
3. 推荐模型model.py
先看一下我们要实现的模型图:

(注:图片来自原作者仓库)
pytorch依然要求用户自定义的模型类至少实现两个方法:__init__()和__forward__(),其中__init__()用来初始化(定义一些pytorch的线性层、卷积层、embedding层等等),__forward__()用来前向传播和反向传播误差梯度信息。
分别来看下model.py里的这两个函数:
3.1 初始化函数
def __init__(self, user_max_dict, movie_max_dict, convParams, embed_dim=32, fc_size=200):
'''
Args:
user_max_dict: the max value of each user attribute. {'uid': xx, 'gender': xx, 'age':xx, 'job':xx}
user_embeds: size of embedding_layers.
movie_max_dict: {'mid':xx, 'mtype':18, 'mword':15}
fc_sizes: fully connect layer sizes. normally 2
'''
super(rec_model, self).__init__()
# --------------------------------- user channel ----------------------------------------------------------------
# user embeddings
self.embedding_uid = nn.Embedding(user_max_dict['uid'], embed_dim)
self.embedding_gender = nn.Embedding(user_max_dict['gender'], embed_dim // 2)
self.embedding_age = nn.Embedding(user_max_dict['age'], embed_dim // 2)
self.embedding_job = nn.Embedding(user_max_dict['job'], embed_dim // 2)
# user embedding to fc: the first dense layer
self.fc_uid = nn.Linear(embed_dim, embed_dim)
self.fc_gender = nn.Linear(embed_dim // 2, embed_dim)
self.fc_age = nn.Linear(embed_dim // 2, embed_dim)
self.fc_job = nn.Linear(embed_dim // 2, embed_dim)
# concat embeddings to fc: the second dense layer
self.fc_user_combine = nn.Linear(4 * embed_dim, fc_size)
# --------------------------------- movie channel -----------------------------------------------------------------
# movie embeddings
self.embedding_mid = nn.Embedding(movie_max_dict['mid'], embed_dim) # normally 32
self.embedding_mtype_sum = nn.EmbeddingBag(movie_max_dict['mtype'], embed_dim, mode='sum')
self.fc_mid = nn.Linear(embed_dim, embed_dim)
self.fc_mtype = nn.Linear(embed_dim, embed_dim)
# movie embedding to fc
self.fc_mid_mtype = nn.Linear(embed_dim * 2, fc_size)
# text convolutional part
# wordlist to embedding matrix B x L x D L=15 15 words
self.embedding_mwords = nn.Embedding(movie_max_dict['mword'], embed_dim)
# input word vector matrix is B x 15 x 32
# load text_CNN params
kernel_sizes = convParams['kernel_sizes']
# 8 kernel, stride=1,padding=0, kernel_sizes=[2x32, 3x32, 4x32, 5x32]
self.Convs_text = [nn.Sequential(
nn.Conv2d(1, 8, kernel_size=(k, embed_dim)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(15 - k + 1, 1), stride=(1, 1))
).to(device) for k in kernel_sizes]
# movie channel concat
self.fc_movie_combine = nn.Linear(embed_dim * 2 + 8 * len(kernel_sizes), fc_size) # tanh
# BatchNorm layer
self.BN = nn.BatchNorm2d(1)
__init__() 有5个参数:
-
user_max_dict/movie_max_dict:用户/电影字典,即用户/电影的一些属性的最大值,决定我们的模型的embedding表的宽度。user_max_dict={ 'uid':6041, # 6040 users 'gender':2, 'age':7, 'job':21 } movie_max_dict={ 'mid':3953, # 3952 movies 'mtype':18, 'mword':5215 # 5215 words }在我们的模型中,这些字典作为固定的参数被传入。
-
convParams:文本卷积网络超参,表示网络层数和卷积核大小。convParams={ 'kernel_sizes':[2,3,4,5] } -
embed_dim:全局的embed大小,表示特征空间的维度。 -
fc_size: 最后的全连接神经元个数
最后分别根据用户通道定义一些全连接层、embedding层、文本卷积层(标题文本已经被one-hot化存入数据集中)
3.2 前向传播
直接看代码吧:
def forward(self, user_input, movie_input):
# pack train_data
uid = user_input['uid']
gender = user_input['gender']
age = user_input['age']
job = user_input['job']
mid = movie_input['mid']
mtype = movie_input['mtype']
mtext = movie_input['mtext']
if torch.cuda.is_available():
uid, gender, age, job,mid,mtype,mtext = \
uid.to(device), gender.to(device), age.to(device), job.to(device), mid.to(device), mtype.to(device), mtext.to(device)
# user channel
feature_uid = self.BN(F.relu(self.fc_uid(self.embedding_uid(uid))))
feature_gender = self.BN(F.relu(self.fc_gender(self.embedding_gender(gender))))
feature_age = self.BN(F.relu(self.fc_age(self.embedding_age(age))))
feature_job = self.BN(F.relu(self.fc_job(self.embedding_job(job))))
# feature_user B x 1 x 200
feature_user = F.tanh(self.fc_user_combine(
torch.cat([feature_uid, feature_gender, feature_age, feature_job], 3)
)).view(-1,1,200)
# movie channel
feature_mid = self.BN(F.relu(self.fc_mid(self.embedding_mid(mid))))
feature_mtype = self.BN(F.relu(self.fc_mtype(self.embedding_mtype_sum(mtype)).view(-1,1,1,32)))
# feature_mid_mtype = torch.cat([feature_mid, feature_mtype], 2)
# text cnn part
feature_img = self.embedding_mwords(mtext) # to matrix B x 15 x 32
flattern_tensors = []
for conv in self.Convs_text:
flattern_tensors.append(conv(feature_img.view(-1,1,15,32)).view(-1,1, 8)) # each tensor: B x 8 x1 x 1 to B x 8
feature_flattern_dropout = F.dropout(torch.cat(flattern_tensors,2), p=0.5) # to B x 32
# feature_movie B x 1 x 200
feature_movie = F.tanh(self.fc_movie_combine(
torch.cat([feature_mid.view(-1,1,32), feature_mtype.view(-1,1,32), feature_flattern_dropout], 2)
))
output = torch.sum(feature_user * feature_movie, 2) # B x rank
return output, feature_user, feature_movie
分为两步:
- 拆解数据:根据用户和电影dict的键值拆解sample里的数据
- 前向传播:没有特别的,就是用
__init__()定义的网络层来传递张量即可。
4. 主程序main.py
还是先来看代码:
def train(model,num_epochs=5, lr=0.0001):
loss_function = nn.MSELoss()
optimizer = optim.Adam(model.parameters(),lr=lr)
datasets = MovieRankDataset(pkl_file='data.p')
dataloader = DataLoader(datasets,batch_size=256,shuffle=True)
losses=[]
writer = SummaryWriter()
for epoch in range(num_epochs):
loss_all = 0
for i_batch,sample_batch in enumerate(dataloader):
user_inputs = sample_batch['user_inputs']
movie_inputs = sample_batch['movie_inputs']
target = sample_batch['target'].to(device)
model.zero_grad()
tag_rank , _ , _ = model(user_inputs, movie_inputs)
loss = loss_function(tag_rank, target)
if i_batch%20 ==0:
writer.add_scalar('data/loss', loss, i_batch*20)
print(loss)
loss_all += loss
loss.backward()
optimizer.step()
print('Epoch {}:\t loss:{}'.format(epoch,loss_all))
writer.export_scalars_to_json("./test.json")
writer.close()
if __name__=='__main__':
model = rec_model(user_max_dict=user_max_dict, movie_max_dict=movie_max_dict, convParams=convParams)
model=model.to(device)
# train model
#train(model=model,num_epochs=1)
#torch.save(model.state_dict(), 'Params/model_params.pkl')
# get user and movie feature
# model.load_state_dict(torch.load('Params/model_params.pkl'))
# from recInterface import saveMovieAndUserFeature
# saveMovieAndUserFeature(model=model)
# test recsys
from recInterface import getKNNitem,getUserMostLike
print(getKNNitem(itemID=100,K=10))
print(getUserMostLike(uid=100))
流程大致如下:
- 调用
model.py构建推荐模型。 - 训练模型
train(model,num_epochs=5, lr=0.0001)- 选择损失函数
- 选择优化器Adam
- 构建数据加载器dataloader
- 开始训练,反向传播,优化参数
- 保存模型参数
5. 推荐接口recInterface.py
模型训练结束后,我们可以得到电影的特征和用户的特征(可以看网络图中最后一层连接前两个通道的输出即为用户/电影特征,我们在训练结束后将其返回并保存起来)。
使用recInterface.py里的saveMovieAndUserFeature(model)可以将这两个特征保存为Params/feature_data.pkl,同时保存用户和电影的字典,用来获取特定用户或者电影的信息,格式以用户为例:{'uid':uid,'gender':gender,'age':age,'job':job}
def def saveMovieAndUserFeature(model):
'''
Save Movie and User feature into HD
'''
batch_size = 256
datasets = MovieRankDataset(pkl_file='data.p')
dataloader = DataLoader(datasets, batch_size=batch_size, shuffle=False,num_workers=4)
# format: {id(int) : feature(numpy array)}
user_feature_dict = {}
movie_feature_dict = {}
movies={}
users = {}
with torch.no_grad():
for i_batch, sample_batch in enumerate(dataloader):
user_inputs = sample_batch['user_inputs']
movie_inputs = sample_batch['movie_inputs']
# B x 1 x 200 = 256 x 1 x 200
_, feature_user, feature_movie = model(user_inputs, movie_inputs)
# B x 1 x 200 = 256 x 1 x 200
feature_user = feature_user.cpu().numpy()
feature_movie = feature_movie.cpu().numpy()
for i in range(user_inputs['uid'].shape[0]):
uid = user_inputs['uid'][i] # uid
gender = user_inputs['gender'][i]
age = user_inputs['age'][i]
job = user_inputs['job'][i]
mid = movie_inputs['mid'][i] # mid
mtype = movie_inputs['mtype'][i]
mtext = movie_inputs['mtext'][i]
if uid.item() not in users.keys():
users[uid.item()]={'uid':uid,'gender':gender,'age':age,'job':job}
if mid.item() not in movies.keys():
movies[mid.item()]={'mid':mid,'mtype':mtype, 'mtext':mtext}
if uid not in user_feature_dict.keys():
user_feature_dict[uid]=feature_user[i]
if mid not in movie_feature_dict.keys():
movie_feature_dict[mid]=feature_movie[i]
print('Solved: {} samples'.format((i_batch+1)*batch_size))
feature_data = {'feature_user': user_feature_dict, 'feature_movie':movie_feature_dict}
dict_user_movie={'user': users, 'movie':movies}
pkl.dump(feature_data,open('Params/feature_data.pkl','wb'))
pkl.dump(dict_user_movie, open('Params/user_movie_dict.pkl','wb'))(model):
'''
Save Movie and User feature into HD
'''
batch_size = 256
datasets = MovieRankDataset(pkl_file='data.p')
dataloader = DataLoader(datasets, batch_size=batch_size, shuffle=False,num_workers=4)
# format: {id(int) : feature(numpy array)}
user_feature_dict = {}
movie_feature_dict = {}
movies={}
users = {}
with torch.no_grad():
for i_batch, sample_batch in enumerate(dataloader):
user_inputs = sample_batch['user_inputs']
movie_inputs = sample_batch['movie_inputs']
# B x 1 x 200 = 256 x 1 x 200
_, feature_user, feature_movie = model(user_inputs, movie_inputs)
# B x 1 x 200 = 256 x 1 x 200
feature_user = feature_user.cpu().numpy()
feature_movie = feature_movie.cpu().numpy()
for i in range(user_inputs['uid'].shape[0]):
uid = user_inputs['uid'][i] # uid
gender = user_inputs['gender'][i]
age = user_inputs['age'][i]
job = user_inputs['job'][i]
mid = movie_inputs['mid'][i] # mid
mtype = movie_inputs['mtype'][i]
mtext = movie_inputs['mtext'][i]
if uid.item() not in users.keys():
users[uid.item()]={'uid':uid,'gender':gender,'age':age,'job':job}
if mid.item() not in movies.keys():
movies[mid.item()]={'mid':mid,'mtype':mtype, 'mtext':mtext}
if uid not in user_feature_dict.keys():
user_feature_dict[uid]=feature_user[i]
if mid not in movie_feature_dict.keys():
movie_feature_dict[mid]=feature_movie[i]
print('Solved: {} samples'.format((i_batch+1)*batch_size))
feature_data = {'feature_user': user_feature_dict, 'feature_movie':movie_feature_dict}
dict_user_movie={'user': users, 'movie':movies}
pkl.dump(feature_data,open('Params/feature_data.pkl','wb'))
pkl.dump(dict_user_movie, open('Params/user_movie_dict.pkl','wb'))
recInterface.py还有其他的功能函数:
-
getKNNitem(itemID,itemName='movie',K=1): 根据项目的id得到K近邻项目,如果itemName='user',那么就是获取K近邻的用户。逻辑很简单:
- 根据
itemName提取保存在本地的相应的用户/电影特征集合 - 根据
itemID获取目标用户的特征 - 求其特征与其他所有用户/电影的cosine相似度
- 排序后返回前k个用户/电影即可
- 根据
-
getUserMostLike(uid): 获取用户id为uid的用户最喜欢的电影过程也很容易理解:
- 依次对
uid对应的用户特征和所有电影特征做一个点积操作 - 该点击操作视为用户对电影的评分,对这些评分做一个sort操作
- 返回评分最高的即可。
- 依次对
6. 声明
大家有问题可以直接在Github仓库的issue里提问。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号