
使用动态时间规整 (DTW) 解决时间序列相似性度量及河流上下游污染浓度相似性识别分析
时间序列相似性度量方法
时间序列相似性度量常用方法为欧氏距离ED(Euclidean distance)和动态时间规整DTW(Dynamic Time Warping)。总体被分为两类: 锁步度量(lock-step measures) 和弹性度量(elastic measures) 。锁步度量是时间序列进行 “一对一”的比 较; 弹性度量允许时间序列进行 “一对多”的比较。
欧氏距离属于锁步度量。

在时间序列中,我们通常需要比较两端音频的差异。而两段音频的长度大部分是不相等的。在语音处理领域上表现为不同人的语速不同。即时同一个人不同一时刻发同一个音,也不可能具有完全相同的时间长度。而且每个人对同一个单词的不同音素的发音速度也是不同的,有的人会把"A"这个音拖得稍长,或者"i"稍短。在这种复杂的情况下,利用传统的欧几里得距离是无法求得有效的两个时间序列之间的相似性的(即距离)。
如下图,实线波形的a点会对应于虚线波形的b’点,这样传统的通过比较距离来计算相似性很明显不靠谱。因为很明显,实线的a点对应虚线的b点才是正确的。
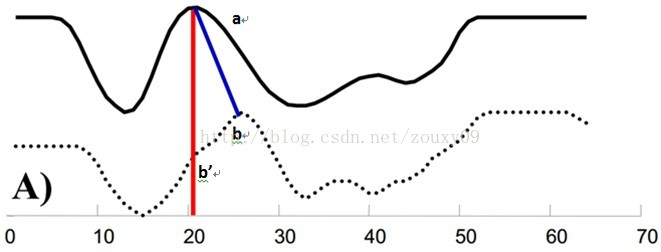
考虑序列长短不一,或时间步不对齐的时候,特别是在峰值的时候,欧氏距离是无法有效计算两个时间序列的距离。DTW算法将其中一个序列进行线性放缩、进行某种“扭曲”操作,。可以存在一对多mapping的情况,在时间序列探索过程中效果更好。适用于复杂时间序列,属于弹性度量
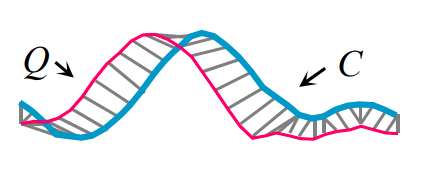
dtw算法介绍
假设我们有两个时间序列Q和C,他们的长度分别是n和m:(实际时间序列匹配运用中,一个序列为参考模板,一个序列为测试模板)
Q = q1, q2,…,qi,…, qn ;
C = c1, c2,…, cj,…, cm ;
为了对齐这两个序列,我们需要构造一个n x m的矩阵网格,矩阵元素(i, j)表示qi和cj两个点的距离d(qi, cj)(也就是序列Q的每一个点和C的每一个点之间的相似度,距离越小则相似度越高。这里先不管顺序),一般采用欧式距离,d(qi, cj)= (qi-cj)2(也可以理解为失真度)。每一个矩阵元素(i, j)表示点qi和cj的对齐。DP算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为两个序列进行计算的对齐的点。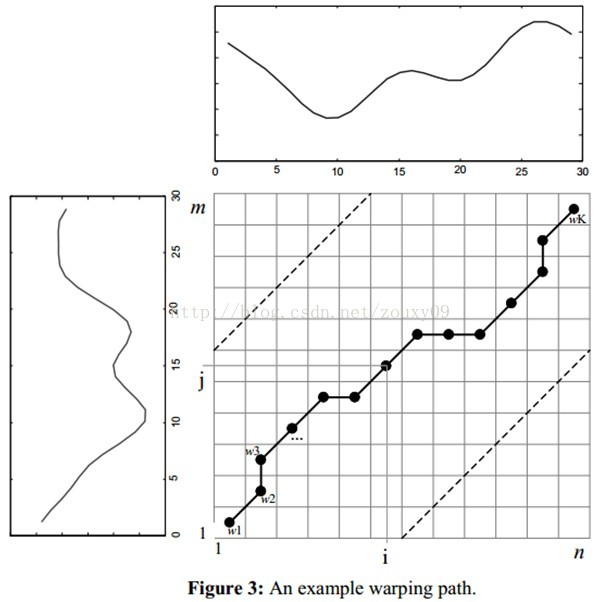
那么这条路径我们怎么找到呢?那条路径才是最好的呢?也就是刚才那个问题,怎么样的warping才是最好的。
首先,这条路径不是随意选择的,需要满足以下几个约束:
1)边界条件:w1=(1, 1)和wK=(m, n)。任何一种语音的发音快慢都有可能变化,但是其各部分的先后次序不可能改变,因此所选的路径必定是从左下角出发,在右上角结束。
2)连续性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足 (a-a’) <=1和 (b-b’) <=1。也就是不可能跨过某个点去匹配,只能和自己相邻的点对齐。这样可以保证Q和C中的每个坐标都在W中出现。
3)单调性:如果wk-1= (a’, b’),那么对于路径的下一个点wk=(a, b)需要满足0<=(a-a’)和0<= (b-b’)。这限制W上面的点必须是随着时间单调进行的。以保证图B中的虚线不会相交。
结合连续性和单调性约束,每一个格点的路径就只有三个方向了。例如如果路径已经通过了格点(i, j),那么下一个通过的格点只可能是下列三种情况之一:(i+1, j),(i, j+1)或者(i+1, j+1)。
满足上面这些约束条件的路径可以有指数个,最佳路径是使得沿路径的积累距离达到最小值这条路径。这条路径可以通过动态规划(dynamic programming)算法得到。具体搜索或者求解过程的直观例子解释可以参考:http://www.cnblogs.com/tornadomeet/archive/2012/03/23/2413363.html
普通dtw方法引入和使用
第一步:dtw包安装,以Anaconda为例
从开始菜单打开 Anaconda prompt 管理工具
输入dwt安装脚本
pip install dtw
第二步:dtw包导入
from dtw import dtw
第三步:dtw函数使用
首先,需要定义距离函数,其中,x为参照序列数据,y为测试序列数据
distance=lambda x,y :np.abs(x-y)
接下来,调用dtw方法
d,cost_matrix,acc_cost_matrix,path=dtw(x,y,distance)
dtw函数输入参数说明
x:参照序列数据
y:测试序列数据
distance:距离函数
dtw函数输出参数说明
d:累计距离
cost_matrix:两个序列之间的两两距离
acc_cost_matrix:dp矩阵
path:最佳路径,包含两个数组,path[0] 参照序列下标值,path[1] 测试序列下标值
轨迹线打印出图
plt.imshow(cost_matrix.T,origin='lower',cmap='gray')
plt.plot(path[0],path[1])
plt.show()
dtw-python包的安装与引用
dtw库的使用限制太多,不够灵活,且作图不够方便,主要体现运算量大、首尾必须匹配、序列间对应个数无法限定等。dtw-python包是R语言中dtw实现的python版本,基本的API是对应的,它的优势在于能够自定义点的匹配模式,约束条件,和滑动窗口。同时提供方便的作图和快速的计算(C语言的内核),官方文档点击这里。
dtw-python 包安装脚本
pip install dtw-python
dtw-python 包引用
from dtw import dtw,dtwPlot,stepPattern,warp,warpArea,window #不建议直接 from dtw import * 方式,避免冲突
由于在dtw包选用过程中,先安装了dtw包,后安装了dtw-python包,在dtw-python引用过程中,出现dtw包引用失败情况,建议两者保留其一。可使用包卸载脚本对dtw包进行卸载,并在Anaconda安装目录下 \Anaconda3\Lib 目录下清除掉 以 ~ 开头命名的文件夹
pip uninstall dtw
dtw函数的参数说明
ds=dtw(x, y=None, dist_method='euclidean', step_pattern='symmetric2', window_type=None, window_args={}, keep_internals=False, distance_only=False, open_end=False, open_begin=False)
输入参数说明:
dist_method 定义你用的距离方法,默认为’euclidean’,即欧几里得距离。
keep_internals=True保存内部的信息包含距离矩阵之类的,一般我们把它设为True。
step_pattern定义了点之间的匹配模式,有好几种,具体查看官网(StepPattern — The dtw-python package 1.3.0 documentation (dynamictimewarping.github.io))。
window_type表示全局条件约束,也有几种模式,同查看官网(dtw — The dtw-python package 1.3.0 documentation (dynamictimewarping.github.io))。"none", "itakura", "sakoechiba", "slantedband",其中sakoechiba方式需要在window_args 参数中传递window_size参数,方式如下:window_args= {"window_size": 1}
distance_only如果设置为True,会加速计算,只计算距离,忽略匹配函数。
open_end和open_begin设为True表示无拘束的匹配,即完全的部分匹配,默认是全局匹配,就是严格对应头和尾。
输出参数说明:
ds.distance:累计距离
ds.index1:参照序列下标值
ds.index2:测试序列下标值
dtw输出结果打印
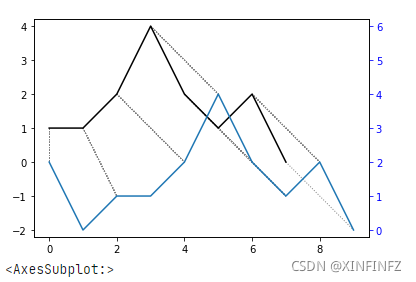
ds.plot(type="twoway",offset=-2)
一般有twoway和threeway两种模式,下面详解,offset=-2可以理解为两根线之间的分离程度,为了方便看清可以设的大一些。下图左侧为twoway方式的输出结果,右侧为threeway方式的输出结果。
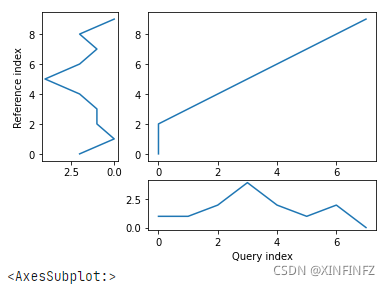
dtw函数使用注意事项
1.数据中不能出现空置和无效值,使用上一记录替代缺失数据时,同一时段内缺失数据不能过多,否则会造成变化趋势匹配结果偏差较大
2.最大值和最小值可能不会做到正确匹配
dtw使用实例:上下游河流断面污染物浓度变化趋势相似度识别
背景:同一条河流上两个断面的污染物浓度在变化趋势上呈现一定的相似性。但由于河流流速的不定,上游断面浓度的波峰波谷在下游断面上出现的时间间隔不同,可以通过dtw方法实现两断面间相似变化趋势的时间段,以及上下游断面间污染物浓度变化的相互关系
第一步:添加python包引用
import numpy as np import pandas as pd import matplotlib.pylab as plt import math import datetime import time #用于时间秒转换成时间 from dtw import dtw,dtwPlot,stepPattern,warp,warpArea,window #不建议直接 from dtw import * 方式,避免冲突 import sys import pymssql import xlwt from pandas._libs.tslibs.timestamps import Timestamp
第二步:通过csv方式读取两个断面污染物的浓度监测数值
beginTime='2019/1/2 12:00' endTime='2019/2/18 12:00' #从csv文件中取出数据 df=pd.read_csv('wq3.csv',encoding='utf-8', index_col='datatime') #从csv文件中读取时间序列数据,index_col列定义为索引对象 df.index=pd.to_datetime(df.index) df_xy_org=df['xyvalue'][beginTime:endTime] #指定时间序列中下游的监测数据列 df_sy_org=df['syvalue'] #指定时间序列中上游的监测数据列 #具体计算中需要排除掉缺数的情况,特别是长时间的缺数,会影响到最终的匹配结果。通过使用上一次监测数据方法不合适 for i in range(0,len(df_xy_org)): if not df_xy_org[i] or math.isnan(df_xy_org[i]): #判断数值是否为空 df_xy_org[i] = df_xy_org[i-1] for i in range(0,len(df_sy_org)): if not df_sy_org[i] or math.isnan(df_sy_org[i]): #判断数值是否为空 df_sy_org[i] = df_sy_org[i-1]
第三步:为了更有效的找到波峰和波谷,对污染物浓度做一阶差分处理
#比对数据做一阶差分处理 df_xytime=np.empty(len(df_xy_org)-1,dtype=datetime.datetime) df_xyvalue=np.empty(len(df_xy_org)-1) for i in range(1,len(df_xy_org)-1): df_xytime[i-1]=df_xy_org.index[i].to_pydatetime() df_xyvalue[i-1]=(float(df_xy_org.values[i])-float(df_xy_org.values[i-1])) df_xy=pd.Series(df_xyvalue,index=df_xytime) df_sytime=np.empty(len(df_sy_org)-1,dtype=datetime.datetime) df_syvalue=np.empty(len(df_sy_org)-1) for i in range(1,len(df_sy_org)-1): df_sytime[i-1]=df_sy_org.index[i].to_pydatetime() df_syvalue[i-1]=(float(df_sy_org.values[i])-float(df_sy_org.values[i-1])) df_sy=pd.Series(df_syvalue,index=df_sytime)
第四步:定义距离函数
#定义距离计算方法 dist=lambda x,y:np.abs(np.power(100,x)-np.power(100,y))
第五步:下游断面监测数据作为参照序列,对上游断面监测数据中选取【参照序列长度正负2的长度】的序列,循环验证最相似的时间序列
#dwt计算,比对dist生成的结果中,累计距离最小的项作为最终的输出结果 lunci=20 bestBegin=datetime.datetime.strptime(beginTime, '%Y/%m/%d %H:%M') bestEnd=datetime.datetime.strptime(endTime, '%Y/%m/%d %H:%M') bestCost=sys.float_info.max bestds='undefined' #生成待比对断面的监测数据,长度上边可以比下游断面的监测数据长度多或者少两条记录(-2,-1,0,1,2),要求首尾必须匹配方式 diff=np.array([-2,-1,0,1,2],dtype=np.int) for lendiff in diff: bestLunci=-1 for ii in range(lunci): delta_begin=datetime.timedelta(hours=(-4)*(lunci-ii)) delte_end=datetime.timedelta(hours=(-4)*(lunci-ii-int(lendiff))) try: tempbegin=datetime.datetime.strptime(beginTime, '%Y/%m/%d %H:%M')+delta_begin tempend=datetime.datetime.strptime(endTime, '%Y/%m/%d %H:%M')+delte_end tempdf_sy=df_sy[tempbegin:tempend] ds=dtw(df_xy,tempdf_sy,dist_method=dist,keep_internals=True,step_pattern='asymmetric',window_type='sakoechiba',open_begin=False,open_end=False,window_args= {"window_size": 1}) #参数传递方法 print('运行轮次:'+str(ii)+'时 ds.distance='+str(ds.distance)) if bestCost>ds.distance: bestCost=ds.distance bestds=ds bestBegin=tempbegin bestEnd=tempend bestLunci=ii bestds.plot(type="twoway") print(bestdsT.distance) print('运行轮次:'+str(ii)+'成功!') except Exception as e: print('运行轮次:'+str(ii)+'出错!') print(e)
第六步:找到原始断面污染物浓度值,并找出上下游不同时刻点的对应关系情况,输出csv文件
#记录上下游污染物浓度数据到一个数组中 records=pd.DataFrame(columns=['syvalue','xyvalue']) #把dtw运行结果存入csv文件中 #创建文件 file = xlwt.Workbook() #写入sheet名称,2017-05-01T06_00_00 格式 name_sheet='上下游水质关系' table = file.add_sheet(name_sheet) title=['df_xytime','df_sytime','df_xyvalue','df_syvalue','timediff'] bestdf_sy=df_sy[bestBegin:bestEnd] #table.write(行_0开始, 列_0开始, 值) #写入表头,第一行 for j in range(len(title)): table.write(0, j, title[j]) #index_i+1 行,index_j列 for index_i,r in enumerate(bestds.index1): try: df_xytime=datetime.datetime.strptime(beginTime, '%Y/%m/%d %H:%M')+datetime.timedelta(hours=4*1) +datetime.timedelta(hours=4*index_i) #beginTime先加一个小时的原因是,前期执行了一个一阶差分,时间上往后延迟了一个周期,而bestBeginTime不存在这种问题 df_sytime=bestBegin+datetime.timedelta(hours=4*int(bestds.index2[index_i])) df_xyvalue=df_xy_org[df_xytime] df_syvalue=df_sy_org[df_sytime] timediff=(df_xytime-df_sytime).days*24+(df_xytime-df_sytime).seconds/3600 record=pd.DataFrame([[df_syvalue,df_xyvalue]],columns=['syvalue','xyvalue'])#注意插入的数据包含有两级中括号 records=records.append(record,ignore_index=True) table.write(index_i+1,0,df_xytime.strftime('%Y-%m-%d %H:%M:%S')) table.write(index_i+1,1,df_sytime.strftime('%Y-%m-%d %H:%M:%S')) table.write(index_i+1,2,df_xyvalue) table.write(index_i+1,3,df_syvalue) table.write(index_i+1,4,timediff) except: continue try: #保存文件 name_file=name_sheet+'.csv' file.save(name_file) except Exception as e: print (e) #找到原始数据,绘制关系对应图 print('records')
测试数据: https://files.cnblogs.com/files/HoEn/dtw%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.zip?t=1676453291
参考资料:
语音信号处理之(一)动态时间规整(DTW)_zouxy09的专栏-CSDN博客_动态时间规整
时间序列匹配之dtw的python实现(二)_轻舟已过万重山的博客-CSDN博客_dtw python 用法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号