python 13 包、常用模块
day13 包、常用模块
1.区分py文件的两种用途
m1.py
def f1():
print('from f1')
print(__name__)
if __name__ == '__main__':
f1()
>>>>
__main__*
from f1
import m1
>>>>
m1
2.软件开发的目录规范
自定义导入
# 方案一
import sys
# sys.path.append(r'xxx\xx\x\conf')
# sys.path.append(r'xxx\xx\x\core')
# sys.path.append(r'xxx\xx\x\db')
# 方案二
# sys.path.append(r'xxx\xx\x')
# 方案三
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(__file__))
sys.path.append(BASE_DIR)
print(__file__) # 返回当前文件的绝对路径
# 方案四
# 将run.py放到上级目录下
3.常用模块模块
time模块!!
# # 时间分为三种格式
# # 1.时间戳
# print(time.time())
# # 2.格式化的字符串
# print(time.strftime("%Y-%m-&d %H:%M:%S"))
#
# # 3.结构化的时间对象
# obj = time.localtime()
# print(obj.tm_year)
# print(obj.tm_wday)
# print(time.gmtime())
import arrow
print(arrow.get(333333333333).format('YYYY-MM-DD HH:mm:ss')) # get方法可自动识别字符串、时间戳
date = arrow.get('2017-11-11 11:11:11')
data_str = date.format('YYYY-MM-DD HH:mm:ss')
print(date.timestamp())
print(date.float_timestamp)
print(date.shift(days=-10).format('YYYYMMDD')) # 获取date前10天的日期
print(arrow.now())
print(date.day)
print(date.month)
print(date.year)
print(date.week)
random模块!!
import random
print(random.random())#(0,1)----float 大于0且小于1之间的小数
print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数
print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数
print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5]
print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合
print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716
item=[1,3,5,7,9]
random.shuffle(item) #打乱item的顺序,相当于"洗牌"
print(item)
# print(chr(65))
# print(chr(90))
# print(ord('A'))
# print(ord('Z'))
# 随机生成验证码
import random
def make_code(size=4):
res = ''
for i in range(size):
num = str(random.randint(0, 9))
alpha = chr(random.randint(65, 90))
res += random.choice([num, alpha])
return res
configparser模块
import configparser
config = configparser.ConfigParser()
config.read('my.ini')
# res = config.sections()
# res = config.items('section1')
# res = config.options('section1')
# res = config.get('section1', 'salary')
# res = config.getfloat('section1', 'salary')
# res = config.getint('section1', 'salary')
# res = config.getboolean('section1', 'is_admin')
# print(res)
import configparser
config=configparser.ConfigParser()
config.read('a.cfg')
#查看所有的标题
res=config.sections() #['section1', 'section2']
print(res)
#查看标题section1下所有key=value的key值
options=config.options('section1')
print(options) #['k1', 'k2', 'user', 'age', 'is_admin', 'salary']
#查看标题section1下所有key=value的(key,value)格式
item_list=config.items('section1')
print(item_list) #[('k1', 'v1'), ('k2', 'v2'), ('user', 'egon'), ('age', '18'), ('is_admin', 'true'), ('salary', '31')]
#查看标题section1下user的值=>字符串格式
val=config.get('section1','user')
print(val) #egon
#查看标题section1下age的值=>整数格式
val1=config.getint('section1','age')
print(val1) #18
#查看标题section1下is_admin的值=>布尔值格式
val2=config.getboolean('section1','is_admin')
print(val2) #True
#查看标题section1下salary的值=>浮点型格式
val3=config.getfloat('section1','salary')
print(val3) #31.0
re!!
import re
# \w 匹配字母数字下划线
# \W 匹配与\w相反
# \s 匹配空白字符
# \S 匹配与\s相反的
# \d 匹配数字
# \D 匹配与\d相反
# ^适用于多行模式只从每行的头部开始匹配不把\n当字符
# $适用于多行模式只从每行的尾部开始匹配不把\n当字符
# \A不适用多行模式将字符串当做一行匹配开头且把\n当字符
# \Z不适用多行模式将字符串当做一行匹配结尾且把\n当字符
# \n 换行符
# \t 制表符
# .代表匹配一个非换行符之外的任意字符
# 第三个参数匹配模式
# re.MULTILINE 多行末世中分成多行匹配
# re.DOTALL
res = re.findall('\S', 'hel_l+o- w*o(rld 123')
res = re.findall('\Aa',"""abc
a123
a456
666
""", re.MULTILINE)
>>>>
['a']
# []匹配一个字符,该字符可以是指定的字符
# [^]表示匹配非括号内的符号
res = re.findall('a[0-9a-zA-z]c', 'aAc a1c abc a c a.c a\nc a\tc aaaac',re.S)
res = re.findall(r'a[^+*\\-]c', 'a+c a-c a*c a\c aAc a1c abc a c a.c a\nc a\tc aaaac', re.S)
# *左边那个字符出现0次到无穷次
# ?左边那个字符出现0次到1次
# +左边那个字符出现1次到无穷次
# (n,m)左边那个字符出现n次到m次
res = re.findall('ab*','a ab abbb abbbbb bbbba')
print(res)
>>>>
['a', 'ab', 'abbb', 'abbbbb', 'a']
res = re.findall('ab?', 'a ab abbb abbbbb bbbba')
print(res)
>>>>
['a', 'ab', 'ab', 'ab', 'a']
res = re.findall('ab{3,5}', 'a ab abbb abbbbb bbbba')
print(res)
>>>>
['abbb', 'abbbbb']
# ?: 表示取消分组
res = re.findall("compan(?:ies|y)","Too many companies have gone bankrupt, and the next one is your company")
print(res)
>>>>
['companies', 'company']
# .* 贪婪模式能匹配的都匹配
res = re.findall('a.*c', 'a1231231+-c66666666c')
>>>>
['a1231231+-c66666666c']
# .*?非贪婪模式只匹配最近的
res = re.findall('a.*?c', 'a1231231+-c66666666c')
>>>>
['a1231231+-c']
logging!
一、日志级别
CRITICAL = 50 #FATAL = CRITICAL
ERROR = 40
WARNING = 30 #WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0 #不设置
settings.py
# -*- coding: utf-8 -*-
# User = Hina
# Motto = "粪虫至秽变为蝉而饮露于秋风,腐草无光化为萤而耀采于夏月!"
# Date = 2021/4/2
"""
logging配置
"""
import os
# 1、定义三种日志输出格式,日志中可能用到的格式化串如下
# %(name)s Logger的名字
# %(levelno)s 数字形式的日志级别
# %(levelname)s 文本形式的日志级别
# %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
# %(filename)s 调用日志输出函数的模块的文件名
# %(module)s 调用日志输出函数的模块名
# %(funcName)s 调用日志输出函数的函数名
# %(lineno)d 调用日志输出函数的语句所在的代码行
# %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
# %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
# %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
# %(thread)d 线程ID。可能没有
# %(threadName)s 线程名。可能没有
# %(process)d 进程ID。可能没有
# %(message)s用户输出的消息
# 2、强调:其中的%(name)s为getlogger时指定的名字
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]'
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
test_format = '%(asctime)s] %(message)s'
fm2 = "%(asctime)s : %(message)s"
fm1 = "%(asctime)s - %(filename)s:%(lineno)d %(levelname)s][%(message)s"
log2_path = 'a2.log'
log1_path = 'a1.log'
# 3、日志配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'formatter1': {
'format': fm1
},
'formatter2': {
'format': fm2
},
},
'filters': {},
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'formatter2'
},
# 打印到文件的日志,收集info及以上的日志
'file1': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,日志轮转
'formatter': 'formatter1',
# 可以定制日志文件路径
# BASE_DIR = os.path.dirname(os.path.abspath(__file__)) # log文件的目录
# LOG_PATH = os.path.join(BASE_DIR,'a1.log')
'filename': log1_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
'file2': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'formatter1',
'filename': log2_path, # 确定好路径
'encoding': 'utf-8',
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['file1', 'file2', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'用户相关': {
'handlers': ['file1', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'交易相关': {
'handlers': ['file2', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
},
}
common.py
# -*- coding: utf-8 -*-
# User = Hina
# Motto = "粪虫至秽变为蝉而饮露于秋风,腐草无光化为萤而耀采于夏月!"
# Date = 2021/4/2
import logging.config
import settings
def get_logger(name):
logging.config.dictConfig(settings.LOGGING_DIC)
logger = logging.getLogger(name)
# logger = logging.getLogger('交易相关')
return logger
logger = get_logger('交易相关')
# logger.debug('这是一条debug日志')
logger.info('xxx比yyy帅')
# logger.warning('这是一条warning日志')
# logger.error('这是一条error日志')
# logger.critical('这是一条critical日志')
json与pickle!!
# 1.序列化
# dic = {
# 'a': 123,
# 'b': 234,
# 'c': 456,
# }
#
# dic_s = str(dic)
#
# with open('xlh.txt','w',encoding='utf-8') as f:
# f.write(dic_s)
# 2.反序列化
# eval(string) 将string中的字符串当做代码执行
# with open('xlh.txt','r',encoding='utf-8') as f:
# dic = eval(f.read())
# print(dic)
# 序列化的两大用途
# 1.存档
# 2.跨平台交互数据(需要使用一种通用的数据格式)
import json
# ====================json 格式的序列化与反序列化1
# dic = {'name':"egon","age":18.5,"k1":True,'k2':None,'k3':(1,2,3)}
# json_str = json.dumps(dic)
# print(json_str,type(json_str))
# with open('a.json',mode='wt',encoding='utf-8') as f:
# f.write(json_str)
# with open('a.json',mode='rt',encoding='utf-8') as f:
# json_str = f.read()
# res = json.loads(json_str)
# print(res,type(res))
# ====================json 格式的序列化与反序列化2
# dic = {'name':"egon","age":18.5,"k1":True,'k2':None,'k3':(1,2,3)}
# with open('a.json',mode='wt',encoding='utf-8') as f:
# json.dump(dic,f)
# with open('a.json',mode='rt',encoding='utf-8') as f:
# res = json.load(f)
# print(res,type(res))
序列化的两大用途
- 存档(pickle)
- 跨平台交互数据(需要是用一种通用的数据格式——>json)
subprocess!!
import subprocess
import time
obj = subprocess.Popen('tasklist', shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
# time.sleep(3)
# print(obj)
res1 = obj.stdout.read()
res2 = obj.stderr.read()
print(res1.decode('gbk'))
print(res2)
hashlib!!!
哈希算法
交给hash算法一串内容,hash算法会计算出一个值,该值称为哈希值,哈希值有三大特点
- 只要采用了hash算法一样,并且传入的内容一样,那么hash值一定一样。
- hash值得长度取决于算法,与传入内容的多少无关。
- hash值不可逆推。
两大用途:
- 文件内容完整性校验 = 1 + 2
- 加密 = 3
import hashlib
m = hashlib.md5()
m.update("哈哈".encode())
m.update("hello".encode())
m.update("我擦嘞".encode())
print(m.hexdigest())
>>>>
63212ccaf7e70e66090b2e79f350ff99
m.update("哈".encode())
m.update("哈".encode())
m.update("he".encode())
m.update("llo".encode())
m.update("我".encode())
m.update("擦嘞".encode())
print(m.hexdigest())
>>>>
63212ccaf7e70e66090b2e79f350ff99
os!!
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.system('tasklist') # 执行命令
os.environ 获取系统环境变量
print(os.environ)
os.environ['current_user'] = 'hina'
print(os.environ.get('current_user'))
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
# 获取当前目录文件的上上级目录
# print(os.path.normpath(r"D:\a\b\..\.."))
print(__file__)
print(os.path.dirname(os.path.dirname(__file__)))
# print(os.path.join(__file__, '..', '..'))
print(os.path.normpath(os.path.join(__file__, '..', '..')))
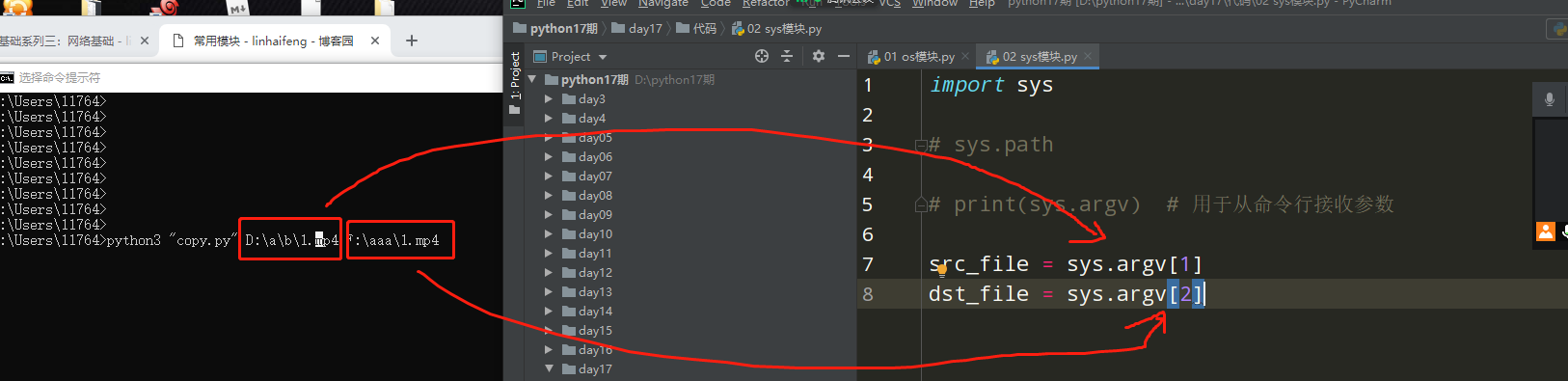
sys!
shutil!
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
1 import shutil
2
3 shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
1 shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.rmtree(path[, ignore_errors[, onerror]])
递归的去删除文件
1 import shutil
2
3 shutil.rmtree('folder1')
shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/ - format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
1 #将 /data 下的文件打包放置当前程序目录
2 import shutil
3 ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data')
4
5
6 #将 /data下的文件打包放置 /tmp/目录
7 import shutil
8 ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
解压缩
import zipfile
# 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close()
# 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
zipfile压缩解压缩
import tarfile
# 压缩
>>> t=tarfile.open('/tmp/egon.tar','w')
>>> t.add('/test1/a.py',arcname='a.bak')
>>> t.add('/test1/b.py',arcname='b.bak')
>>> t.close()
# 解压
>>> t=tarfile.open('/tmp/egon.tar','r')
>>> t.extractall('/egon')
>>> t.close()
tarfile压缩解压缩
shelve
import shelve
f = shelve.open(r'a.sh1')
f['xxx'] = {'k1': (1, 2, 3), 'k2': {4, 5, 6}}
f['yyy'] = [111, 222, 333]
print(f['xxx']['k2'])
print(f['yyy'])
xml
类似于html的标签化。不如json简洁。
包(***)
什么是包
包的本质就是一个包含有_init__的文件夹,也是模块的一种
既然包也是模块,那么包就是用来被导入使用
# 首次导入模块发送三件事
# 1.产生一个模块的名称空间
# 2.执行模块的文件,将运行过程中产生的名字都丢到模块的名称空间中国
# 3.在当前位置拿到一个名字mmm,该名字指向模块的名称空间
# 首次导入包发送三件事
# 1.产生一个包的名称空间
# 2.执行包下__init__的文件,将运行过程中产生的名字都丢到模块的名称空间中国
# 3.在当前位置拿到一个名字mmm,该名字指向__init__的名称空间
import mmm
# 推荐使用相对导入
from .m1 import f1
from .m2 import f2
from .m3 import f3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号