python day 12 递归、匿名函数、模块
day 12 递归、匿名函数、模块
复习
-
装饰器模板
from functools import wraps # 无参装饰器 def outter(func): @wraps(func) def wrapper(*args, **kwargs): res = func(*args, **kwargs) return res return wrapper # 有参装饰器 def outter2(x, y, z): def outter(func): @wraps(func) def wrapper(*args, **kwargs): print(x, y, z) res = func(*args, **kwargs) return res return wrapper return outter -
迭代器
-
自定义迭代器
生成器:yeild
生成器表达式:(i for i in range(5))
-
列表生成式:[表达式 for x in 可迭代对象 if 条件]
1.函数递归
函数的递归调用:是函数嵌套调用的一种特殊形式,具体指的是在调用一个函数的过程中,又直接或者间接地调用自己,称之为函数的递归调用
函数的递归调用就是一个循环的过程
def f1():
print('from f1')
f1()
f1()
def f1():
print('f1')
f2()
def f2():
print('f2')
f1()
一个递归过程应该分为两个阶段
- 回溯:向下一层一层调用
- 递推:向上一层一层返回
# age(5) = age(4) + 10
# age(4) = age(3) +10
# age(3) = age(3) +10
# age(2) = age(3) +10
#
# age(1) = 18
#
#
# n > 1 —> age(n) = age(n-1) +10
# n = 1 —> 18
def age(n):
if n == 1:
return 18
else:
return age(n-1) + 10
python 没有尾递归优化
# nums = [1, [2, [3, [4, [5, [6, [7, [8, ]]]]]]]]
# def func(ls):
# if len(ls) == 1:
# print(ls[0])
# else:
# print(ls[0])
# func(ls[1])
#
#
# func(nums)
# nums = [1, [2, [3, [4, [5, [6, [7, [8, [9, 10, 11]]]]]]]]]
# def func(ls):
# for i in ls:
# if type(i) is list:
# func(i)
# else:
# print(i)
# func(nums)
nums = [-3, 1, 5, 7, 9, 11, 13, 18, 22, 38, 78, 98]
def binary_search(ls, left, right, val):
if left <= right:
mid = (left + right) // 2
if ls[mid] == val:
return mid
else:
if ls[mid] > val:
right = mid - 1
else:
left = mid + 1
binary_search(ls, left, right, val)
else:
print('不存在')
return
# print(binary_search(nums, 0, len(nums) - 1, 12))
def search(val, ls):
print(ls)
if len(ls) == 0:
print('不存在')
return
mid = len(ls) // 2
if val == ls[mid]:
print(mid)
return mid
elif ls[mid] > val:
new_ls = ls[:mid]
return search(val, new_ls)
else:
new_ls = ls[mid+1:]
return search(val,new_ls)
print(search(22, nums))
2.匿名函数
lambda x,y:x+y
salary = {
'hina': 1000,
'rui': 3000,
'nazi': 100,
}
def func(k):
return salary[k]
print(max(salary,key=lambda k:salary[k]))
print(min(salary,key=lambda k:salary[k]))
print(sorted(salary,key=lambda k:salary[k]))
了解:
filter:返回可迭代对象
names = ['hina_nb','rui_sb','naci_sb']
print((name for name in names if name.endswith('sb')))
print(list(filter(lambda name: name.endswith('sb'), names)))
crazystring = 'dade142.;!0142f[.,]ad'
# 只保留数字
filter(str.isdigit, crazystring)
a = list(filter(str.isdigit, crazystring))
print(a)
# 只保留字母
filter(str.isalpha, crazystring)
# 只保留字母和数字
filter(str.isalnum, crazystring)
# 如果想保留数字0-9和小数点’.’ 则需要自定义函数
filter(lambda ch: ch in '0123456789.', crazystring)
map
names = ['hina', 'rui', 'naci']
print([name + 'sb' for name in names])
print(list(map(lambda name: name + 'sb', names)))
reduce
from functools import reduce
print(reduce(lambda x, y: x + y, [1, 2, 3, 4, 5], 100))
print(reduce(lambda x, y: x + y, ["a", "b", "c"]))
3.模块的使用
-
什么是模块
模块就是一系列功能的集合体
模块分为四种类别:
- 一个py文件就可以是一个模块
- 包:就是一个存放有__init__.py文件的文件夹
- 使用C编写并链接到python解释器的内置模块
- 已被编译为共享或DLL的C或C++的扩展
模块有三种来源:
-
python解释器自带的
内置的:time
标准库:os
-
第三方库
-
自定义的库
-
为何要用模块
- 拿来主义,极大地提示开发效率
- 解决代码冗余问题
-
如何用模块
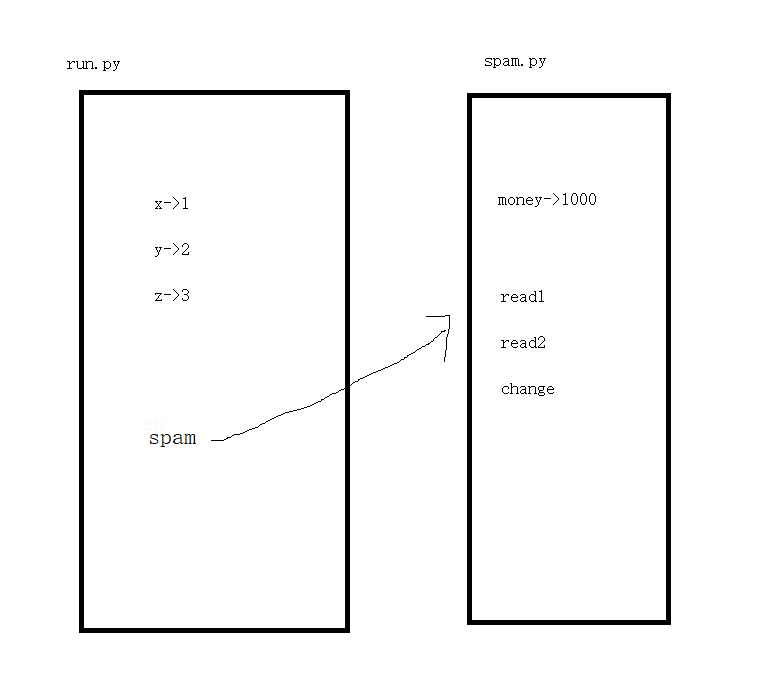
import:
(首次)导入模块会发生三件事 # 后续的导入直接引用首次导入的成果,不会重复导入
- 会触发spam.py运行,所有会产生一个模块的名称空间
- 运行spam.py的代码,将运行过程中产生的名字都丢到模块的名称空间中
- 在当前执行文件的名称空间中拿到一个名字spam,该名字就是指向模块的名称空间的
from...import...
- 在当前执行文件的名称空间中拿到一个名字money,该名字就是指向模块的名称空间的对应的名字
from...import *
*====...中的____all____ = ['a','b....]
-
循环导入问题
# m1.py 中 def f1(): from m2 import y # m2.py 中 def f2(): from m1 import x -
模块的搜索路径
-
内存
-
内置
-
sys.path:强调sys.path是以执行程序为准的
import sys sys.path.append(r'D:\\pythondir')
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号