python day05 copy、集合
day05 copy、集合
1、深浅拷贝!!!
默认情况下都是浅拷贝(只拷贝一层)
在不可变类型的改变中不能互相影响,在可变类型的修改中会互相影响。
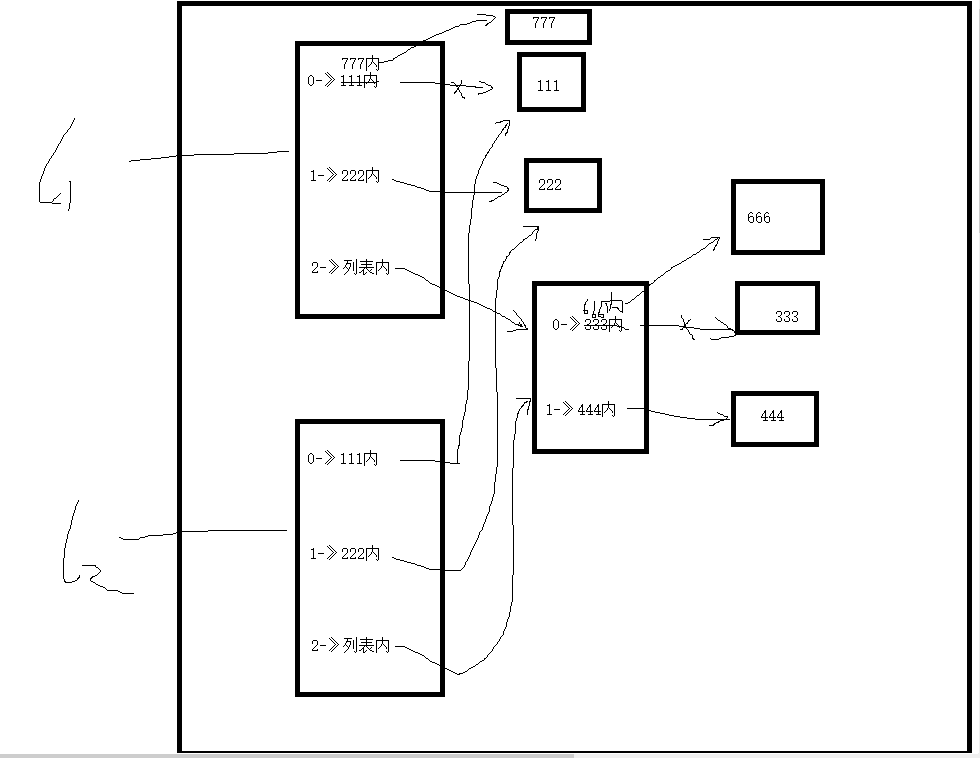
# 默认情况下都是浅拷贝(只拷贝一层)
l1 = [111, 222, [333,444]]
l2 = l1.copy()
l3 = l1[:]
l1[2][0] = 666
print(l1)
print(l2)
print(l3)
>>>>
[111, 222, [666, 444]]
[111, 222, [666, 444]]
[111, 222, [666, 444]]
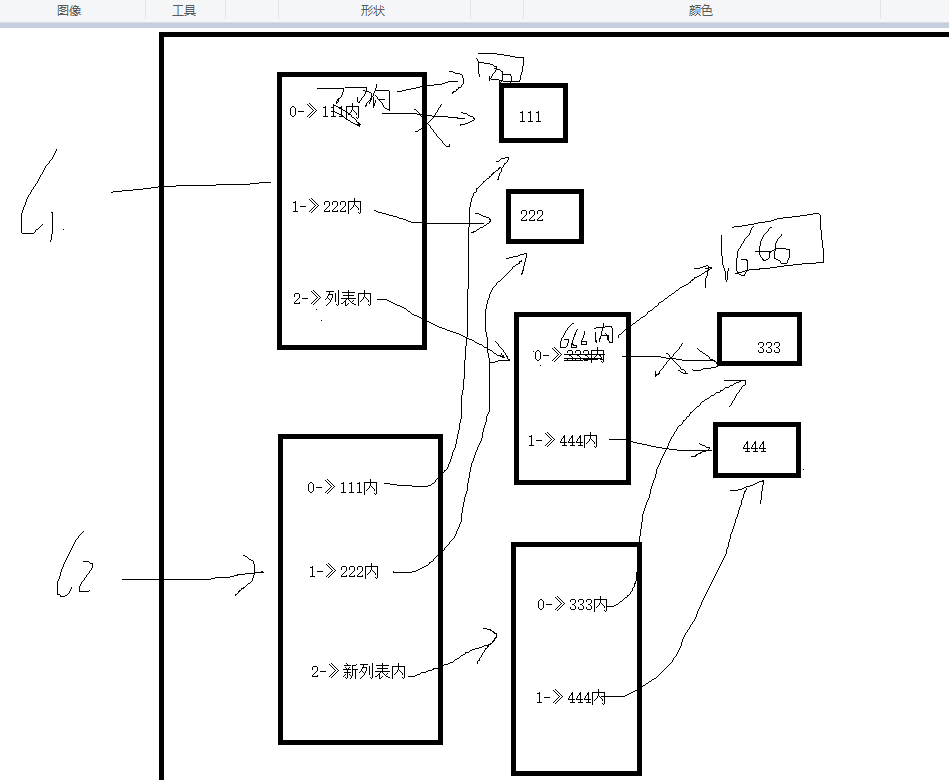
# 默认情况下都是浅copy
l1 = [111,222,[333,444]]
l2 = l1.copy()
# l3 = l1[:]
# print(id(l1[0]),id(l1[1]),id(l1[2]))
# print(id(l2[0]),id(l2[1]),id(l2[2]))
# l1[2][0] = 666
l1[0] = 777
print(l1)
print(l2)
man = ["上海",[100,]]
woman = man.copy()
man[1][0] -= 30
print(man)
print(woman)
深拷贝(每一层都拷贝)
from copy import deepcopy
l1 = [111, 222, [333, 444]]
l2 = deepcopy(l1)
print(id(l1[0]), id(l1[1]), id(l1[2]))
print(id(l2[0]), id(l2[1]), id(l2[2]))
>>>>
1950393849648 1950393853264 1950673951296
1950393849648 1950393853264 1950673997760
l1[2][0] = 666
print(l1)
print(l2)
[111, 222, [666, 444]]
[111, 222, [333, 444]]
2、集合类型
-
用途:
-
关系运算
python = ['engo','alex','张全蛋','刘全蛋','lxx'] linux = ['egon','jack','tom','lxx'] -
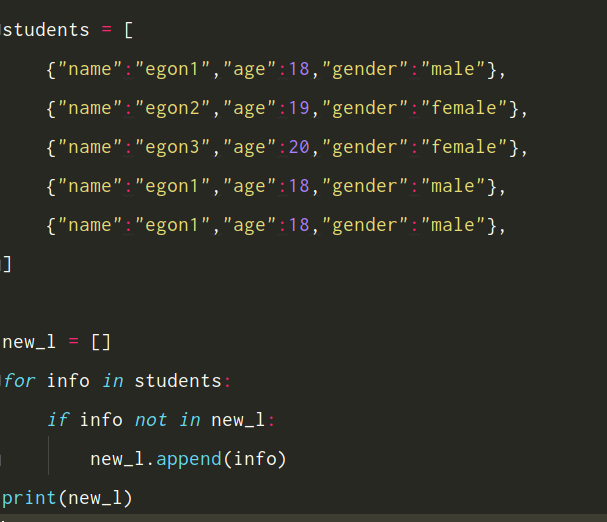
去重:局限性在于无法保证被修改列表的顺序以及若是列表中有可变类型则set会直接报错
-
-
定义方式:在{}内用逗号分隔开多个元素,需要注意的是集合的元素必须满足
- 集合内的元素必须是不可变类型
- 集合内的元素无序
- 集合内的元素没有重复的
s = {} ====> 定义的空字典 s = set() ====>定义的空集合 -
常用操作+内置方法
names = ['egon','egon','egon','lili','jack'] res = list(set(names)) >>>> ['jack', 'lili', 'egon']
关系运算:
```PYTHON
python = {'egon','alex','张全蛋','刘全蛋','lxx'}
linux = {'egon','jack','tom','lxx'}
print(python&linux) # 交集
print(python|linux) # 并集
print(python-linux) # 差集
print(python^linux) # 对称差集===并集-交集
父子集:父子指的包含与被包含的关系
父集>= 子集<=
s1 = {1, 2, 3}
s2 = {1, 2}
print(s1 > s2)>>>>True
s1 = {1, 2, 3}
s2 = {1, 2, 4}
print(s1 >= s2)>>>>False
print(s1 <= s2)>>>>False
```
内置方法
```python
print(python&linux)
print(python.intersection(linux))
print(python|linux)
print(python.union(linux))
print(python-linux)
print(python.difference(linux))
print(python^linux)
print(python.symmetric_difference(linux))
s1 = {'a', 'b', 'c', 'ab', 'ac'}
print(s1.isdisjoint({1, 2, 3})) # 若没有交集则为空
s1.discard(2) # 删除集合中的2 若不存在则不报错
s1.remove(4) # 删除集合中的4 若不存在则报错
```
总结:
-
存多个值
-
无序
-
set集合可变,frozenset不可变集合
s1 = {1,2,3} print(id(s1)) s1.add(4) print(id(s1)) print(s1)
3、回顾
# 字符串常用方法
# msg = '#^&-*(_ hellO wordllsah -=&!'
# 1索引
# print(msg[10])
# 2切片:
# print(msg[:4:-1])
# 3替换replace
# print(msg.replace('ll', 'LL', 1))
# 4切割 字符串转化为列表 split
# print(msg.split('-', 1))
# 5大小写
# print(msg.upper())
# print(msg.lower())
# 6字符串格式化 f-string/format/%s
# 7判断开头或者结尾或是数字
# print(msg.startswith('x'))
# print(msg.endswith('!'))
# print(msg.isdigit())
# 8strip/lstrip/rstrip
# msg.strip('!@#$a%') # 原理:msg先从左边开始遍历查看字符是否在strip中若在则删除直到出现第一个不在的时候从右边出发重复操作
# 9''.join(列表) 将列表转化为字符串
# print('hina'.join(['I', 'LOVE', 'HINA']))
# 10 in / not in
# 列表常用方法
ls = [111, 'aaa', 'bbb', 222, '333']
# 1索引
# print(ls[3])
# 2切片
# print(ls[1:4:2]) # 浅拷贝
# 3追加
# ls.append('ccc')
# print(ls)
# ls.extend([11,22])
# 4插入
# ls.insert(1, 'xxx')
# print(ls)
# 5删除
# del ls[0]
# print(ls)
# ls.remove(111)
# print(ls)
# a = ls.pop(1)
# print(ls)
# 6 in / not in
# 7 reverse
# ls.reverse()
# print(ls)
# print(ls[::-1])
# 8 sort(列表中数据类型要一致)
# 9 clear 清空列表但列表还在
# 元组
# 1 索引
# 2切片
# 3 len
# 4 in/not in
# 字典
dic = {'k1':1,'k2':2}
# 1 in / not in
# 2 删除
# del dic['k1'] # 单纯的删
# print(dic)
# print(dic.pop('k1')) # 取走值
# print(dic)
# print(dic.popitem()) # 随机删一组键值对
# print(dic)
# 3 keys values items
# print(dic.keys())
# print(dic.values())
# print(dic.items())
# 4 索引
# print(dic.get('k3'))
# print(dic['k1']) # 区别在于若字典中没有对应的键则get不会报错返回空而[]会报错
# 遍历
# for index, k in enumerate(dic):
# print(index, k)
#
# for k1, k12 in zip(dic,{'k3':3,"k4":4}):
# print(k1,k12)
