python day08 函数
day 08 函数
复习
-
字符编码
只能输入英文字符—————ASCII格式的二进制(内存)—————ASCII格式的二进制(硬盘)
只能输入中文和英文字符—————GBK格式的二进制(内存)—————GBK格式的二进制(硬盘)
只能输入日文和英文字符—————shift-JIS 格式的二进制(内存)—————shift-JIS 格式的二进制(硬盘)
可以输入万国字符—————unicode格式的二进制————utf-8格式的二进制
只能输入中文和英文字符—————unicode格式的二进制————gbk格式的二进制
只能输入日文和英文字符—————unicode格式的二进制————shift-JIS格式的二进制
可以输入万国字符—————utf-8格式的二进制————utf-8格式的二进制
utf8mb4————>可以存表情
保证不乱码:
1.存不乱
存入硬盘用utf-8
2.取不乱
取的编码与读的编码保持一致
- 指针移动
1.函数介绍
-
什么是函数
函数就是盛放代码的容器,把实现某一功能的一组代码丢到一个函数中就做成了一个小工具
具备某一功能的工具————>函数
事先准备工具的过程————>函数的定义
遇到应用场景拿来就用———>函数的调用
-
为何要用函数
没有用函数前面临的问题:
-
代码冗余,程序组织结构不清晰、可读性差
-
扩展性差
-
如何用函数:先定义,后调用
-
如何用函数
原则:先定义、后调用
定义函数的语法
def 函数名(参数1,参数2,......):
"""
文档注释
"""
代码1
代码2
代码3
return 返回值
如何调用函数:
函数名(1,2)
函数————————工厂
函数名———————地址
参数————————原材料
函数体代码—————工厂的流水线
返回值———————工厂的产品
一、先定义、后调用
二、函数在定义阶段发生了什么事情
定义函数不执行函数体代码,但是会检测函数体的语法
x = 10
print(x)
def func(): # func=函数的内存地址
print('start...')
print('xxx...')
print('end...')
print(func)
三、函数在调用阶段发生了什么事情
先通过函数名找到函数的内存地址,然后函数的内存地址()会触发函数体代码的运行
四、定义与调用函数的三种形式
定义的三种方式
-
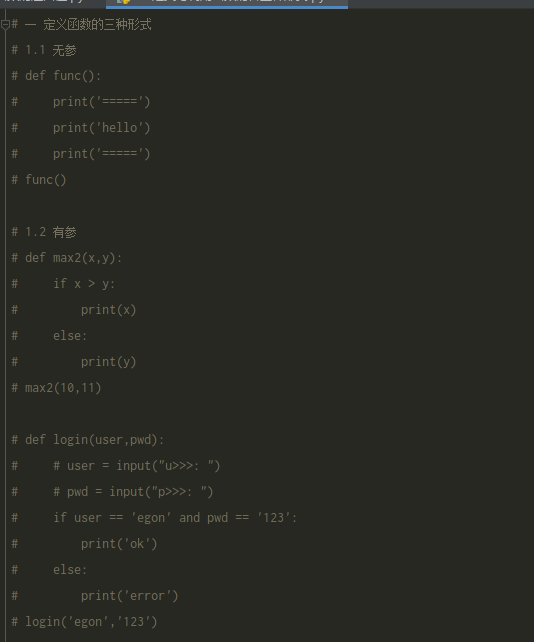
无参
-
有参
-
空函数
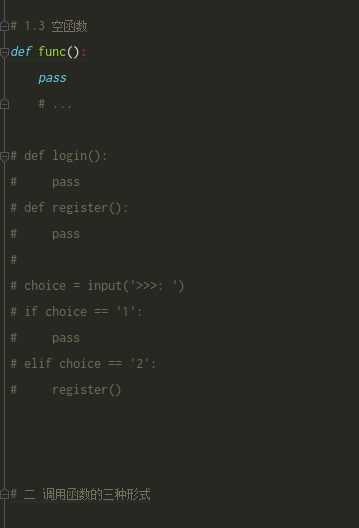
调用的三种方式
2.1语句形式:input('>>:')
2.2表达式形式:res = input('>>:')
2.3可以把函数调用当做参数传给另外一个函数
2.函数的返回值
# 用return控制函数的返回值:
# 函数内可以有多个return,但只要执行一次,整个函数就立即结束,并且将return后的值
# 当做本次调用的结果返回,具体来说,函数的返回值又分为三类
# 1.return值:返回的就是该值本身
# 2.return值1,值2,值3 返回的就是一个元组
# 3.函数内可以没有return,或者就一个return后没有值,返回的就是None
3.函数的参数
-
形参:在函数定义阶段括号内定义的变量名,称之为形式参数,简称形参
-
实参:在函数调用阶段括号内传入的值,称之为实际参数,简称实参
形参与实参的关系是:
在调用函数参数时,实参的值会绑定给形参名,然后可以在函数内使用,函数调用完毕后,解除绑定
# 一 函数参数分为两大类:
# 1、形参:在函数定义阶段括号内定义的变量名,称之为形式参数,简称形参
# 2、实参:在函数调用阶段括号内传入的值,称之为实际参数,简称实参
# 形参与实参的关系是:
# 在调用函数时,实参的值会绑定给形参名,然后可以在函数内使用,函数调用完毕后,解除绑定
# def func(x,y):
# # x=1
# # y=2
# print(x+y)
#
# m = 1
# n = 2
# func(m,n)
# 二:参数详解
# 2.1 位置形参::在函数定义阶段按照从左到右的顺序依次定义的形参,称之为位置形参
# 特点:必须被传值,多一个不行少一个也不行
# def func(x,y):
# print(x+y)
# func(1,2)
# func(1,2,3)
# func(1,)
# 2.2 默认形参:在函数定义阶段就已经为某个形参赋值了,称之为默认形参
# 特点:在函数定义阶段就已经赋值了,意味着在调用阶段可以不用为其赋值
# ps: 可以混用位置形参与默认形参,但是位置形参必须在前
# def func(x,y=2):
# print(x)
# print(y)
# func(1,3)
# func(1)
# def register(name,age,gender="male"):
# print(name,age,gender)
#
# register("李铁蛋",38)
# register("王全蛋",19)
# register("赵银蛋",28)
# register("lili",18,"female")
# 默认形参需要注意的问题是:
# 1、默认形参的值只在函数定义阶段被赋值一次
# 2、默认形参的值通常应该是不可变类型
# 案例1
# m = 100
# def func(x,y=m): # y -> 100的内存地址
# print(x,y)
#
# m = 200
# func(1)
>>>>
(1,100)
# 案例2
# m = [11,22,]
# def func(x,y=m): # y -> [11,22,]的内存地址
# print(x,y)
#
# # m = 200
# m.append(33)
# func(1)
>>>>
(1,[11,22,33])
def register(name, x, hobbies=[]): # hobbies = []内地址
hobbies.append(x)
print("%s 的爱好是 %s" % (name, hobbies))
register("egon", 'read')
register("liu", 'chou')
register("hxx", 'tang')
>>>>
egon 的爱好是 ['read']
liu 的爱好是 ['read', 'chou']
hxx 的爱好是 ['read', 'chou', 'tang']
def register(name,x,hobbies=None): # hobbies = []内地址
if hobbies is None:
hobbies = []
hobbies.append(x)
print("%s 的爱好是 %s" %(name,hobbies))
register("egon",'read')
register("liu",'chou')
register("hxx",'tang')
>>>>
egon 的爱好是 ['read']
liu 的爱好是 ['chou']
hxx 的爱好是 ['tang']
# 2.3 位置实参:在函数调用阶段按照从左到右的顺序依次传入的值,称之为位置实参
# 特点:按照顺序与形参一一对应
# def func(x,y):
# print(x)
# print(y)
#
# func(1,2)
# func(2,1)
# 2.4 关键字实参:在函数调用阶段按照key=value的格式传入的值,称之为关键字实参
# 特点:可以打乱顺序,但是仍然能够为指定的形参赋值
# ps:可以混用位置实参与关键字实参,但是
# 1、位置实参必须在关键字实参前
# 2、不能为同一个形参重复赋值
# def func(x,y):
# print(x)
# print(y)
# func(y=2,x=1) >>>>2,1
# func(1,y=2) >>>>1,2
# func(y=2,1) >>>>ERROR
# func(1,2,y=3) >>>>ERROR
# 2.5 *与**在形参与实参中的应用
# 可变长的参数:可变长指的是在函数调用阶段,实参的个数不固定,而实参是为形参赋值的,所以对应着必须要有一种特殊格式的形参
# 能用来接收溢出的实参
# 形参中带*:*会接受溢出的位置实参,将其存成元组,然后赋值给紧跟其后的变量名
# def func(x, **y): # y = (2, 3, 4, 5, 6)
# print(x)
# print(y)
# func(1, 2, 3, 4, 5, 6)
# 形参中带**:**会接受溢出的位置实参,将其存成字典,然后赋值给紧跟其后的变量名
# def func(x, **y): # y = {'a': 2, 'b': 3, 'c': 4}
# print(x)
# print(y)
# func(1, a=2, b=3, c=4)
# func(1, 2, 3, a=1, b=2, c=3) # 报错
# def my_sum(*x):
# print(sum(x))
#
#
# my_sum(1, 2, 3, 4)
# 实参中带*:*后跟的必须是一个可以被for循环遍历的类型,
# *会将实参打散成位置实参
# def func(x, y, z):
# print(x)
# print(y)
# print(z)
#
#
# func(*[11, 22, 33])
# 实参中带**:**后跟的必须是一个字典,
# **会将实参打散成关键字实参
def func(x, y, z):
print(x)
print(y)
print(z)
func(**{'x': 1, 'y': 2, 'z': 3})
def index(x, y, z):
print(x, y, z)
def wrapper(*args, **kwargs): # args = (1,2,3,4,5,6,7) kwargs = {"a":1,"b":2,"c":3}
print(args)
print(kwargs)
index(*args, **kwargs) # index(*(1,2,3,4,5,6,7),**{"a":1,"b":2,"c":3})
# index(1,2,3,4,5,6,7,a=1,b=2,c=3)
# wrapper(1, 2, 3, 4, 5, 6, 7, a=1, b=2, c=3)
>>>>
(1, 2, 3, 4, 5, 6, 7)
{'a': 1, 'b': 2, 'c': 3}
Traceback
wrapper(1, z=2, y=3)
>>>>
(1,)
{'z': 2, 'y': 3}
1 3 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号