

CPU大小端模式及转换
通信协议中的数据传输、数组的存储方式、数据的强制转换等这些都会牵涉到大小端问题。
CPU的大端和小端模式很多地方都会用到,但还是有许多朋友不知道,今天暂且普及一下。
一、为什么会有大小端模式之分呢?
因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。
但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的int型。另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。
对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。
二、什么是大端和小端?
大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中。
小端模式:是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。
假如32位宽(uint32_t)的数据0x12345678,从地址0x08004000开始存放:
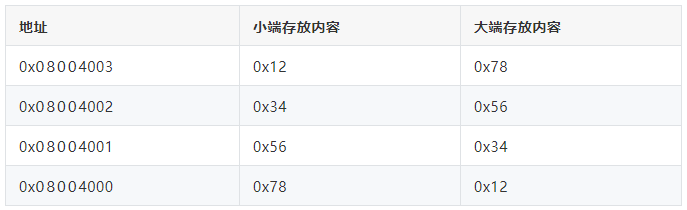
再结合一张图进行理解:

从上面表格、图可以看得出来,大小端的差异在于存放顺序不同。
三、数组在大端小端情况下的存储
以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value。
1.大端模式下
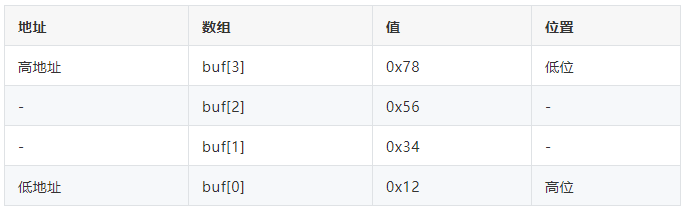
2.小端模式下

不知道大家对数组进行强制转换成整型数据没有?
如果你要进行强制转换,肯定要考虑大小端问题。
四、大小端谁更好?
小端模式:强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式:符号位的判定固定为第一个字节,容易判断正负。
总结:大端小端没有谁优谁劣,各自优势便是对方劣势。
五、大小端转换
开篇说了,实际应用中,大小端应用的地方很多通信协议、数据存储等。如果字节序不一致,就需要转换。
只要你理解其中原理(高低顺序),转换的方法很多,下面简单列列两个。
1.对于16位字数据
#define BigtoLittle16(A) (( ((uint16)(A) & 0xff00) >> 8) | \
(( (uint16)(A) & 0x00ff) << 8))
2.对于32位字数据
#define BigtoLittle32(A) ((( (uint32)(A) & 0xff000000) >> 24) | \
(( (uint32)(A) & 0x00ff0000) >> 8) | \
(( (uint32)(A) & 0x0000ff00) << 8) | \
(( (uint32)(A) & 0x000000ff) << 24))

posted on 2019-11-29 23:05 Big_Chuan 阅读(4333) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具