KMP 算法
总结自:最浅显易懂的 KMP 算法讲解
KMP 算法是一个经典的字符串匹配算法。字符串匹配是一个非常基本的操作,也就是在一个字符串中寻找另一个子串。
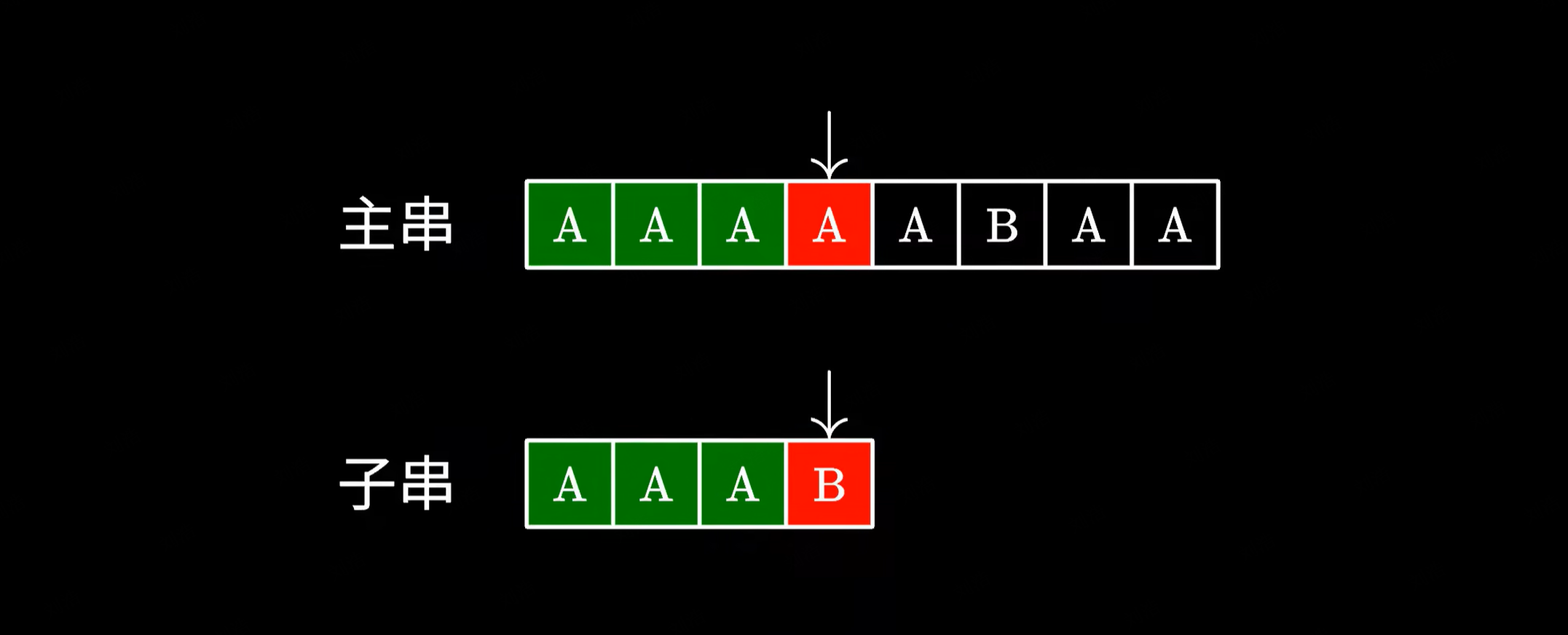
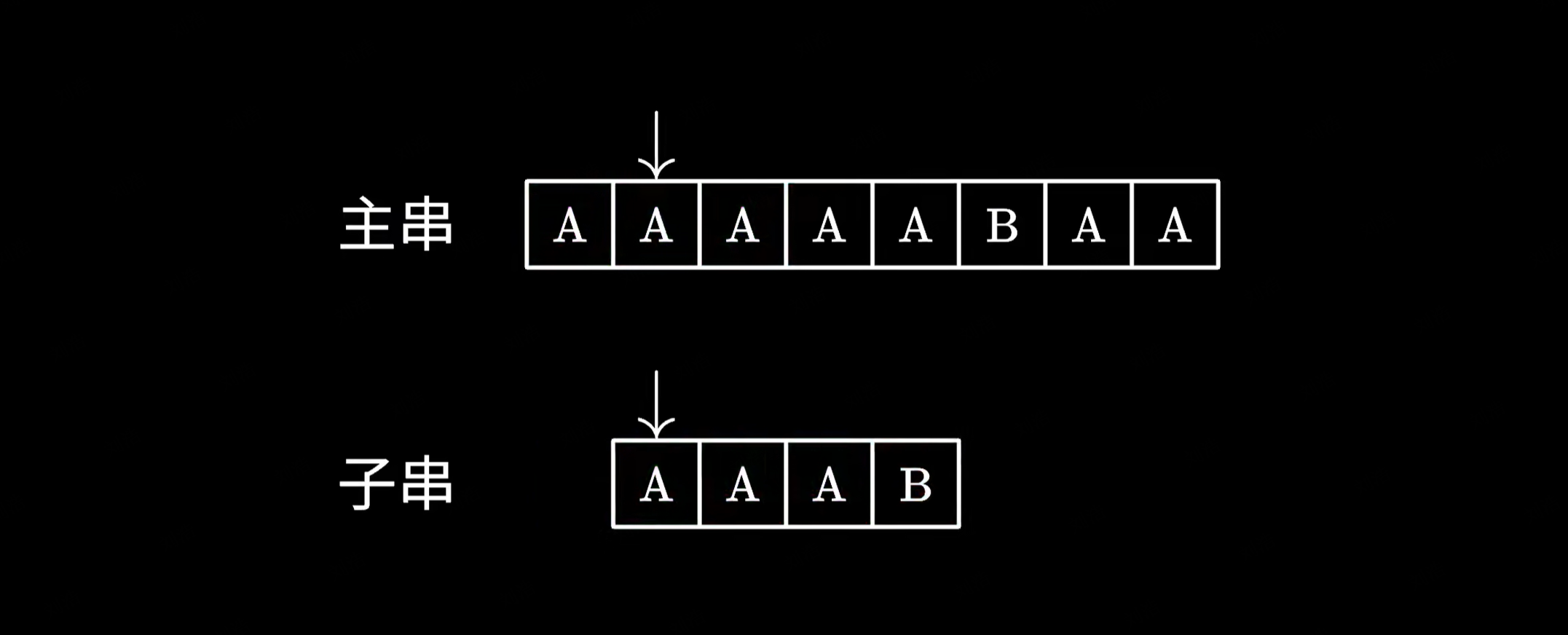
最容易想到的解法是一种暴力匹配的算法,比如一个字一个字地与子串进行比对,一旦匹配失败,就跳回主串中的下一个字符,重新开始匹配。
 |
 |
 |
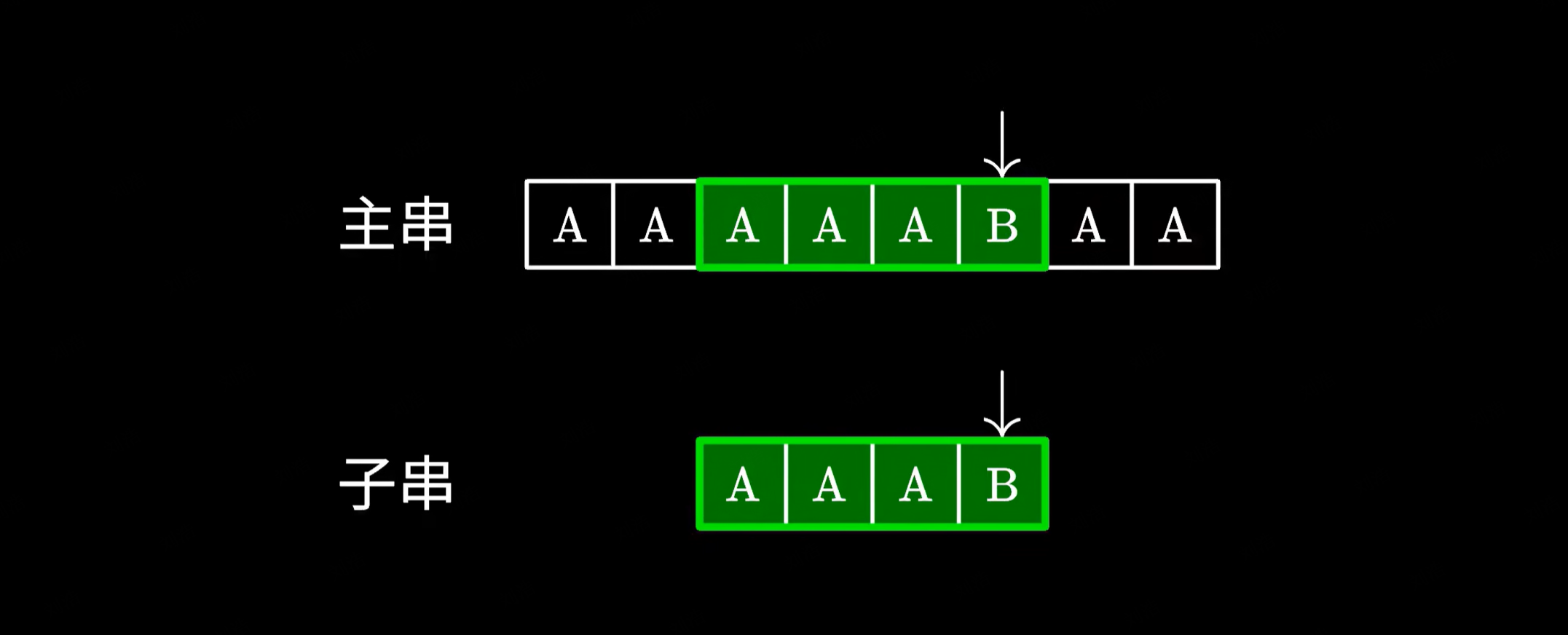 |
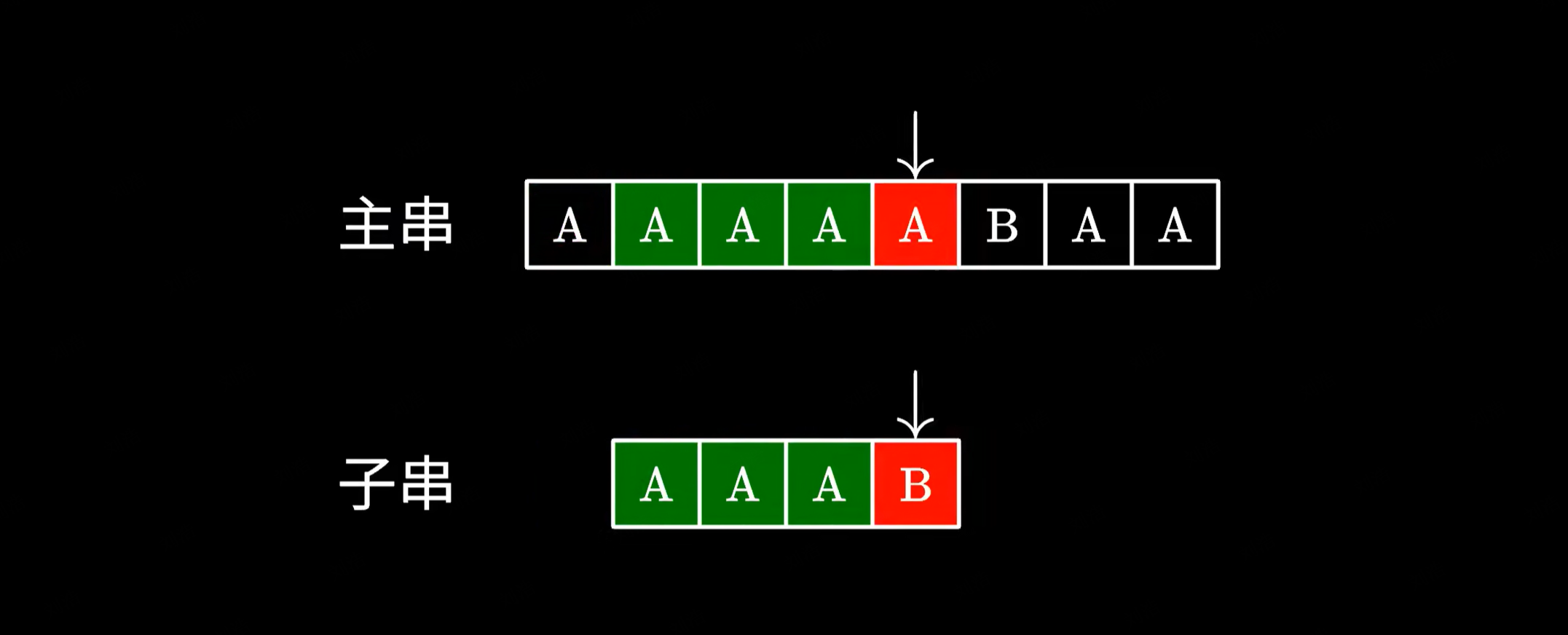
这个算法的原理很简单,实现起来也十分容易,但最大的问题在于它的时间复杂度,假如你运气不好,恰好碰到主串和子串都是若干个 A,最后仅跟一个 B 的情况。这个时候算法会很傻地把前面的 A 都比对完,然后发现最后一个字符不匹配,于是跳回下一个字符重新比对,做了不少的无用功。
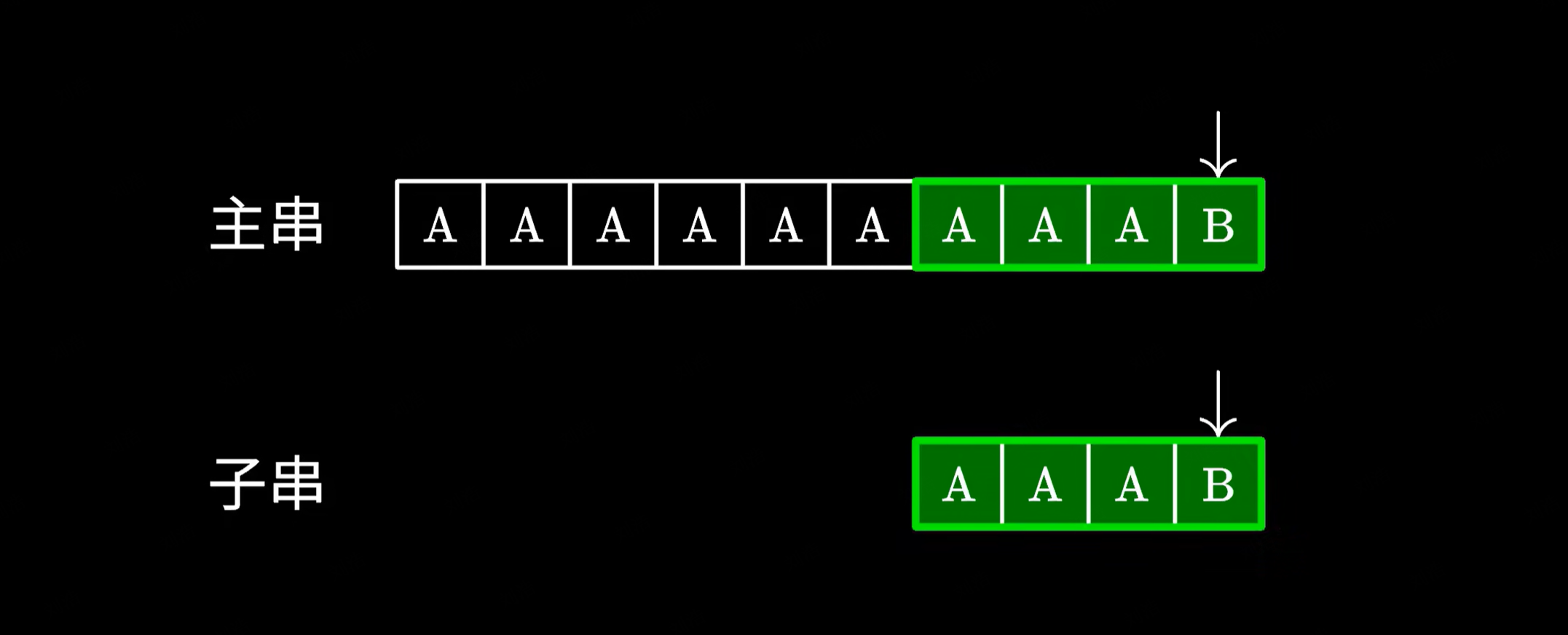 |
不难发现这是一个 O(N · M) 时间复杂度的算法(其中 n 和 m 分别为主串和子串的长度),因此效率极低。
这个时候有三位大佬 D.E.Knuth、J.H.Morris、V.R.Pratt 他们就想:既然字符串在比对失败的时候,我们已经知道之前都读过哪些字符了,有没有可能避免“跳回下一个字符再重新匹配”的步骤呢?
 |
于是他们就发表了线性时间复杂度的 KMP 算法。KMP 算法中,你只需要在一次字符串遍历的过程中,就可以匹配出子串,时间复杂度为 O(n + m)。
KMP 算法的基本思路是,当我们发现某一个字符不匹配的时候,由于已经知道之前遍历过的字符,那能不能利用这些信息来避免暴力算法中回退的步骤呢?换句话说,我们不希望递减主串的这个指针,而让它永远向前方移动。如果能做到这一点,我们的算法不就可以改进为线性时间复杂度了吗?
 |
 |
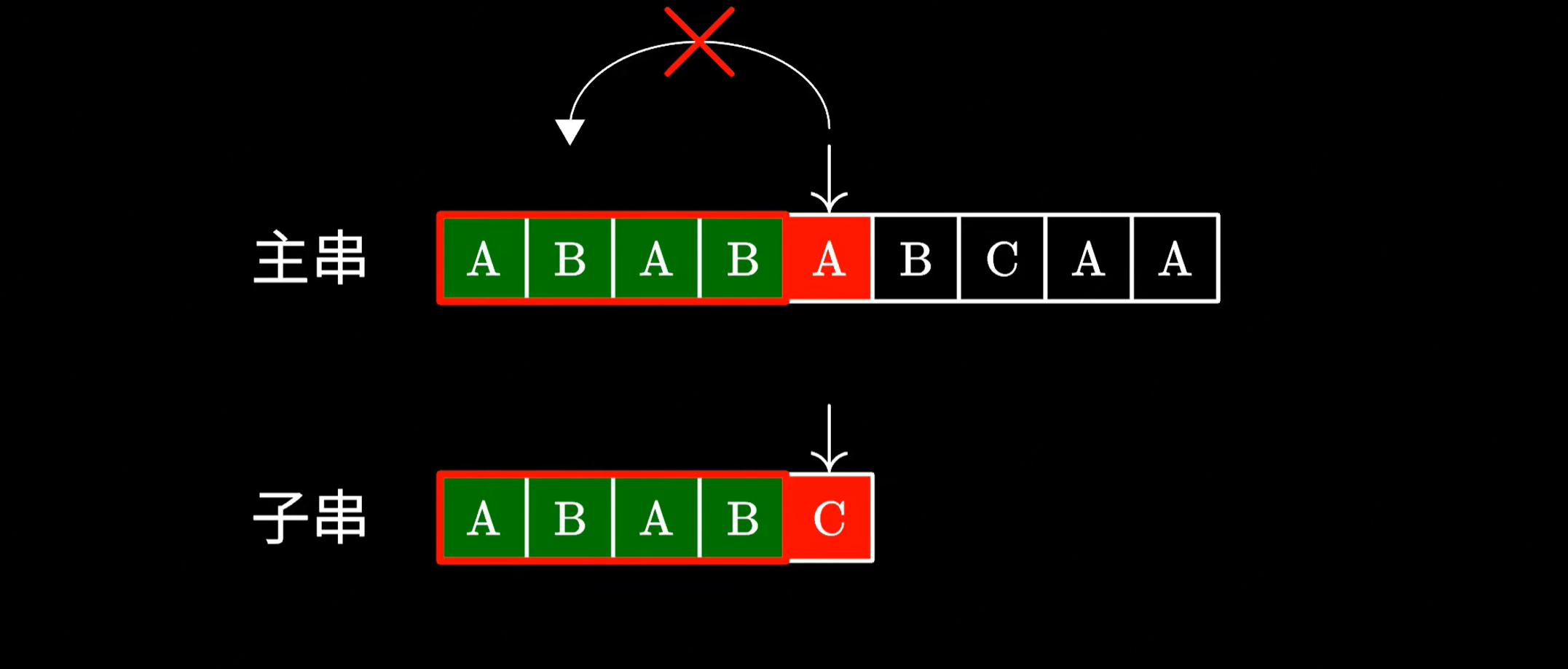
给大家举个例子,这里我们在主串中搜索 ABABC。然后发现最后一个字符不匹配:
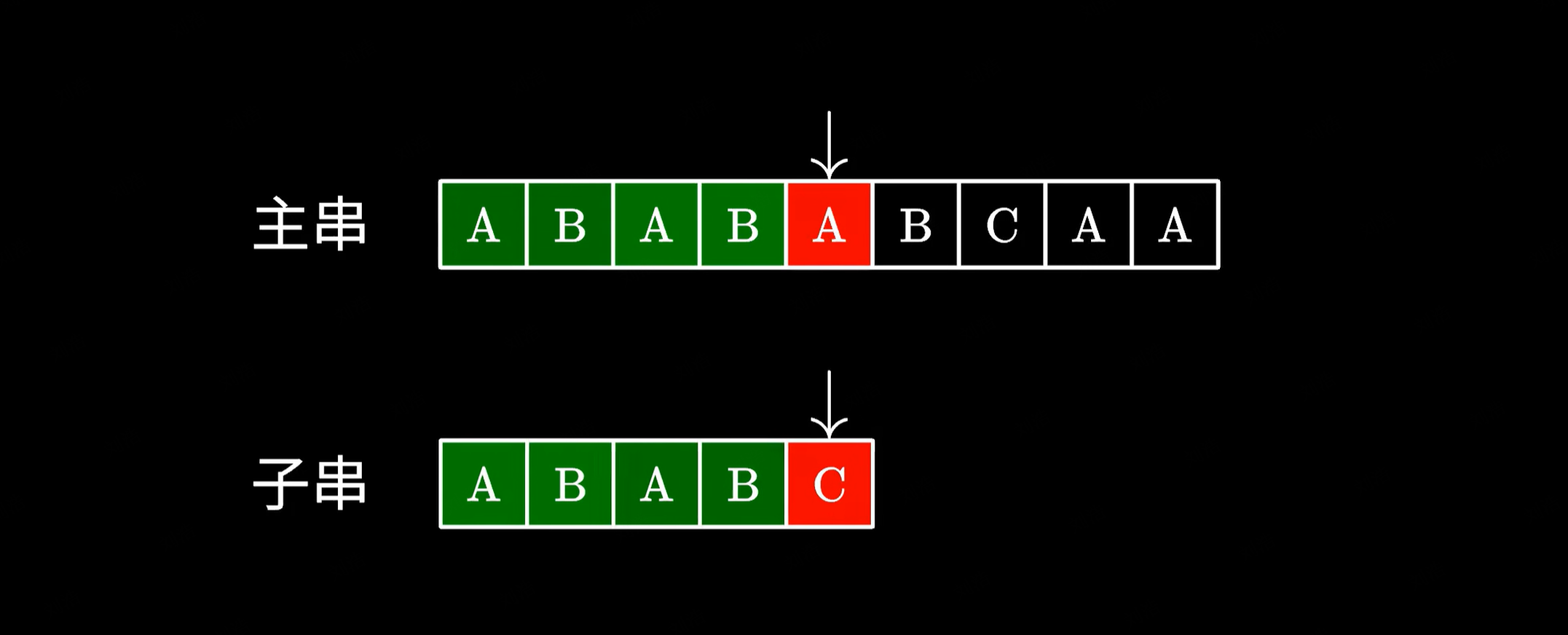 |
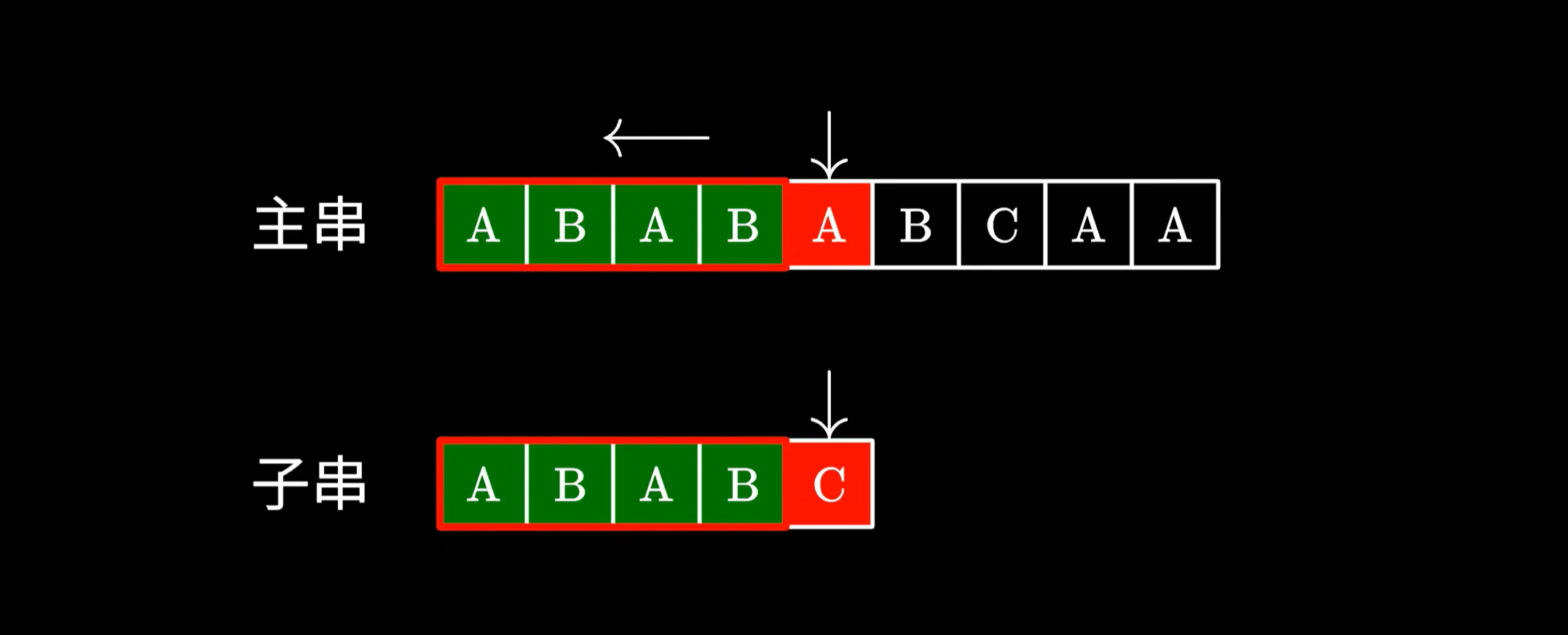
这个时候由于我们已经知道前面都读到过哪些字符,是不是可以将子串移动到这个位置,接着进行匹配呢?
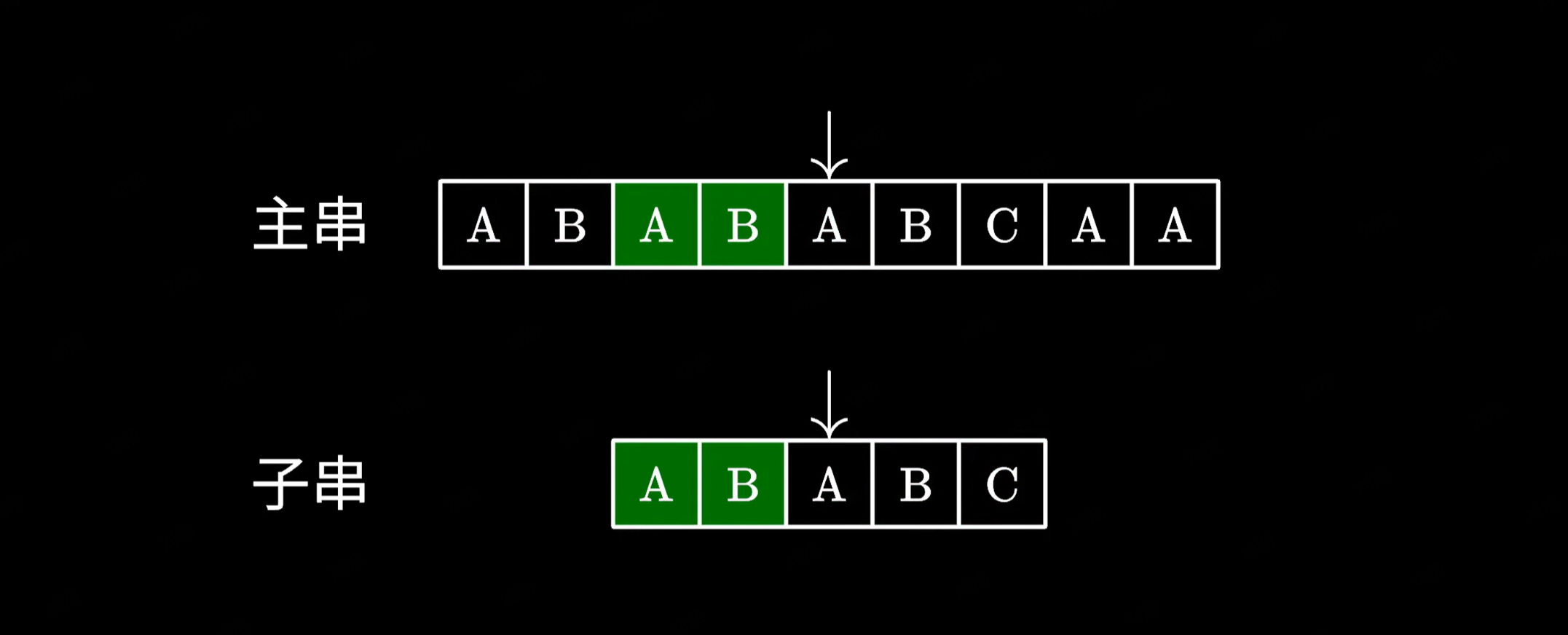 |
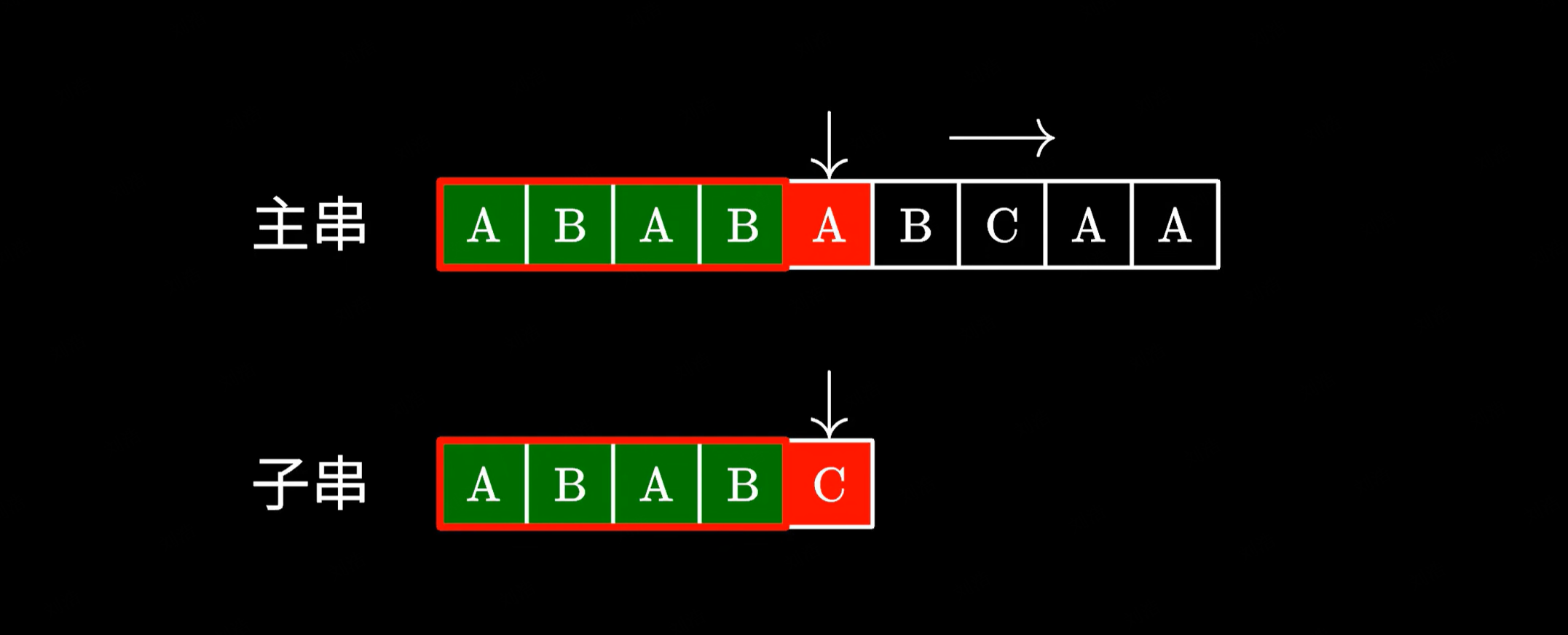
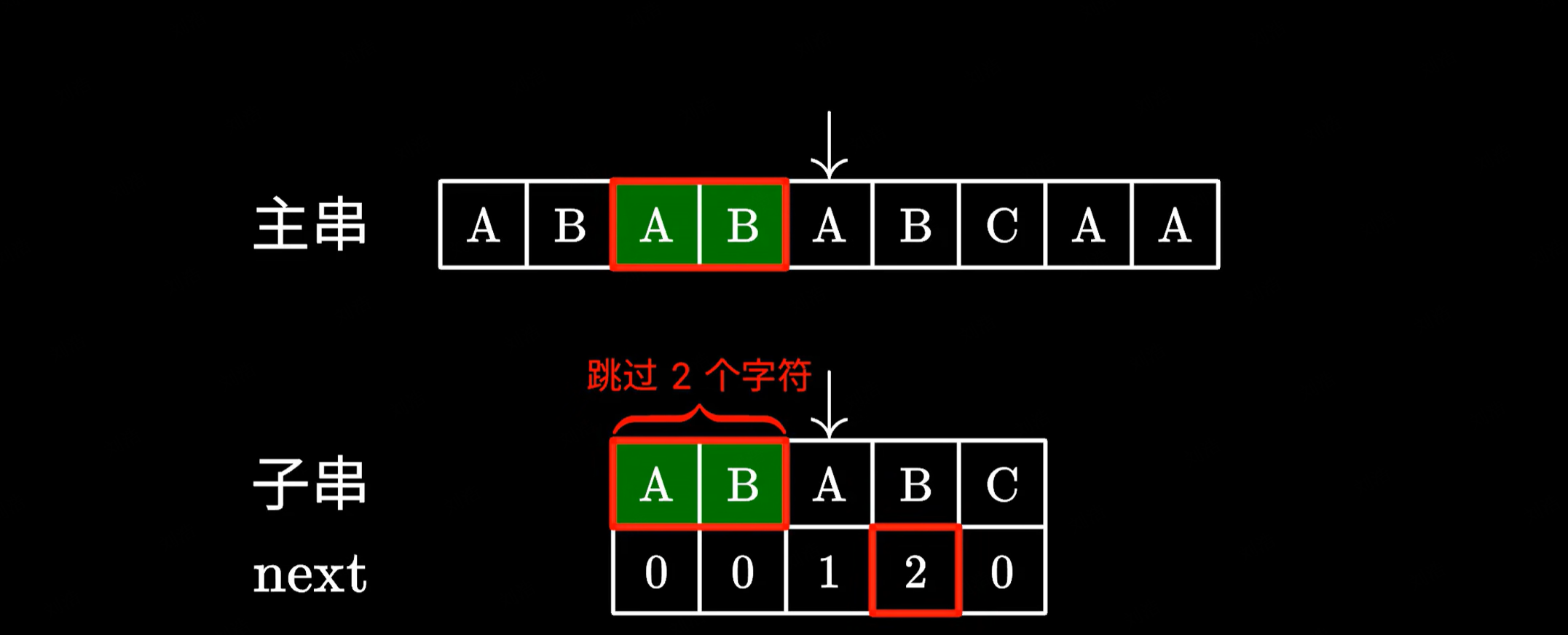
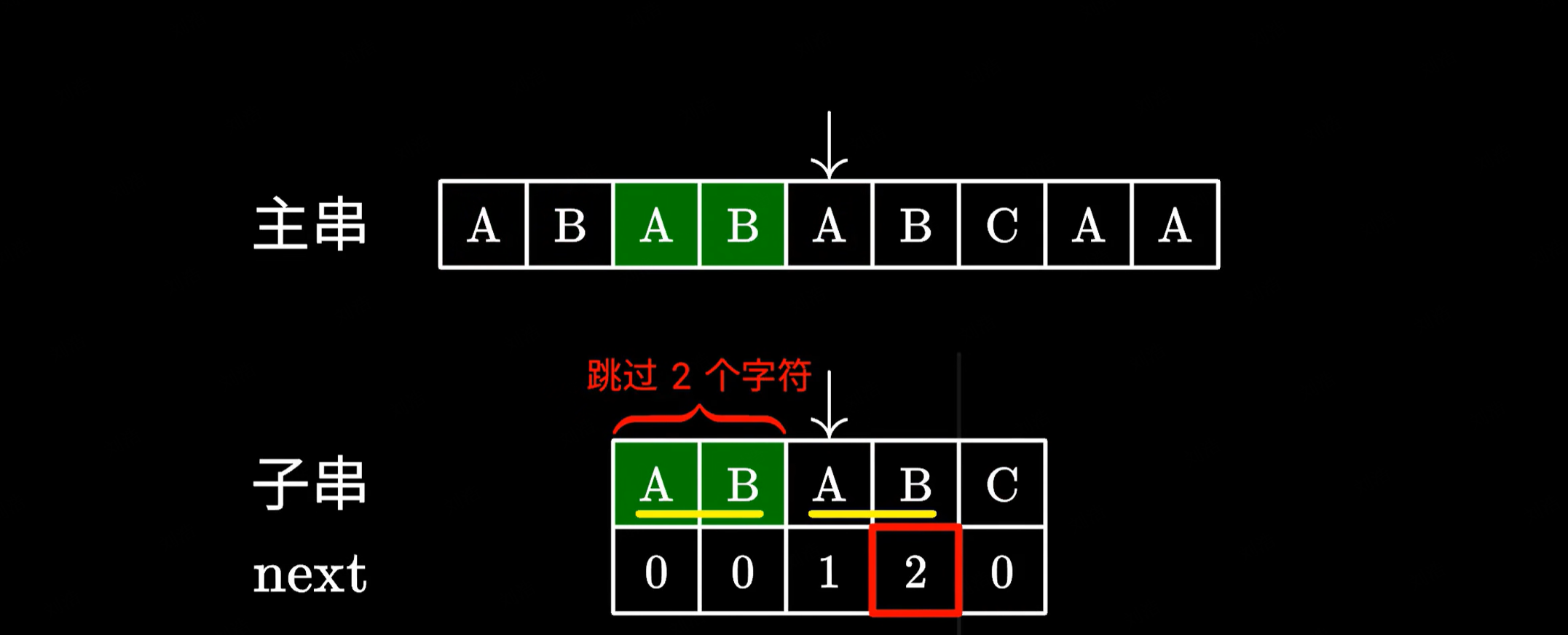
由于这里的 AB 和主串中的 AB 是相同的,我们完全可以跳过它们避免重复的比对。接下来只需要继续测试后面的字符就好了。
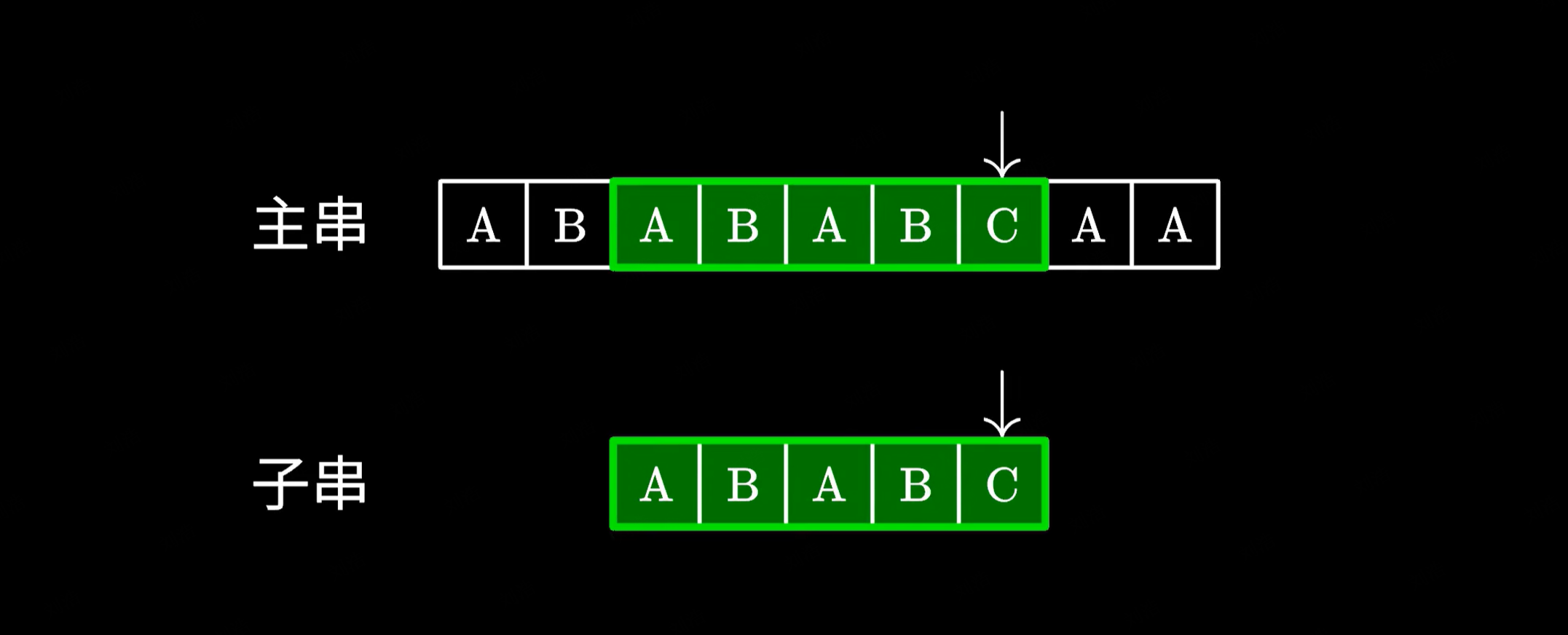 |
那你可能会问,我们怎么知道应该跳过多少个字符呢?这里就要用到 KMP 中定义的 next 数组了。我们先不管 next 数组是怎样生成的,先来看一下它的功能和用途。
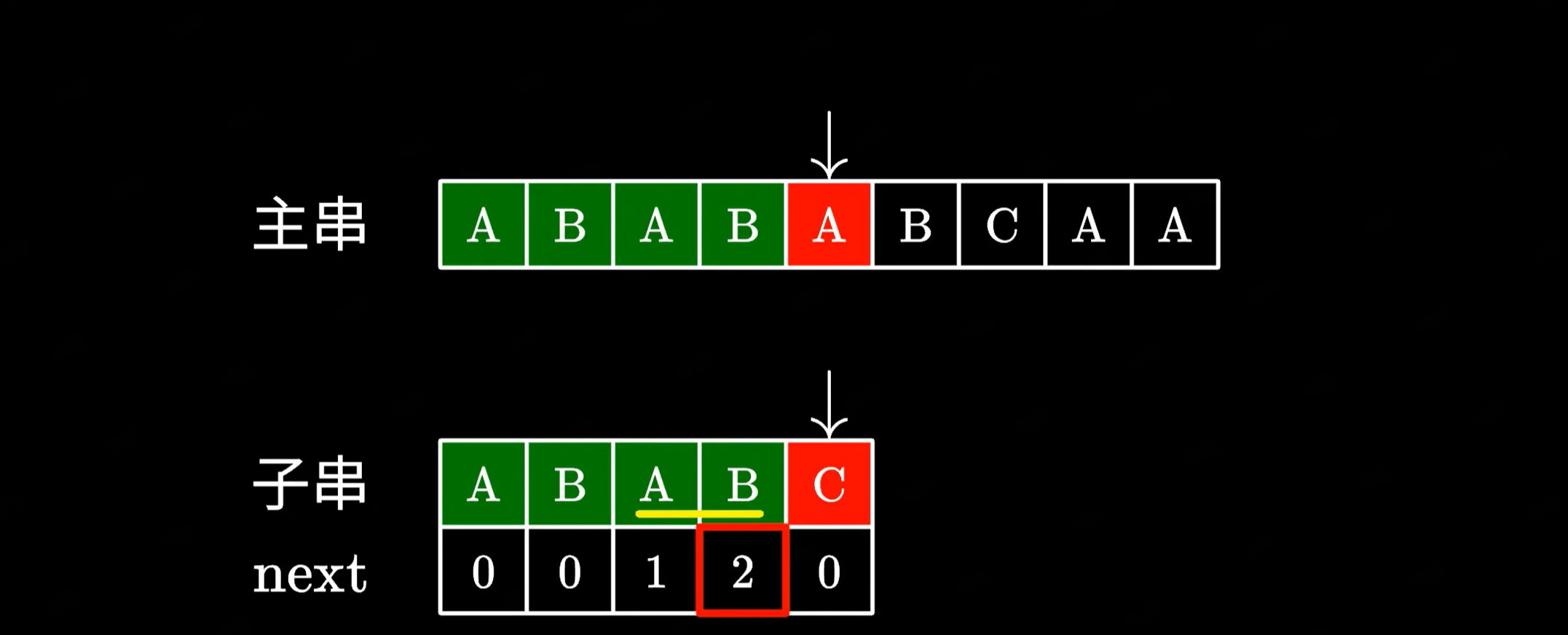
KMP 算法在匹配失败的时候,会去看最后一个匹配的字符它所对应的 next 数值:
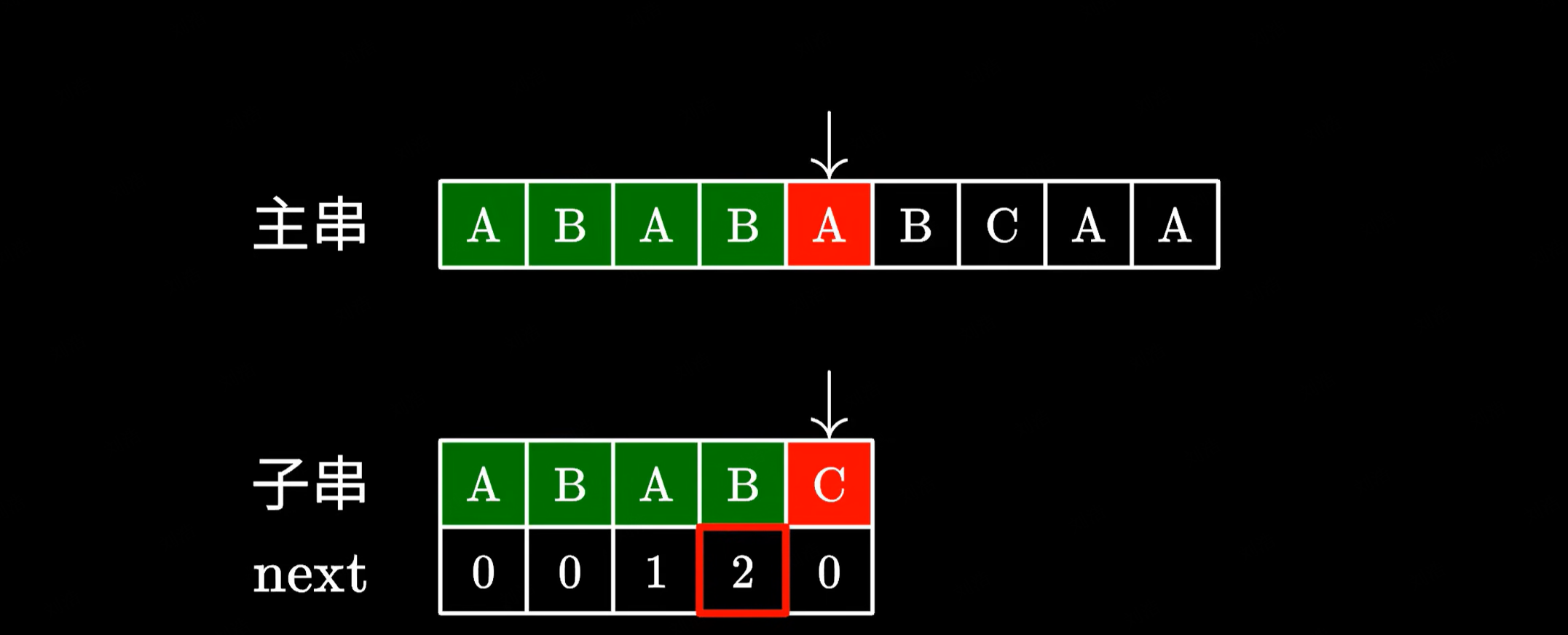 |
比如这里是 2,于是我们移动子串,直接跳过前面的这两个字符。这里的 2 代表子串中我们可以跳过匹配的字符个数,也就是说前面的这两个 AB 不需要看了,直接从下一个字符接着匹配。
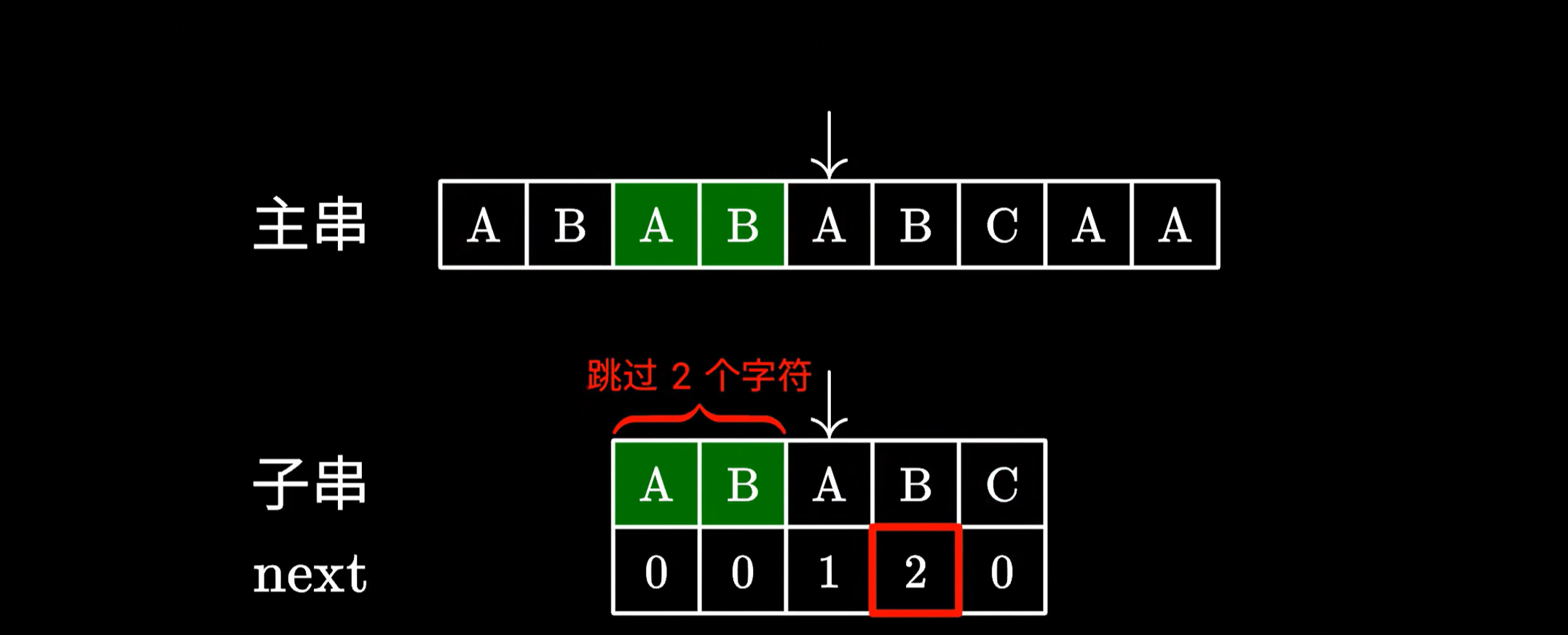 |
很显然这样是没有问题的,因为跳过的这两个 AB 确实能够与主串中的 AB 匹配上,所以我们只需要继续测试后面的字符就好了。
 |
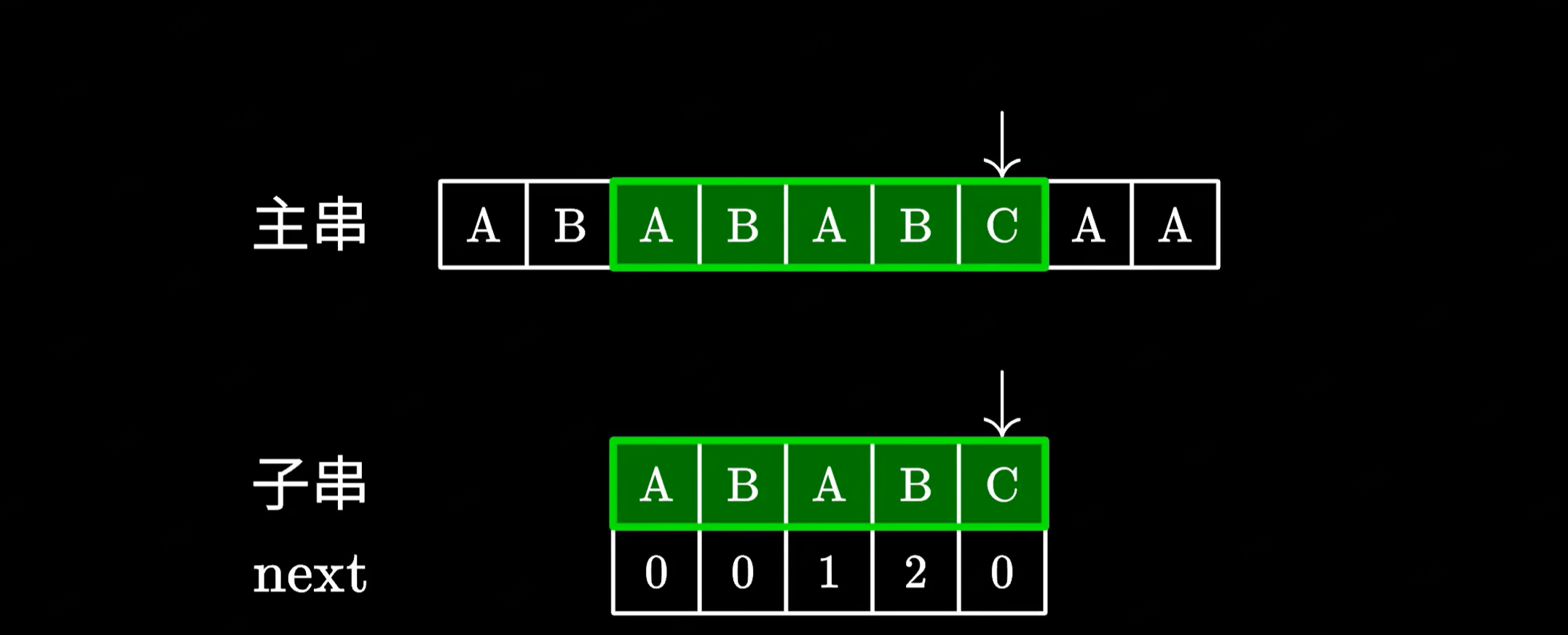 |
由于不再需要回退主串中的指针,只需要一次主串的遍历就可以完成匹配,效率自然会比之前的暴力算法高很多。
那么接下来我们来看一下 KMP 算法的程序实现。这里假设我们已经事先得出了 next 数组,关于数组的计算我马上讲到。
def kmp_search(string, patt):
next = build_next(patt) # 假设我们已经算出了 next 数组
i = 0 # 主串中的指针
j = 0 # 子串中的指针
while i < len(string):
if string[i] == patt[j]: # 字符匹配,指针后移
i += 1
j += 1
elif j > 0: # 字符失配,根据 next 跳过子串前面的一些字符串
j = next[j - 1]
else: # 子串第一个字符就失配
i += 1
if j == len(patt): # 匹配成功
return i - j
首先我们逐个字符地比较,如果当前字符相同则同时递增 i、j 这两个指针,如果不相同则根据 next 数值跳过子串前几个字符的比较。需要注意的是这里的 i 永远不递减,这也是 KMP 算法的精髓。如果指针对已经到达了子串的末尾,则代表匹配成功,我们直接返回匹配的起始位置即可。
这里程序的逻辑还是比较简单的,时间复杂度为 O(n)。
那么接下来要解决的关键问题就是 next 数组的生成了。
之前我们讲到 next 数组中的数值代表在匹配失败的时候,子串中可以跳过匹配的字符个数,如果是 2 就代表我们可以跳过前两个字符的比较。但凭什么可以这么做呢?
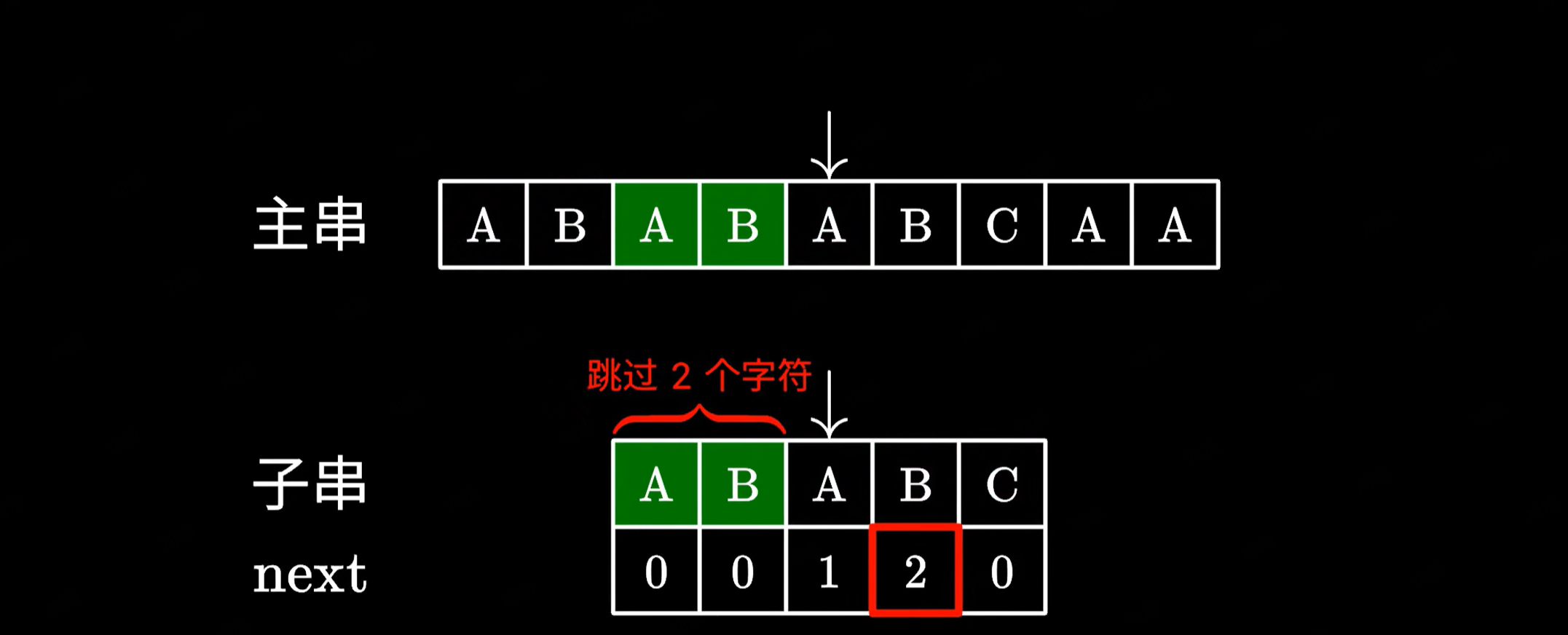 |
因为我们之前成功匹配的最后这两个 AB:
 |
和这里跳过的最前面的这两个 AB 是完全一样的:
 |
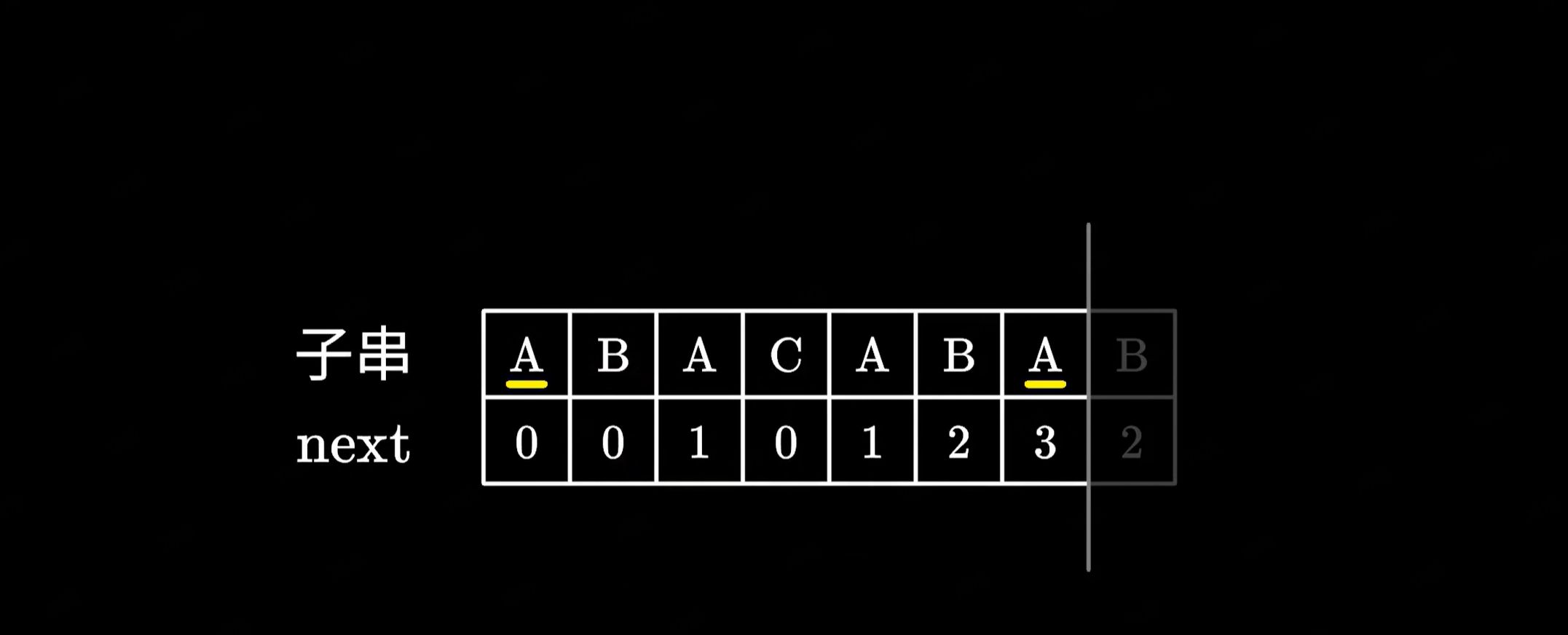
换句话说,对于子串的前四个字符。它们拥有一个共同的前缀和后缀 AB 长度为 2。
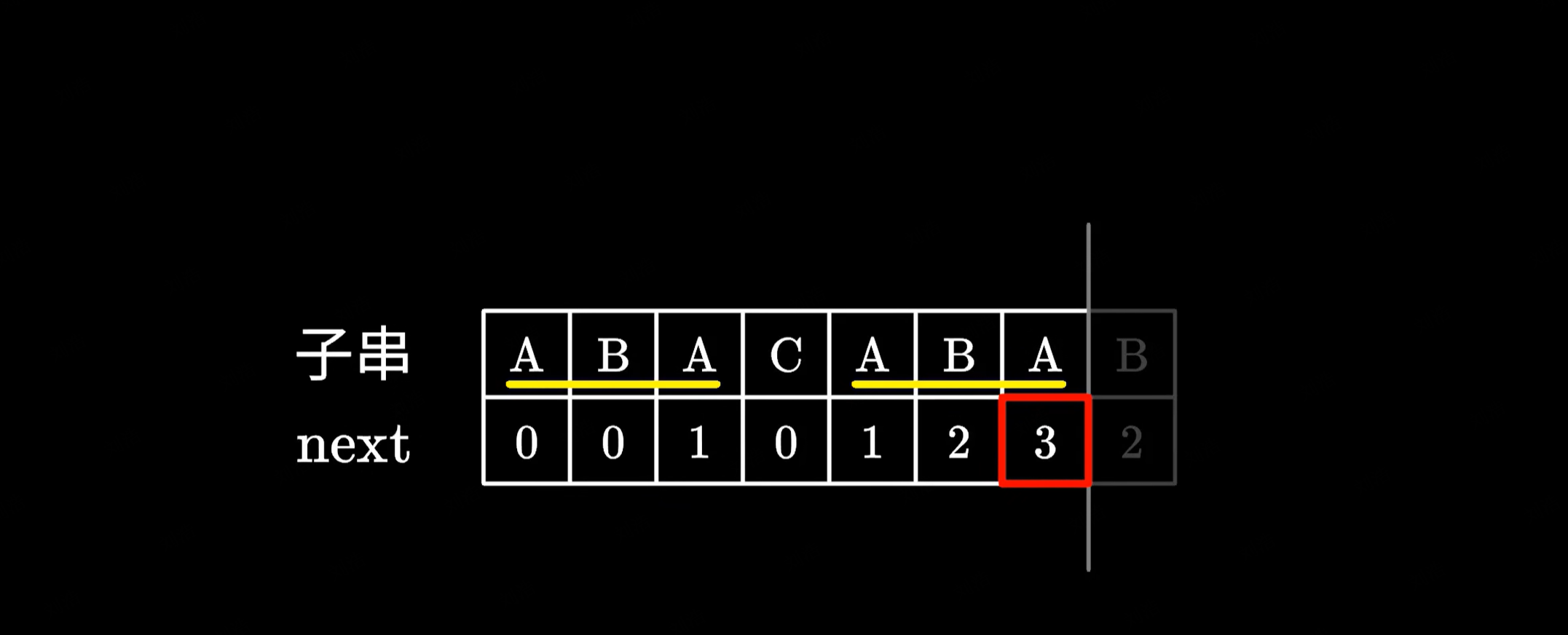
所以可以发现 next 数组的本质,其实就是寻找子串中相同前后缀的长度,并且一定是最长的前后缀。比如这里的 A-A 虽然也相同,但它并不是最长的,这里还有一个更长的 ABA,因此 next 为 3。
 |
 |
另外我们要找的前后缀不能是字符串本身,比如我们总共就四个字符,如果还跳过前四个字符的比较,那情况还有意义吗?
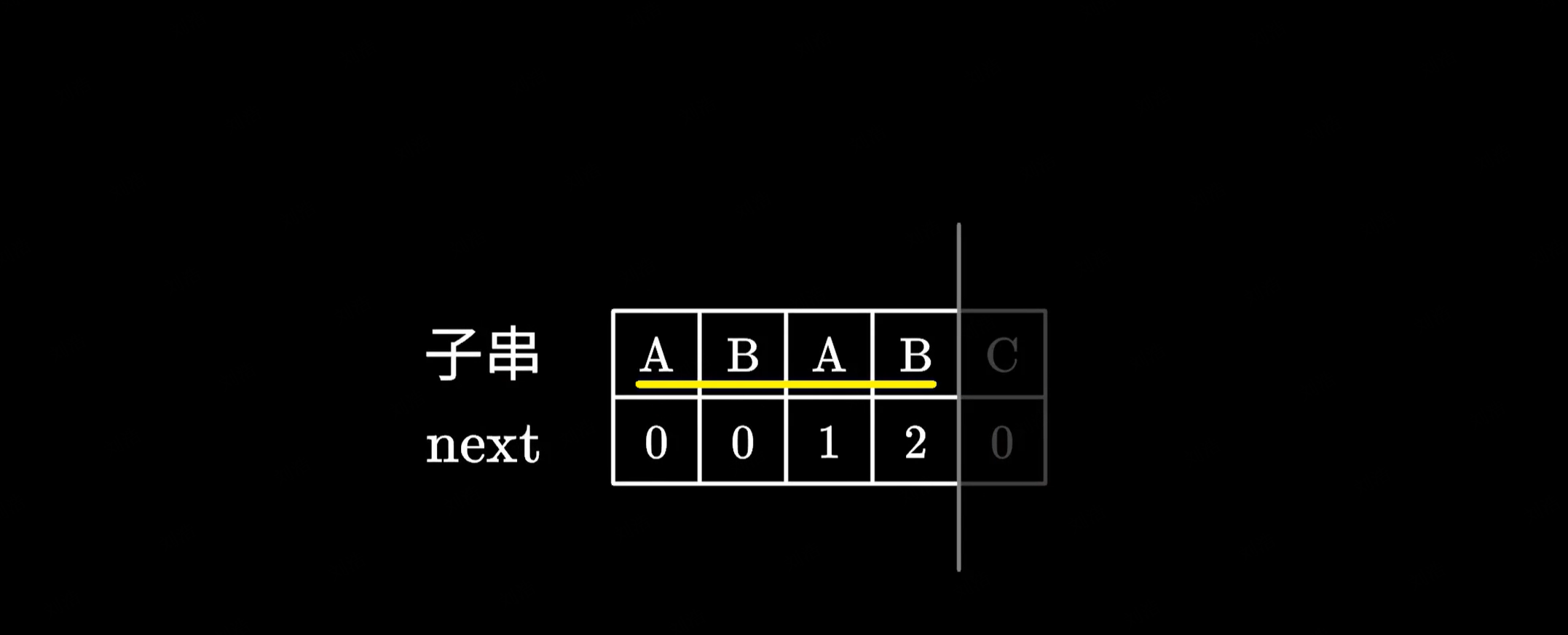 |
下面我们还是以 ABABC 为例,来说明一下 next 数组的计算:
- 首先对第一个字符,显然不存在比它还短的前后缀,所以 next 直接为 0;
- 接着对于前两个字符,同样没有相同的前后缀,所以 next 为 0;
- 对于前三个字符,由于 A 是共同的前后缀,所以 next 为 1;
- 对于前四个字符,由于 AB 是共同的前后缀,next 为 2;
- 对于前五个字符,同样找不到相同的前后缀,所以 next 为 0;
- 这样我们就计算得到了整个 next 数组。
但算法应该怎么写呢?
我们当然可以用 for 循环暴力求解,但显然效率太低,其实这里可以采用一种递推的方式来快速求解 next 数组,它的巧妙之处在于会不断地利用已经掌握的信息,来避免重复的运算。
假设我们已经知道当前的共同前后缀了,长度为 2:
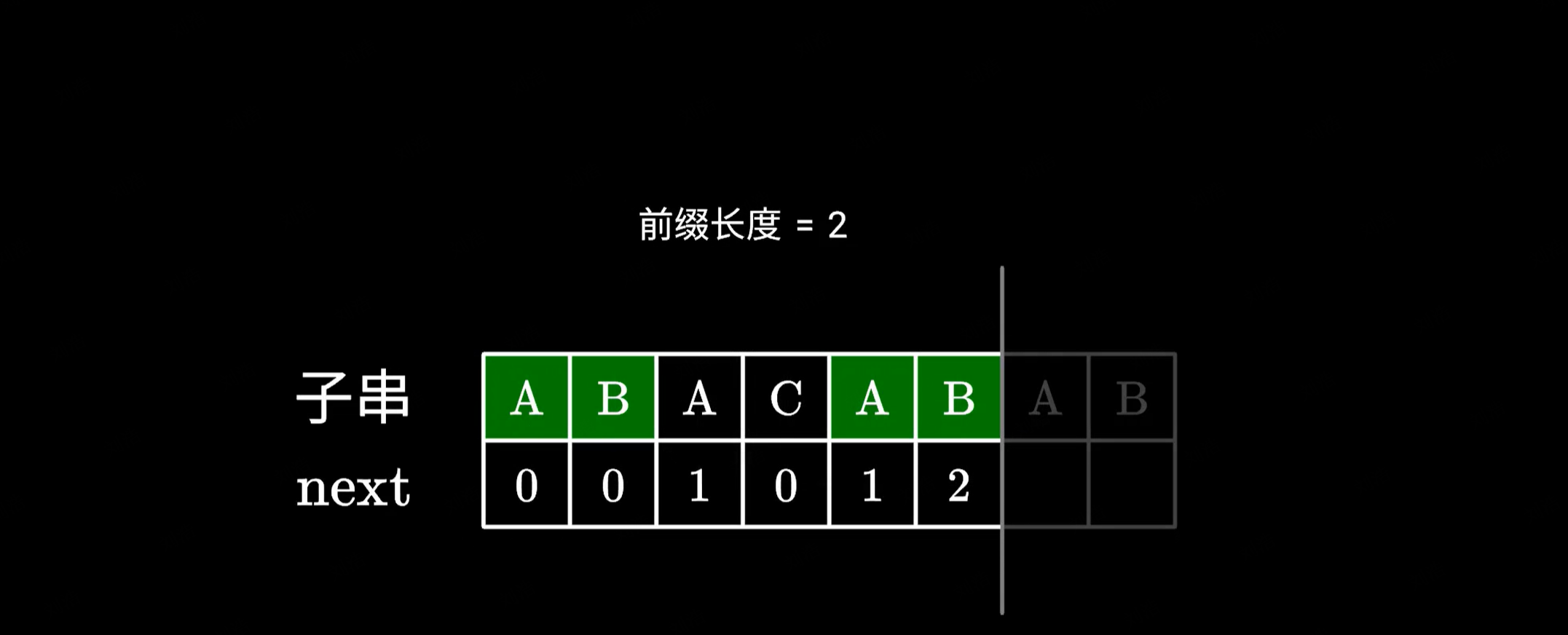 |
接下来分两种情况讨论:
- 如果下一个字符依然相同的话,不就直接构成了一个更长的前后缀吗?很明显它的长度等于之前的加上 1;
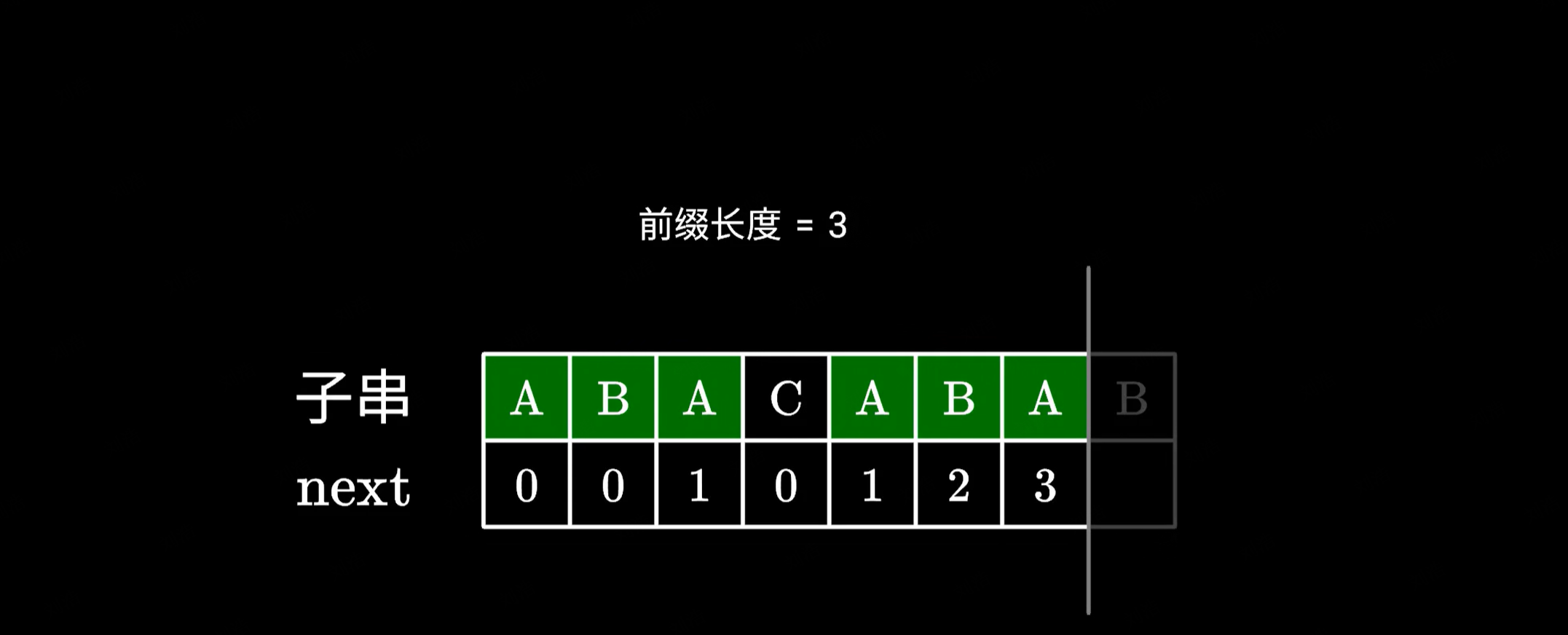 |
- 但如果下一个字符不同的话,又应该怎么办呢?
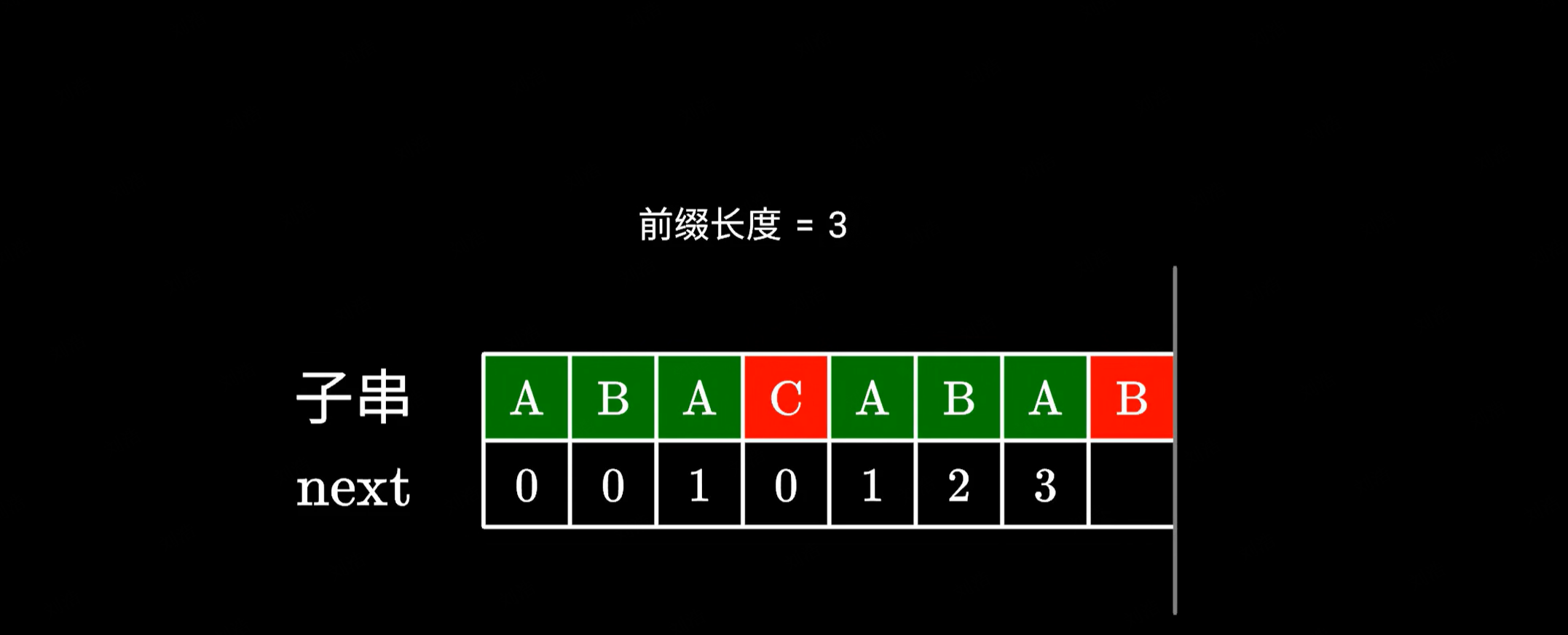 |
既然 ABA 无法与下一个字符构成更长的前后缀。我们就看看其中存不存在更短的,比如这里的 A,它其实是有可能与下一个字符构成共同前后缀的,这一步难道要暴力求解吗?其实不然。
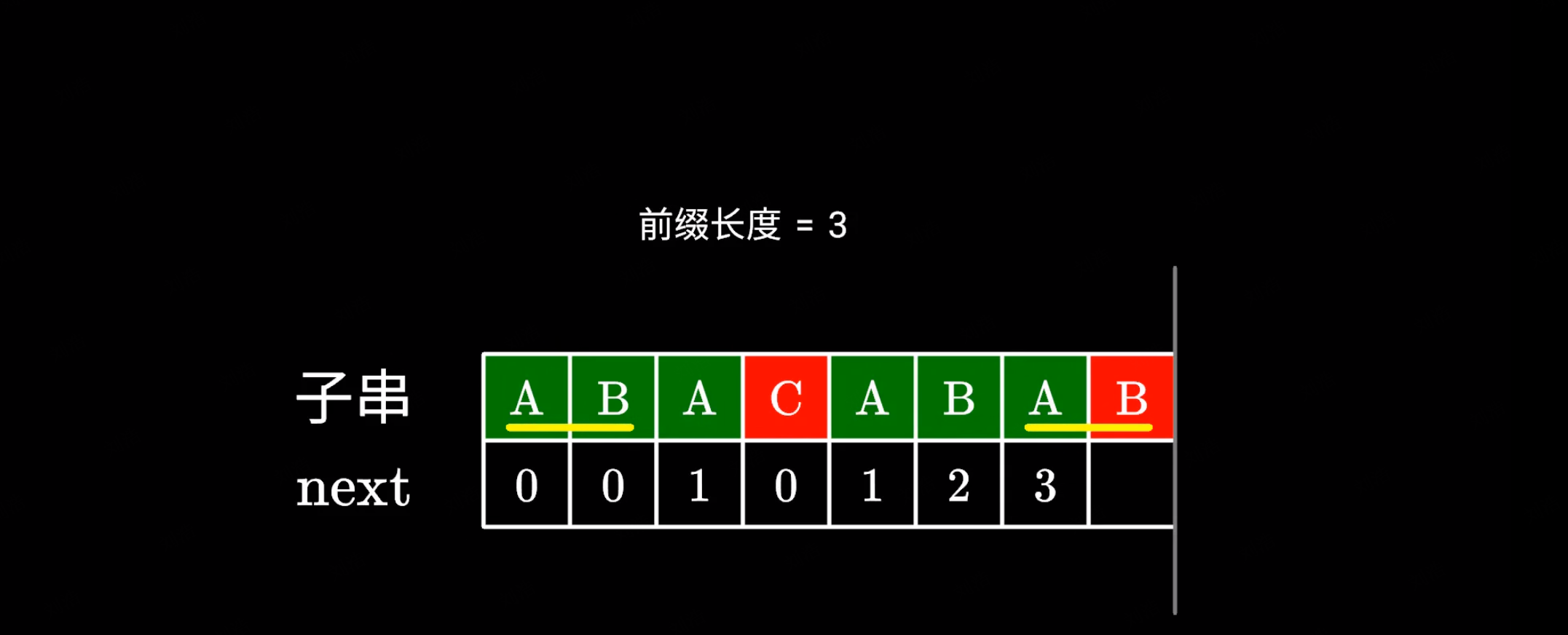 |
根据之前的计算,我们掌握了一个重要信息,那就是子串前后的这两部分是完全相同的:
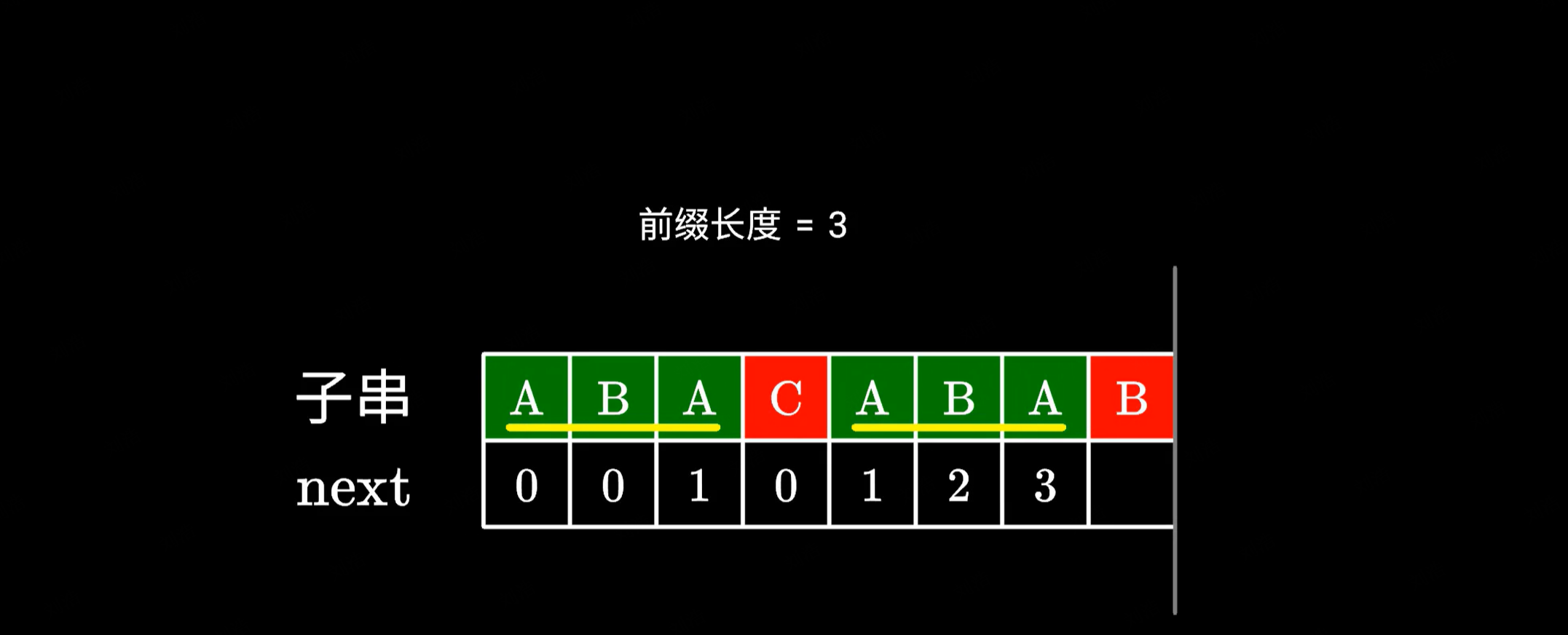 |
也就是说,右边这部分(ABA)的后缀其实等同于左边这部分的后缀(ABA),那我们直接在左边寻找共同的前后缀不就好了吗?
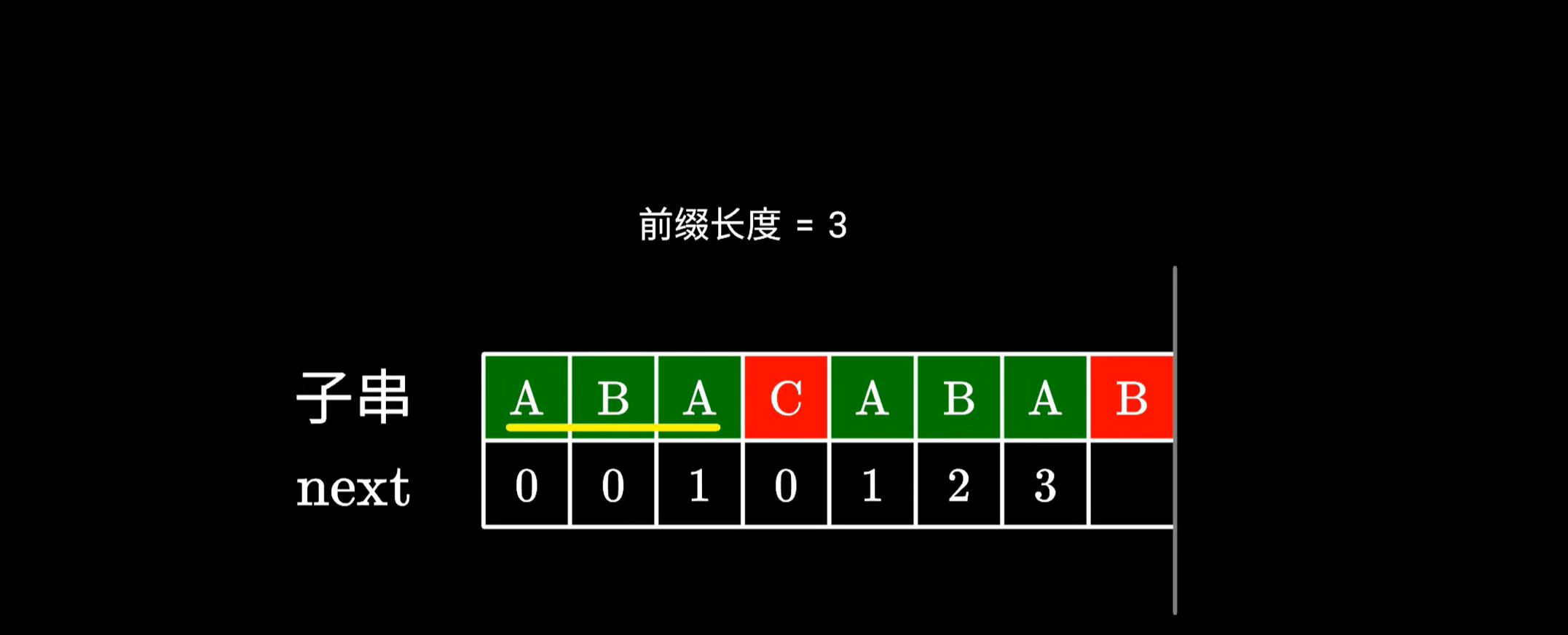 |
而左边的前后缀我们之前已经计算过了,直接查表就可以得到它的长度是 1:
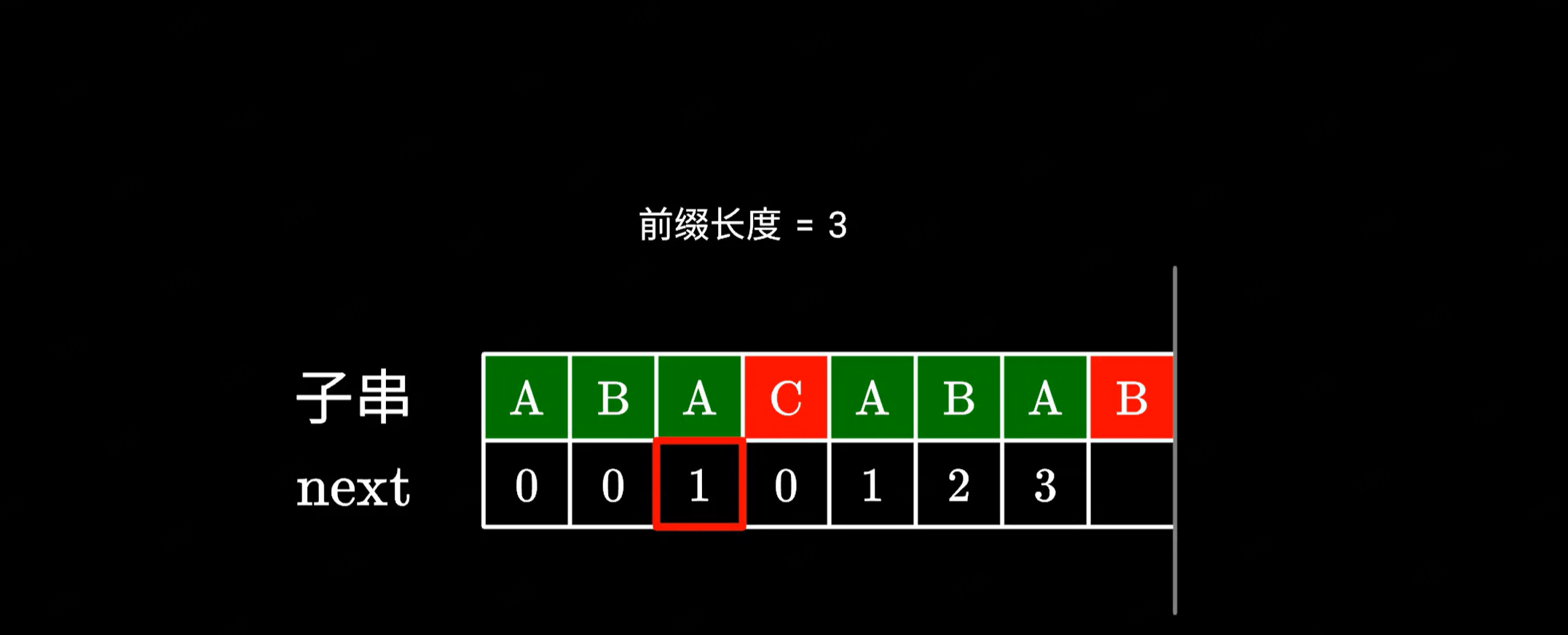 |
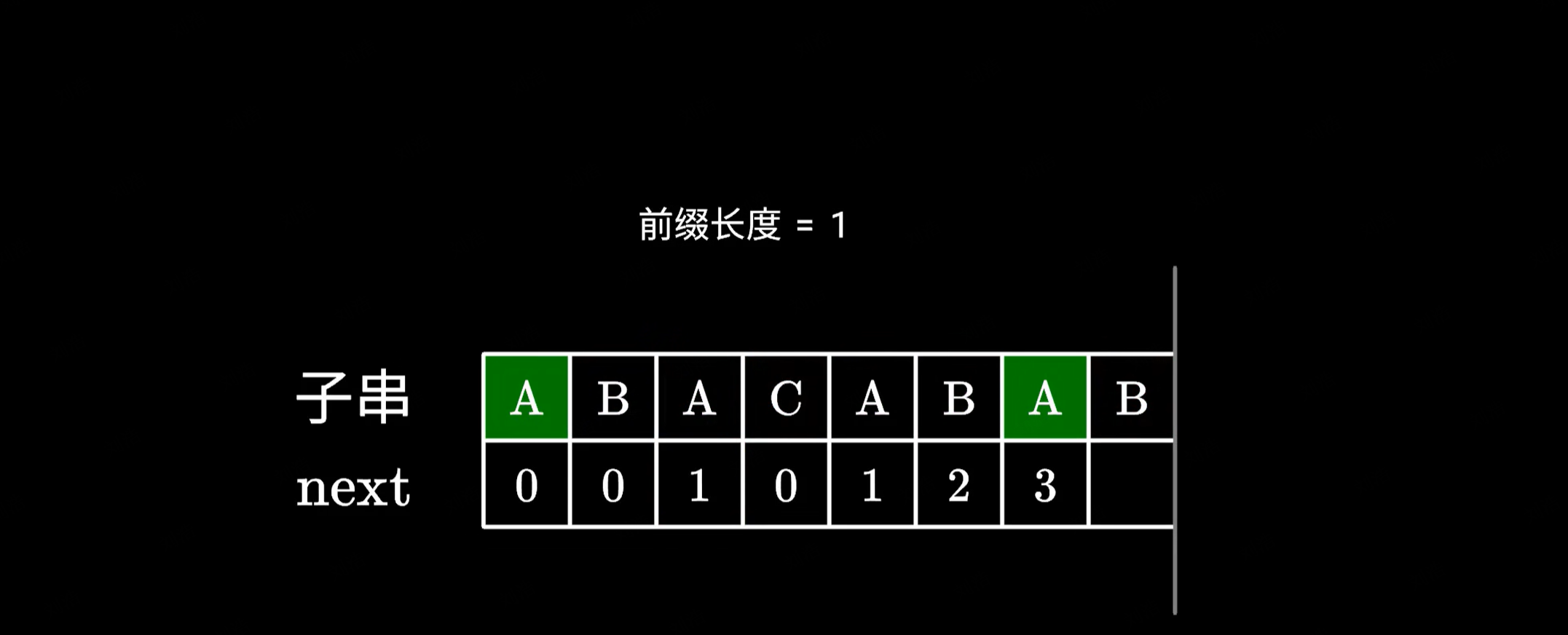 |
于是我们又回到最开始的步骤,检查下一个字符是否相同,如果相同则可以构成一个更长的前后缀,长度加 1 即可。
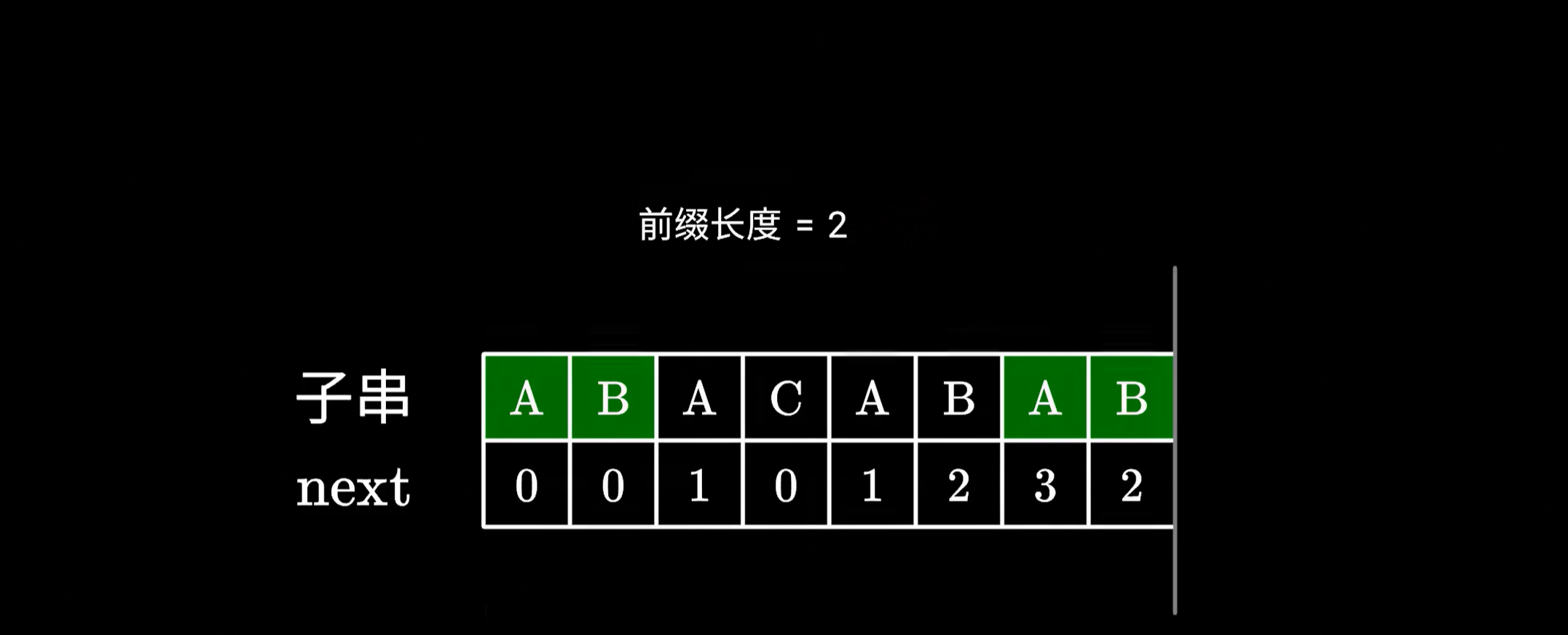 |
在掌握了算法的原理之后,代码的实现就很简单了。
"""
计算 next 数组
"""
def build_next(patt):
next = [0] # next 数组(初值元素一个 0)
prefix_len = 0 # 当前共同前后缀的长度
i = 1
while i < len(patt): # 遍历字符
if patt[prefix_len] == patt[i]:
# 下一个字符依然相同,长度加 1
prefix_len += 1
next.append(prefix_len)
i += 1
else:
# 下一个字符不同
if prefix_len == 0:
# 查表后发现不存在更短的前后缀
next.append(0)
i += 1
else:
# 查表看看其中存不存在更短的前后缀
prefix_len = next[prefix_len - 1]
return next
从索引 1 开始,我们遍历 patt 中的每个字符,依次生成每一个 next 数值。如果下一个字符依然相同的话,代表可以构成一个更长的前后缀,长度加 1 即可。如果下一个字符不同的话,我们直接查表看看其中存不存在更短的前后缀,如果依然不存在的话,那么将 next 设为 0 即可。
到这里,我们就讲完了 KMP 算法的全部内容。
不得不说 next 数组的计算确实比较绕,但它的本质不过是通过已经掌握的信息来规避重复的运算,这个和动态规划的思想是非常像的。
