Linux 常用命令
面向 CentOS7。
一、帮助信息
ls --help # 打印 ls 命令的帮助信息 man ls # 查看 ls 命令的说明文档 whatis ls # 查看 ls 命令的简要说明(将 man 手册 NAME 节区下的那句描述的话打印出来) info ls # 查看 ls 命令更加详细的说明文档
二、文件和目录
cd
切换目录。
cd / # 切换到顶层目录 cd ~ # 切换到当前用户的 home 目录(比如 root 用户的 home 目录为 /root) cd .. # 切换到当前目录的父目录 cd - # 进入上一次工作路径
pwd
Print working directory。显示用户当前所在的工作目录。
[root@localhost ~]# pwd /root
ls
显示目录文件(目录也视作文件)。
[root@localhost ~]# ls anaconda-ks.cfg
-a --all,列出目录所有文件,包含隐藏文件 -l 长格式显示文件信息,包括权限、所有者、文件大小和修改日期等 -h --human-readable,以易读大小显示,常与 l 选项一起出现 -t 以文件修改时间排序,最新文件在前 -S 以文件大小排序 -r --reverse,反序排列,通常与其他排序参数一起使用 -A --almost-all,列出除 . 及 .. 的其它文件 -R --recursive,递归列出全部内容 -1 每行显示一个文件,适合输出到管道或文件 --color 启用彩色输出,以便更好地区分文件类型
ll # ls -l 的简写形式 ls [dir] # 查看指定目录下的内容
touch
修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。
touch test.txt # 如果 test.txt 文件不存在,则创建一个名为 test.txt 的新的空白文件 echo 'text' > test.txt # 在 test.txt 文件中写入内容(覆盖原内容) echo 'text' >> test.txt # 在 test.txt 文件中追加内容
另:可用后文的 cat 新建文件。
mkdir
mkdir <dir> # 创建目录 mkdir -p <dir1>/<dir2>/<dir3> # 创建多级目录,-p 表示若路径中的某些目录尚不存在,系统将自动建立好那些尚不在的目录
rm
rm -i <file> # 删除文件,删除前询问确认 rm -f <file> # 不带提示地(强制)删除文件 rm -r <dir> # 递归地删除指定目录 rm -rf <dir> # 不带提示地(强制)递归删除指定目录
rmdir
删除空目录。
rmdir <dir> # 删除空目录 rmdir -p <dir> # 删除多级空目录,-p 表示当子目录被删除后使父目录为空目录的话,则一并删除 rmdir dir* # 删除以 dir 开头的空目录
mv
为文件或目录改名、或将文件或目录移动到其他位置。
mv -i <file1> <file2> # 将 file1 重命名为 file2,如果 file2 已经存在,则询问是否覆盖 mv <file> <dir> # 将 file 移动到 dir mv <dir1> <dir2> # 如果 dir2 不存在,就将 dir1 重命名为 dir2;如果 dir2 存在,就将 dir1 移动到 dir2 mv <file1> <dir>/<file2> # 将 file1 移动到 dir 并改名为 file2 mv * ../ # 将当前目录下的所有内容移动到父目录
cp
复制文件到指定目录。
-i 提示 -r 复制目录及目录内所有项目
cp <file> <dir> # 将文件复制到指定目录下 cp <file> ./test.txt # 将文件复制到当前目录下,并改名为 test.txt(创建指定名称的文件副本) cp -r <dir1> <dir2> # 将 dir1 和 dir1 下的所有内容复制到 dir2 cp -r <dir1>/* <dir2> # 将 dir1 下的所有内容复制到 dir2 cp -s a.txt link_a.txt # 为 a.txt 建立一个名为 link_a.txt 的快捷方式
cat
Concatenate。连接文件并打印到标准输出设备上。
-n 输出所有行号 -b 仅对非空行输出行号
cat <file> # 显示文件内容 cat -n file1 > file2 # 把 file1 的内容加上行号后输入到 file2 cat > filename # 从键盘创建一个文件,只能创建新文件,不能编辑已有文件 cat >> filename # 从键盘读取输入追加到一个文件 cat -b file1 file2 >> file3 # 把 file1 和 file2 的文档内容加上行号(空白行不加)之后将内容附加到 file3 文档里 cat file1 file2 > file # 将几个文件合并为一个文件
more
与 cat 类似,不过会以一页一页的形式显示,更方便使用者逐页阅读。
-c 从顶部清屏,然后显示 -n 定义屏幕大小为 n 行 +n 从笫 n 行开始显示 -p 通过清除窗口而不是滚屏来对文件进行换页,与 -c 选项相似 -s 把连续的多个空行显示为一行
more +3 text.txt # 显示文件中从第 3 行起的内容 ll | more -5 # 在所列出文件目录详细信息,借助管道使每次显示 5 行
常用操作命令:
h 显示帮助信息 <Enter> 向下滚动一行 <Space> 向下滚动一屏 b 返回上一屏 = 输出当前行的行号 q 退出 more
less
与 more 类似。可以按键盘上下方向键显示上下内容,退出后不会留下刚显示的内容。
h 显示帮助界面 -i 忽略搜索时的大小写 -N 显示每行的行号 -s 显示连续空行为一行 /<str> 向下搜索字符串 ?<str> 向上搜索字符串 n 重复前一个搜索(与 / 或 ? 有关) N 反向重复前一个搜索(与 / 或 ? 有关) b 向后翻一页 d 向后翻半页 q 退出 less 命令 u 向前滚动半页 y 向前滚动一行 <Space> 滚动一页 <Enter> 滚动一行 <PageDown> 向下翻动一页 <PageUp> 向上翻动一页
ps -aux | less -N # ps 查看进程信息并通过 less 分页显示
head
显示文件开头内容。
-n <行数> 显示的行数(行数为负数表示从最后向前数)
head 1.log -n 20 # 显示 1.log 文件中前 20 行 head -n -10 t.log # 显示 t.log 最后 10 行
tail
显示文件结尾内容。常用于查看日志文件。
-f 循环读取(常用于查看递增的日志文件) -n <行数> 显示行数(从后向前)
tail -f <file> # 动态查看文件末尾的内容(监测更新),通常用于查看日志文件的内容 tail -5 <file> # 查看文件末尾 5 行的内容 tail -5f <file> # 动态查看文件末尾 5 行的内容
tar
Tape archive。用来打包、解包、压缩、解压文件。tar 本身不具有压缩功能,只具有打包 / 解包功能,压缩及解压需要调用其它的程序来完成。
弄清两个概念:打包和压缩。打包是指将一大堆文件或目录变成一个总的文件;压缩则是将一个大的文件通过一些压缩算法变成一个小文件。包文件后缀为 .tar 表示只是完成了打包,并没有压缩;包文件后缀为 .tar.gz 表示打包的同时用 gzip 进行了压缩。
常用参数:
-z --gzip,支持 gzip 压缩 / 解压 -c --create,建立新的包文件 -x --extract,从包文件中抽取文件 -v --verbose,显示操作过程 -f 指定包文件名称 -t 显示包文件中的内容 -C <目的目录> 提取到指定目录
tar -cvf dir.tar <dir> # 将指定文件夹打包为名为 dir.tar 的包,同时打印打包过程 tar -zcvf dir.tar.gz <dir> # 将指定文件夹打包为名为 dir.tar.gz 的包,打包的同时进行压缩 tar -xvf dir.tar # 将指定打包文件解包到当前目录 tar -zxvf dir.tar.gz # 将指定压缩文件解压到当前目录 tar -zxvf dir.tar.gz -C <dir> # 将指定压缩文件解压到 dir 目录 tar -ztvf dir.tar.gz # 查看刚打包的文件内容(加 z 因为是使用 gzip 压缩的) tar --exclude /home/dmtsai -zcvf myfile.tar.gz /home/* /etc # 压缩打包 /home, /etc ,但不要 /home/dmtsai
zip/unzip
zip/unzip 是常用的压缩/解压缩命令,使用 zip/unzip 命令前需要安装对应工具:
yum install -y zip unzip
zip -r example.zip /path/to/directory # 压缩整个目录 zip example.zip example.txt # 压缩单个文件到指定压缩包(压缩包不存在则新建) zip example.zip file1.txt file2.txt file3.txt # 压缩多个文件到指定压缩包
unzip example.zip # 解压指定文件到当前路径 unzip -l example.zip # 查看 .zip 文件中的内容而不解压 unzip example.zip -d /path/to/directory # 将文件解压到指定的目录 unzip -o example.zip # 使用 -o 选项自动覆盖现有文件(默认情况下,如果解压缩的文件已经存在,unzip 会询问是否覆盖)
ln
Link files。为文件在另外一个位置建立一个同步的链接。
链接分类:软件链接及硬链接。
软链接:
- 软链接,以路径的形式存在。类似于 Windows 操作系统中的快捷方式;
- 软链接可以跨文件系统,硬链接不可以;
- 软链接可以对一个不存在的文件名进行链接;
- 软链接可以对目录进行链接。
硬链接:
- 硬链接,以文件副本的形式存在。但不占用实际空间;
- 不允许给目录创建硬链接;
- 硬链接只有在同一个文件系统中才能创建。
需要注意:
- 第一:ln 命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;
- 第二:软链接用
ln –s <源文件> <目标文件>创建,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接用ln <源文件> <目标文件>创建,没有参数 -s,它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
-b 删除,覆盖以前建立的链接 -s 软链接(符号链接) -v 显示详细处理过程
ln -v source.log link1.log # 给文件创建硬链接,并显示操作信息 ln -sv source.log link.log # 给文件创建软链接,并显示操作信息 ln -sv /opt/soft/test/test3 /opt/soft/test/test5 # 给目录创建软链接
wc
Word count。统计指定的文件中的字节数、字数、行数,并将统计结果输出。
-c 统计字节数 -l 统计行数 -m 统计字符数 -w 统计词数,一个字被定义为由空白、跳格或换行字符分隔的字符串
wc text.txt # 输出文件的行数、单词数、字节数、文件名 wc -l text.txt # 输出文件的行数、文件名 cat test.txt | wc -l # 统计输出结果的行数
三、查找
在 linux 要查找某个文件,但不知道放在哪里了,可以使用下面的一些命令来搜索:
which 查看可执行文件的位置 whereis 查看文件的位置 locate 配合数据库查看文件位置 find 搜寻硬盘查询文件名称
which
在 $PATH 中搜索某个系统命令的位置,返回第一个搜索结果。使用 which 命令,就可以看到某个系统命令是否存在,以及执行的到底是哪一个位置的命令。
echo $PATH # 查看当前 $PATH 变量 which ls # 查看 ls 命令是否存在,执行哪个
whereis
在预定目录下(whereis -l 查看)查找二进制文件(参数 -b)、man 说明文件(参数 -m)和源代码文件(参数 -s)。如果省略参数,则返回所有信息。whereis 及 locate 都是基于系统内建的数据库进行搜索,因此效率很高,而 find 则是遍历硬盘查找文件。
-b 定位可执行文件 -m 定位帮助文件 -s 定位源代码文件 -u 搜索默认路径下除可执行文件、源代码文件、帮助文件以外的其它文件
whereis ls # 查找 ls 程序相关文件
locate
通过搜寻系统内建文档数据库快速查找内容。数据库由 updatedb 程序来更新,文件若是最近才建立或刚更名的,locate 可能会找不到,可以执行 updatedb 命令来手动更新数据库。
locate 与 find 命令相似,可以使用如 *、? 等进行正则匹配查找。
-l <num> 只显示指定行数 -r 使用正则表达式
locate pwd # 查找和 pwd 相关的所有文件(文件名中包含 pwd) locate /etc/sh # 搜索 etc 目录下所有以 sh 开头的文件 locate -r '^/var/.*reason$' # 查找 /var 目录下,以 reason 结尾的文件(其中 .* 表示非空的任意多个字符)
find
-print 将匹配的文件列出到标准输出。 -exec 对匹配的文件逐个执行该参数所给出的 shell 命令。相应命令的形式为 'command' { } \;,注意 { } 和 \; 之间的空格。 -ok 和 -exec 的作用相同,只不过以一种更为安全的模式来执行该参数所给出的 shell 命令,在执行每一个命令之前,都会给出提示,让用户来确定是否执行。 -name 按照文件名查找文件 -perm 按文件权限查找文件 -user 按文件所有者查找文件 -group 按照文件所属的组来查找文件。 -type 查找某一类型的文件 d 目录 f 普通文件 -size +<n> 查找文件大于为 n 单位的文件,+ 替换为 - 表示文件小于 n 单位的文件 c 字节 b 块(512 字节) w 字(2 字节) k 千字节 M 兆字节 G 吉字节 -atime +n 查找系统中 n*24 小时前访问的文件 -ctime -n 查找系统中最近 n*24 小时被改变文件状态的文件 -mtime +n 查找系统中 n*24 小时前被改变文件数据的文件 (- 限定时间在距今 n 日以内,+ 限定时间在距今 n 日以前) -maxdepth n 最大查找目录深度 -mindepth n 最小查找目录深度 -depth 优先查找子目录 -path 配合 -prune 排除搜索目录 -prune 排除目录。如果同时使用了 -depth 选项,那么 -prune 选项会被忽略 -delete 将查找出的文件删除
find ./ -type d # 在当前目录查找所有目录,./ 代表当前目录(可省略,默认即当前目录) find ./ -type f # 在当前目录查找所有文件 find ./ -name '*.log' # 在当前目录查找以 .log 结尾的文件 find -atime -2 # 查找 48 小时内修改过的文件 find /opt -perm 777 # 查找 /opt 目录下权限为 777 的文件 find -size +1000c # 查找大于 1000 Byte 的文件 find -size 1000c # 查找等于 1000 Byte 的文件 find -size -1000c # 查找小于 1000 Byte 的文件 find test -path 'test/test4' -prune # 在 test 目录查找,不在 test4 子目录查找,-path 和 -prune 搭配用来排除搜索路径
-exec 参数后面跟的是 command 命令,它的终止是以 ; 为结束标志,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。{} 花括号代表前面 find 查找出来的文件名。
find . -type f -mtime +10 -exec rm -f {} \; # 在当前目录中查找更改时间在 10 日以前的文件并删除它们(无提醒) find . -name '*.log' -mtime +5 -ok -exec rm {} \; # 当前目录中查找所有文件名以 .log 结尾、更改时间在 5 日以上的文件,并删除它们,在删除之前先给出提示 find . -f -name 'passwd*' -exec grep "pkg" {} \; # 当前目录下查找文件名以 passwd 开头,内容包含 "pkg" 字符的文件 find . -name '*.log' -exec cp {} test3 \; # 用 exec 选项执行 cp 命令
可以把匹配到的文件用管道符传递给 xargs 命令。xargs 命令每次获取一批文件,这样它可以先处理最先获取的一部分文件,然后是下一批,并如此继续下去。
find . -type f | xargs file # 查找当前目录下每个普通文件,然后使用 xargs 执行 file 命令判断文件类型 find . -name "*.log" | xargs -i mv {} test4 # 利用 xargs 执行 mv 命令,-i 表示替换 {} 为各查找结果 find . -type f | xargs grep 'test' # 用 grep 命令在当前目录下的所有普通文件中搜索 test 这个词
grep
文本搜索。Global Regular Expression Print。
grep [option] pattern file|dir
-v 反转匹配,即只输出不匹配指定模式的行 -A n --after-context 显示匹配字符后 n 行 -B n --before-context 显示匹配字符前 n 行 -C n --context 显示匹配字符前后 n 行 -c --count 计算匹配列数 -i 忽略大小写 -l 列出文件内容符合指定模式的文件的文件名 -n 显示匹配内容所在行数 -R 递归查找文件夹 -E 使用扩展正则表达式
grep 的规则表达式:
^ # 锚定行的开始 如:'^grep'匹配所有以 grep 开头的行。 $ # 锚定行的结束 如:'grep$'匹配所有以 grep 结尾的行。 . # 匹配一个非换行符的字符 如:'gr.p'匹配 gr 后接一个任意字符,然后是 p。 * # 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟 grep 的行。 .* # 一起用代表任意字符。 [] # 匹配一个指定范围内的字符,如'[Gg]rep'匹配 Grep 和 grep。 [^] # 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含 A-R 和 T-Z 的一个字母开头,紧跟 rep 的行。 \(..\) # 标记匹配字符,如'\(love\)',love 被标记为 1。 \< # 锚定单词的开始,如:'\<grep'匹配包含以 grep 开头的单词的行。 \> # 锚定单词的结束,如'grep\>'匹配包含以 grep 结尾的单词的行。 x\{m\} # 重复字符 x,m 次,如:'0\{5\}'匹配包含 5 个 o 的行。 x\{m,\} # 重复字符 x,至少 m 次,如:'o\{5,\}'匹配至少有 5 个 o 的行。 x\{m,n\} # 重复字符 x,至少 m 次,不多于 n 次,如:'o\{5,10\}'匹配 5--10 个 o 的行。 \w # 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以 G 后跟零个或多个文字或数字字符,然后是 p。 \W # \w 的反置形式,匹配一个或多个非单词字符,如点号句号等。 \b # 单词锁定符,如:'\bgrep\b'只匹配 grep。
ps -ef | grep svn # 查找指定进程 ps -ef | grep svn -c # 查找指定进程个数 grep -lR '^grep' /tmp # 从文件夹中递归查找以 grep 开头的行,并只列出文件 grep '^[^x]' test.txt # 查找非 x 开关的行内容 grep -E 'ed|at' test.txt # 显示包含 ed 或者 at 字符的内容行
awk
awk是一个强大的文本处理工具。它的主要功能是对文本文件(尤其是结构化文本,如 CSV 或制表符分隔的文件)进行模式匹配和处理。
基本概念
- 文本处理:
awk可以逐行读取文本,分析每一行,并根据指定的条件执行操作。 - 字段分隔: 默认情况下,
awk使用空格或制表符作为字段分隔符,可以通过设置不同的分隔符来处理其他格式的文本。
基本语法
awk 'pattern { action }' file
- pattern: 匹配模式,决定哪些行将被处理。
- action: 对匹配的行执行的操作,可以是打印、计算等。
常见用法
-
打印特定字段:
awk '{print $1, $3}' file.txt 这将打印文件
file.txt中每行的第一个和第三个字段。 -
使用特定分隔符:
awk -F',' '{print $1}' file.csv 这里使用逗号作为字段分隔符,打印每行的第一个字段。
-
条件匹配:
awk '$2 > 100 {print $1}' file.txt 这将打印
file.txt中第二个字段大于 100 的行的第一个字段。 -
计算总和:
awk '{sum += $1} END {print sum}' file.txt 这将计算
file.txt中第一列的总和并打印。 -
格式化输出:
awk '{printf "Name: %s, Age: %d\n", $1, $2}' file.txt 使用
printf格式化输出每行的内容。
四、管理
uname
Unix name。显示系统信息。
-a --all,显示全部的信息 -m --machine,显示计算机类型 -n --nodename,显示在网络上的主机名称 -r --release,显示操作系统的发行编号 -s --sysname,显示操作系统名称 -v 显示操作系统的版本 --version 显示版本信息
uname -m # 查看计算机类型
ip
显示或设置网络设备。
ip addr # 或者 ip addr show,显示网卡 IP 信息 ip link # 或者 ip link show,显示网络接口信息 ip link set eth0 up # 开启 eth0 网卡 ip link set eth0 down # 关闭 eth0 网卡 ip addr add 192.168.0.1/24 dev eth0 # 设置 eth0 网卡 IP 地址 ip addr del 192.168.0.1/24 dev eth0 # 删除 eth0 网卡 IP 地址
systemctl
System control。管理系统服务。
systemctl status <服务> # 查看服务状态 systemctl stop <服务> # 暂时关闭服务 systemctl start <服务> # 开启服务 systemctl restart <服务> # 重启服务 systemctl enable <服务> # 设置开机启动 systemctl disable <服务> # 关闭并禁止开机启动 systemctl | grep running # 列出所有运行中服务 systemctl list-unit-files --state=enabled # 列出所有已启用服务,或者 systemctl list-unit-files | grep enabled
systemctl status sshd # 查看 sshd 状态
防火墙
systemctl status firewalld # 查看防火墙状态,或者 firewall-cmd --state systemctl stop firewalld # 暂时关闭防火墙 systemctl start firewalld # 开启防火墙 systemctl enable firewalld # 设置开机启动 systemctl disable firewalld # 关闭并禁止开机启动 firewall-cmd --reload # 重启防火墙 firewall-cmd --zone=public --list-ports # 查看指定区域所有打开的端口 firewall-cmd --zone=public --add-port=80/tcp --permanent # 在指定区域打开 80 端口(记得重启防火墙),--permanent 表示永久生效 firewall-cmd --zone=public --remove-port=80/tcp --permanent # 在指定区域关闭 80 端口(记得重启防火墙)
说明:
--zone 作用域 --add-port=8080/tcp 添加端口,格式为:端口 / 通讯协议 --permanent 永久生效,没有此参数重启后失效
为了保证系统安全,不建议关闭服务器的防火墙。
chmod
Change mode。改变 linux 系统文件或目录的访问权限。只有文件所有者和超级用户可以修改文件或目录的权限。
-c 当发生改变时,报告处理信息 -R 处理指定目录以及其子目录下所有文件
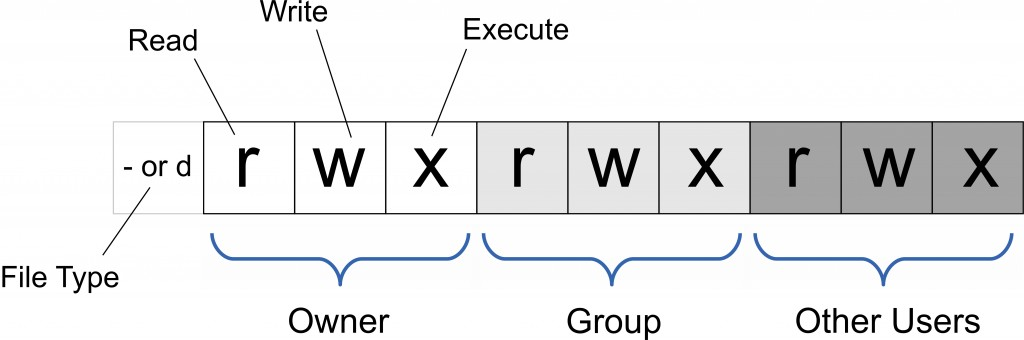
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件所有者(Owner)的读、写和执行权限;与所有者同组(Group)的用户的读、写和执行权限;系统中其他用户(Other Users)的读、写和执行权限。
以文件 log2012.log 为例:
[root@localhost test]# ls -l -rw-r--r-- 1 root root 296K 11-13 06:03 log2012.log
第一列共有 10 个位置,第一个字符指定了文件类型。第一个字符如果是横线,表示是一个文件,如果是 d,表示是一个目录。从第二个字符开始到第十个 9 个字符,3 个字符一组,分别表示了 3 组用户对文件或者目录的权限。权限字符用横线代表空许可,r 代表可读,w 代表可写,x 代表可执行。
 |
可以使用绝对模式(八进制数字模式)或符号模式指定文件的权限。
符号模式:
chmod [who][operator][permission] [file|dir]
可包含多个[who][operator][permission]项目,每个项目之间用逗号隔开。
who(用户类型):
u 目录或者文件的当前的用户 g 目录或者文件的当前的群组 o 除了目录或者文件的当前用户或群组之外的用户或者群组 a 所有的用户及群组
operator(操作符):
+ 为指定的用户类型增加权限 - 去除指定用户类型的权限 = 设置指定用户权限的设置,即将用户类型的所有权限重新设置
常用 permission(权限):
r 读权限,用数字 4 表示 w 写权限,用数字 2 表示 x 执行权限,用数字 1 表示 - 删除权限,用数字 0 表示
示例:
chmod a+x t.log # 增加文件 t.log 所有用户可执行权限 chmod u=r t.log -c # 撤销原来所有的权限,然后使拥有者具有可读权限,并输出处理信息 chmod u=rwx,g=rx,o=x t.log -c # 给 file 的所有者分配读、写、执行的权限,给 file 的所在组分配读、执行的权限,给其他用户分配执行的权限 chmod u+r,g+r,o+r -R text/ -c # 将 test 目录及其子目录所有文件添加可读权限
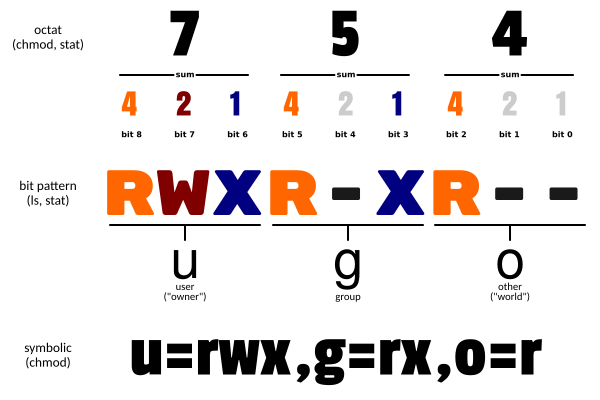
绝对模式:
chmod [sum1][sum2][sum3] [file|dir]
sum 为一个数字,是三个相邻符号的和,log2012.log 的权限为rw-r--r--,sum(rw-)=4+2+0=6,sum(r--)=4+0+0=4,所以rw-r--r--等价于644。
示例:
chmod 751 t.log -c # 与 chmod u=rwx,g=rx,o=x t.log -c 效果相同 sun(rwx)=7,sum(rx)=5,sum(x)=1。
 |
ps
Process status。用来查看当前运行的进程状态,一次性查看。需要动态连续结果时使用 top 命令。
linux 上进程有 5 种状态,ps 工具标识进程的 5 种状态码:
D 不可中断 R 运行 S 中断 T 停止 Z 僵死
-a 显示同一终端下所有进程,除了阶段作业领导者之外 a 显示当前终端机下的所有进程,包括其他用户的进程 -A 显示所有进程,不以终端机来区分 c 显示进程真实名称 e 显示环境变量 f 显示进程间的关系 -aux 显示所有进程,不以终端机来区分,比 -A 显示更多栏的信息
ps -ef # 显示所有进程环境变量及进程间关系 ps -A # 显示所有进程 ps -aux | grep apache # 与 grep 联用查找某进程 ps -aux | grep '(cron|syslog)' # 找出与 cron 与 syslog 这两个服务有关的 PID 号码
top
实时监控系统的性能,包括 CPU 使用率、内存使用情况以及正在运行的进程等。
top # 启动 top
-
第一行:显示系统当前时间、运行时间、用户登录数、平均负载等信息。
-
第二行:显示任务(进程)的数量,包括正在运行、睡眠、停止和僵尸状态的进程。
-
第三行:显示 CPU 的使用情况,包括用户空间、系统空间、空闲和等待等。
-
第四行:显示内存和交换区的使用情况。
常用快捷键
在 top 界面中,可以使用以下快捷键进行操作:
- h:显示帮助信息。
- q:退出 top。
- k:杀死一个进程。输入进程 ID 后,可以结束该进程。
- r:改变进程的优先级(nice 值)。
- M:按内存使用量排序。
- T:按时间/累计时间排序。
- 1:显示每个 CPU 的使用情况。
- c:切换显示进程命令行与程序名。
- s:设置刷新间隔(默认是 3 秒)。
过滤和搜索
- 按
Shift + F:进入字段选择界面,可以选择要显示的列。 - 按
Shift + O:按特定字段排序。 - 按
/:搜索特定进程。
kill
发送指定的信号到相应进程。不指定信号将发送 SIGTERM(15) 终止指定进程。如果仍无法终止该程序可用 "-KILL" 参数,其发送的信号为 SIGKILL(9) ,将强制结束进程,使用 ps 命令或者 jobs 命令可以查看进程号。root 用户将影响用户的进程,非 root 用户只能影响自己的进程。
-l 列出信号名称 -a 当处理当前进程时,不限制命令名和进程号的对应关系 -p 只打印相关进程的进程号(PID),而不发送任何信号 -u 指定用户
常用信号:
1 (HUP) 重新加载进程 9 (KILL) 杀死一个进程 15 (TERM) 正常停止一个进程
kill -l # 列出全部的信号名称 kill -l 9 # 列出指定信号名称 kill -9 $(ps -ef | grep pro1) # 先使用 ps 查找进程 pro1,然后用 kill 杀掉 kill -KILL $(ps -ef | grep pro1) # 与上面的命令等价 kill -u Bob # 杀死指定用户所有进程
free
显示系统内存使用情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。
-h 以易读格式显示信息 -b 以 Byte 为单位显示 -k 以 KB 为单位显示 -m 以 MB 为单位显示 -g 以 GB 为单位显示 -s <间隔秒数> 持续显示 -t 显示总合
free -ht # 以易读格式显示内存使用情况,且显示总和 free -s 10 # 周期性查询内存使用情况
df
Disk free。显示磁盘空间使用情况。
-a 全部文件系统列表 -h 以易读格式显示信息 -i 显示 Inode 信息 -l 只显示本地磁盘 -T 列出文件系统类型
df -lh # 以易读格式显示本地磁盘使用情况 df -haT # 以易读方式列出所有文件系统及其类型
du
Disk usage。显示每个文件和目录的磁盘使用空间。
-a 显示子目录中文件的大小 -k 以 KB 为单位显示 -m 以 MB 为单位显示 -g 以 GB 为单位显示 -h 以易读方式显示 -s --summarize,仅显示总计大小,而不是递归地列出每个文件的大小 -c --total,除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和
du -hc --max-depth=1 # 输出当前目录下各个子目录所使用的空间 du -h test/ # 以易读方式显示文件夹内及子文件夹大小 du -ha test/ # 以易读方式显示文件夹内所有文件大小 du -hc test1/ test2/ # 显示几个文件或目录各自占用磁盘空间的大小,并统计它们的总和 du -sh # 显示当前目录总计空间 du -sh * # 显示当前目录下各个子目录及文件所使用的空间
五、其他
history # 查看历史命令 clear # 清屏 reset # 重新初始化终端 wget <url> # 下载文件 curl <url> # 发起请求 nohup /root/test.sh > output.log 2>&1 & # 不挂起后台执行 /root/test.sh 命令,并重定向输出到 output.log 文件中 # 2>&1:将标准错误输出(stderr)重定向到标准输出(stdout),这样所有输出都会写入同一个文件 # &:将命令放入后台执行 jobs # 查看后台作业 netstat -ntlp # 查看占用的端口 cat /etc/redhat-release # 查看 CentOS 版本
参考:
Linux 常用命令学习 | 菜鸟教程
Linux 命令搜索引擎、Linux 课程
linux 命令 which,whereis,locate,find 的区别 - 知乎
which/whereis/whatis/locate/find 的区别 - 诸子流 - 博客园
Linux chmod 命令 | 菜鸟教程
Linux touch 命令 | 菜鸟教程
BV13a411q753
systemd - How to list all enabled services from systemctl? - Ask Ubuntu
Linux ip 命令 | 菜鸟教程
Linux uname 命令 | 菜鸟教程
Linux nohup 命令 | 菜鸟教程
find 命令,Linux find 命令详解:在指定目录下查找文件 - Linux 命令搜索引擎
linux 怎么查看 CentOS 版本
Linux cat 命令 | 菜鸟教程


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· 什么是nginx的强缓存和协商缓存
· 一文读懂知识蒸馏
· Manus爆火,是硬核还是营销?