背包、队列和栈的实现(基于数组)
前面总结了背包、队列和栈的概念,现在总结背包、队列和栈(基于数组)的实现。
注:代码/图片中的 StdIn 和 StdOut 是《算法(第四版)》中的工具库,在这里功能上分别等价于 Java 中的 System.in 和 System.out。
API 是开发的起点,所以先给出 API:
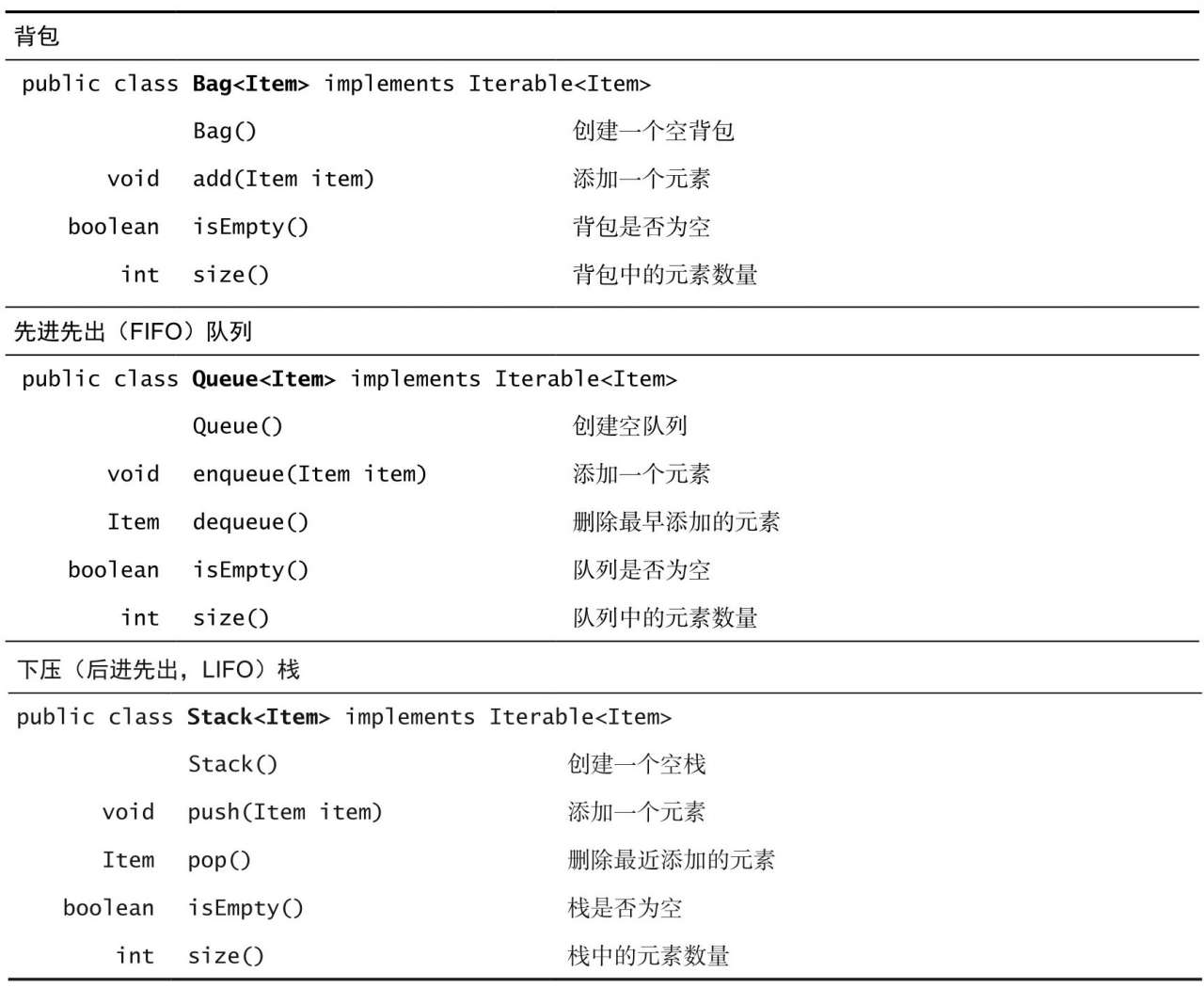 |
总思路是先给出一个简单而经典的实现,然后讨论它的改进并实现表 1 中的所有 API。
定容栈
从简单的开始,先实现一种表示容量固定的字符串栈的抽象数据类型,如表 2 所示。
它的 API 和 Stack 的 API 有所不同:它只能处理 String 值、要求用例指定一个容量且不支持迭代。
实现一份 API 的第一步就是选择数据的表示方式。对于 FixedCapacityStackOfStrings,显然可以选择 String 数组。由此可以得到表 2 中底部的实现。
 |
 |
这种实现的主要性能特点是 push 和 pop 操作所需的时间独立于栈的长度。许多应用会因为这种简洁性而选择它。但几个缺点限制了它作为通用工具的潜力,下面尝试改进它。
泛型定容栈
FixedCapacityStackOfStrings 的第一个缺点是它只能处理 String 对象。对此,可在代码中引入泛型。表 4 中的代码展示了实现的细节。
 |
调整数组大小
在 Java 中,数组一旦创建,其大小是无法改变的。这导致创建大容量的栈在栈为空或几乎为空时会浪费大量的内存,而小容量的栈则可能不满足保存大量数据的要求。
所以 FixedCapacityStack 最好能够支持动态调整数组大小,使它既足以保存所有元素,又不至于浪费过多的空间。
为此,可以给 FixedCapacityStack 添加一个 resize(int) 方法:
private void resize(int max) { // 将大小为 N <= max 的栈移动到一个新的大小为 max 的数组中 Item[] temp = (Item[]) new Object[max]; for (int i = 0; i < N; i++) temp[i] = a[i]; a = temp; }
然后在 push() 中,检查数组是否太小,太小时调用 resize(int) 增大数组长度:
public void push(Item item) { // 将元素压入栈顶 if (N == a.length) resize(2*a.length); a[N++] = item; }
类似地,在 pop() 中,首先删除栈顶的元素,之后如果数组太大就调用 resize(int) 将它的长度减半。
public Item pop() { // 从栈顶删除元素 Item item = a[--N]; a[N] = null; // 避免对象游离 if (N > 0 && N == a.length/4) resize(a.length/2); return item; }
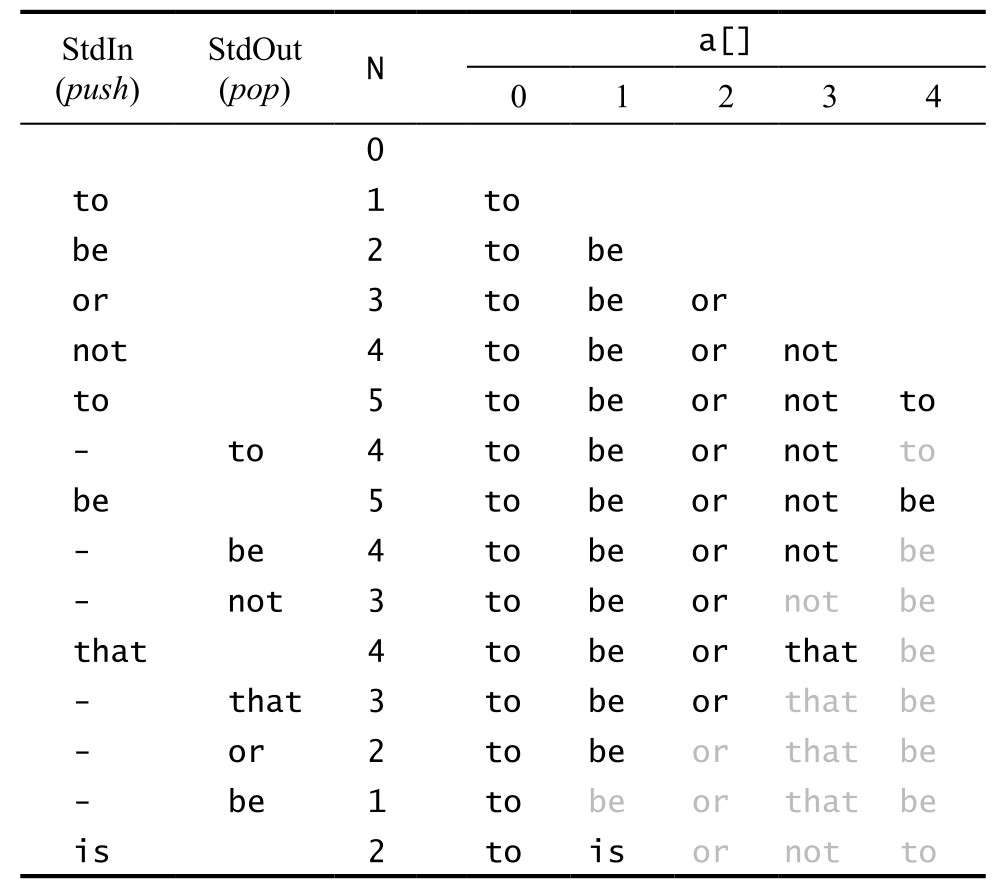
push() 和 pop() 操作中数组大小调整的轨迹见表 5。
 |
迭代
集合类数据类型的基本操作之一就是,能够使用 Java 的 foreach 语句通过迭代遍历并处理集合中的每个元素。有关在代码中加入迭代的方法见 Java 迭代。
栈的实现
有了前面的准备,就能够写出下压栈能动态调整数组大小的实现。
栈的实现(基于数组)
import java.util.Iterator; public class ResizingArrayStack<Item> implements Iterable<Item> { private Item[] a = (Item[]) new Object[1]; // 栈元素 private int N = 0; // 元素数量 public boolean isEmpty() { return N == 0; } public int size() { return N; } private void resize(int max) { // 将栈移动到一个大小为 max 的新数组 Item[] temp = (Item[]) new Object[max]; for (int i = 0; i < N; i++) temp[i] = a[i]; a = temp; } public void push(Item item) { // 将元素添加到栈顶 if (N == a.length) resize(2*a.length); a[N++] = item; } public Item pop() { // 从栈顶删除元素 Item item = a[--N]; a[N] = null; // 避免对象游离 if (N > 0 && N == a.length/4) resize(a.length/2); return item; } public Iterator<Item> iterator() { return new ReverseArrayIterator(); } private class ReverseArrayIterator implements Iterator<Item> { // 支持后进先出的迭代 private int i = N; public boolean hasNext() { return i > 0; } public Item next() { return a[--i]; } public void remove() { } } }
背包和队列的实现
受上述栈的实现过程的启发,可以类似写出背包和队列的实现。
对于背包,将栈实现中的 push(Item) 方法的方法名改为 add 并删除添加元素的方法即可。
背包的实现(基于数组)
import java.util.Iterator; public class ResizingArrayBag<Item> implements Iterable<Item> { private Item[] a = (Item[]) new Object[1]; // 背包元素 private int N = 0; // 元素数量 public boolean isEmpty() { return N == 0; } public int size() { return N; } private void resize(int max) { // 将栈移动到一个大小为 max 的新数组 Item[] temp = (Item[]) new Object[max]; for (int i = 0; i < N; i++) temp[i] = a[i]; a = temp; } public void add(Item item) { // 将元素添加到背包 if (N == a.length) resize(2*a.length); a[N++] = item; } public Iterator<Item> iterator() { return new ReverseArrayIterator(); } private class ReverseArrayIterator implements Iterator<Item> { // 支持后进先出的迭代 private int i = N; public boolean hasNext() { return i > 0; } public Item next() { return a[--i]; } public void remove() { } } }
对于队列,可以使用两个实例变量作为索引,一个变量 head 指向队列的开头,一个变量 tail 指向队列的结尾,如表 6 所示。在删除一个元素时,使用 head 访问它并将 head 加 1;在插入一个元素时,使用 tail 保存它并将 tail 加 1。如果某个索引在增加之后越过了数组的边界则将它重置为 0。
 |
队列的实现(基于数组)
import java.util.Iterator; public class ResizingArrayQueue<Item> implements Iterable<Item> { private static final int INIT_CAPACITY = 8; private Item[] a = (Item[]) new Object[INIT_CAPACITY]; // 队列元素 private int N = 0; // 元素数量 private int head = 0; // 指向队列的开头 private int tail = 0; // 指向队列的结尾 public boolean isEmpty() { return N == 0; } public int size() { return N; } private void resize(int max) { // 将队列移动到一个大小为 max 的新数组 Item[] temp = (Item[]) new Object[max]; for (int i = 0; i < N; i++) temp[i] = a[(head + i) % a.length]; a = temp; head = 0; tail = N; } public void enqueue(Item item) { // 将元素添加到队尾 if (N == a.length) resize(2*a.length); a[tail++] = item; if (tail == a.length) tail = 0; N++; } public Item dequeue() { // 从队头删除元素 Item item = a[head]; a[head++] = null; // 避免对象游离 if (head == a.length) head = 0; N--; if (N > 0 && N == a.length/4) resize(a.length/2); return item; } public Iterator<Item> iterator() { return new ResizingArrayQueueIterator(); } private class ResizingArrayQueueIterator implements Iterator<Item> { // 支持先进先出的迭代 private int i = 0; public boolean hasNext() { return i < N; } public Item next() { Item item = a[(i + head) % a.length]; i++; return item; } } }
队列的两个索引
注意到队列用了两个索引来处理数据,这和栈以及背包的实现明显不同。为什么要这样写?
受栈实现的启发,可能会写出如下队列的实现:
import java.util.Iterator; public class ResizingArrayQueue<Item> implements Iterable<Item> { private Item[] a = (Item[]) new Object[1]; // 队列元素 private int N = 0; // 元素数量 public boolean isEmpty() { return N == 0; } public int size() { return N; } private void resize(int max) { // 将队列移动到一个大小为 max 的新数组 Item[] temp = (Item[]) new Object[max]; for (int i = 0; i < N; i++) temp[i] = a[i]; a = temp; } public void enqueue(Item item) { // 将元素添加到队尾 if (N == a.length) resize(2*a.length); a[N++] = item; } public Item dequeue() { // 从队头删除元素 Item item = a[0]; // 将后面的元素整体前移 for (int i = 1; i < N; i++) a[i - 1] = a[i]; N--; if (N > 0 && N == a.length/4) resize(a.length/2); return item; } public Iterator<Item> iterator() { return new ResizingArrayQueueOfItemsIterator(); } private class ResizingArrayQueueOfItemsIterator implements Iterator<Item> { // 支持先进先出的迭代 private int i = 0; public boolean hasNext() { return i < N; } public Item next() { return a[i++]; } } }
该实现更加直观易懂,但注意到其中的 dequeue 操作会发生数组元素的整体前移,这是相当耗时的,使用两个索引来实现队列则可解决这个问题。
性能
上述基于数组的实现几乎(但还没有)达到了任意集合类数据类型的实现的最佳性能:
❏ 每项操作的用时都与集合大小无关;
❏ 空间需求总是不超过集合大小乘以一个常数。
基于数组的实现的缺点在于某些 push/enqueue/add 和 pop/dequeue 操作会调整数组的大小:这项操作的耗时和栈大小成正比。基于链表的实现则可以克服该缺陷。
总结自《算法(第四版)》1.3 背包、队列和栈


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构