
01_Java解析XML
【打印list、Map集合的工具方法】
/** * 打印List集合对应的元素 */ public void printList(List<Object> list){ for(Object o:list){ System.out.println(o.toString()); } } /** * 打印Map集合对应的key-value */ public void printMap(Map<String,String> map){ Iterator it=map.entrySet().iterator(); while(it.hasNext()){ Entry entry=(Entry) it.next(); String key=(String) entry.getKey(); String value=(String) entry.getValue(); System.out.println("[ key="+key+", value="+value+" ]"); } }
【cnBlogs.xml,保存在C:/cnBlogs.xml】
<?xml version="1.0" encoding="UTF-8"?> <spiderman name="开源中国GIT"> <property key="duration" value="30s" /><!-- 运行时间 0 表示永久,可以给 {n}s {n}m {n}h {n}d --> <property key="scheduler.period" value="24h" /><!-- 调度间隔时间 --> <property key="logger.level" value="WARN" /><!-- 日志级别 INFO DEBUG WARN ERROR OFF --> <property key="worker.download.enabled" value="1" /><!-- 是否开启下载工人 --> <property key="worker.extract.enabled" value="1" /><!-- 是否开启解析工人 --> <property key="worker.result.enabled" value="1" /><!-- 是否开启结果处理工人 --> <property key="worker.download.class" value="net.kernal.spiderman.worker.download.impl.WebDriverDownloader" /> <property key="worker.download.chrome.driver" value="dist/chromedriver.exe" /><!-- WebDriver下载器的Chrome驱动 --> <property key="worker.download.selector.delay" value="1s" /><!-- WebDriver下载器的延时时间 --> <property key="worker.download.size" value="1" /><!-- 下载线程数 --> <property key="worker.extract.size" value="2" /><!-- 页面抽取线程数 --> <property key="worker.result.size" value="2" /><!-- 结果处理线程数 --> <property key="worker.result.handler" value="net.kernal.spiderman.worker.result.handler.impl.FileJsonResultHandler" /> <property key="worker.result.store" value="store/result" /><!-- 采集结果放置目录 --> <property key="queue.store.path" value="store" /><!-- 检查器需要用到BDb存储 --> <!-- 种子 --> <seed url="http://www.cnblogs.com/HigginCui/p/5811631.html" /> <seed url="http://www.cnblogs.com/HigginCui/p/5811234.html" /> <seed url="http://www.cnblogs.com/HigginCui/p/5827356.html" /> <seed url="http://www.cnblogs.com/HigginCui/p/5811494.html" /> <!-- 页面抽取规则 --> <extract> <extractor name="HtmlCleaner" class="net.kernal.spiderman.worker.extract.extractor.impl.HtmlCleanerExtractor" isDefault="1" /> <extractor name="Text" class="net.kernal.spiderman.worker.extract.extractor.impl.TextExtractor" /> <page name="我的项目列表" extractor="HtmlCleaner"> <url-match-rule type="equals">http://www.cnblogs.com/HigginCui/p/5811631.html</url-match-rule> <model> <field name="项目URL" isForNewTask="1" isArray="1" xpath="//a[@class='project']" attr="href"> <filter type="script">'http://www.cnblogs.com/HigginCui/p/5811631.html'+$this</filter> </field> </model> </page> <page name="项目详情" extractor="Text"> <url-match-rule type="startsWith">http://www.cnblogs.com/HigginCui/p/5811494.html</url-match-rule> </page> </extract> </spiderman>

【test1.java】 使用extractModel(Object obj,String modelXpath)方法抽取对应xpath元素的方法
public class Demo01 {
/**
* xpath提供了对Xpath计算环境和表达式的访问
*/ private XPath xpath; /** * Document表示整个HTML或XML文档,它是文档的根,提供对文档数据的基本访问。 */ private Document doc; private Transformer transformer; @Test public void test1() throws ParserConfigurationException, SAXException, IOException { InputStream is=new FileInputStream("C:\\cnBlogs.xml"); DocumentBuilder db=DocumentBuilderFactory.newInstance().newDocumentBuilder(); //从DOM工厂获得DOM解析器 doc=db.parse(is); //解析的XML文档C:\\cnBlogs.xml的输入流,得到一个Document xpath=XPathFactory.newInstance().newXPath(); //抽取property中的key属性 System.out.println("=========抽取property中的key属性=========="); List<Object> propertyKeyList=extractModel(doc,"//property/@key"); printList(propertyKeyList); //抽取seed中的url属性 System.out.println("=========抽取seed中的url属性=========="); List<Object> seedUrlList=extractModel(doc,"//seed/@url"); printList(seedUrlList); //抽取extractor中的class属性 System.out.println("=========抽取extractor中的class属性=========="); List<Object> extractorClassList=extractModel(doc,"//extractor/@class"); printList(extractorClassList); //抽取url-match-rule的text()文本 System.out.println("=========抽取url-match-rule的text()文本=========="); List<Object> url_match_rulTextList=extractModel(doc,"//url-match-rule/text()"); printList(url_match_rulTextList); } /** * 抽取对应Xpath为"modelXpath"的元素的方法 */ public List<Object> extractModel(Object obj,String modelXpath){ NodeList nodeList = null; try { /** * Xpath.compile(String expression):编译一个xpath表达式expression提供以后计算,返回一个XPathExpression * XPathExpression.evalute(Object item,QName returnType):计算指定上下文的Xpath表达式,返回指定的类型的结果 */ nodeList = (NodeList)this.xpath.compile(modelXpath).evaluate(obj, XPathConstants.NODESET); } catch (XPathExpressionException e) { e.printStackTrace(); } //下面是将NodeList集合转换成我们普通的ArrayList集合 List<Object> mNodes = new ArrayList<Object>(); for (int i = 0; i < nodeList.getLength(); i++){ //getLength():获取NodeList中的结点数 Node node = nodeList.item(i); //返回NodeList集合中的第i个项 mNodes.add(node); } return mNodes; }
}
【运行结果】

【小结】
Document表示整个HTML或者Xml文档,它是文档的根,提供对文档数据的基本访问。
DocumentBuilder对象的parse(is)方法从InputStream输入流解析获得一个Document
Xpath提供了对Xpath计算环境和表达式的访问。
编译一个xpath表达式expression以提供后续计算,返回有个XpathExpression
计算指定上下文的Xpath的表达式,返回指定类型的结果returnType
Node是整个文档对象模型的主要数据类型。它表示该文档树中的单个节点。包括nodeName、nodeValue和Attributes作为一种获取节点信息的机制。
【对Node的解析】
@Test public void testNode() throws Exception{ InputStream is=new FileInputStream("C:\\cnBlogs.xml"); DocumentBuilder db=DocumentBuilderFactory.newInstance().newDocumentBuilder(); //从DOM工厂获得DOM解析器 doc=db.parse(is); //解析的XML文档C:\\cnBlogs.xml的输入流,得到一个Document xpath=XPathFactory.newInstance().newXPath(); List<Object> propertyNodeList=extractModel(doc,"//property"); //抽取对应的model for(Object o: propertyNodeList){ Node node=(Node) o; System.out.println("【 =======nodeType:"+node.getNodeType()+", nodeName:"+node.getNodeName()+" =======】"); NamedNodeMap attrs=node.getAttributes(); //获取所有的属性name-value(所以是Map类型的) for(int i=0;i<attrs.getLength();i++){ //遍历所有的map Node n=attrs.item(i); System.out.println("[ nodeType:"+n.getNodeType()+", nodeName:"+n.getNodeName()+", nodeValue:"+n.getNodeValue()+" ]"); //得到属性的name 和 属性的value } } }
【运行结果(部分)】
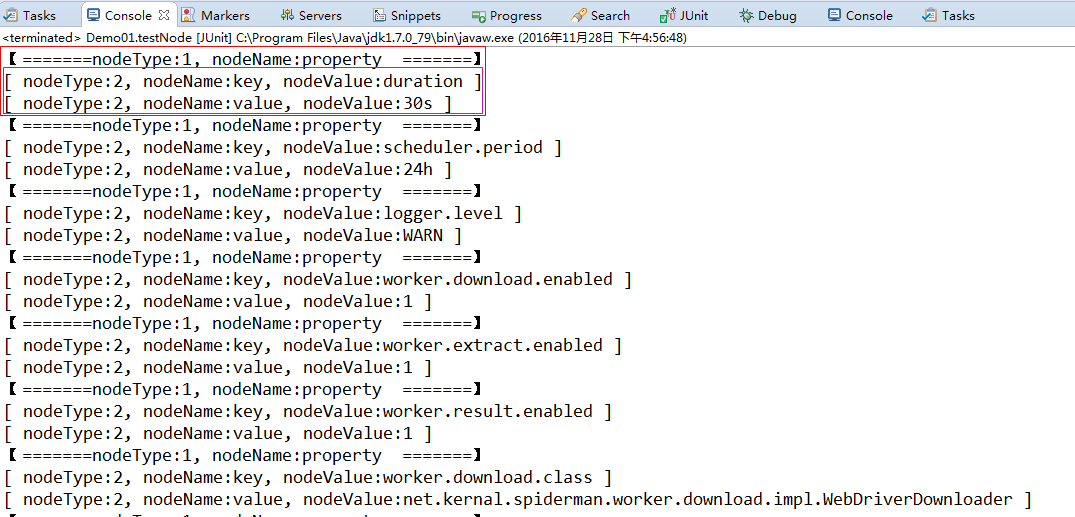
【解释】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号