数据结构:堆 heap
堆分为小顶堆和大顶堆,其本质是一颗 “近似的完全二叉树” ,不同点在于:
除叶子节点外,小顶堆的每个父节点的value都要比其左右两个子节点的value小;大顶堆的每个父节点的value都要比其左右两个子节点的value大。
其中,value是节点的取值,index为节点在树中的索引或者位置。例如:
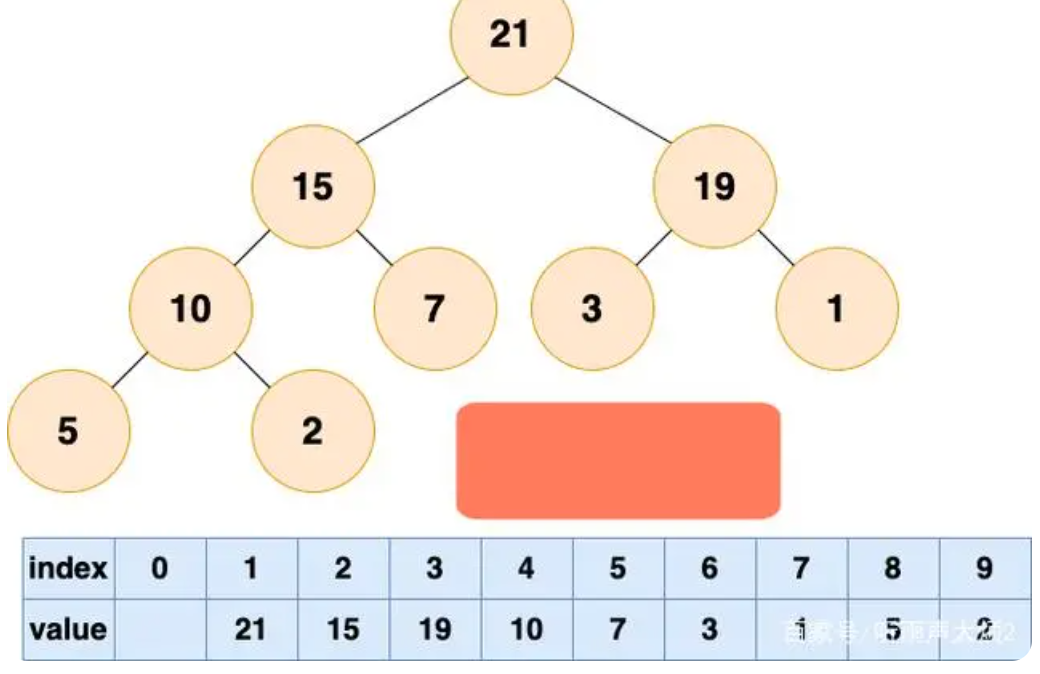
小顶堆/大顶堆最本质的特点在于,其根节点一定是整个数中最小或者最大的元素,这个也是其区别于其他数据结构最大的特点
以大顶堆为例,先来说说其最主要的两个操作add和pop是如何实现的:
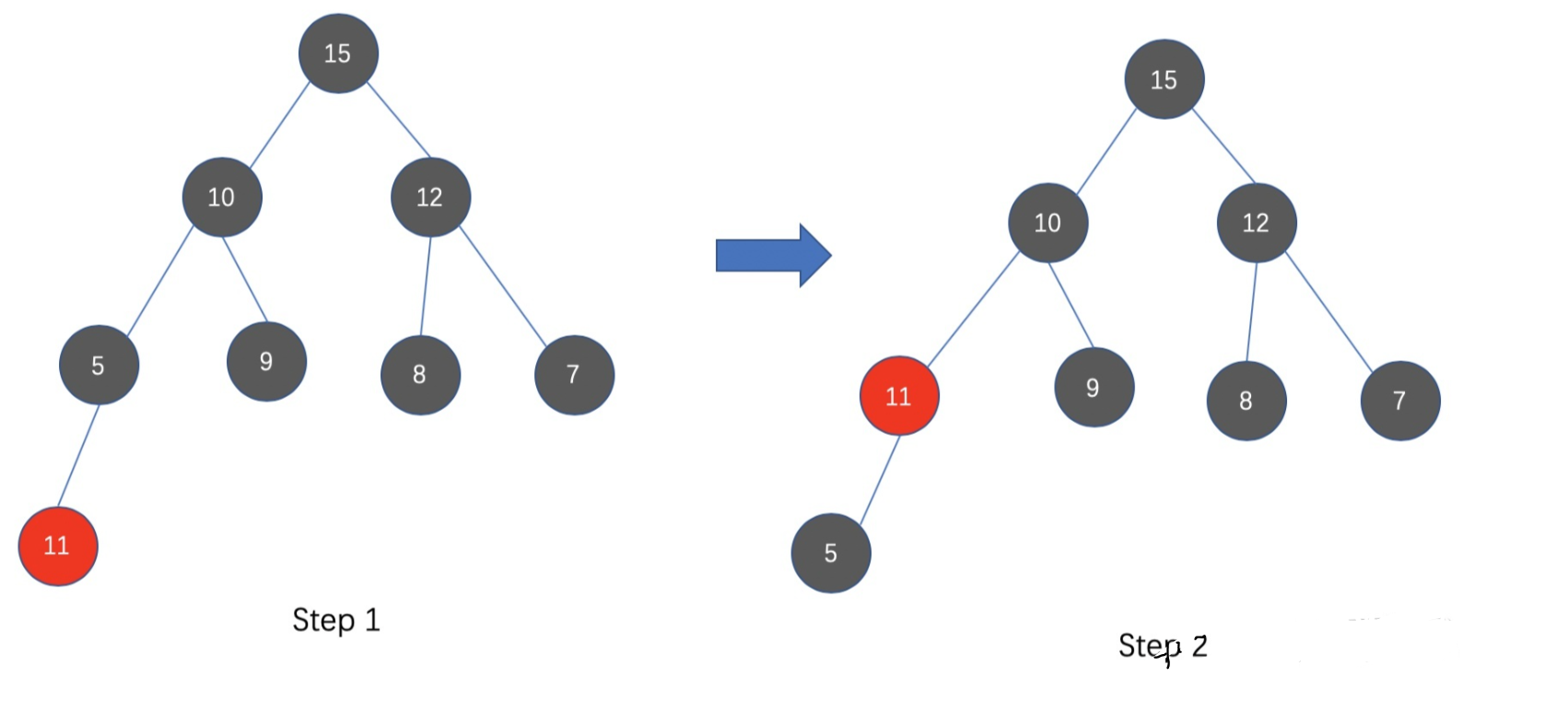
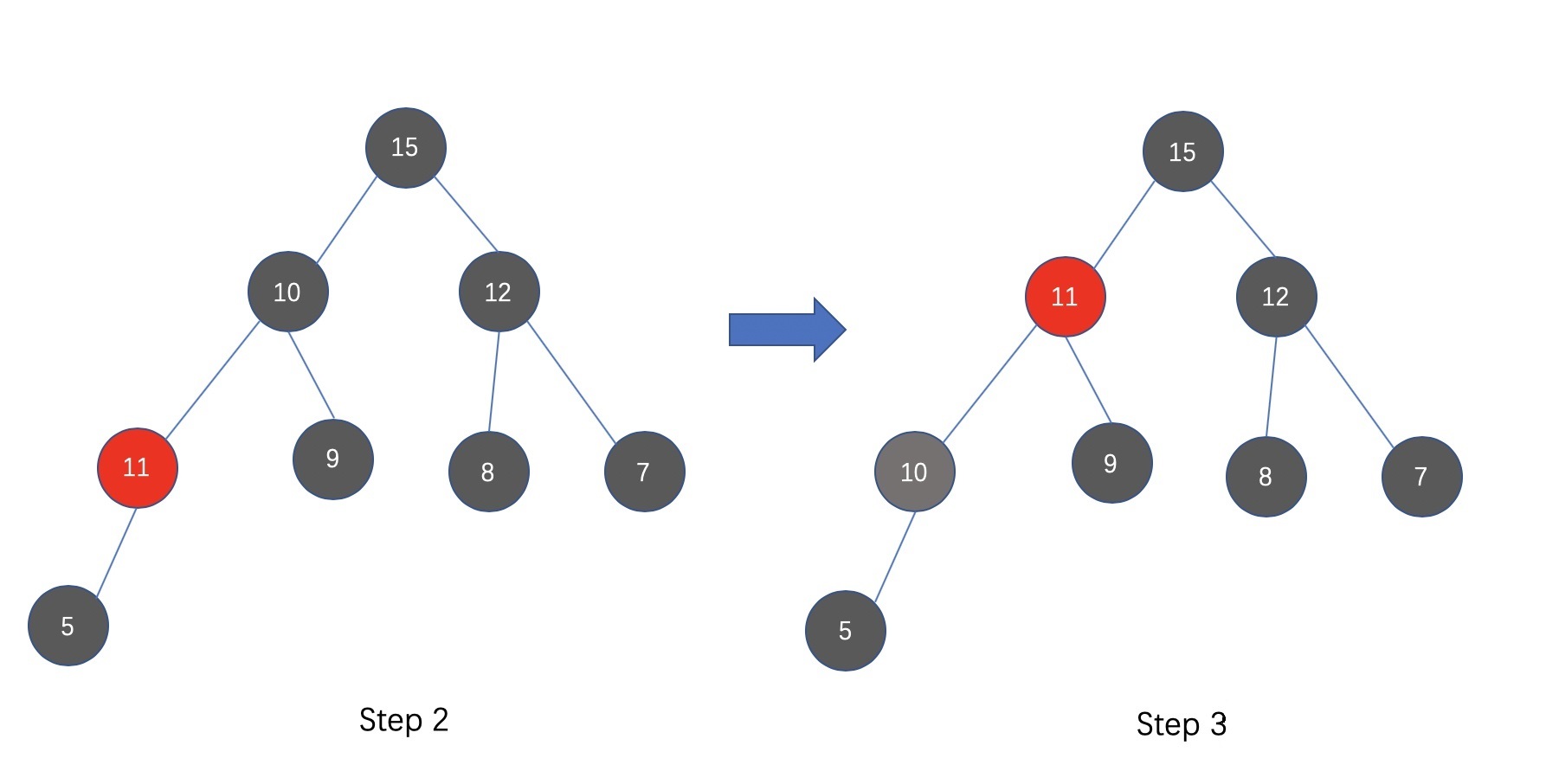
.add()
- 在往已有的大顶堆中添加元素时,将新元素作为树的最后的一个节点
- 比较新节点与其父节点:如果新节点的值大于父节点,那么交换父节点和新节点的位置(其实就是交换两个元素的值)
- 重复上述步骤,直到新节点比其父节点小,或者当前新节点的位置已经是根节点了,那么停止上述循环即可,此时大顶堆更新完毕。
.pop()
从大顶堆中弹出元素,是指弹出堆的根节点,也就是弹出堆中取值最大的元素。弹出根节点之后,需要对堆进行调整,以使得其结构还是一个大顶堆,这个过程被称之为"「堆化」";存在两种堆化方法,分别是自顶向下、自底向上方法。
首先介绍自底向上堆化方法:
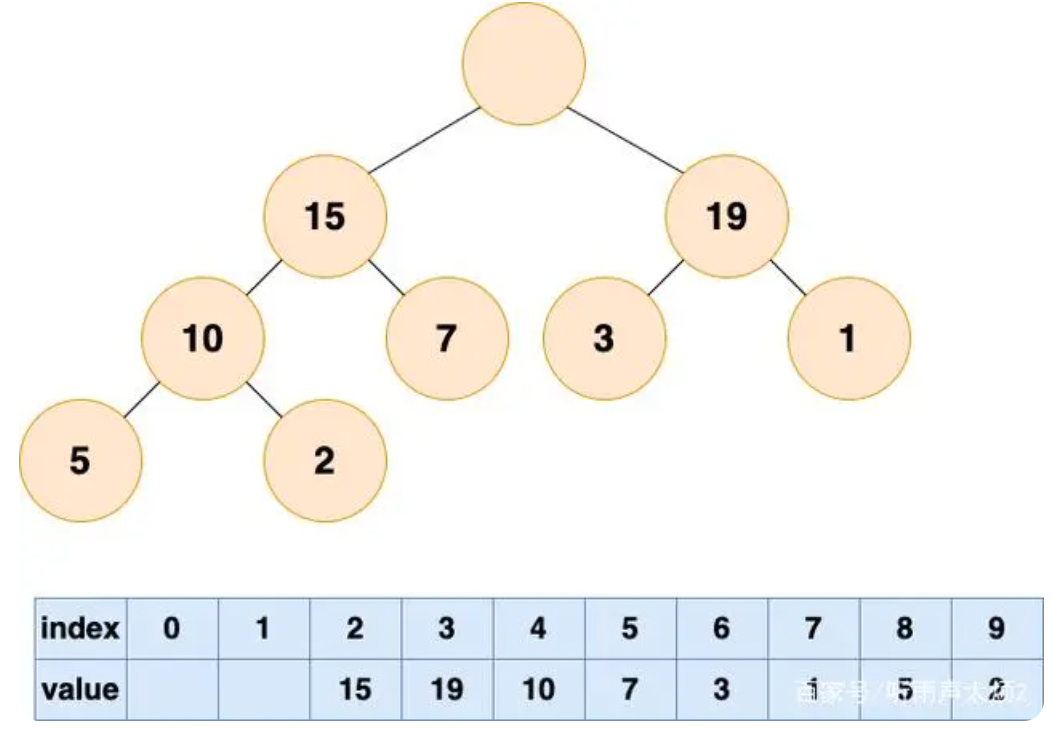
-
“在堆这个公司中,会出现老大离职的现象,老大离职之后,他的位置就空出来了”;首先删除堆顶元素,使得数组中下标为 1 的位置空出。
-
“那么他的位置由谁来接替呢,当然是他的直接下属了,谁能力强就让谁上呗”;比较根结点的左子节点和右子节点,也就是下标为 2,3 的数组元素,将较大的元素填充到根结点(下标为 1)的位置。
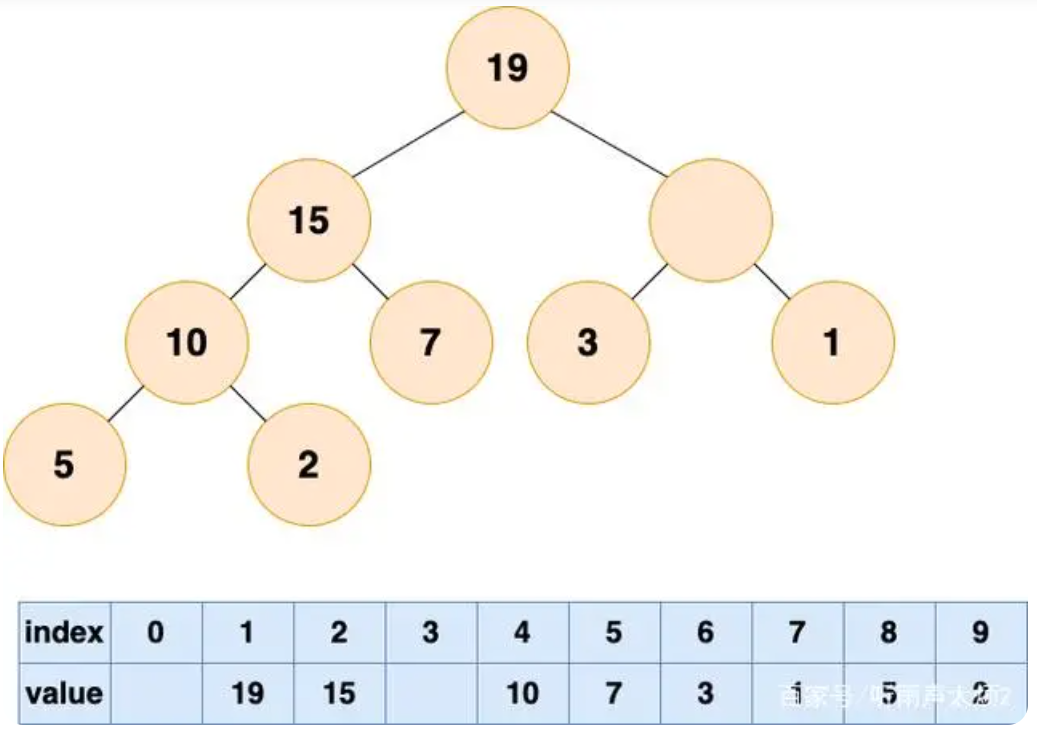
-
“这个时候又空出一个位置了,老规矩,谁有能力谁上”;一直循环比较空出位置的左右子节点,并将较大者移至空位,直到堆的最底部。
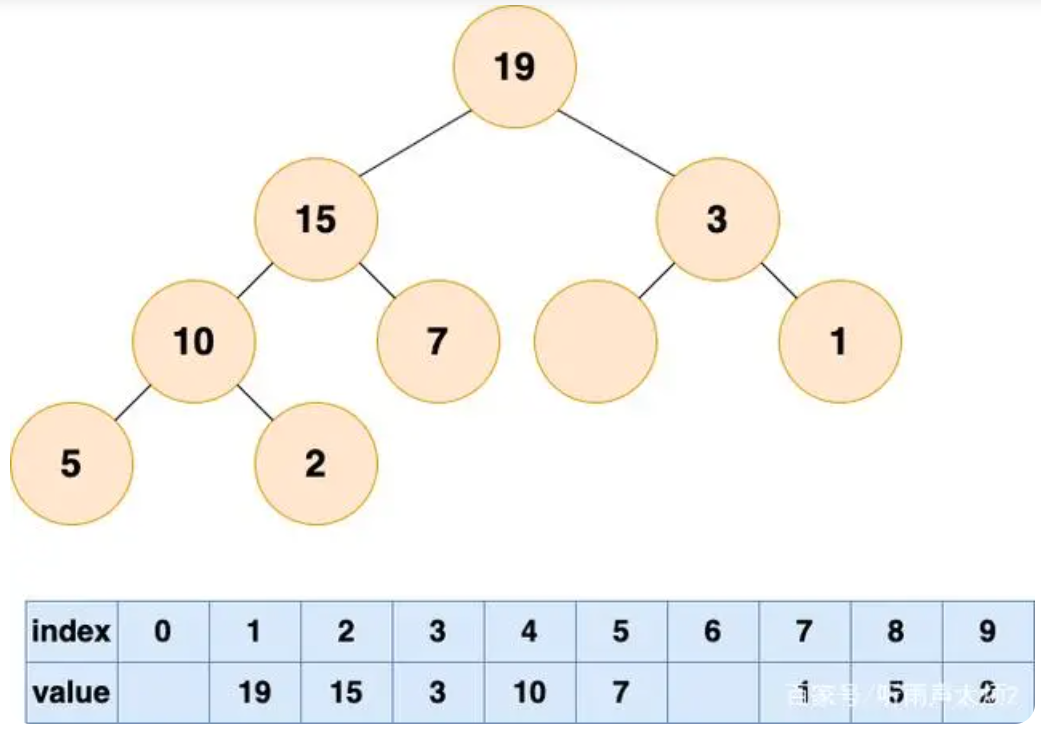
这个时候已经完成了自底向上的堆化,没有元素可以填补空缺了,但是,我们可以看到数组中出现了“气泡”(index=6位置),这会导致存储空间的浪费。
自顶向下堆化方法:
-
直接将堆的最后一个叶子节点移到根节点的位置。
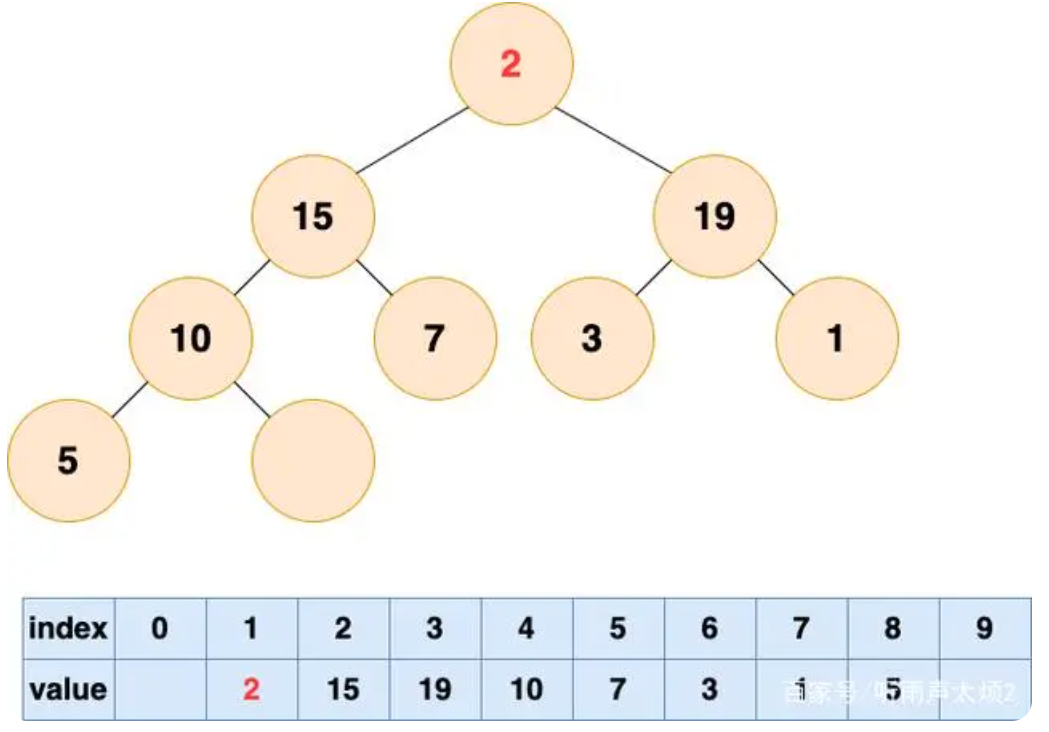
-
从根节点开始,比较根节点和其左右子节点的元素大小,若根节点不是都比子节点大,那么根节点与其较大的一个子节点进行交换。
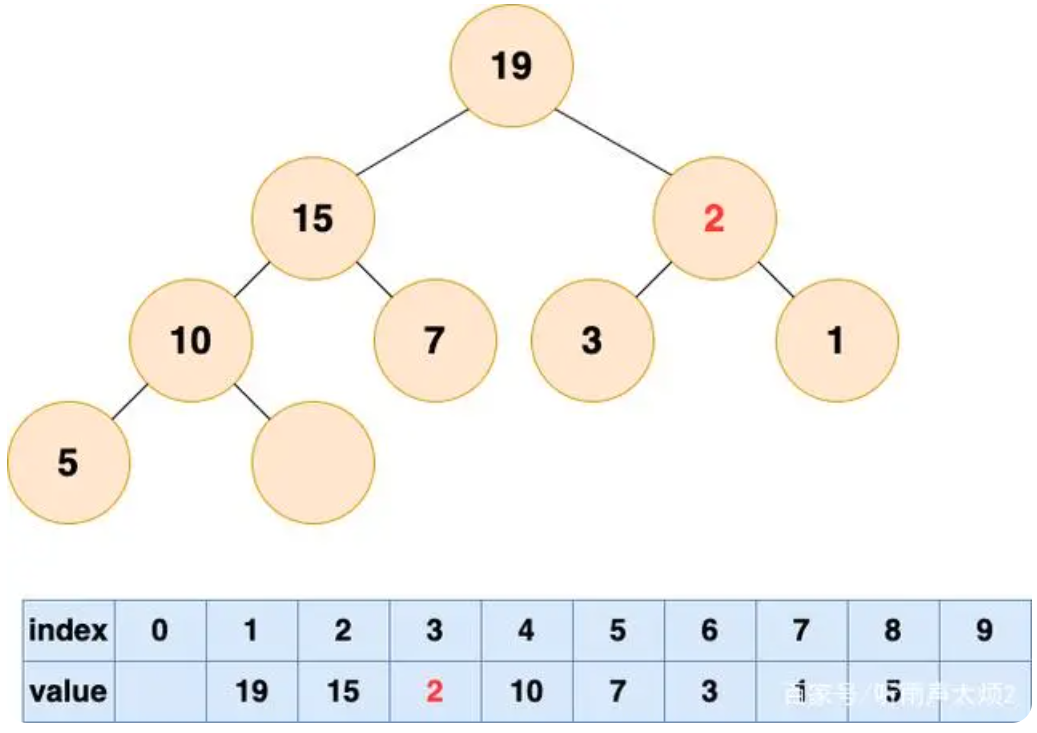
-
只要存在子节点,那么继续比较父节点和左右子节点的大小,直到当前节点已经是叶子节点或者它比它的左右子节点取值都大,那么停止循环,最大堆已经更新完毕。
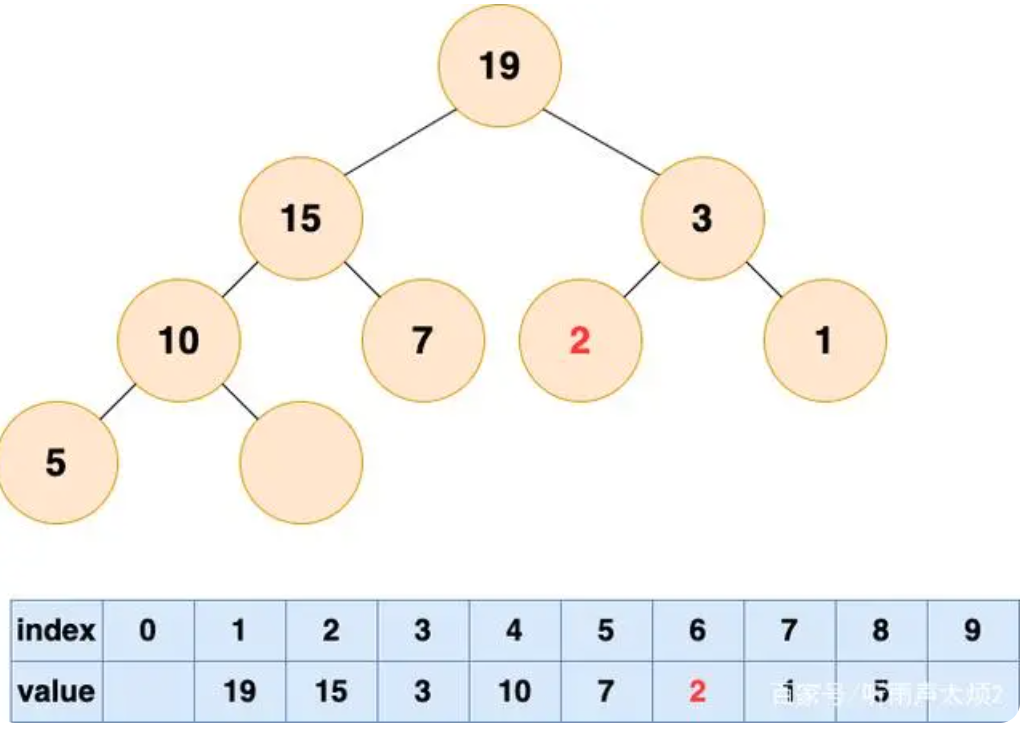
可见存储堆的数组气泡仅位于末尾,可以节省存储,实现堆在内存中的利用更加紧凑。
小顶堆的刚好相反,每一个子树的父节点key值总是小于其两个子节点的key值,因此pop和push方法与大顶堆的原理也十分相似。
堆的用途
当我们只关心所有数据中的最大值或者最小值,或者存在多次获取最大值或者最小值、多次插入或删除数据时,就可以使用堆结构。相对于有序数组而言,堆的主要优势在于更新数据效率较高(pop、push操作),而不在于寻找数据。
参考:
https://zhuanlan.zhihu.com/p/77583063?utm_id=0
https://baijiahao.baidu.com/s?id=1701196303627569777&wfr=spider&for=pc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号