实验内容
实验任务1
略
实验任务2
略
实验任务3
1 def task3(): 2 with open("/Users/chenxi/Documents/文稿 - 陈曦的MacBook Air - 1/python data/实验5数据文件/data3.txt" 3 ,"r",encoding="utf-8") as f: 4 title=f.readline() 5 title=title.strip() 6 datas=f.readlines() 7 for i in range(len(datas)): 8 datas[i]=eval(datas[i].strip()) 9 10 with open("/Users/chenxi/Documents/文稿 - 陈曦的MacBook Air - 1/python data/实验5数据文件/data3_processed.txt" 11 ,"w+",encoding="utf-8") as f: 12 #print(f"{title}\t\t四舍五入后数据") 13 print("原始数据:\n",datas)# 14 datas_2=[]# 15 f.write(f"{title}\t\t四舍五入后数据\n") 16 for i in datas: 17 if i%1>=0.5: 18 #print(f"{i}\t\t{int(i+1)}") 19 datas_2.append(int(i+1))# 20 f.write("{0}\t\t{1}\n".format(i,int(i+1))) 21 else: 22 #print(f"{i}\t\t{int(i)}") 23 datas_2.append(int(i))# 24 f.write("{0}\t\t{1}\n".format(i,int(i))) 25 print("四舍五入后数据:\n",datas_2)#
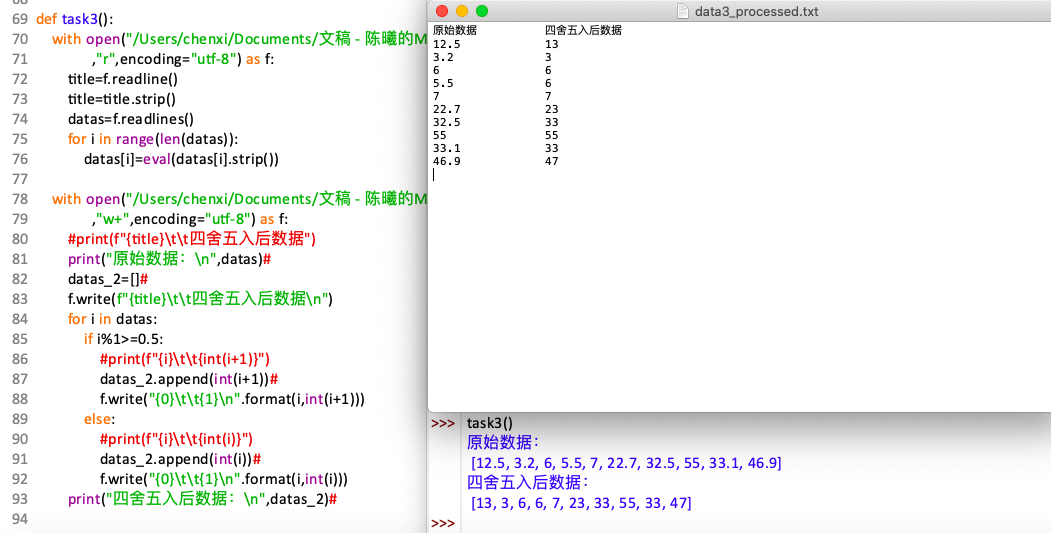
*将后面带#的行用注释行替换即可以文件内样式输出。
实验任务4
1 def task4(): 2 with open("/Users/chenxi/Documents/文稿 - 陈曦的MacBook Air - 1/python data/实验5数据文件/data4.txt" 3 ,"r",encoding="utf-8") as f: 4 titles=f.readline() 5 titles=titles.split() 6 datas_s=f.read().split() 7 dataarray=[[],[],[],[]] 8 for i in range(len(datas_s)): 9 if i%4==0: 10 dataarray[0].append(datas_s[i]) 11 elif i%4==1: 12 dataarray[1].append(datas_s[i]) 13 elif i%4==2: 14 dataarray[2].append(datas_s[i]) 15 elif i%4==3: 16 dataarray[3].append(datas_s[i]) 17 datas=[] 18 for i in range(len(dataarray[0])): 19 data=[] 20 for j in range(4): 21 data.append(dataarray[j][i]) 22 datas.append(data) 23 with open("/Users/chenxi/Documents/文稿 - 陈曦的MacBook Air - 1/python data/实验5数据文件/data4_processed.txt" 24 ,"w+",encoding="utf-8") as f: 25 for i in range(len(datas)): 26 for j in range(i+1,len(datas)): 27 if datas[i][2]>datas[j][2]: 28 datas[i],datas[j]=datas[j],datas[i] 29 for i in range(len(datas)): 30 if datas[i][2]!=datas[i+1][2]: 31 n=i+1;break 32 for i in range(n): 33 for j in range(i,n): 34 if datas[i][3]<datas[j][3]: 35 datas[i],datas[j]=datas[j],datas[i] 36 for i in range(n,len(datas)): 37 for j in range(i,len(datas)): 38 if datas[i][3]<datas[j][3]: 39 datas[i],datas[j]=datas[j],datas[i] 40 41 print("\t".join(titles)) 42 f.write("\t".join(titles)+"\n") 43 for i in range(len(datas)): 44 print("\t".join(datas[i])) 45 f.write("\t".join(datas[i])+"\n")
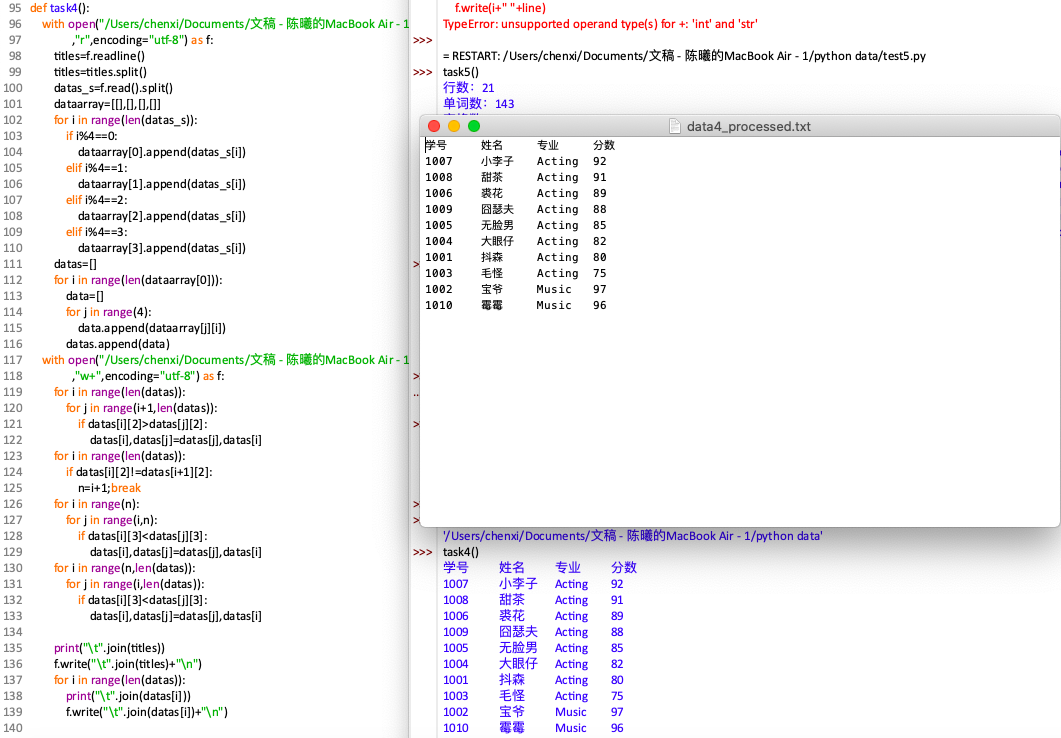
*使用numpy库可大幅缩减代码行数。但容易出错。
实验任务5
1 def task5(): 2 with open("/Users/chenxi/Documents/文稿 - 陈曦的MacBook Air - 1/python data/实验5数据文件/data5.txt" 3 ,"r",encoding="utf-8") as f: 4 text=f.read() 5 chars=0;spaces=0;lines=1;words=0 6 for i in range(len(text)-1): 7 chars+=1 8 if text[i]=="\n": 9 lines+=1 10 elif text[i]==" ": 11 spaces+=1 12 elif text[i].isalpha() and not(text[i+1].isalpha()) and not(text[i+1]=="'"): 13 words+=1 14 chars+=1 15 print(f"行数:{lines}\n单词数:{words}\n空格数:{spaces}\n字符数:{chars}") 16 17 f.seek(0) 18 lines=f.readlines() 19 20 with open("/Users/chenxi/Documents/文稿 - 陈曦的MacBook Air - 1/python data/实验5数据文件/data5_with_line.txt" 21 ,"w+",encoding="utf-8") as f: 22 i=1 23 for line in lines: 24 f.write("{0} {1}".format(i,line)) 25 i+=1
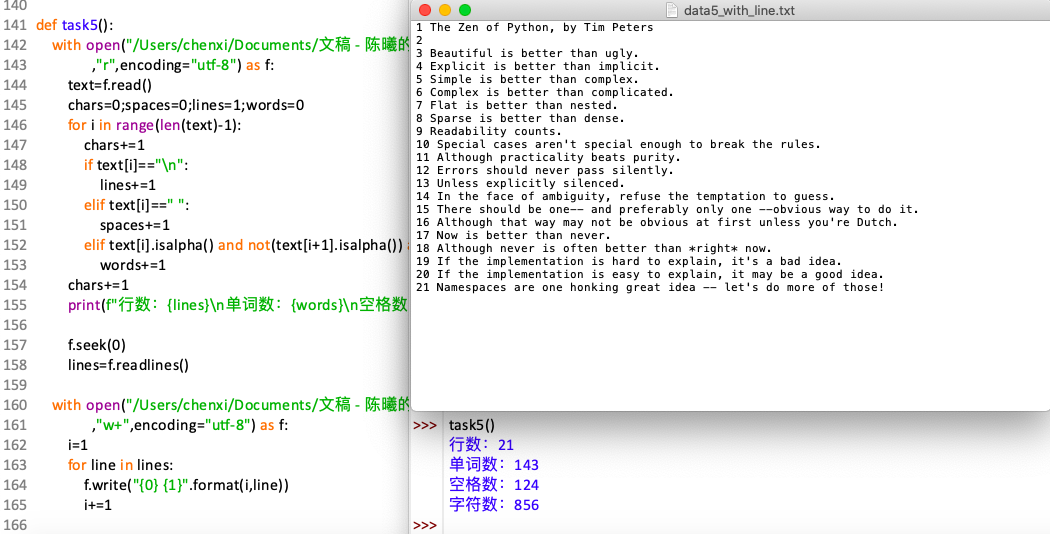
*用计算器数过,单词数143无误。答案可能有误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号