并行与分布式计算复习要点
概念
计算机架构
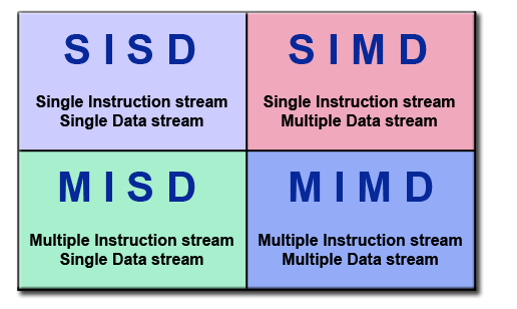
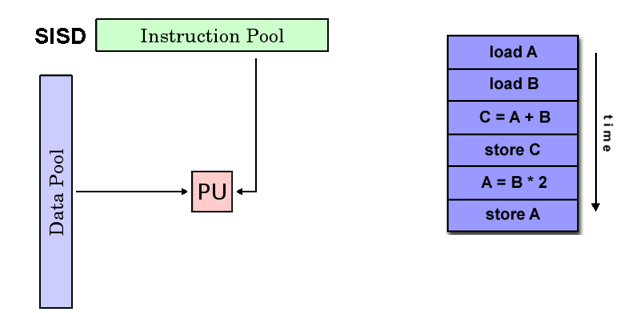
SISD
- Single instruction stream Single Data stream
- 单指令单数据,串行计算机
- 在任何一个时钟周期,CPU都只有一个指令流;在任何一个时钟周期,都只有一个数据流作输入
- 确定性执行
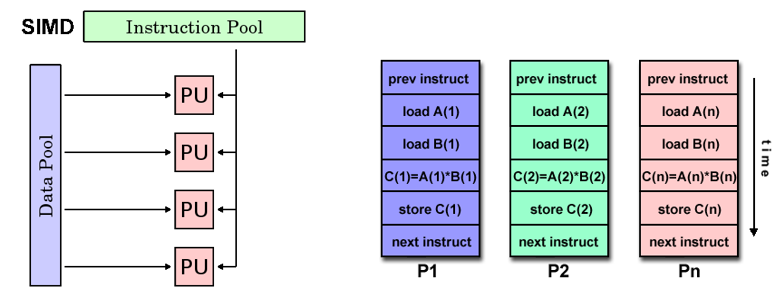
SIMD
- Single instruction stream Multiple Data stream
- 单指令多数据,并行计算机
- 每个处理单元在任何一个时钟周期都执行相同的指令;每个处理单元可以在不同的数据元件上操作
- 适用于处理具有高度规律性的问题
- 同步和确定性
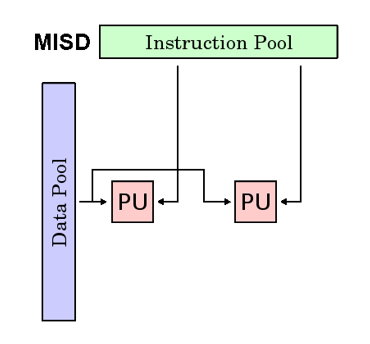
MISD
- Multiple instruction stream Single Data stream
- 多指令单数据,并行计算机,很少有实际例子
- 每个处理单元通过单独的指令流处理数据,单个数据流输入多个处理单元
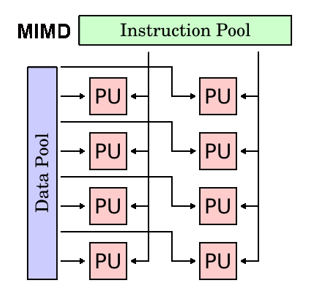
MIMD
- Multiple Instruction stream Multiply Data stream
- 多指令多数据,最常见的并行计算机
- 每个处理单元执行不同的指令流,使用不同的数据流
- 同步或异步,确定性或非确定性
共享内存
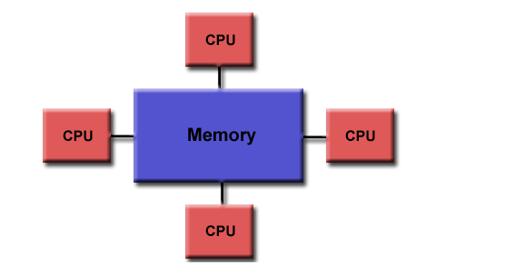
并行计算机的一种存储结构,有全局地址空间
- 特性
所有处理器将所有内存作为全局地址空间访问
多个处理器独立运行,但共享内存资源
所有处理器可以看到由一个处理器引起的内存位置变化 - 优点
全局地址空间便于编程
内存接近CPU,任务之间的数据共享,既快速又均匀 - 缺点
内存和CPU之间缺乏可扩展性
成本高、代价大
根据内存访问时间被归为UMA、NUMA
UMA 统一内存访问
- Uniform Memory Access
- 所有处理器平等的访问内存
- 一个处理器更新了共享内存,其他处理器都能知道,既缓存连贯性
SMP,对称多处理器的表示(Symmetrical Multi-Processing)
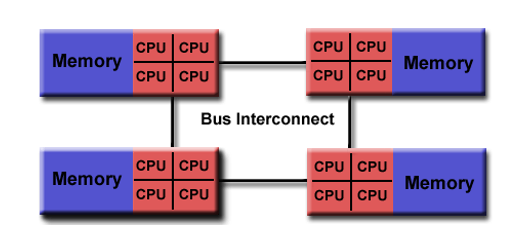
NUMA 非统一内存访问
- Non-Uniform Memory Access
- 通过物理连接将多个SMP连接在一起
- 一个SMP可以访问另一个SMP的内存,并非都有平等的访问时间来访问所有内存
- 跨链接的内存访问速度慢
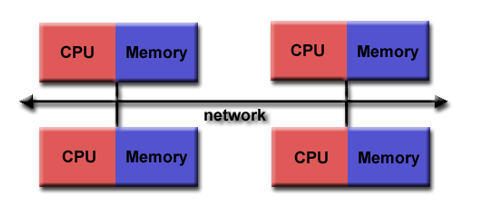
分布式内存
并行计算机的一种存储结构
- 特性
需要通信网络来连接处理器的内存
处理器有本地内存,不存在全局地址空间
独立运行,不适用缓存连贯
处理器需要访问其他处理器的数据时,程序员需要明确定义数据传输方式和访问时间,进行任务的同步
用于数据传输的网络结构差别大
- 优点
内存可随着处理器数量的增加而增多
每个处理器可以快速访问自己的内存,且没有冲突,没有维护缓存一致性的开销
成本低 - 缺点
程序员需要负责很多通信之间的详细信息
因为没有全局地址空间,很难建立分布式内存管理映射
并行计算模型
PRAM
-
Parallel Random Access Machine, 随机存取并行机器
-
共享存储的SIMD模型,在PRAM中有一个同步时钟,所有的操作都是同步进行的
有一个集中的共享存储器和一个指令控制器,通过SM(Shared Memory)的R/W交换数据,隐式同步计算。
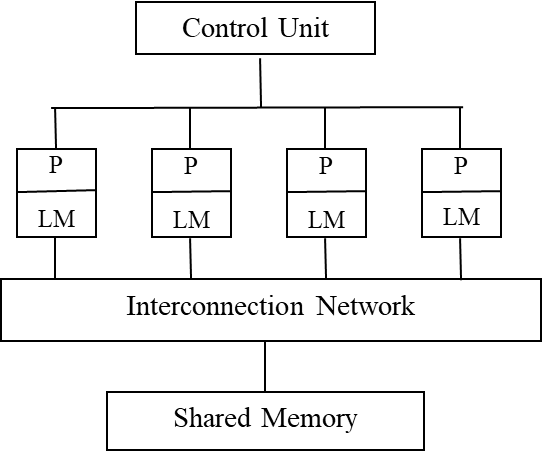
-
并发读写控制策略
根据处理器对共享存储单元同时读、同时写的性质,分为

(E:Exclusive C:Concurrent) -
不同并发读写控制策略的计算能力

优点:适用于并行复杂度分析,隐藏了同步和通信的细节,
缺点:不适合MIMD并行机,忽略了SM的竞争,通信延迟等问题,全局访存通常要比预想的慢
APRAM
- Asynchronous Parallel Access Machine,异步的PRAM模型,也称分相PRAM
- 适用于MIMD
每个处理器有其局部存储器、局部时钟、局部程序;无全局时钟,各处理器异步执行;处理器通过SM进行通讯;处理器间依赖关系,需在并行程序中显式地加入同步路障。
指令类型:全局读、全局写、局部操作、同步


T是总的计算时间,t是每一个phase中执行的最长时间,局部操作和全局读写的时间应该包含在t里面
BSP
- Bulk Synchronous Parallel,块同步模型,是一种异步MIMD-DM(distributed memory)模型
- 块内异步并行,块间显式同步
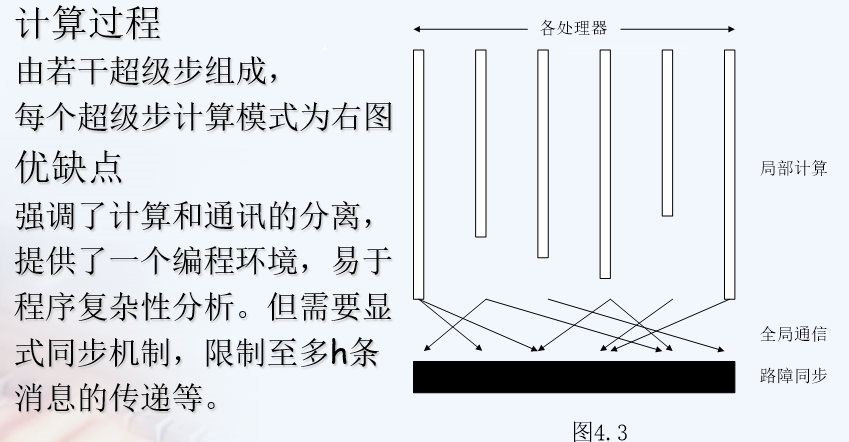
这里和APRAM的不同是:APRAM在每一个phase中可以局部也可以全局操作,最后再进行同步。BSP是等最慢的处理器执行完之后再进行全局通信,之后再进行同步(不严谨)

并行方法的一般设计过程PCAM
- PCAM Partitioning Communication Agglomeration Mapping
- 划分 通信 组合 映射


MPI并行编程
- Message Passing Interface
- 是一种基于消息传递的跨语言的并行编程技术,支持点对点通信和广播通信。消息传递接口是一种编程接口标准,而不是一种详细的编程语言,MPI是一种标准或者规范,目前存在对多种MPI标准的实现
并行测试标准
通信测试标准

Amdahl定律(固定负载)


S为加速比,W为问题规模,Ws为程序中的串行部分,Wp为程序中的并行部分,f是串行分量比例:Ws/W
加速比等于同样的程序在串行机上的执行时间/在并行机上的执行时间
Gustafson定律
实际问题中固定负载量而增加处理机数目没有意义,因此增多处理机,必须也增多负载

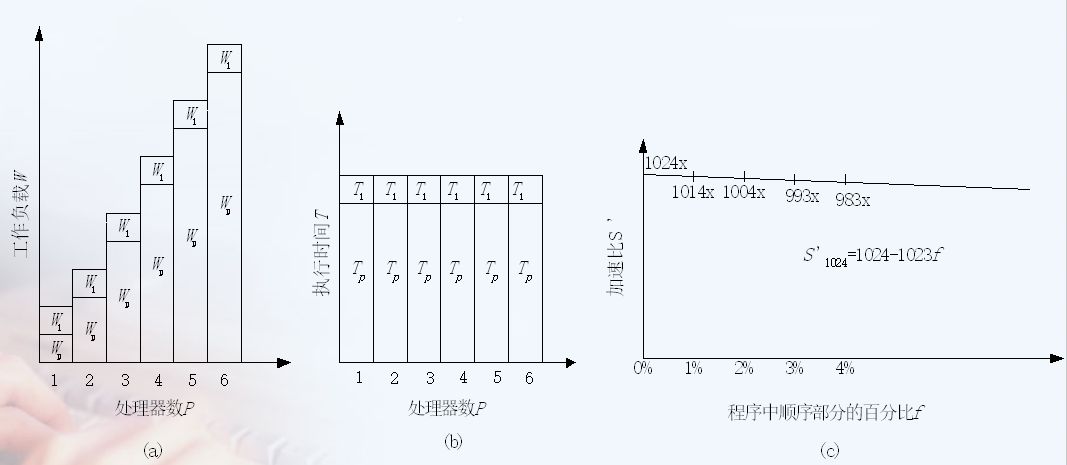
加速比与效率
效率=S/P
加速比/处理机数
问题规模不变,处理机数量增加,效率就下降
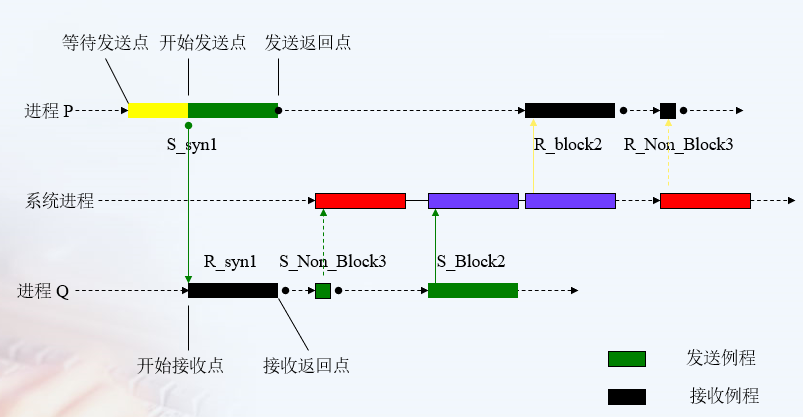
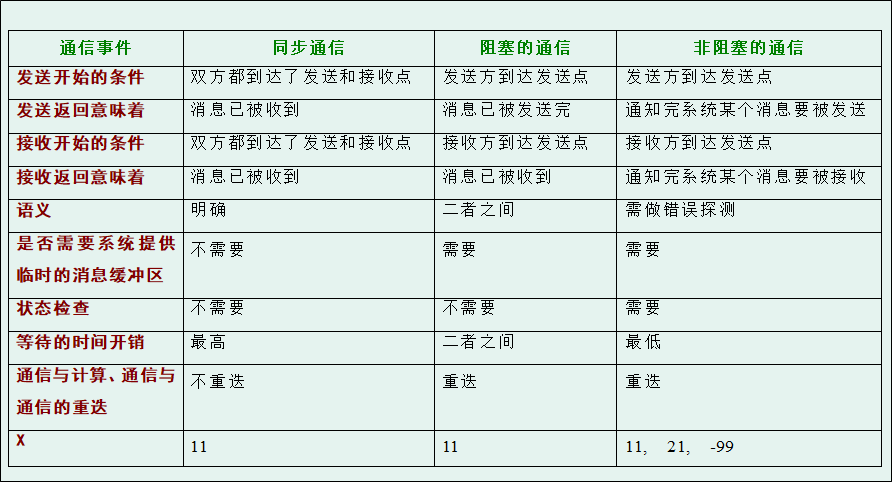
⭐⭐消息传递三种方式
进程之间通过消息传递实现数据共享和进程同步
- 同步的消息传递
Synchronous Message Passing
开始发送:双方到达发送点和接受点
发送返回和接收返回:消息已被收到
开始接收:双方到达发送点和接受点
等待时间:最多 - 阻塞的消息传递
Blocking Message Passing
开始发送:发送方到达发送点
发送返回:消息已被发完
开始接收:接收方到达接受点
接收返回:消息已经被接收
等待时间:介于二者之间 - 非阻塞的消息传递
Nonblocking Message Passing
开始发送:发送方到达发送点
发送返回:通知完系统发送消息
开始接收:接收方到达接受点
接收返回:通知完系统接收消息
等待时间:最少
三种方式异同


MPI点对点通信与集群通信
点对点通信
这是一种非阻塞通信,让计算和通信重叠,提高效率。
如果是阻塞通信,通信还没结束时,处理器只能等待,不能计算,浪费了计算资源。
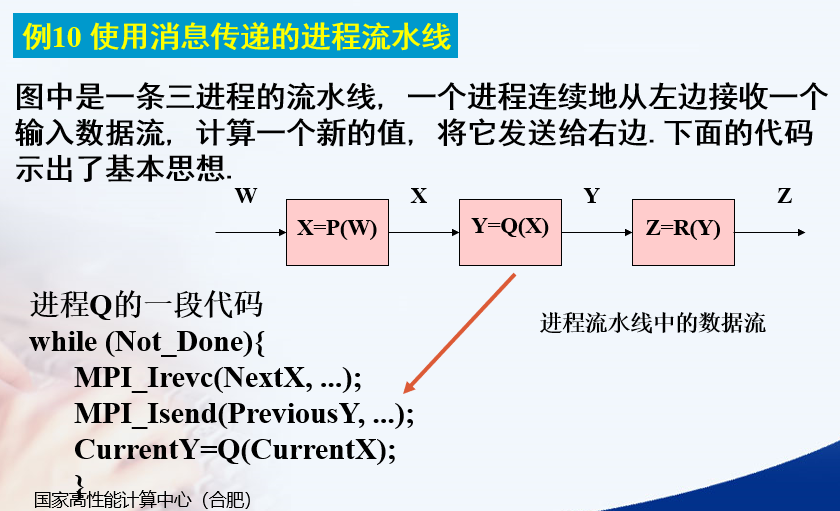
Q接收的是下一次用来计算的X
Q发送的是上一次计算完的Y
接着用这次收到的X计算Y
下图的代码应该是进程流水线具体是怎么接收发送的,需要双缓冲
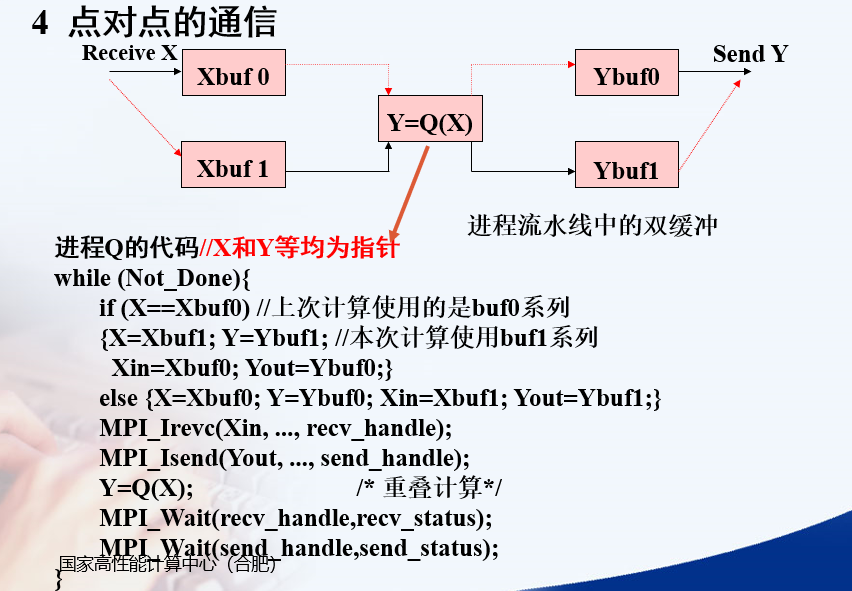
Isend Irevc是非阻塞式,调用完立刻返回,需要调用等待函数检查发送和接收是否完成即send_handle revc_handle
X Y Xbuf0 Xbuf1 Ybuf0 Ybuf1 Xin Yout都是指针
Xin Yout是要发送或接收的数据的指针
X Y指当前计算用的缓冲区
图中的红线和黑线,分别表示不同的循环中,发送和接收的情况
具体看红色线的一次循环:
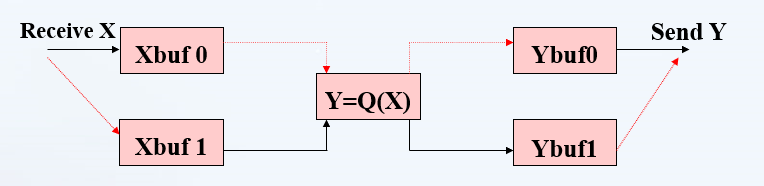
接收Xubf1,为了下一次计算;发送的是Ybuf1,是上一次计算的结果。
然后计算Y=Q(X),X来自上一次接收的Xbuf0,Y计算过之后放在Ybuf0中等待下一次发送。
集群通信
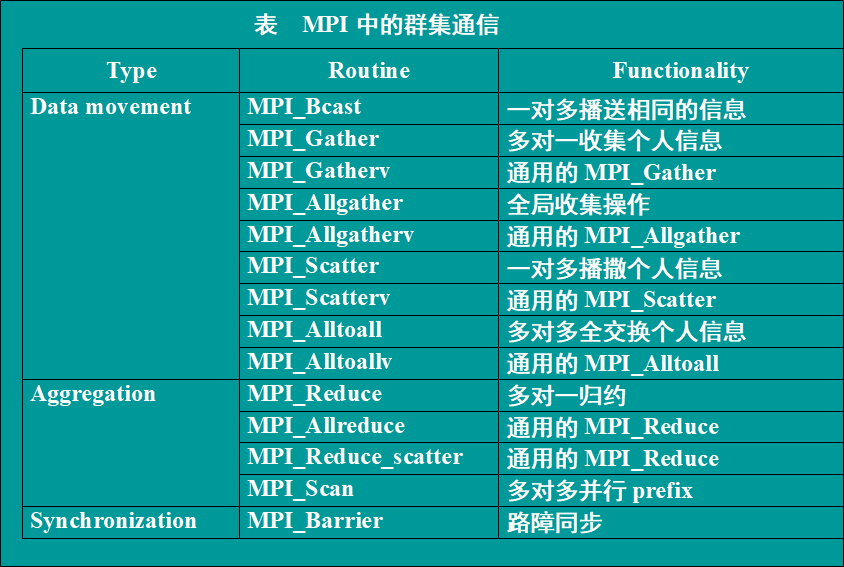
通信子中的所有进程都必须调用群集例程
- 广播(Broadcast)
MPI_Bcast(Address, Count ,DataType, Root, Comm)
标记为root的进程将相同的消息发送给Comm通信子中的所有进程
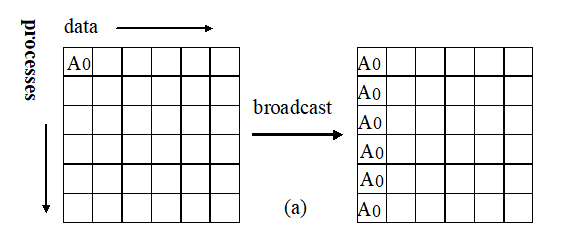
- 播撒(Scatter)聚集(Gather)
MPI_Scatter(SendAddress, SendCount, SendDataType, RecvAddress, RecvCount, RecvDataType, Root, Comm);
MPI_Gather(SendAddress, SendCount, SendDataType, RecvAddress, RecvCount, RecvDataType, Root, Comm);
播撒:root进程给每个进程都发送一个不同的消息,要发送的消息有序的存放在root进程的发送缓存中
聚集:root从每个进程接收消息,接收的消息有序的存放在root进程的接收缓存中。
播撒和聚集是两个相反的操作
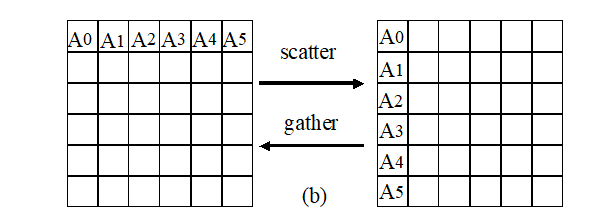
- 扩展的聚集和播撒(Allgather)
MPI_Allgather(SendAddress, SendCount, SendDataType, RecvAddress, RecvCount, RecvDataType, Comm);
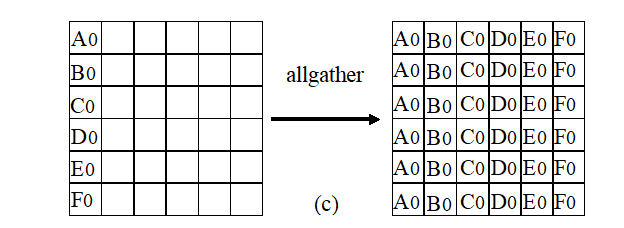
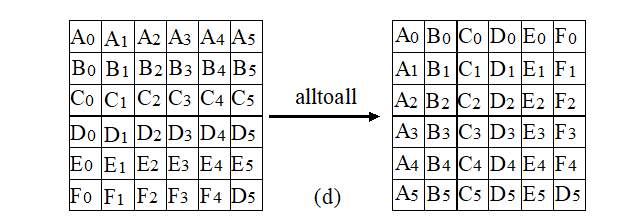
- 全局交换(Total Exchange)
MPI_Alltoall(SendAddress, SendCount, SendDataType, RecvAddress, RecvCount, RecvDataType, Comm);
每个进程都向n个进程发送消息,要发送的消息有序的存放在发送缓存中
换个角度,每个进程都从n个进程接收消息,要接收的消息有序的存放在接收缓存中
全局交换就是n个进程做n次gather,一次全局交换有n^2个消息通信
- 聚合(Aggregation)
有两种聚合操作:归约(Reduction)和扫描(Scan)
归约:每个进程将要归约的值存放在SendAddress中,所有进程将这些值归约为最终结果存放在root进程的RecvAddress中,归约操作为op
MPI_Reduce(SendAddress, RecvAddress, Count, DataType, Op, Root, Comm);
扫描:没有了root,将部分值组合成n个最终值,存放在每个进程的RecvAddress中,操作为op
MPI_Scan(SendAddress, RecvAddress, Count, DataType, Op, Comm);
- 路障(Barrier)
MPI_Barrier(Comm);
通信子中所有进程进行同步,即相互等待,直到所有进程执行完自己的Barrier函数
⭐⭐MPI求PI的值
计算PI的公式
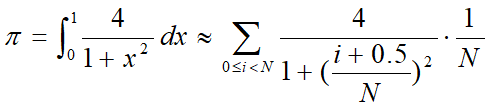
#include <stdio.h>
#include <mpi.h>
#include <math.h>
long n, /*number of slices */
i; /* slice counter */
double sum, /* running sum */
pi, /* approximate value of pi */
mypi,
x, /* independent var. */
h; /* base of slice */
int group_size,my_rank;
main(argc,argv)
int argc;
char* argv[];
{
int group_size,my_rank;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_rank( MPI_COMM_WORLD, &my_rank); //获得当前进程在通信子中的编号
MPI_Comm_size( MPI_COMM_WORLD, &group_size); //获得通信子内的进程数量
n=2000;
/* Broadcast n to all other nodes */
MPI_Bcast(&n,1,MPI_LONG,0,MPI_COMM_WORLD); //将n广播给所有进程,指定编号为0的进程为root进程
h = 1.0/(double) n;
sum = 0.0;
//每个进程计算一部分
for (i = my_rank; i < n; i += group_size) {
x = h*(i+0.5);
sum = sum +4.0/(1.0+x*x);
}
mypi = h*sum;
/*Global sum * reduce到root进程,用的是求和运算*/
MPI_Reduce(&mypi,&pi,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);
if(my_rank==0) { /* Node 0 handles output */
printf("pi is approximately : %.16lf\n",pi);
}
MPI_Finalize();
}
MapReduce
模型原理
对于相互之间不存在依赖关系的大数据,实现并行的最佳方法就是分而治之。
MPI等并行方法缺少高层并行编程模型,程序员需要自行指定存储、划分、计算等任务;缺乏统一的并行框架结构,程序员需要考虑诸多细节。
因此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了大多数系统层的细节,用Map和Reduce两个函数提供了高层并发编程模型抽象。
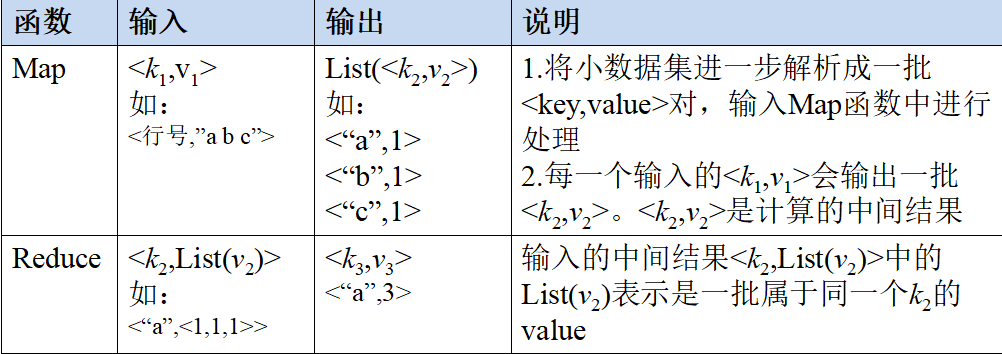
一个大的数据集被分成许多独立的分片(split),这些分片给多个Map任务并行处理
<k1, v1>:k1是主键,v1是数据,经Map处理后生成了很多中间结果,即List(<k2,v2>)。
Reduce对中间结果进行合并,把key值相等的数据合并在一起,即<k2, List(v2)>,最后生成最终结果,即<k3, v3>
通俗的说,将一个文本拆成n份(Map阶段,做拆分),然后让n个人对这n份文本单独进行统计,最后将n个人的结果进行合计(Reduce阶段,进行统计),则得出最后的结果
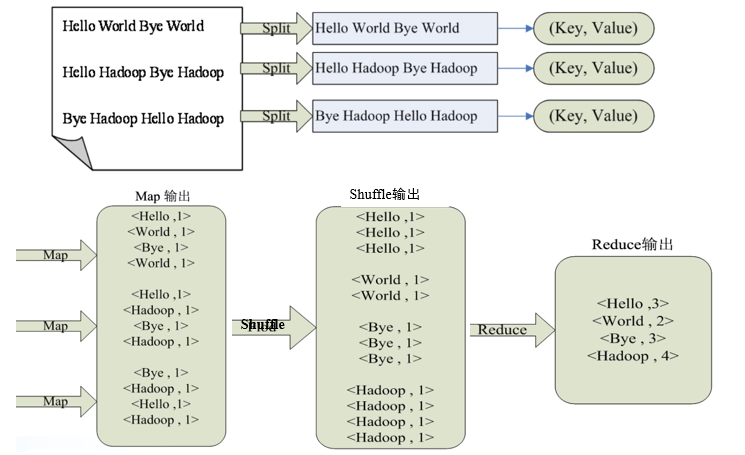
⭐⭐wordcount实例
图示:
核心伪代码:

简写很多的伪代码
public class Mapper()
{
/*
key和value是输入的键值对
context是输出的结果
*/
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//默认取每行的数据,每行都有空格,按空格切分
String lineContent = value.toString(); //取出每行的数据
String words[] = lineContent.split(" "); //进行每行数据的拆分
for(String word : words){ //循环每个单词而后进行数据的生成
//每一个单词最终生成的保存个数是1
context.write(word, 1);
}
}
}
public class Reducer()
{
/*
key和values是map输出的中间结果,需要reduce处理
context是reducer输出的最终结果
*/
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0 ; //保存每个单词出现的总次数
for(IntWritable count : values){
sum += count;
}
context.write(key, sum);
}
}
public static void main(String[] args) throws Exception{
//首先完成配置,给Job命名
Configuration configuration=new Configuration(); //进行相关配置
Job job=Job.getInstance(configuration, "word count"); //创建一个工作对象
//先指定该工程的类,再依次指出各执行流的流
job.setJarByClass(Myjob.class); //设置当前的工作对象
job.setMapperClass(Mapper.class); //设置map对象类
job.setReducerClass(Reducer.class); //设置reduce对象类
//设置输出格式,以及输入输出路径
job.setOutputKeyClass(Text.class); //设置输出的key类型
job.setOutputValueClass(IntWritable.class); //设置输出的value类型
FileInputFormat.addInputPath(job, new Path("/hadoop/hadoop.txt")); //设置输入的文件位置
FileOutputFormat.setOutputPath(job, new Path("/hadoop/out")); //设置输出的文件位置
job.waitForCompletion(true);
return 0;
}
- wordcount的map阶段,map的参数有输入的key,输出的value,输出的context也是一个<key,value>类型的。输入一般以文件的形式,输入的key一般就是行号,类型是Object。输入的value为该行的内容,类型是Text。输出结果Context的key是单词,就是Text类型,value是整数,就是IntWritable类型。
- Reduce阶段进行一个统计工作,输入来自map的输出,key是单词,类型是Text,values是单词数量,并且是一个迭代器(类似数组),就是
Iterable<IntWritable>类型 - 主函数首先完成配置,给Job命名,之后,先指定该工程的类,再依次指出各执行流的流,最后设置输出格式,以及输入输出路径
容错控制策略(4种)
容错:系统能在发生故障的前提下继续提供服务
检查点容错
过程:周期性备份和回滚恢复
任务出错时,可以从最近一次成功的checkpoint处恢复计算
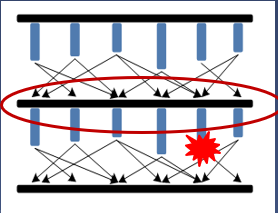
备份开销和恢复效率不可兼得
血统容错
输入输出的依赖关系:
窄依赖:一对一
宽依赖:一对多
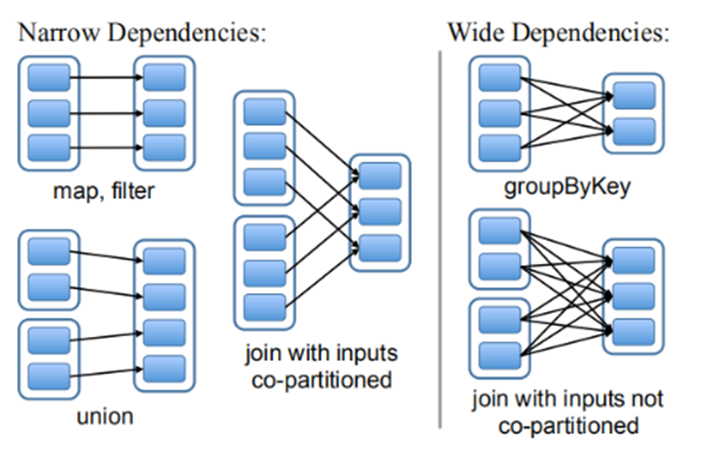
血统容错:记录中间结果的依赖关系,根据血统信息来重新计算一部分,恢复丢失的数据
如果血统信息过长,计算就会比较耗时,也需要使用检查点,避免太多的重复计算
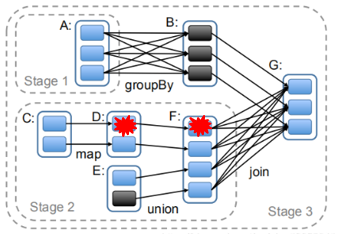
用C1重新计算D1,用D1重新计算F1,血统容错可以精准恢复数据,但只对窄依赖有效
若G1出错,需要算B1和F全部
推测式执行
如果有一个task执行的太慢,就会启动一个备份任务,最终使用原任务和备份任务中执行较快的task的结果。
推测式执行默认是关闭的,因为重复的任务会使集群的效率降低。
推测式执行是以空间换时间,一般在资源空闲且作业完成度较大时启动
补偿式容错
不做准备,出现故障时重置丢失数据(重新计算)
优点:无冗余(前三种都有冗余,数据冗余或计算冗余)
缺点:局限性大,只对一些算法适用
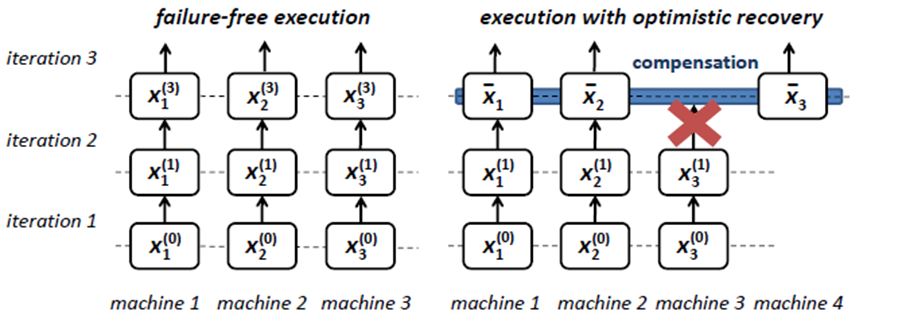
注: 有错误请指出!

