

CPP基础语法
C++基础语法
基本数据类型的大小
不同编译器的内置类型大小不同,比如指针类型,同是x86-64的CPU,g++的指针大小为8,visual的指针大小为4,minGW指针大小为8
C++标准只保证基本数据类型有一个最小大小:

记录几个常用类型的大小,都基于x86-64处理器架构
| g++ | MinGW_g++ | visual c++ | |
|---|---|---|---|
| char | 1 | 1 | 1 |
| int | 4 | 4 | 4 |
| long | 8 |
4 | 4 |
| long long | 8 | 8 | 8 |
| 指针类型 | 8 | 8 | 4 |
特别注意visual c++编译器的指针类型为4字节大小,以及g++编译器的long类型为8字节。
指针类型辨析
copy
- 1
- 2
- 3
- 4
- 5
int *p[10] // 1
int (*p)[10] // 2
int *p(int) // 3
int (*p)(int) // 4
int (*p[2])(int) // 5
- 一个指针数组,有10个元素,每个元素都是一个int型指针,指向一个int变量
- 一个数组指针,指向一个数组,这个数组有10个元素,每个元素都是一个int变量
- 是一个函数声明,函数名为p,接收一个int型变量,返回一个int型指针
- 是一个函数指针,该指针指向的函数接收一个int型变量,返回一个int型变量
- 是一个函数指针数组,这个数组有2个元素,每个元素都存储一个函数指针,函数指针指向的函数接收一个int型变量并返回int型变量。
数组名a与&a
总的来说,数组名的值是指向数组第一个元素的指针,而对数组名取地址则返回一个指向数组的指针。
“数组名的值指向数组第一个元素的指针”,其中一维数组的第一个元素是标量,二维和二维以上的数组的第一个元素则是一个矢量。
copy
- 1
- 2
- 3
- 4
- 5
int a[] = {1,2,3};
int* b = a;
int c[][3] = {{1,2,3},{4,5,6},{7,8,9}};
int (*d)[3] = c;
如上所示,a的值指向数组的第一个元素1,而c的值指向二维数组的第一个元素{1,2,3},这是一个数组,因此被赋值的变量的类型因为数组指针:
copy
- 1
- 2
- 3
int c[][3] = {{1,2,3},{4,5,6},{7,8,9}};
int (*d)[3] = c; // 正确
int *e = c; // compiler error : cannot convert ‘int (*)[3]’ to ‘int*’ in initialization
“对数组名取地址则返回一个指向数组的指针”,注意指向的是数组,因此这两个指针的类型都是矢量。
copy
- 1
- 2
- 3
- 4
- 5
int a[] = {1,2,3};
int (*refa)[3] = &a; // &a的类型是一个数组指针,指向一个长度为3的数组
int c[][3] = {{1,2,3},{4,5,6},{7,8,9}}; // &cc 的类型是一个数组指针,指向一个3 * 3的二维数组。
int (*refc)[3][3] = &c;
知道了数组名和对数组名取地址后的指针类型,那么相应的指针加减法的含义就非常顺利地对上号了
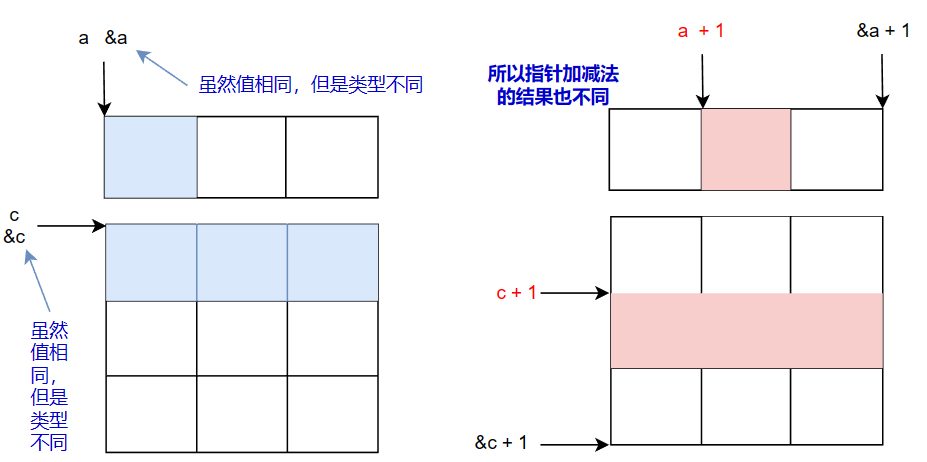
有了上面的铺垫,下面这道笔试题就容易多了,该笔试题考察数组名和对数组名取地址的区别:
copy
- 1
- 2
- 3
- 4
int aa[2][5] = {1,2,3,4,5,6,7,8,9,10};
int* ptr1 = (int*)(&aa + 1); // &aa + 1指向整个二维数组的最后元素的后一个元素
int* ptr2 = (int*)(*(aa + 1)); // aa + 1指向二维数组的第二个元素,即一个一维数组
printf("%d %d\n", *(ptr1 - 1), *(ptr2 - 1));// 输出什么?
答案为10,5。
看看具体的地址值吧:
copy
- 1
- 2
printf("&aa = %p, &aa + 1 = %p \n", &aa, &aa + 1);
printf("aa + 1 = %p\n", aa + 1);
输出为:
copy
- 1
- 2
&aa = 0x7ffee9452ed0, &aa + 1 = 0x7ffee9452ef8
aa = 0x7ffee9452ed0, aa + 1 = 0x7ffee9452ee4
当然这是在我的机器上的某次实验,结果可能并不是每次相同,但是aa 与 aa + 1和&aa 与&aa + 1之间的差值是相同的。
结构体内存对齐
结构体内存对齐规则
-
结构体的第一个成员在结构体变量存储位置偏移量为0的地址处。从第二个成员开始,在其自身对齐数的整数倍开始存储。各类型的对齐数如下所示:
对齐数 类型 1 char 2 short 4 int ,float 8 long,double,char* -
结构体变量所用总空间大小是成员中最大对齐数的整数倍。
-
当遇到嵌套结构体的情况,嵌套结构体对齐到其自身成员最大对齐数的整数倍,结构体的大小为当下成员最大对齐数的整数倍。
为什么要对齐
处理器的存取粒度一般不会是1字节,而是双字节、四字节、八字节等等。
假设一个处理器的存储粒度为4字节,那么存储器一次存取4字节。如果它要读取一个没有对齐的int型值,假设这个int的存储地址为1,处理器为了读取这个int值,会进行两次读取,第一次读取0 - 3的内存,剔除0字节,第二次读取4 - 7的内存,剔除5 - 7的内存,然后将两块数据合并放入寄存器。

与读取内存对齐的变量相比,处理器读取非内存对齐的操作显然多了很多。
所以为了执行效率考虑,结构体遵循上述的对齐规则。
此外,一些处理器对基本的内存操作能够保证原子性,前提是内存对齐了

(当然这只是处理器的保证,编译器可能不会有这样的保证)
实例
在x86-64的g++编译器上进行实验
copy
- 1
- 2
- 3
- 4
- 5
struct stu {
char a;
int b;
char c;
}
-
a在0偏移地址存放
b在4偏移地址存放,其中b之前空出的3字节的内容就是为了对齐b而浪费的3字节内存
c在偏移地址8存放 -
以上内存加起来一共9字节。
这个结构体的最大成员对齐数位4,因此这个结构体本生的对齐数应为4,因此sizeof(stu) 应为 12, 所以在结构体最后padding3个空字节
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
struct stu1 {
double a;
int b;
int c;
} // sizeof(stu1) = 16。
// a 存放在偏移地址0, b存放于偏移地址8, c存放于偏移地址12
struct stu2 {
int b;
double a;
int c;
} // sizeof(stu2) = 24。
// b 存放于偏移地址0,a存放于偏移地址8,c存放于偏移地址16,那么一共是20字节,又由于规则二,那么sizeof(stu2) = 24
从这个例子中可以看出,结构体成员的申明顺序会对结构体大小造成影响。
更进一步地,同通常一个cacheline的大小为64B,那么一个缓存行可以存放4个stu1,但只能存放2.7个stu2,导致了缓存利用率的不高,间接影响了时间效率。
# pragma pack宏
不同CPU架构、不同编译器对相同数据类型可能有不同的对齐数,那么可能会带来一些兼容性问题。比如网络传输,在一个机器上的sizeof结果可能是20字节,但是另一个机器上却成了24字节,这可能带来一些问题。
# pragma pack(n)宏就可以解决这个问题,它可以提示编译器使用不同的字节对齐大小,n的取值可为1、2、4、8等。注意只有当 n < 某类的默认字节对齐大小时,编译器才会改变对齐方式!
例1:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
struct stu {
char a;
int b; // 由于int的默认字节对齐大小为4,小于1,因此编译器改变int的对齐大小
char c;
}
int b此时不会从4的倍数地址开始存储,而是紧挨着char a之后。因此sizeof(stu) = 6。
使用# pragma pack(1)即可使得编译器不进行对齐,这样stu这个类在任何机器上的大小都是相同的。
指针和引用
“引用的底层还是指针”,为了验证这句话,做个实验吧。首先编写.cpp文件,定义三个函数,参数传递方式分别为值传递、指针传递、引用传递。
在main函数中,定义对应的变量,然后调用这几个函数:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
class Widget {
public:
int a_;
Widget(int a):a_(a) {
cout << "Widget(int a)\n";
}
Widget(const Widget& other):a_(other.a_) {
cout << "Widget(const Widget& other)\n";
}
};
void funObj(Widget a) {
a.a_ = 2;
}
void funPtr(Widget* a) {
a->a_ = 2;
}
void funRef(Widget& a) {
a.a_ = 2;
}
int main() {
Widget widget_obj = Widget(1);
Widget* widget_ptr = &widget_obj;
Widget& widget_ref = widget_obj;
funObj(widget_obj);
funPtr(widget_ptr);
funRef(widget_ref);
funRef(widget_obj);
return 0;
}
g++编译链接形成可执行文件,然后使用objdump查看汇编代码,看看引用在底层到底是怎么工作的
copy
- 1
g++ RefAndPtr.cpp -o RefAndPtr && objdump -d RefAndPtr | c++filt > RefAndPtr.objdump
在objdump生成的文件中定位main函数:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
00000000000008a9 <main>:
----------------------------------以下代码为:栈帧调整以及一些栈检查的代码-------------------------------------------
# ..........
-------------------------------------以下代码为:widget_obj构建------------------------------------------
8c0: 48 8d 45 e0 lea -0x20(%rbp),%rax # 在-0x20(%rbp)这个地址构造对象
8c4: be 01 00 00 00 mov $0x1,%esi # 第二个参数是构造函数接受的成员函数初始值
8c9: 48 89 c7 mov %rax,%rdi # 第一个参数是widget_obj对象在站上的地址
8cc: e8 cd 00 00 00 callq 99e <Widget::Widget(int)> # 调用构造函数
------------------------------------以下代码为:设置widget_ptr的值--------------------------------------
8d1: 48 8d 45 e0 lea -0x20(%rbp),%rax # 取得widget_obj对象的地址
8d5: 48 89 45 e8 mov %rax,-0x18(%rbp) # 设置widget_ptr的值
-----------------------------------以下代码为:设置widget_ref--------------------------------------
8d9: 48 8d 45 e0 lea -0x20(%rbp),%rax # 对比编译器对widget_ptr的操作,编译器眼里引用与指针是一样的
8dd: 48 89 45 f0 mov %rax,-0x10(%rbp) # 可以看到引用的底层实现还是指针
-----------------------------------以下代码为:为了调用funObj,首先在main函数的栈上构造一个临时对象----------------------------
8e1: 48 8d 55 e0 lea -0x20(%rbp),%rdx # -0x20(%rbp)为刚刚widget_obj被构建的地址
8e5: 48 8d 45 e4 lea -0x1c(%rbp),%rax # 将-0x1c(%rbp),作为临时对象的构建地址
8e9: 48 89 d6 mov %rdx,%rsi
8ec: 48 89 c7 mov %rax,%rdi
8ef: e8 d8 00 00 00 callq 9cc <Widget::Widget(Widget const&)>
------------------------------------以下代码为:4个函数的调用操作-------------------------------------------------------
8f4: 48 8d 45 e4 lea -0x1c(%rbp),%rax # 取得临时对象的地址,修改这个临时对象不影响widget_obj对象
8f8: 48 89 c7 mov %rax,%rdi
8fb: e8 6a ff ff ff callq 86a <funObj(Widget)>
900: 48 8b 45 e8 mov -0x18(%rbp),%rax # 取得widget_ptr的值,指向widget_obj对象
904: 48 89 c7 mov %rax,%rdi
907: e8 73 ff ff ff callq 87f <funPtr(Widget*)>
90c: 48 8b 45 f0 mov -0x10(%rbp),%rax # 取得widget_ptr的值,指向widget_obj对象
910: 48 89 c7 mov %rax,%rdi
913: e8 7c ff ff ff callq 894 <funRef(Widget&)>
918: 48 8d 45 e0 lea -0x20(%rbp),%rax # 取得widget_obj对象的地址
91c: 48 89 c7 mov %rax,%rdi
91f: e8 70 ff ff ff callq 894 <funRef(Widget&)>
------------------------------------以下代码为:一系列栈检测操作以及退出操作--------------------------------------------------
# ........
其中的这段汇编代码:
copy
- 1
- 2
- 3
- 4
- 5
- 6
------------------------------------以下代码为:设置widget_ptr的值--------------------------------------
8d1: 48 8d 45 e0 lea -0x20(%rbp),%rax # 取得widget_obj对象的地址
8d5: 48 89 45 e8 mov %rax,-0x18(%rbp) # 设置widget_ptr的值
-----------------------------------以下代码为:设置widget_ref--------------------------------------
8d9: 48 8d 45 e0 lea -0x20(%rbp),%rax # 对比编译器对widget_ptr的操作,编译器眼里引用与指针是一样的
8dd: 48 89 45 f0 mov %rax,-0x10(%rbp) # 可以看到引用的底层实现还是指针
可以看出引用的底层实现还是指针,还是占用8字节的内存大小。
另外,三种函数调用,无论是传值、传指针还是传引用,编译器都将变量地址存放在rdi寄存器,然后调用相应的函数。其中值传递函数有前置准备工作,创建一个临时对象,然后会使用这个临时对象的地址,不会影响原对象的状态。
那么,funObj、funRef、funPtr这三个函数在编译器眼里有什么不同吗?可以在objdump输出的文件中查找这三个函数的汇编实现,你会发现它们没有任何区别,都是操作外部调用者传入的指针进行赋值操作。唯一的区别是,funRef、funPtr这两个函数操作的指针指向main函数栈帧中的widget_obj,而funObj这个函数操作的指针指向main函数栈帧中的临时对象(这里可以看出传值对程序的效率影响)。

下面是main函数以及三个被调函数的栈帧示意图:

指针于引用在使用上的区别,参考自阿秀的网站
- 引用
本质是一个指针,同样会占8字节内存(x86,g++编译器);指针是具体变量,需要占用存储空间 - sizeof指针得到的是本指针的大小,sizeof引用得到的是引用所指向变量的大小
- 指针可以为空,引用不能为NULL且在定义时必须初始化
- 指针在初始化后可以改变指向,而引用在初始化之后不可再改变所引用的对象(注意这里指的是指向不能更改,而不是所指对象的值。所以引用相当于一个指针常量)
- 不存在指向空值的引用,必须有具体实体;但是存在指向空值的指针。
- 对指针变量取地址得到指针变量在内存中的地址,而对引用变量取地址得到的是引用变量所引用对象在内存中的地址(这在operator = 中的判重逻辑中常用)
所以引用的本质是一个必须被初始化且不能被初始化为nullptr的指针常量。
既然引用的本质是指针,那么为什么已经有了指针的情况下还要使用引用呢?
C++之父的回答 : Stroustrup: C++ Style and Technique FAQ
最主要的还是为了支持操作符重载。如果没有引用的话,会显得很丑陋?
引用与指针的使用场景?
- 当所指对象有可能是nullptr,则使用指针而不是引用, 反之如果所指对象不可能\不能为null则使用引用
- 操作符重载的编写中,通常情况下,它的接收参数是引用类型,返回参数也是引用类型。
隐藏对继承和重载的影响
- 整理自《effective C++》条款33以及条款52
- 还有这个,整理了重写与隐藏的区别(基类、派生类有同名virtual函数,但是参数不同,不会触发重写机制而是会触发隐藏机制)
其实在2021的cmu15445的项目0中碰到过,但是没整理好,现在重新看了effective C++的条款52被它提到的覆盖机制搞糊涂了。
以下内容主要整理自effective C++的条款33。
变量名的遮掩主要是由于C++对变量名称的搜寻方式导致的,当遇到一个名字时,C++会先从local作用域中找这个名称,如果找不到则往外一层作用域寻找,最后会找到全局作用域。如下代码所示:v1这个名称在成员函数作用域找到,v2这个名称在类作用域中找到,而v3则在全局域中找到。
那些同名但是作用域大的变量很有可能被C++忽略,这样就好像这些变量被“遮蔽”了。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
double v1 = 2.1;
double v2 = 1.1;
double v3 = 3.2;
class A {
public:
int v1;
int v2;
A() {
v1 = 1;
v2 = 2;
}
void printfv1() {
int v1 = 3;
std::cout<<v1<< std::endl;
}
void printfv2() {
std::cout << v2<< std::endl;
}
void printfv3() {
std::cout << v3 << std::endl;
}
};
int main() {
A a;
a.printfv1(); // 3 , 打印局部变量
a.printfv2(); // 2, 打印成员变量
a.printfv3(); // 3.2 打印全局变量
}
名称遮蔽规适用于任何名称,无论是变量名称,还是函数名称。
当涉及函数名称时,遮蔽机制可能对继承和重载带来一些影响,这可能会造成一些混淆。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
class B {
public:
void f1() {
printf("B::f1\n");
}
void f2() {
printf("B::f2\n");
}
};
class C : B {
public:
void f1(int a) {
printf("C::f1(int)\n");
}
};
int main() {
C c;
c.f1(1); // 正常
c.f1(); // 报错!
c.f2(); // 正常
}
如上所示,class B定义f1和f2函数,class 继承B。
很容易掉进这样的陷阱:C继承了B,因此C有了f1的无参数版本,然后C定义一个接收参数的f1,即可触发重载机制了。
实际上,名称遮掩规则可不管你是不是需要重载,只要在C中定义了f1这个名称的函数,那么就会掩盖B中的所有f1这个名称的函数定义!因此根本不会有重载发生!因此当调用c.f1()时,编译器会报错,因为它找不到这个函数定义。
如果想要让B中定义的f1可见,那么就要在C的作用域内,加入using语句
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
class C :public B {
public:
using B::f1; // using 语句
void f1(int a) {
printf("C::f1(int)\n");
}
};
int main() {
C c;
c.f1(1); // 正常
c.f1(); // 现在继承和重载机制起作用了
c.f2(); // 正常
}
或者不用加上using,在调用方法前加上作用域限定符也可以:
copy
- 1
c.B::f1();
这个机制让我感到困惑,但只能表示顺从。
define与const的区别
整理自《effective C++》 条款2
从编译器对两个关键词的区别来讲:
- define根本不会由编译器处理,在
预处理阶段,就会将文件中的所有相关名称替换成为define定义的变量,编译器根本看不到define定义的“变量名” - 预处理“盲目的”将所有涉及的名称都替换为define定义的变量,因此有可能导致目标文件出现多个相同的值,导致
执行文件膨胀
从定义“常量”的作用讲:
- define定义的“常量”名可能没有进入
符号表(symbol table)内,而const 定义的常量一定在符号表内的,因此debug时,define写出的程序可能会比较费力 - define无法创建一个class专属常量,因为define不重视作用域。const + static能够创建class的专属常量。
const 关键字
修饰变量或函数
不考虑类的情况
- const常量在定义时必须初始化,之后无法更改
- const形参接收const和非const参数
考虑类的情况
-
const成员
变量:不能在类定义外部初始化,只能通过构造函数初始化列表进行初始化,并且必须有构造函数;不同类对其const数据成员的值可以不同,所以
不能在类中声明时初始化参考自 -
const成员
函数:-
const形参同样也接收const和非const参数
-
但是,如果以const“修饰”函数,则
可构成函数重载。即非const对象,可调用const和非const成员函数,而const对象只能调用const 成员函数copy- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
class C{ public: void func1(int a) { } void func2( int a) const{ } }; int main() { C c; c.func2(a); // 非const对象可正常调用const成员函数 c.func1(a); // 非const对象调用非const成员函数 const C c2; // c2.func2(a); // const对象调用const成员函数 // error :'this' argument to member function 'func1' has type 'const C', but function is not marked const // c2.func1(a); // cont对象调用非const成员函数,编译器报错! }
-
const与指针
如果const在*号左侧,表示被指向的值是常量,指针本身的指向可以改变,但是指向的值不能被改变
如果const在*号的右侧,表示指针自身是常量, 指针本省的指向不可以改变,但是指向的值能够被改变
如果*号两侧都有const的化的话,那无论是值还是指向都不能改变了。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
char greeting[] = "hello";
const char* p2 = greeting;
char * const p3 = greeting;
*p2 = 'a'; // error:Read-only variable is not assignable
p2 = something; // 正常
*p3 = 'b'; // 正常
p3 = something; // error: Cannot assign to variable 'p3' with const-qualified type 'char *const'
const与迭代器
迭代器被设计成类似指针的行为,比如 *iterator相当于对一个指针解引用取得这个迭代器“指向”的值,如果iterator++,则相当于对指针做递增,使得迭代器“指向”容器的下一个元素。
如果const施加于迭代器,则相当于声明一个指针为const(T* const),即表示迭代器的指向不能改变
copy
- 1
- 2
- 3
- 4
- 5
std::vector<int> vec;
const std::vector<int>::iterator iter = vec.begin();
*iter = 10; // 可以改变迭代器的值
iter++; // 错误! 不能改变迭代器的指向
如果让iterator指向的值不能改变,但是可以改变指向(像是定义了 const T*),那么需要使用const_iterator
copy
- 1
- 2
- 3
- 4
- 5
std::vector<int> vec;
std::vector<int>::const_iterator iter = vec.begin(); // 使用`const_iterator`
*iter = 10; // 错误,不可以改变迭代器的值
iter++; // 正确,const_iterator能够改变迭代器的指向
static关键字
概览
修饰变量:
-
static修饰全局变量,表示该变量
仅在本编译单位可见,是个局部符号。存放于data或者bss段中 -
static修饰函数的局部变量,表示该变量
仅被初始化一次,且独立于函数存在。其初始化涉及到线程安全等话题。存放于data或者bss段中。 -
statci修饰成员变量,表示该变量
不占用对象存储空间,是属于“类”的。存放于data或者bss段中。
static修饰变量还将在C++对象模型中详细讨论。
修饰函数:
-
static修饰普通函数,表示该函数仅在本编译单元可见,是个局部符号。
-
static修饰成员函数,表示该函数“是属于类”的,它不会像non-static成员函数一样接收this这个隐式指针,因此也不能获取对象的non-static成员变量。且被static修饰的成员函数不能被添加virtual、const、volatile关键词。
static类成员的初始化
头文件如下:
copy
- 1
- 2
- 3
- 4
- 5
// head.h
class test {
public:
static int a;
};
怎么初始化这个test::a?
首先,非const的static的成员必须在类外初始化。如果在申明的时候进行初始化,编译器报错:Non-const static data member must be initialized out of line
copy
- 1
- 2
- 3
- 4
- 5
// head.h
class test {
public:
static int a = 1; // compiler error
};
只能在类外初始化,那么是在那个文件中?在头文件中?
copy
- 1
- 2
- 3
- 4
- 5
- 6
// head.h
class test {
public:
static int a;
};
int test::a = 1; // compiler warning
编译器会警告:Variable 'a' defined in a header file; variable definitions in header files can lead to ODR violations。(ODR = One Definition Rule)
因为头文件可能被多个.cpp文件被include,所以可能会有多个多个定义。
那么只能在.cpp源文件中定义:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
// A.cpp
int test::a = 2;
int main() {
// ...
return 0;
}
这样就好了?还有什么要注意的?
还是要注意不要违反ODR,不要在多个.cpp文件中include head.h文件,并链接到一块:
copy
- 1
- 2
- 3
- 4
- 5
- 6
// B.cpp
int test::a = 2;
int func() {
// ...
}
copy
- 1
g++ A.cpp B.cpp -o exeo
不出意外的话你会得到链接错误:
copy
- 1
- 2
- 3
/tmp/cc6Fxlo5.o:(.data+0x0): multiple definition of `test::a'
/tmp/ccSlw0dj.o:(.data+0x0): first defined here
collect2: error: ld returned 1 exit status
最为对比,可以接着看看下一个话题。
“被static修饰的全局变量只对编译单元可见”到底啥意思?
实例程序如下:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
// head.h
static int a = 3;
// 1.cpp
using namespace std;
static int b = 1;
void fun() {
cout << "1.cpp : a = " << a << endl;
a += 5;
cout << "1.cpp : a + 5 , a = " << a << endl;
}
// 2.cpp
using namespace std;
extern void fun() ;
int main() {
cout << "2.cpp : a = " <<a << endl;
a += 4;
cout << "2.cpp : a += 4 , a = " <<a << endl;
fun();
}
编译链接两个文件然后执行:g++ 1.cpp 2.cpp -o obj && ./obj 。输出如下:
copy
- 1
- 2
- 3
- 4
2.cpp : a = 3
2.cpp : a += 4 , a = 7
1.cpp : a = 3
1.cpp : a + 5 , a = 8
可以看到两个文件中各自有一个int a变量,它们互不影响。
作为验证,我们可以查看obj文件的符号表,nm obj:
copy
- 1
- 2
0000000000202010 d a
0000000000202018 d a
可以看到有两个a变量,它们存储的位置不相同。且注意它们都是小写的d,表示这两个符号是局部的。
与上一个话题进行对比,这里我们没有违反ODR,这就是“被static修饰的全局变量只对编译单元可见”的意义。在C++中也另一个关键词inline也有相似的作用,但是底层机制并不相同,详见下文关于inline关键词的内容。
如果A文件有定义: static int b = 1; B 文件申明extern int b;那么B文件能存取A的a变量吗??
不能,会报链接错误:undefined reference to `b'
以上结论对static修饰的普通函数也适用。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
// static_fun.c
static int fun() {
std::cout << "head fun()\n";
}
// 1.cpp
extern void fun2();
void fun1() {
std::cout << "int 1.cpp call fun():\n";
fun();
}
int main() {
fun1();
fun2();
}
// 2.cpp
int fun2() {
std::cout << "int 2.cpp call fun():\n";
fun();
}
同样会在符号表中出现两个fun符号,但是它们都是局部符号,且地址不用:
copy
- 1
- 2
000000000000081a t fun()
00000000000008c6 t fun()
如果A文件有定义: static int b = 1; B 文件申明extern int b;那么B文件能存取A的a变量吗??
不能,会报链接错误:undefined reference to `b'
volatile关键字
整理自《effective modern C++》条款40
volatile好像常常被混淆地与线程安全相关的内容一起出现,但是volatile关键词不能保证线程安全,因为volatile:
- 既不能保证操作的原子性
- 也不能限制CPU指令的重排序
volatile只是告诉编译器,现在处理的不是常规内存,不要对代码做出优化。那么什么是常规内存,什么是特种内存?
-
常规内存(RAM)的特征是:如果向内存写入了某个值,该值会一直留在那里,直到被覆盖。因此编译器可以对一些冗余的赋值操做简化,或者直接使用寄存器中的值
copy- 1
- 2
- 3
- 4
- 5
int x; auto y = x; y = x; x = 10; x = 20;将会被简化为:
copy- 1
- 2
- 3
int x; auto y = x; x = 10; -
但是,特种内存,比如用于
memory IO的内存,它的实际值由外部设备决定,而非用于读取或写入常规内存(RAM),它的实际值是时刻变化着的。在这种情况下,需要让编译器老老实实地从内存读数据(而不是使用寄存器的值),并将修改过的变量值立刻写入内存而不是缓存到寄存器。用户C++代码写了多少次读写操作,硬件就得执行多少次读写操作,不能简化。
那么volatile阻止了编译器的乱序优化,就能保证线程安全吗?---不能,还有CPU指令层面的重排序。
记住volatile只能防止编译器的乱序执行,但不能防止CPU的乱序执行(结论来自《程序员的自我修养》),若要保证线程安全,则需要告诉CPU不要乱序执行。相关话题:实现单例模式
explicit关键字
参考:
- 《effective C++》条款17, 中文版P76
- https://stackoverflow.com/questions/121162/what-does-the-explicit-keyword-mean
explicit关键字修饰构造函数,可以禁止隐式转换。
例1:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
class Foo
{
private:
int m_foo;
public:
// single parameter constructor, can be used as an implicit conversion
Foo (int foo) : m_foo (foo) {}
int GetFoo () { return m_foo; }
};
void DoBar (Foo foo)
{
int i = foo.GetFoo ();
}
int main ()
{
DoBar (42);// 隐式转换
}
DoBar函数传入的是42,一个整数,但是DoBar函数要的是一个Foo对象。这时编译器就会查看Foo的构造函数,是否有可能将一个整数构造成一个Foo对象,确实可以,因此DoBar调用成功,编译器在背后隐式地调用Foo的构造函数将42转化为了Foo对象。
但是如果在Foo的构造函数前加上explicit关键字,那么编译器会报错!
不过依然可以用static_cast进行显示的转换。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
...
explicit Foo (int foo) : m_foo (foo) {}
...
int main ()
{
DoBar (Foo(42)); // 创建临时对象
DoBar (42); // 隐式转换被禁止,编译器报错!
DoBar (static_cast<Foo>(42));// 应该使用显示转换
}
例2:智能指针相关
函数声明如下:
copy
- 1
void processWidget(std::tr1::share_ptr<Widget pw, int priority)
如果你这样调用:
copy
- 1
processWidget(new Widget,1);
将会报错,因为std::tr1::share_ptr的构造函数是explicit的,并不能执行由原生指针向share_ptr类的转换。
必须这样显示地调用share_ptr的构造函数才行:
copy
- 1
processWidget(std::tr1::share_ptr<Widget>(new Widget),1);
析构、拷贝构造、拷贝赋值函数
当用户没有显示定义这三个函数(注意这三个函数不包括默认构造函数)时,编译器会自动生成它们(effective C++ 条款5)(但是《深入了解C++对象模型》指出它不会自动生成,只会在编译器需要它们时才被生成)。
对于拷贝构造和拷贝赋值函数,编译器默认创建的版本只是将对象的non-static成员一一拷贝。如果类成员具有一个指针,它指向了一个heap中的对象,那么默认的构造函数将只拷贝指针变量而不会新建heap对象,这就是所谓的“浅拷贝”。如果要执行“深拷贝”,则要自己定义拷贝函数、赋值函数,对动态分配的数据结构进行分配和构建。
当你决定自己编写构造和赋值函数时,一定要注意要拷贝全部的成员变量。如果变量涉及继承,那就更要小心了。编译器默认生成的拷贝构造和拷贝赋值函数将会在初始化派生类前,调用基类的拷贝构造函数\拷贝赋值函数,因此当我们自己编写这两个函数时,也要手动调用基类的构造\赋值函数,否则对象的初始化值将不完整,可能导致未定义行为。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
class Base {
private:
int a_;
}
class Derived : public Base {
private:
int b_;
public:
Derived(const Derived& d):Base(d) {// 调用基类的拷贝构造函数
b_ = d.b_;
}
Derived& operator=(const const Derived& d) {
Base::operator=(d); // 调用基类的拷贝赋值函数
b_ = d.b_;
return *this;
}
}
赋值函数需要考虑“自我赋值”的情况,当类的成员有指针时,需要特别注意。
可选做法1: 比较目标和源地址是否相同
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
class p{
public: SomeThing* a;
...
P& operator=(const P& p) {
if (this == &p) { // 对引用取地址得到所引用对象的地址
return *this;
}
delete a;
a = new Something(*p.a);
return *this;
}
}
可选做法2:使用临时变量
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
class p{
public: SomeThing* a;
...
P& operator=(const P&) {
SomeThing* temp = a;
a = new SomeThing(*p.a);
delete temp;
return *this;
}
}
对于析构函数,编译器生成的是non-virtual函数,当涉及到多态基类时,这可能造成“局部销毁的现象”。
因此对于具有virtual函数的类来说,客户需要手动定义一个virtual析构函数,确保在将来调用delete Base* 的时候能够调用正确的析构函数销毁对象。
不要在构造和析构函数过程中调用virtual函数
- 当构造一个派生类时首先调用基类的构造函数,如果基类的构造函数有一个virtual函数,那么此时这个virtual函数版本是基类的而不是派生类的版本,因为派生类还没有被构造呢。
- 从C++对象模型的角度解答
友元
使得在类作用域外部的类或者函数能够直接获取类的private成员。
常用的场景有:重载>> << 运算符,请参考13.15 — Friend functions and classes – Learn C++ (learncpp.com)
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
class Point
{
private:
double m_x{};
double m_y{};
double m_z{};
public:
Point(double x=0.0, double y=0.0, double z=0.0)
: m_x{x}, m_y{y}, m_z{z}
{
}
friend std::ostream& operator<< (std::ostream& out, const Point& point);
friend std::istream& operator>> (std::istream& in, Point& point);
};
// 两个全局函数能够直接获取Point类的private成员变量,因为它们是Point的友元
std::ostream& operator<< (std::ostream& out, const Point& point)
{
// Since operator<< is a friend of the Point class, we can access Point's members directly.
out << "Point(" << point.m_x << ", " << point.m_y << ", " << point.m_z << ')';
return out;
}
std::istream& operator>> (std::istream& in, Point& point)
{
// Since operator>> is a friend of the Point class, we can access Point's members directly.
// note that parameter point must be non-const so we can modify the class members with the input values
in >> point.m_x;
in >> point.m_y;
in >> point.m_z;
return in;
}
如何看待friend?他不破坏封装性吗?
分两个角度看,friend使得友元函数\类能够读取本类的私有属性。但是使用friend暴露的封装性可控。如果不使用友元又要使其他类能够读写本类的数据成员,那么只能将数据成员写成public,这样的封装性破坏更严重!
例子: shared_ptr能够"无障碍"地转换为weak_ptr, 那么必然会有存在一个转换函数,它处于weak_ptr类域中,但是需要直接获取share_ptr的私有成员变量:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
template <typename T>
class weak_ptr {
// shared_ptr转换为weak_ptr的函数:
template<class U>
weak_ptr(shared_ptr<U> const& sp) noexcept
: _ptr{sp._ptr}, // 这里直接获取sp的成员变量,需要shared_ptr将weak_ptr设置成友元类
_control_block{sp._control_block}
{
// ...
}
}
那么shared_ptr据需要将weak_ptr申明为友元:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
template<typename T,
...>
class shared_ptr_access {
friend class weak_ptr;
// ...
private:
element_type* _ptr;
detail::control_block_base* _control_block;
}
当然,unique_ptr也能无障碍地转换到shared_ptr, 也是相同的话术。
char[] 、 char* 和 C++ string implementation (待完成)
首先一个笔试题,看看变量存在那种存储区域中:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
int zero_init_global = 0; // bss 段
int non_init_global; // bss
int init_global = 1; // data 段
char *ptr1; // bss
char char_array_g[] = "234"; // data 段
int main()
{
char char_array[] = "123456"; // 栈, abc\0 一整个在栈上分配,数组名s的值就是字符a在栈上的地址
char *ptr2; // 栈
char *ptr3 = "123456"; // p3在栈,但"123456"存放 rodata 段(只读数据段), 这也是为什么不能通过p3修改字符串的原因
int non_init_local; // 栈
int init_local = 1; // 栈
static int static_zero_init = 0; // bss
static int static_non_init; // bss
static int static_init = 1; // data
ptr1 = (char*)malloc(10);
ptr2 = (char*)malloc(20); // malloc分配得来得10和20字节的数据存放于堆,需要程序员手动管理
strcpy(ptr1,"123456"); // "123456"放在常量区,编译器把函数第二个参数当作指针,该指针的值等于ptr3。
// 这是常见优化(记得JVM也有这种优化),使得编译器不再重复创建相同的字符串,节省空间
}
可以使用nm指令,进行简单的验证(B/b表示变量“存储”在bss段,D/d表示变量存储在data段,大写表示符号全局可见,小写表示符号仅本文件可见)
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
000000000020101c B zero_init_global
0000000000201028 B non_init_global
0000000000201010 D init_global
0000000000201030 B ptr1
0000000000201024 b static_zero_init.2952
0000000000201020 b static_non_init.2953
0000000000201014 d static_init.2954
除了上面的在符号表中出现的变量,我主要对以下三个语句感兴趣:
copy
- 1
- 2
- 3
char char_array_g[] = "234"; // data 段
char char_array[] = "123456"; // 栈, abc\0 一整个在栈上分配,数组名s的值就是字符a在栈上的地址
char *ptr3 = "123456"; // p3在栈,但"123456"存放 rodata 段(只读数据段), 这也是为什么不能通过p3修改字符串的原因
char char_array[] = "123456"; 其实等价于 char char_arra[] = {'1', '2', '3', '4', '5', '6', '\0'}; 所以该语句直接在栈上分配空间以存放字符串"123456"。
char *ptr3 = "123456;"; 就不一样了,ptr3是一个指针变量,由于它在mian函数中申明定义,所以ptr3会存放在栈上,而这跟指针所指向的内存却是在elf文件中的只读数据段中。如何验证?需要用到readelf命令:
copy
- 1
- 2
- 3
- 4
- 5
>$ readelf -S test | grep .rodata
[16] .rodata PROGBITS 00000000000007a0 000007a0
>$ readelf -x 16 test
Hex dump of section '.rodata':
0x000007a0 01000200 31323334 353600 ....123456.
你可以看到在rodata段中有"123456"的内容。
使用同样的手段,你可以看到char_array_g指向的内容存放在data段。
关于数组名和指针
test_a函数接收的参数类型为char a[10],但却退化成指针类型!
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
void test_a(char a[10]) {
cout << sizeof(a) << endl;
}
int main() {
char a[10];
cout << sizeof(a) << endl; // 10
test_a(a); // 8 !
return 0;
}
关于字典序
copy
- 1
- 2
- 3
- 4
- 5
string a("a");
string A("A");
string b("b");
cout << a.compare(A) << endl; // 正数
cout << a.compare(b) << endl; // 负数
尤其注意"a" 和 "A"的比较,前者在ASCI码较大,所以前者比后者大。这与直觉"大写字母比小写字母大"不符
libc++’s implementation of std::string | Joel Laity
strlen和sizeof的区别
sizeof是C语言中的一个单目运算符,用来计算数据类型所占空间的大小,单位为字节;而strlen是一个函数,用来计算字符串长度,它将/0视为一个字符串的结尾,但值得注意的是strlen不将最后的/0计入总长度。
因为sizeof值在编译时确定,所以不能用来得到动态分配(运行时分配)存储空间的大小。
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
int main(){
const char* str = "name";
cout << sizeof(str) << endl; // 取的是指针str的长度,是8
cout << strlen(str) << endl; // 取的是这个字符串的长度,不包含结尾的 \0。大小是4
char char_array[] = "name";
cout << sizeof(char_array) << endl; // 取的是数组的长度为5,注意包括结尾的\0
cout << strlen(char_array) << endl; // 取的是这个字符串的长度4,不包含结尾的 \0。大小是4
return 0;
}
让我感到困惑的是下面这个笔试题:
copy
- 1
- 2
cout << sizeof("hello") << endl; // 输出6
cout << strlen("world") << endl; // 输出5
为什么sizeof("hello")会输出6呢?本以为也会输出8来着,难道“hello”的类型在这里是一个字符数组?
strcpy
strcpy原型声明:
copy
- 1
char *strcpy(char* dest, const char *src);
它将src地址开始且含有null结束符的字符串赋值到以dest开始的地址空间。
不安全, 以前的黑客可以利用该函数的特征会进行缓冲区溢出攻击.
同样的原因strncpy函数也不安全。
推荐使用strcpy_s()函数:
copy
- 1
errno_t strcpy_s( char *restrict dest, rsize_t destsz, const char *restrict src );
其中destsz限制了可使用的缓冲区大小。
inline关键字
内联
inline对函数的修饰,仅仅是对编译器的一个申请,不是强制命令,是否真的要inline,由编译器自行评估。
而且,在class定义内定义的成员函数,都会隐式地加上inline关键字。
inline的好处是消除了函数调用的开销,也有其他的一些我们看不到的编译器在背后做出的优化。
但是也有可能导致一些坏处。
首先,inline在C++中是编译期行为而不是链接期行为,因此在编译器在即将把函数调用替换成inline函数体时,必须看到inline的定义式。因此这也要求inline函数的定义一定被置于头文件内。那么这就很容易导致生成较大的目标文件了,(因为include 的头文件只是单纯地被拷贝)因此可能降低指令缓存的命中率。
其次,inline函数无法随着程序库的升级而升级。如果客户代码使用了程序库的一个inline函数f,一旦程序库的设计者决定改变f,那么客户的所有用到f的代码都要重新编译,而不是仅仅重新链接。
最后,对于调试版本的程序中的inline函数是不可能生效的,因为不可能在一个并不存在函数中设定断点。
此外,对virtual函数加inline也不能生效,因为virtual意味着在运行期再决定调用哪个具体函数,而inline意味着在执行前将调用动作替换成调用函数的调用体,这两个关键词的目标不一致
inline 与 ODR(one definition rule)
C语言下的inline仅仅表示对内联优化的提示,如果多个编译单元存在不止一份inline函数的定义,链接器将发出mutiple definition错误。
做个实验:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
// header.h
extern void fun0();
inline void fun0() {
static int fun0_static = 1;
printf("fun0 in header\n");
fun0_static++;
printf("fun0_static = %d\n", fun0_static);
}
// 1.c
void fun1() {
fun0();
}
extern void fun2();
int main() {
fun1();
fun2();
fun1();
}
// 2.c
void fun2() {
fun0();
}
1.c和2.c都include了header.h ,因此会在两个c文件中重复定义fun0函数,如果就这样编译它,则会出现mutiple definition链接错误:
copy
- 1
multiple definition of `fun0'
说明我们违反了ODR规则。解决的办法就是在inline函数前加上static关键字,这样在两个不同的编译单元之间可以有相同名字的fun0函数:
copy
- 1
- 2
- 3
- 4
- 5
- 6
// header.h
static inline void fun0(); // extern 关键词与inline关键词冲突
static inline void fun0() {
printf("fun0 in header\n");
}
使用nm查看其符号表:
copy
- 1
- 2
- 3
- 4
000000000000063a t fun0
000000000000067d t fun0
0000000000201010 d fun0_static.2250
0000000000201014 d fun0_static.2250
发现有两个fun0函数的实现,它们在内存中的位置不相同。且它们分别各自拥有自己的static local变量!这一点也可以从输出文字发现:
copy
- 1
- 2
- 3
- 4
- 5
- 6
fun0 in header
fun0_static = 2
fun0 in header
fun0_static = 2
fun0 in header
fun0_static = 3
但是在C++中,inline关键词自己就能做到static + inline的效果,
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
// header.h
extern void fun0();
inline void fun0() {
static int fun0_var = 1;
printf("fun0 in header\n");
fun0_var++;
printf("fun0_var = %d\n", fun0_var);
}
// 1.cpp
void fun1() {
printf("fun1 in 2.cpp\n");
fun0();
}
extern void fun2();
int main() {
fun1();
fun2();
fun1();
}
// 2.CPP
void fun2() {
printf("fun2 in 2.cpp\n");
fun0();
}
直接编译是没有链接错误的
copy
- 1
g++ 1.cpp 2.cpp -o exe
使用nm命令查看其符号表,nm exe | c++filt :
copy
- 1
- 2
0000000000000815 W fun0()
0000000000201010 u fun0()::fun0_var
发现它只有一个fun0符号,且该符号为弱符号,链接器在面对多个名字相同的弱符号时只会保留其中一个的定义,这样便只会在最后的可执行文件中存在一份fun0文件,而且该函数中的static 局部变量也只会存在一份,在多个编译单元内操作这个static 局部变量,是对相同的值进行读写,这一点也可以从命令行输出中看出:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
fun1 in 1.cpp
fun0 in header
fun0_var = 2
fun2 in 2.cpp
fun0 in header
fun0_var = 3
fun1 in 1.cpp
fun0 in header
fun0_var = 4
所以,在C++中inline关键词不仅仅有提示编译器进行内联优化的功能,也可以使得某个函数能够在多个编译单元内定义。即在C++中,不加inline的函数或者变量(C++17以后,甚至可以对变量加上inline关键字)在整个程序里只允许有一个定义,而有inline修饰的函数和变量在每一个使用它的翻译单元(translation unit)里都有一处定义
再贴一份CPP Reference上的说法:

模板
参考:
-
effective C++条款41
-
《深入理解C++对象模型》 第七章
-
CppCon BackToBasics: Templates:推荐!非常通俗、且规范的视频资料,解释很多会混淆的术语
-
CppCon Walter E. Brown “C++ Function Templates: How Do They Really Work?”
基本概念
三类模板(不包括C++11之后的各类新型模板):
- 类模板,能够偏特化
- 函数模板,
能够执行类型推导,不能偏特化 - 成员函数模板,
能够执行类型推导,不能偏特化
模板具象化是编译期的行为,因此模板有“编译期多态”的说法。并且相对于显示接口(如class定义的各个public成员函数),模板给出的接口是隐式的,它告诉编译器某个类型T需要怎样的行为。
明确概念:
下图来自CppCon的演讲

模板(Template)只是生成实例的方法,而Specialization(真不知道怎么翻译)则是一个具体的实例。
function template不是一个函数,而它的Specialization则是一个函数。class template同理。
如何从模板得到specialization?有两种方法:
- instantiation, 而它又分成隐式和显示两种
- Explicit specialization(这才是我们平时说的“模板特化”)
生成Specialization的各种方法的关系如下:

隐式实例化(implicit instantiation):由编译器决定将类/函数的实例定义放在哪里(遵循One Definition Rule),且只会实例化类模板用到的一部分成员。比如:
copy
- 1
vector<int> {1,3};
编译器将使用int替换vector模板中的一个模板参数,进行隐式初始化,且只会实例化vector的构造函数、析构函数等与上述代码相关的成员。
又如:
copy
- 1
- 2
- 3
string s1 = ...;
string s2 = ...;
string s3 = max(s1, s2);
编译器将使用string替换相关模板中的一个模板参数进行实例化
显示实例化(explicit instantiation):由程序员手动遵循One Definition Rule,即不能在不同的translation unit中同时显示实例化相同的类模板,使用“extern”关键词避免这个囧境;显示实例化会实例化类模板的所有成员。
copy
- 1
- 2
- 3
- 4
// .cpp文件
template class vector<int> // 显示实例化,编译器将会在本translation unit中生成vector模板的一个具体实例
// .h文件
extern template class vector<int>; // 其他编译单元include该头文件,这样便可遵循ODR
模板的显示特化(explicit specialization)): 能够自定义一个模板在特殊情况下的行为,这才是我们平时说的“模板特化”
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
template <class T1, class T2>
class A{
T1 data1;
T2 data2;
};
// 全特化类模板
template <>
class A<int, double>{
int data1;
double data2;
};
类模板特化又分为全特化和偏特化,而函数模板则不允许偏特化。上面的例子,就是类模板的全特化。
偏特化的“偏”有两种,一种是数量上的偏:
copy
- 1
- 2
- 3
- 4
- 5
- 6
// 第一个参数特化,第二个不特化
template <class T1,class T2>
class A<int, T2>{
int data1;
T2 data2;
};
另一种,则是在“参数范围”上的偏:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
// 参数类型限定为指针
template <class T1, class T2>
class A<T1*,T2*>{
T1* data1;
T2* data2;
};
// 参数类型限定为引用
template <class T1, class T2>
class A<T1&,T2&>{
T1& data1;
T2& data2;
};
// 也可以是个数的偏和类型范围的偏的组合
template <class T1, class T2>
class A<int,T2&>{
int data1;
T2& data2;
};
// 以及等等各种排列组合
template <class T1, class T2>
class A<T1*,T2&>{
T1 data1;
T2& data2;
};
//......
全特化与偏特化的用处
traits技法中非常频繁地使用了模板特化与偏特化。
我们可以使用全特化和偏特化对特定类型做增强处理:

通过模板特化也可以去除变量的CV(const 、volatile)特性,也可以去除参数的引用类型,后者在std::forward中有较大作用:
copy
- 1
- 2
- 3
- 4
template<typename T>
T&& forward(typename remove_reference<T>::type& param){
return static_cast<T&&>(param);
}
remove_reference< T >这个模板类同样可以使用偏特化来实现:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
template <typename T>
class RemoveRef {
using Type = T;
};
template <typename T>
class RemoveRef<T&> {
using Type = T;
};
template <typename T>
class RemoveRef<T&&> {
using Type = T;
};
这样无论原本参数类型如何,最后取内置类型 ::Type后的类型一定不会是值类型而不是引用。
《stl源码剖析》的3.3 - 3.7详细介绍了trais技法,值得一看。
实例化的时机
实际的代码生成将在预处理后,链接之前的某些步骤完成,也就是说目标文件内已经包含了某个或某些specialization的具体代码。
-
当编译器看到类模板的定义\声名时,不会生成任何代码,只会执行一些必要的检查。只有当编译器看到了用户代码在使用一个具体的类之后,才会实例化这个类。什么叫使用?是指在类的尖括号写入了具体类型时,比如这样
copy- 1
- 2
Point<int>::Status s; // 使用Point<int>类的static member Point<double> dp; // 定义了一个Point<double>类的对象注意,上面两行代码分别会使编译器实例化两个Point类,一个是Point< int >,另一个是Point< double >。
如果只是定义一个指针:
copy- 1
Point<float>* ptr = 0;编译器什么都不会做,因为ptr本身只是一个指针,编译器并不需要知道与class有关的任何member数据或对象布局
那么如果定义一个引用呢?
copy- 1
Point< char >& ref = 0;我们知道引用一定要初始化,要被绑定在一个具体对象上。因此,上述语句会导致Point< char >的实例化。编译器实际上产生如下的代码:
copy- 1
- 2
Point< char > temporary(char(0)); // 这行隐式的编译器添加的代码,会导致模板实例化的进行 Point< char >& ref = temporary;
因此定义一个模板类型的引用也会使模板实例化
-
而且,类模板就算是被实例化了,编译器也只选择实例化程序需要的部分!比如:
copy- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
template<typename T> class Widget{ public: Widget() { cout << "Wiget()\n"; } void fun1() { cout << "Widget::fun1()\n"; } void fun2() { cout << "Widget::fun2\n"; } }; int main() { Widget<int> a; a.fun1(); }mian函数中我们只用到了模板类的fun1()函数,那么在可执行文件中只会存在fun1的代码,而fun2()没有被使用,因此不会被实例化。可以用nm指令查找:

不存在Widget<int>::fun2()的符号
-
如果我们只是定义一个模板类,而不使用它,那么在最后的可执行文件中,是不会存在模板函数\类的。或者也可以使用nm指令去查找模板函数符号,你不会看见它,好像它不存在一样。
static 成员
类模板中的static 成员, 在模板中的static成员语句只是申明不是定义,应在实现文件中定义而不是头文件中。为什么?--想想#include

new与malloc的区别
new 是操作符 malloc 是库函数
new在调用时会先为对象分配内存,再调用构造函数, malloc不会
malloc 为对象指针分配内存时,要明确指定分配内存的大小,而new不需要
new作为操作符可以被重载 而malloc 不可以
new分配内存成功返回对象指针 malloc返回 void* 类型指针
new分配失败 会抛出异常bad-alloc malloc 则会返回空指针
new从自由存储区为对象分配内存 ; malloc 从堆区分配内存
各种new
- 普通的new
- array new
- nothrow new ,内存分配失败时,不抛出异常而是返回nullptr
- palcement new
基础语法-41-60 | 阿秀的学习笔记 (interviewguide.cn)
关于C++的内存管理,我也另外整理了一偏文章:CPP内存管理 - 别杀那头猪 - 博客园 (cnblogs.com)
实现单例模式
参考资料:
【1】https://www.cnblogs.com/sunchaothu/p/10389842.html
【2】https://www.cnblogs.com/god-of-death/p/7846152.html
【3】面试情景剧 : https://www.cnblogs.com/loveis715/archive/2012/07/18/2598409.html
【5】C++11检测锁的正确实现 https://preshing.com/20130930/double-checked-locking-is-fixed-in-cpp11/
回顾《程序员的自我修养》一书时,对书第一张中提到的“需要加入内存屏障才能实现thread safe的双检测锁的单例模式”感到困惑。
首先书是对的,请看【4】对这一方法的讨论,水很深,我在查资料时一路查到了cache缓存一致性的问题。在这里整理一下,但不保证正确。
懒汉式单例模式
双检测锁的一个实现:参考【1】:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
// 头文件
class Singleton{
public:
typedef std::shared_ptr<Singleton> Ptr;
~Singleton(){
std::cout<<"destructor called!"<<std::endl;
}
Singleton(Singleton&)=delete;
Singleton& operator=(const Singleton&)=delete;
static Ptr get_instance(){
// "double checked lock"
if(m_instance_ptr==nullptr){
std::lock_guard<std::mutex> lk(m_mutex);
if(m_instance_ptr == nullptr){
m_instance_ptr = std::shared_ptr<Singleton>(new Singleton);
}
}
return m_instance_ptr;
}
private:
Singleton(){
std::cout<<"constructor called!"<<std::endl;
}
static Ptr m_instance_ptr;
static std::mutex m_mutex;
};
// 源文件
// initialization static variables out of class
Singleton::Ptr Singleton::m_instance_ptr = nullptr;
std::mutex Singleton::m_mutex;
int main(){
Singleton::Ptr instance = Singleton::get_instance();
Singleton::Ptr instance2 = Singleton::get_instance();
return 0;
}
有几个注意点:
-
为什么双检测,单检测不行?--这是效率上的一个考量,只有第一次函数执行需要使用锁,此后的函数调用都不不需要锁了。
-
使用共享型智能指针管理资源,防止内存泄漏
-
类外的static 变量初始化为nullptr
-
将构造函数申明为private,将拷贝构造和赋值构造函数标记为delete,杜绝任何单例对象被复制的可能
双检测锁的缺陷:见【4】双检测锁的缺陷--scott meyers
它并不是线程安全的,主要原因在于 PTR pInstance = new singletonIstace 这个动作不是原子的, 它会分解为三个动作:先分配内存,然后在该内存上构造对象,最后将地址赋值给指针:
copy
- 1
- 2
- 3
pInstance = // Step 3
operator new(sizeof(Singleton)); // Step 1
new (pInstance) Singleton; // Step 2
但是由于编译器或者CPU的指令优化,很有可能step3比step2提前,此时pTnstance != nullptr,但它指向的对象并不完整!此时,操作系统调度另一个线程调用方法,第一层判断pinstance指针不为null,然后就返回了这个不完整的单例对象指针,这会导致未定义错误。
能够添加volatile关键字消除这种错吗?--不能,见volatile关键字。我们需要“内存屏障”
在双检测锁的实现上,只有C++11版本以上,才能提供可移植的代码实现,见【5】
scott meyers提出的单例模式: 使用局部静态变量
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
class Singleton
{
public:
~Singleton(){
std::cout<<"destructor called!"<<std::endl;
}
Singleton(const Singleton&)=delete;
Singleton& operator=(const Singleton&)=delete;
static Singleton& get_instance(){
static Singleton instance;
return instance;
}
private:
Singleton(){
std::cout<<"constructor called!"<<std::endl;
}
};
int main(int argc, char *argv[])
{
Singleton& instance_1 = Singleton::get_instance();
Singleton& instance_2 = Singleton::get_instance();
return 0;
}
只有在C++11以上的版本,它能够保证线程安全,有以下特性保障:
If control enters the declaration concurrently while the variable is being initialized, the concurrent execution shall wait for completion of the initialization.
如果当变量在初始化的时候,并发同时进入声明语句,并发线程将会阻塞等待初始化结束。
饿汉式单例模式
参考【2】:
copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
//头文件
class Singleton
{
public:
static Singleton& Instance() //Instance()作为静态成员函数提供里全局访问点
{
return instance;
}
private:
Singleton(); //这里将构造,析构,拷贝构造,赋值函数设为私有,杜绝了生成新例
~Singleton();
Singleton(const Singleton&);
Singleton& operator=(const Singleton&);
static Singleton instance;
};
//源文件
Singleton Singleton::instance;
与懒汉模式的双检测锁的区别:
- 懒汉模式在main函数执行之前初始化 Singlton对象,饿汉模式则初始化为null指针
因为在main之前初始化,因此没有线程安全问题。但是潜在问题是:non-local static对象的在不同编译文件中的初始化顺序是未定义的,见《Effective C++》P30:如果一个编译单元的non local static对象的初始化依赖另一个编译单元的non local static 对象,那么这个依赖的对象可能是未初始化的。
解决这个问题的方法是,懒汉模式的meters单例(看上一节)
本文作者:别杀那头猪
本文链接:https://www.cnblogs.com/HeyLUMouMou/p/17304387.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步