防止过拟合方式的一些理解(Regularization,Data Augmentation)
Regularization(正则化):
定义:

任何减少泛化误差而不减少训练误差的行为。
(也就是可以增强对新数据的适配性,不会因为对原数据集拟合过度,导致对新数据的判断能力下降)
种类:
1. L2正则化( Weight Decay(权重衰减),Ridge Regression(岭回归) )
L2带有正则化的损失函数(平方项):
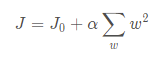
(J0为原来的损失函数,惩罚项是w2求和,这里的w指的就是原来的各项指标(系数),α是正则化参数)
添加惩罚项的原因:
为了防止函数过拟合,添加惩罚项来”矫正“函数的形状,举个例子,如下图:
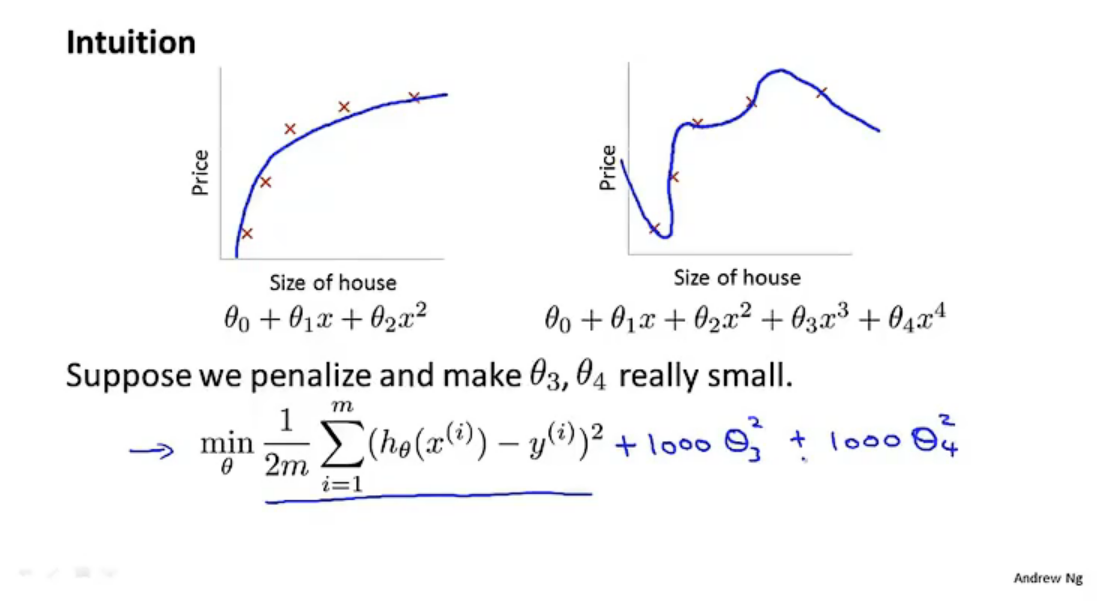
这里我们看到x3和x4两项导致了函数的过拟合,那么我们这个时候应当舍弃它们,也就是将θ3和θ4趋向于0。我们的做法就是在损失函数中给加上两个θ3和θ4的自带很大常数项的项,那么在训练的过程中, θ3和θ4由于常数项过大,就会自行缩小,逐渐逼近于0。
L2正则化的损失函数如下图所示:
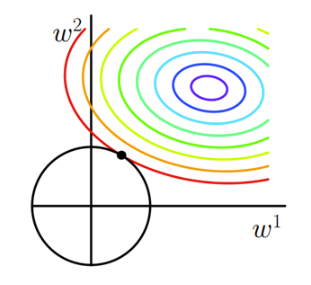
图中彩色多圈的圆是原来未加L2正则化项的损失函数,黑色的圆是正则化项(在这张二维图里就是α = w12 + w22)。与找到最低点(也就是图中的紫圈)不同的是,我们需要找到黑圈和彩圈的之和的最小值,如果这个时候再去找紫圈,那么经过紫圈的黑圈就会画的非常大,也就是α会非常大,那么二者的总和也就无法达到最小。为了达到折中的目的,可以证明(不知道怎么证明)两图恰好相交(相切)的某一个点就是总的loss最小的点。
2. L1正则化( 稀疏回归,Lasso Regression(Lasso回归) )
L1带有正则化的损失函数(绝对值项):
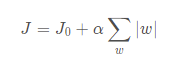
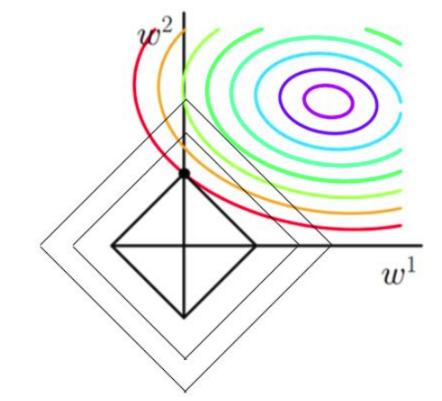
理由如上,可以找到最小值点。不难发现,一个有棱有角的图形和原来损失函数相切的点往往在坐标轴上(维度更高也是如此),这也就说明某些w在最优解的时候会是0,这也就是我们所说的稀疏解(稀疏解就是某些系数为0),这种模型的泛化能力一般更强(不过具体应用我还不知道)。
Data Augmentation(数据增广):
可以理解为扩充数据集的大小以此发现各个数据之间的共性,减少一些特殊化的参数,使得模型的能力更强。
具体地,可以有如下操作:(简单看看就可以)
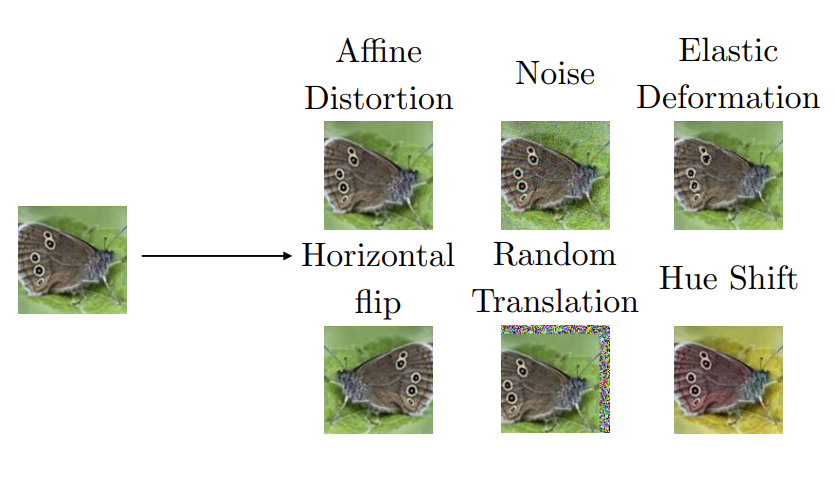
仿射变换、噪声、弹性变换、水平翻转、随机平移、色调变换......
Multi-Task Learning(多任务学习):
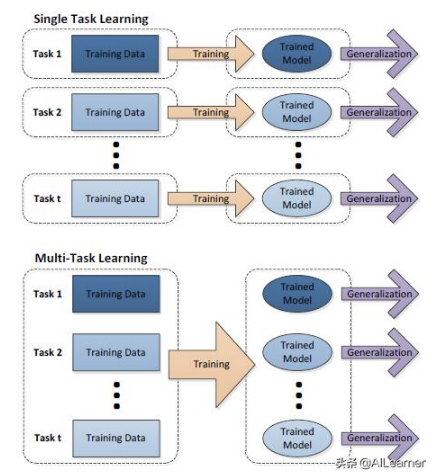

现实世界中很多问题不能分解为一个一个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。把现实问题当做一个个独立的单任务处理,忽略了问题之间所富含的丰富的关联信息。
把多个相关(related)的任务(task)放在一起学习,从而共享一些因素和所学习到的信息,增强泛化能力。
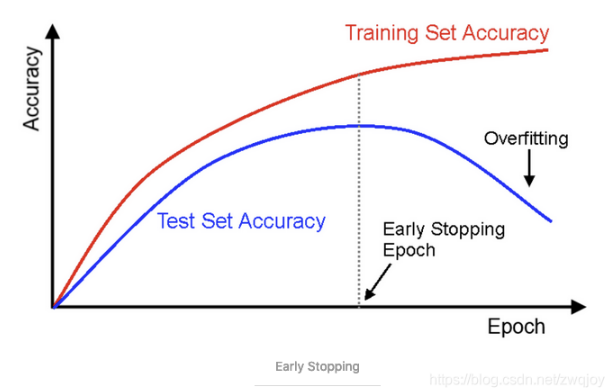
Learning Curves(绘制学习曲线):
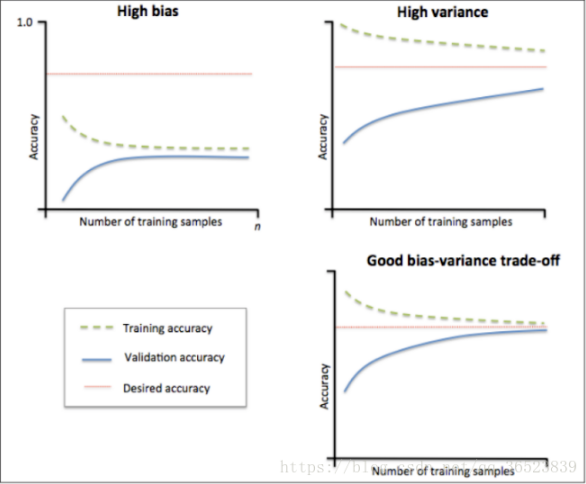
通过绘制学习曲线来判断是否过拟合,如图1,第一张图显示bias较大,准确率小于我们的期望准确率(也就是红色那条线),因此属于欠拟合;第二张图的训练准确率高于期望准确率,测试准确率低于期望值,而且两者差距较大,因此属于过拟合;第三张图做了很好的权衡,是合理的。
根据学习曲线我们可以判断应当做什么调整。
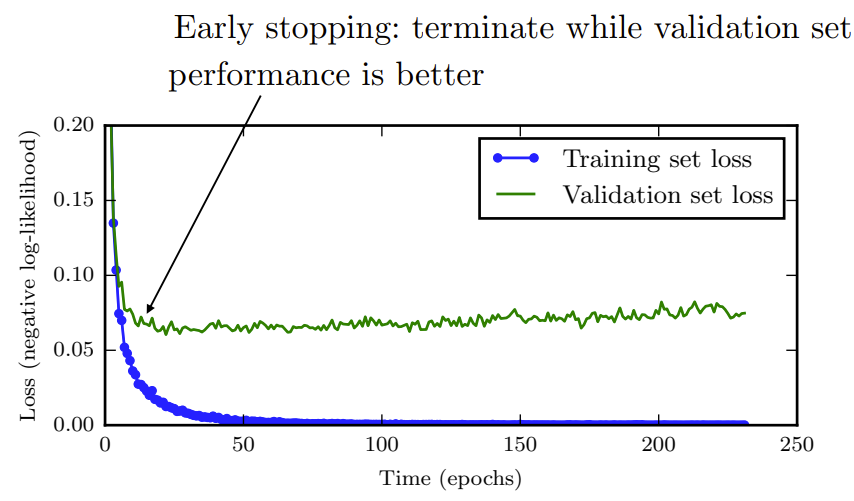
Early Stopping(早停法):
原理:每个epoch结束后(或每N个epoch后): 在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练。
因为精度都不再提高了,在继续训练也是无益的,只会提高训练的时间。
Sparse Representations(稀疏表示):
定义:用一个稀疏向量以及一个过完备字典矩阵相乘来表示某个信号。
(稀疏向量是指让0尽可能多的向量,过完备字典是指和向量有多种组合方法来表示信号的某个矩阵。)
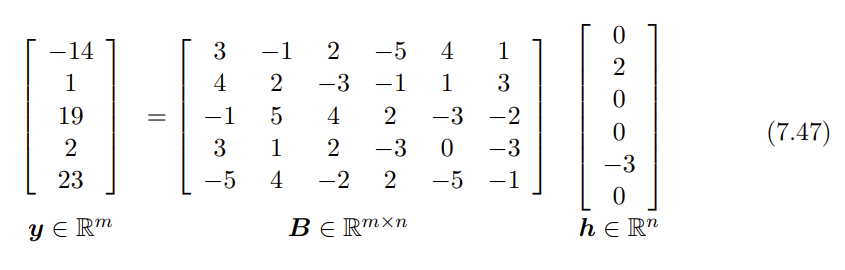
如上图,此向量(信号)可以用一个过完备字典矩阵和一个稀疏向量相乘来表示。
同样的思路,稀疏的表示能够减少一定的不必要特征,找到共性,从而避免过拟合。如下图,虽然比较粗糙和损失特征,但是可以明显看出是一辆跑车。

Bagging(引导聚集算法(装袋算法)):
思路:对于给定的训练样本S,每轮从训练样本S中采用有放回抽样(Booststraping)的方式抽取M个训练样本,共进行n轮,得到了n个样本集合,需要注意的是这里的n个训练集之间是相互独立的。对于这n个样本集合,给定一个弱学习算法进行判断,最后根据投票来确定最终的预测结果,准确率也将提高。
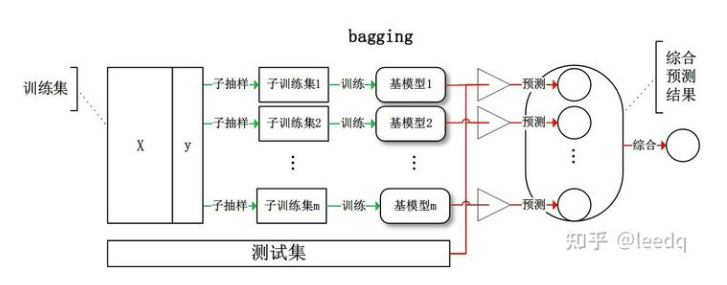
举例:
下图中随机抽取了两组数据,分别进行判断,第一组数据判断是8(根据8的上半部分和6区别进行判断),第二组判断也是8(根据8的下半部分和9区别进行判断)。根据投票结果,最终预测结果也就是8.
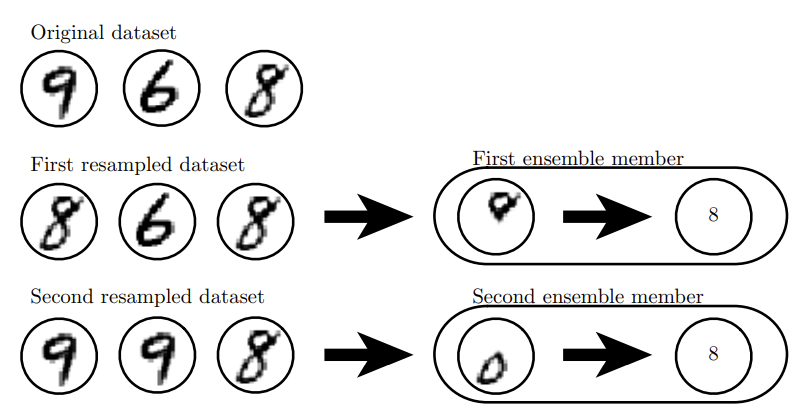
“Bagging是通过结合几个模型降低泛化误差的技术。主要想法是分别训练几个不同的模型,然后让所有模型表决测试样例的输出。 这是机器学习中常规策略的一个例子,被称为模型平均(modelaveraging)。采用这种策略的技术被称为集成方法。模型平均(model averaging)奏效的原因是不同的模型通常不会在测试集上产生完全相同的误差。模型平均是一个减少泛化误差的非常强大可靠的方法。”
Dropout(随机失活):
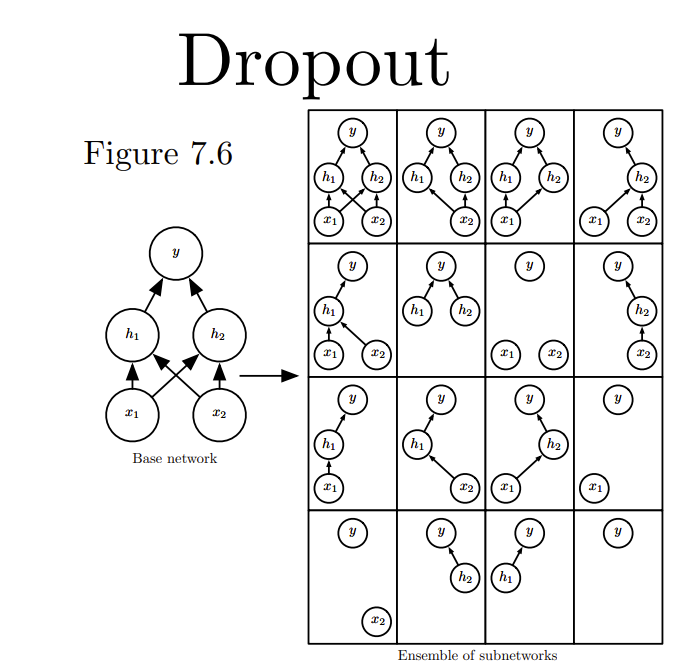
思路:随机(临时)删掉网络中一部分的神经元,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b),然后继续重复这一过程:
- 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
- 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
- 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
重复这一过程。
- (来自:知乎Microstrong)

2、 增强神经元共适应关系,防止某个特征只有在与另一个特征共存时才有效果。
Adversarial Examples(对抗样本):
通过故意添加细微的干扰所形成的输入样本(对抗样本),模型以高置信度给出了一个错误的输出。这也是泛化能力弱的一种体现。

(添加了细微的干扰,导致熊猫被识别为了长臂猿)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号