LLVM学习笔记
本来说暑假就学完llvm + ollvm的,这下笑嘻了。
这篇blog是为了后续混淆学习打基础的。
reference: https://www.kanxue.com/book-section_list-88.htm,钱包-199
安装
LLVM是一种模块化的编译器框架,命名最早源自于底层虚拟机(Low Level Virtual Machine)的首字母缩写。
先安装再说
- Ubuntu 20.04
- LLVM 12.0.1
- CMake 3.24.2
在release界面下载源码
然后创建一个你想要放llvm的路径,我是/home/llvm/Programs/llvm-project,在这个文件夹里解压两个源码包,分别命名为llvm和clang,然后把两个文件夹放进build文件夹,大概是下面这个样子
然后在build内打开终端输入下面这些东西进行源码的编译
cmake -G "Unix Makefiles" -DLLVM_ENABLE_PROJECTS="clang" -DCMAKE_BUILD_TYPE=Release -DLLVM_TARGETS_TO_BUILD="X86" -DBUILD_SHARED_LIBS=On ../llvm
make
make install
(我大概跑了3个多小时吧...
安装完成后,使用clang -help进行测试,若没有报错则说明安装成功
一些错误的解决方法
-
如果在clang -help时报错:clang: error while loading shared libraries: libtinfo.so.5: cannot open shared object file: No such file or directory
应该是系统路径的原因,建议使用sudo find / -name libtinfo.so.5,找到一个该文件后复制其路径,然后sudo ln -s [刚刚找到的文件路径] /usr/local/llvm/lib/libtinfo.so.5
-
如果在clang -help时报错exec format error,那你应该去github上找找对应自己系统的llvm的下载链接,而不是使用本文的下载链接,然后删除现在的llvm并重新安装
简介
我主要是看IR和PASS
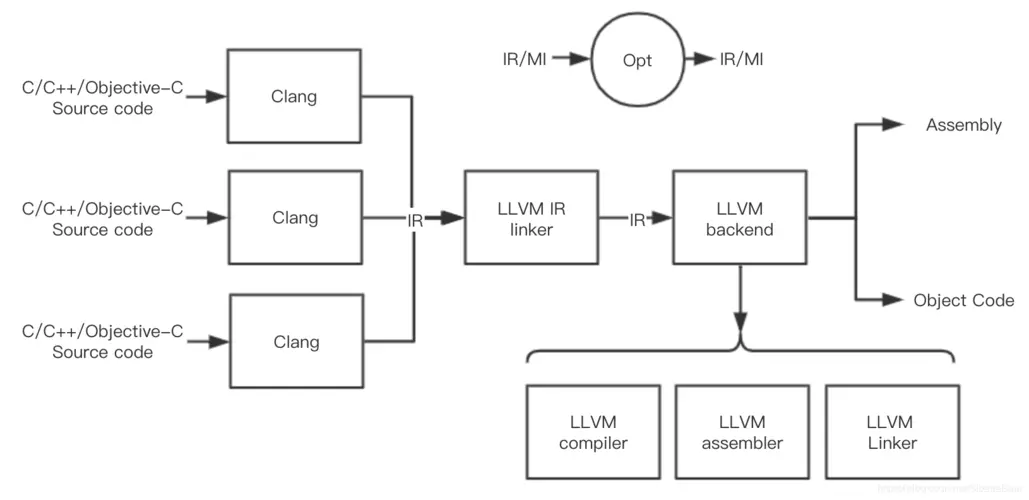
我们知道,传统的编译过程大概可分为两个步骤:把源代码翻译成中间表示(IR),把IR翻译成机器码(或者由解释器来解释执行)。这三个层次也就是前端、中端、后端。
GCC编译器在设计时没有做好层次划分,你不能知道它的IR是什么样子的,它也不会提供接口让你操作IR,这导致了其前端后端的大量数据耦合在了一起。这样一来,GCC就很难支持新的编程语言或者架构。
如果有一个大家都使用的开放的IR,那么每种新语言只需要一个新前端,每个新平台只需要一个新后端,这就比GCC方便的多。LLVM就是这一种项目。LLVM IR本质上一种与源编程语言和目标机器架构无关的通用中间表示,是LLVM项目的核心设计和最大的优势。
然后这里还出现了Clang。Clang是基于LLVM的编译器驱动,他可以把C/C++/OC等源码翻译成LLVM IR的前端,并经由LLVM的库成功由IR到后端。
更多介绍可以移步官方文档
LLVM的基本用法
LLVM有三种表示,分别是
- .ll格式:给人看的版本,是一种可读的IR,类似于汇编代码,但其实它介于高等语言和汇编之间
- .bc格式:不可读的二进制IR,被称作位码(bitcode),用来给机器存储
- 内存表示,只保存在内存中,所以谈不上文件格式和文件后缀
可以通过llvm-as和llvm-dis两个指令来在前两种文件之间做转换(可以从指令的名字中看出来LLVM IR确实是把.ll看做汇编,.bc看做机器码)
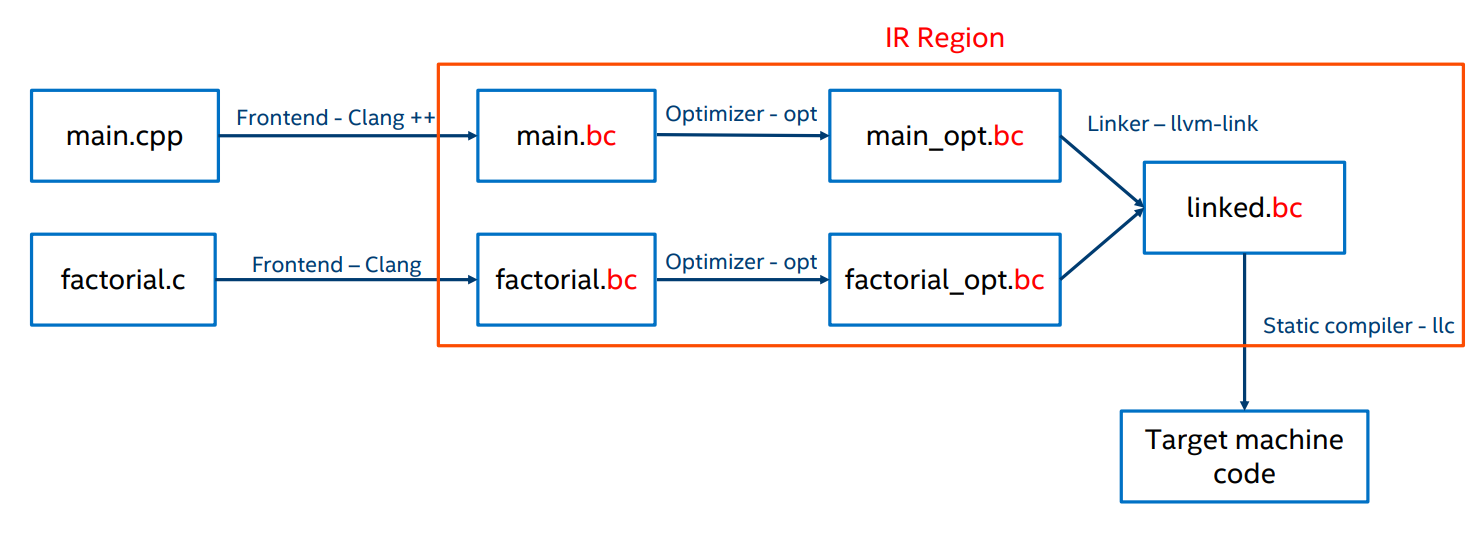
这里给出了一次具体的编译过程。main.cpp和factorial.c各自经过前端Clang翻译变成中间代码.bc文件,随后.bc各自经过优化器进行优化,得到优化后的代码main_obt.bc和factorial_opt.bc,这两个文件经过LLVM IR层面的链接器(llvm-link)合并为一个中间代码文件linked.bc,最后经过静态编译器(llc)进行编译,得到目标平台的机器代码。
注意一下Linker,为了实现链接时优化,LLVM在前端(Clang)生成单个代码单元的IR后,将整个工程的IR都链接起来,同时做链接时优化。之后的compiler只编译LLVM IR。
手动编译一次试试
简单尝试一下编译这个hello.cpp
#include <cstdio>
void Hello()
{
printf("Hello, World!\n");
return;
}
int main()
{
Hello();
return 0;
}
先试试.ll格式的
clang -S -emit-llvm hello.cpp -o hello.ll
然后出来大概是这样的
; ModuleID = 'hello.cpp'
source_filename = "hello.cpp"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@.str = private unnamed_addr constant [15 x i8] c"Hello, World!\0A\00", align 1
; Function Attrs: mustprogress noinline optnone uwtable
define dso_local void @_Z5Hellov() #0 {
%1 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([15 x i8], [15 x i8]* @.str, i64 0, i64 0))
ret void
}
declare dso_local i32 @printf(i8*, ...) #1
; Function Attrs: mustprogress noinline norecurse optnone uwtable
define dso_local i32 @main() #2 {
%1 = alloca i32, align 4
store i32 0, i32* %1, align 4
call void @_Z5Hellov()
ret i32 0
}
attributes #0 = { mustprogress noinline optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
attributes #1 = { "frame-pointer"="all" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
attributes #2 = { mustprogress noinline norecurse optnone uwtable "frame-pointer"="all" "min-legal-vector-width"="0" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" }
!llvm.module.flags = !{!0, !1, !2}
!llvm.ident = !{!3}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{i32 7, !"uwtable", i32 1}
!2 = !{i32 7, !"frame-pointer", i32 2}
!3 = !{!"clang version 13.0.1"}
然后试试.bc
clang -c -emit-llvm hello.cpp -o hello.bc
这下我反正看不懂了
然后应该用opt对LLVM IR进行优化了
opt -load LLVMObfuscator.so -hlw -S hello.ll -o hello_opt.ll
LLVMObfuscator.so在下面LLVM Pass的手操里面有,是通过cmake make编译出来的一个玩意
- -load 加载特定的 LLVM Pass (集合)进行优化(通常为.so文件)
- -hlw 是 LLVM Pass 中自定义的参数,用来指定使用哪个 Pass 进行优化
最终可以将LLVM IR编译为可执行文件了
clang hello_opt.ll -o hello,直接用clang就行
LLVM PASS
LLVM Pass 框架是整个LLVM提供给用户用来干预代码优化过程的框架,也是我们编写代码混淆工具的基础。
编译后的LLVM Pass(一般是.so文件)通过优化器opt进行加载,可以对LLVM IR中间代码进行分析和修改,生成新的中间代码。
同时,LLVM Pass也为开发者提供了丰富的API用于实现中间代码的分析与修改。
来了解一下llvm项目里面的目录文件夹
- llvm/include/llvm: 存放了LLVM提供的公共头文件,也就是编程时使用的
- llvm/lib: 存放了LLVM的大部分源码以及一些不公开的文件夹,在想要了解函数等运行原理时很有用
- llvm/lib/Transform: 存放了所有LLVM的源代码,以及一些自带的PASS
尝试编写一个简单的PASS
目标是编写一个LLVM PASS,遍历程序中的所有函数,并输出"Hello, " + 函数名。我们考虑通过CMake对Pass进行单独编译。
理论准备
LLVM有多种类型的Pass可供选择,包括: ModulePass(基于模块)、FuncitonPass(基于函数)、CallGraphPass(基于调用图)、LoopPass(基于循环)等,我们集中于FunctionPass,因为后续学习的混淆基本都是基于这个玩意的。
FunctionPass是以函数为单位进行处理的,其子类必须实现runOnFunction这个函数,并且在Pass执行时会对每一个函数执行一次runOnFunction函数。这意味着我们可以在该函数内写一些关于IR的玩意。
在编写我们想要实现的简单pass时,大概步骤是:
- 创建一个类,继承FunctionPass父类
- 在创建的类中实现runOnFunction函数
- 向LLVM注册我们的Pass类
手操
首先需要在vscode上配置remote - ssh插件,并且在虚拟机上安装好ssh服务
可参考https://blog.csdn.net/weixin_44260459/article/details/121772911
在这个文件夹里创建一个OLLVM++文件夹,来保存这次的项目,然后在本机的vscode上使用remote - ssh插件连接到虚拟机,并且打开这个文件夹,在OLLVM++文件夹中创建Build和Test文件夹,后续分别用于储存编译后 LLVM Pass以及测试程序。
在Test文件夹内新建文件TestProgram.cpp,作为测试文件,代码如下
#include <cstdio>
#include <cstring>
#include <cstdlib>
char input[100] = {0};
char enc[100] = "\x86\x8a\x7d\x87\x93\x8b\x4d\x81\x80\x8a\
\x43\x7f\x49\x49\x86\x71\x7f\x62\x53\x69\x28\x9d";
void encrypt(unsigned char *dest, char *src){
int len = strlen(src);
for(int i = 0;i < len;i ++){
dest[i] = (src[i] + (32 - i)) ^ i;
}
}
//flag{s1mpl3_11vm_d3m0}
int main(int argc, char *argv[]){
printf("Please input your flag: ");
scanf("%s", input);
unsigned char dest[100] = {0};
encrypt(dest, input);
bool result = strlen(input) == 22 && !memcmp(dest, enc, 22);
if(result){
printf("Congratulations~\n");
}else{
printf("Sorry try again.\n");
}
}
然后在OLLVM++下创建文件夹Transforms,其内容如下
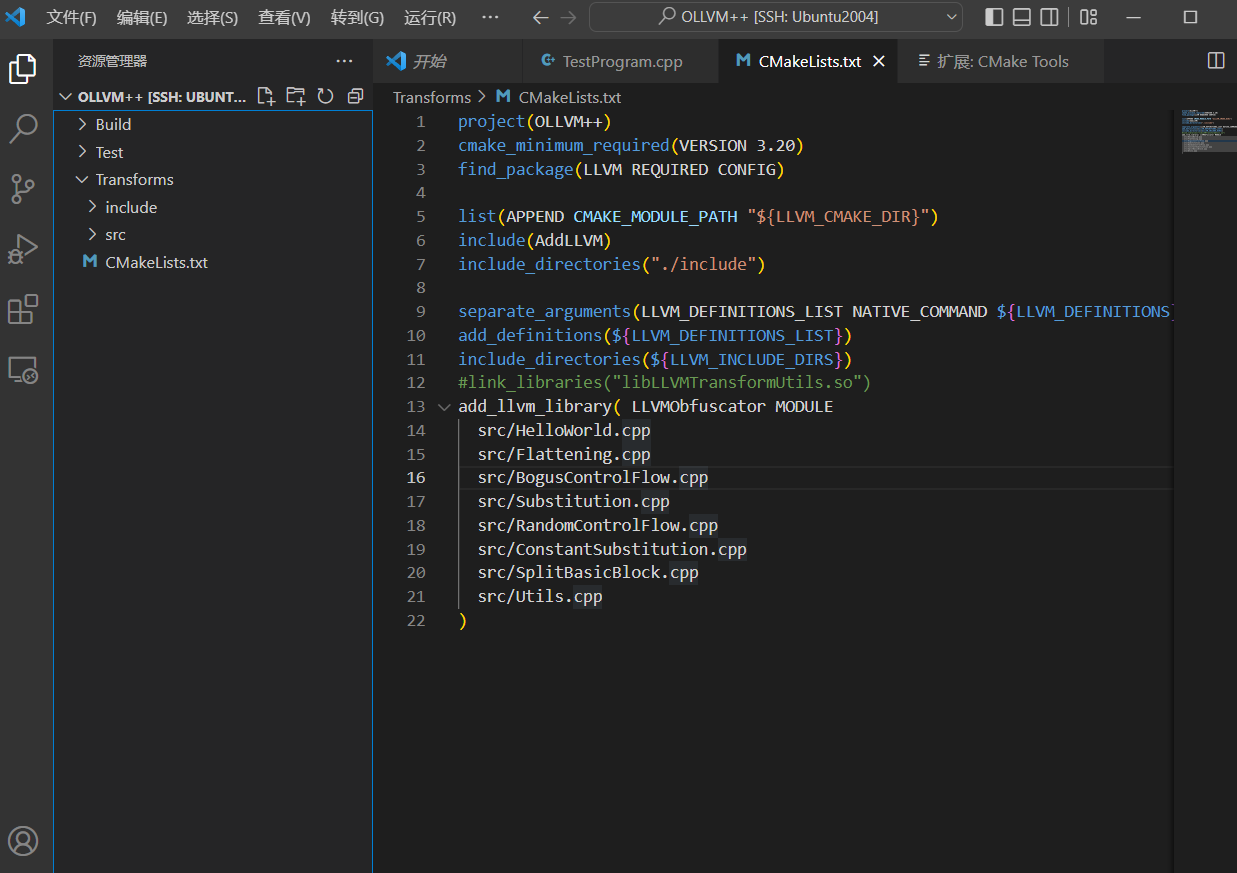
- include文件夹存放LLVM Pass项目的头文件,现在用不上
- src文件夹存放LLVM Pass项目的源代码
- CMakeLists.txt是CMake项目的配置文件
配置文件如下
project(OLLVM++) # 指定了项目的名称
cmake_minimum_required(VERSION 3.13.4) # llvm最低要求是3.13.4
find_package(LLVM REQUIRED CONFIG)
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}")
include(AddLLVM) # 上面是和环境有关的一些配置
include_directories("./include") # 指定项目的包含文件夹,后续可以导入该文件夹的头文件
separate_arguments(LLVM_DEFINITIONS_LIST NATIVE_COMMAND ${LLVM_DEFINITIONS})
add_definitions(${LLVM_DEFINITIONS_LIST})
include_directories(${LLVM_INCLUDE_DIRS}) # 配置项
#link_libraries("libLLVMTransformUtils.so")
add_llvm_library( LLVMObfuscator MODULE # 向llvm中注册一个叫LLVMObfuscator的.so文件
src/HelloWorld.cpp # 这个就是Pass的源代码
)
现在,在src文件夹内新建一个Hello World.cpp,这就是我们今天的主要目标
(以后也可以拿这玩意当一个模板来看,要写pass就在这个框架里面加东西就行)
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
using namespace llvm;
namespace {
class HelloWorld : public FunctionPass{
public:
static char ID;
HelloWorld() : FunctionPass(ID) {}
bool runOnFunction(Function &F);
};
}
bool HelloWorld::runOnFunction(Function &F){
outs() << "Hello, " << F.getName() << "\n";
// outs()获取整个输出流,和cout差不多
// F.getName()获取函数名称
}
char HelloWorld::ID = 0; // 初始化ID
static RegisterPass<HelloWorld> X("hlw", "My first line of LLVM Pass.");
// 向LLVM注册我们的Pass
// 前面一个变量是LLVM Pass的参数(opt的时候用他来指定),后面一个是对该参数的描述
然后写一个shell来编译(test.sh)
cd ./Build
cmake ../Transforms
make
cd ../Test
clang -S -emit-llvm TestProgram.cpp -o TestProgram.ll
opt -load ../Build/LLVMObfuscator.so -hlw -S TestProgram.ll -o TestProgram_hlw.ll
clang TestProgram_hlw.ll -o TestProgram_hlw
./TestProgram_hlw
运行一下看看效果
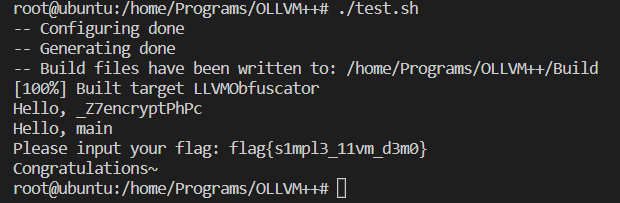
可以看到,在opt优化的过程中终端输出了两行Hello加上函数的名字,这说明我们的Hello World的Pass运行成功了。并且在最后执行了Test程序,这说明我们的编译也没有出问题。
LLVM IR
首先可以看看官方的一个入门引导,英语好的爹可以直接去听一下讲这个PPT的会议。
我就是看这些玩意看吐了才去买的🌏👴的网课
概述
前面我们尝试了写一个pass,但是我们并没有真正的深入理解如何对中间代码进行优化。在LLVM的编译过程中,其优化是基于中间代码LLVM IR的,现在我们进行对IR的学习,为后续代码混淆的学习打好基础。
LLVM IR是一种低级的编程语言,其语法类似于汇编语言,任何高级的编程语言(如c++)都可以用LLVM IR进行优化。如果我们把这些语言都用LLVM IR表示,那么我们可以很方便地进行优化。
我们已经了解过,LLVM IR有两种表示方法:.ll和.bc,并且可以通过llvm-as和llvm-dis两个指令来在前两种文件之间做转换。
在源代码被编译为LLVM IR后,将会具有如下结构:
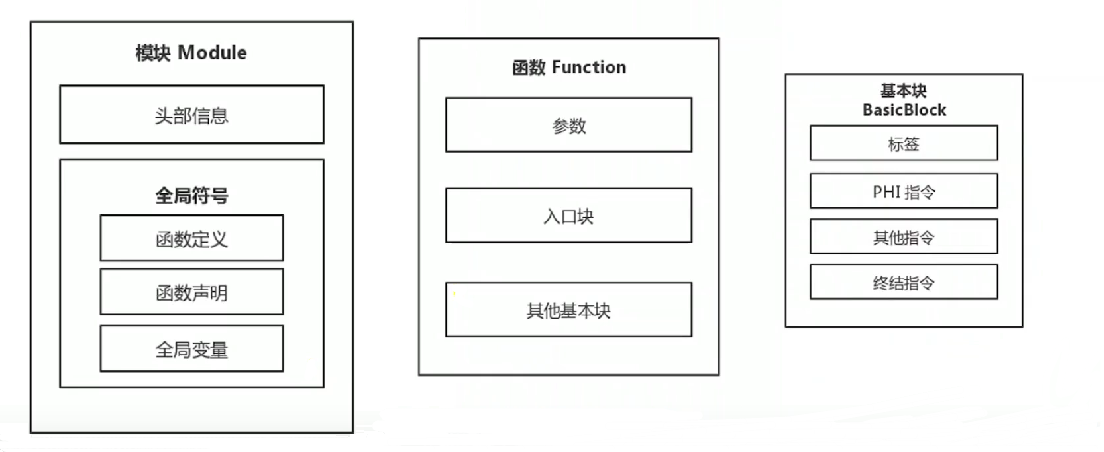
一个源码文件对应LLVM IR中的一个模块。其中,头部信息包含程序的目标平台,如x86,ARM等以及一些其他信息。头部信息由编译器自动生成。全局符号包含函数定义、函数声明以及全局变量,
LLVM IR中的函数表示源代码中的某个函数,这两个“函数”基本上是同一个概念。参数就是函数的参数,函数由若干个基本块组成,其中函数最先执行的基本块为函数的入口块。入口块可以跳转到其他的基本块进行执行。
关于基本块,一个基本块由若干个指令和标签组成,在正常情况下,基本块的最后一条指令为跳转指令(IR中的br或者switch指令),或者返回指令(retn,和c中的return差不多)。这一类指令也叫终结指令(Terminator Instruction)。
除了这些指令,基本块中还有其他的指令,比如PHI指令等。
我们用IDA来类比记忆一下。模块、函数块和基本块的概念可以类比到IDA的Graph View界面。把程序拖进IDA后就可以把他理解为一个模块,一个模块中有若干个函数,就对应IDA的函数列表界面。IDA的Graph View界面可以看到函数的控制流图,一个控制流图由若干个代码块和一些跳转关系组成,图中的代码块可以和LLVM IR中的基本块对应。
基于LLVM的混淆,通常是以函数或者比函数更小的单位为基本单位进行混淆的,我们通常更关心函数和基本块这两个结构。模块这个结构用到的较少。
LLVM IR是学代码混淆的基础,例如:
- 以函数为基本单位的混淆:控制流平坦化
- 以基本块为基本单位的混淆:虚假控制流
- 以指令为基本单位的混淆:指令替代
指令详解
终结指令 Terminator Instructions
在前面提到过,终结指令一般是基本块中的最后一条指令,通常是跳转或返回指令,他们会跳转到下一个基本块继续执行,或者直接从当前执行的函数中返回。
ret
ret指令是函数的返回指令,对应c中的return。ret指令语法如下
ret <type> <value> ; 返回特定类型返回值的return指令
ret void ; 无返回值的return指令
第一类是携带返回值的ret指令,需要指定返回值的类型与值。第二类是无返回值的ret指令,他直接返回一个void,也就是空值。
举个例子
ret i32 5 ; 返回整数 5
ret void ; 无返回值
ret { i32, i8 } { i32 4, i8 2 } ; 返回一个结构体
br
br是”分支”的英文branch的缩写,分为非条件分支和条件分支,对应C/C++的if语句。
无条件分支类似于x86汇编中的jmp指令,条件分支类似于jz/jnz, je/jne等条件跳转指令。
br指令语法如下
br i1 <cond>, label <iftrue>, <label> <iffalse> ; 条件分支
br label <dest> ; 非条件分支
第一类是条件分支,条件分支中需要指定一个条件,其类型为i1,也就是一位整数, 可以理解为bool类型。若为true,则会跳转到第一个标签iftrue对应的基本块,否则跳转到第二个标签iffalse对应的基本块。
第二类是非条件跳转,他会直接跳转到dest对应的基本块。
举个例子
Test:
%cond = icmp eq i32 %a, %b
br i1 %cond, label %IfEqual, label IfUnequal
IfEqual:
ret i32 1
IfUnequal:
ret i32 0
首先是一个条件跳转。条件是icmp指令的运算结果cond。这里的意思是比较a和b是否相等,相等为true否则为false。br指令会根据cond的值进行跳转,cond为true则跳转到基本块IfEqual,该基本块会返回一个值1,cond为false则跳转到基本块IFUnequal,该基本块会返回一个值0。
另:比较指令
另外说一下比较指令,在x86汇编中条件跳转指令(jz,je等)通常与比较指令(cmp,test等)一起出现
在LLVM IR中也有这种指令:icmp等,他们通常与br一起出现
cmp指令也分两类,第一种是icmp指令,一般是整数或指针的比较指令,语法如下
<result> = icmp <cond> <ty> <op1>, <op2> ; 比较整数op1和op2是否满足条件cond
icmp首先要指定条件的类型,这里的条件cond可以是eq(相等),ne(不相等),ugt(无符号大于)等
然后还需要指定比较数的类型ty,例如32位整数i32等。
举个例子
<result> = icmp eq i32 4, 5 ; yields: result=false eq=equal
<result> = icmp ne float* %X, %X ; yields: result=false ne=not equal
<result> = icmp ult i16 4, 5 ; yields: result=true ult=unsigned less than
<result> = icmp sgt i16 4, 5 ; yields: result=false sgt=signed greater than
<result> = icmp ule i16 -4, 5 ; yields: result=false ule=unsigned less or equal
<result> = icmp sge i16 4, 5 ; yields: result=false sge=signed greater or equal
float*就是浮点型指针,其他的很明显了
第二种是fcmp指令,这里的f是float,也就是浮点数的意思。其语法与icmp十分相似
<result> = fcmp <cond> <ty> <op1>, <op2> ; 比较两个浮点数是否满足条件cond
不同点在于其条件cond与icmp不太一样。这里条件可以是oeq(ordered and equal),ueq(unordered or equal),false等。这里order是指两个操作数都不为NAN
举个例子
<result> = fcmp oeq float 4.0, 5.0 ; yields: result=false
<result> = fcmp one float 4.0, 5.0 ; yields: result=true
<result> = fcmp olt float 4.0, 5.0 ; yields: result=true
<result> = fcmp ueq double 1.0, 2.0 ; yields: result=false
switch
switch也是一种分支指令,他可以看做是br指令的升级版,支持的分支更多,但语法也更加复杂。他和c中的switch是差不多的。语法如下
switch <intty> <value>, label <defaultdest> [ <intty> <val>, label <dest> ... ]
首先需要指定一个switch变量,intty是变量类型,value是变量的值。后续的<intty>和<val>分别指定的是每个case的类型和值。如果switch变量和某个case的值相等,他就会跳转到这个case执行对应的分支dest。若都不相等,则会执行默认分支defaultdest。
举个例子
; 与条件跳转等效
%Val = zext i1 %value to i32
switch i32 %Val, label %truedest [ i32 0, label %falsedest ]
; 与非条件跳转等效
switch i32 0, label %dest [ ]
; 拥有三个分支的条件跳转
switch i32 %val, label %otherwise [ i32 0, label %onzero
i32 1, label %onone
i32 2, label %ontwo ]
二元运算指令 Binary Operations
add
add是整数加法指令,对应C中的+号,类似x86汇编中的add指令。语法如下
<result> = add <ty> <op1>, <op2>
十分易懂,ty是变量类型
举个例子
<result> = add i32 4, %var ; yields i32:result = 4 + %var
sub
sub是整数减法指令,对应C中的-号,类似x86汇编中的sub指令。语法如下
<result> = sub <ty> <op1>, <op2>
和add差不多,举个例子
<result> = sub i32 4, %var ; yields i32:result = 4 - %var
<result> = sub i32 0, %var ; yields i32:result = -%var
mul
mul是整数乘法指令,对应C中的*号,类似x86汇编中的mul指令。语法如下
<result> = mul <ty> <op1>, <op2>
举个例子
<result> = mul i32 4, %var ; yields i32:result = 4 * %var
udiv
udiv是无符号整数除法指令,对应C中的/号。如果存在exact关键字,且op1不是op2的倍数,就会出现错误。
语法如下
<result> = udiv <ty> <op1>, <op2> ; yields ty:result
<result> = udiv exact <ty> <op1>, <op2> ; yields ty:result
有点不一样的是下面这一条。exact要求op1是op2的倍数才能正确执行,否则会报错。
举个例子
<result> = udiv i32 4, %var ; yields i32:result = 4 / %var
sdiv
sdiv是有符号整数除法指令,对应C中的/号。语法如下
<result> = sdiv <ty> <op1>, <op2> ; yields ty:result
<result> = sdiv exact <ty> <op1>, <op2> ; yields ty:result
和sdiv一样
举个例子
<result> = sdiv i32 4, %var ; yields i32:result = 4 / %var
urem
urem是无符号整数取余指令,对应C中的%号。语法如下
<result> = urem <ty> <op1>, <op2> ; yields ty:result
举个例子
<result> = urem i32 4, %var ; yields i32:result = 4 % %var
srem
srem是有符号整数取余指令,对应C中的%号。语法如下
<result> = srem <ty> <op1>, <op2> ; yields ty:result
举个例子
<result> = srem i32 4, %var ; yields i32:result = 4 % %var
二元运算指令都算很简单的指令,用法都差不多
按位二元运算 Bitwise Binary Operations
shl
shl是整数左移指令,对应C中的<<号,类似x86汇编中的shl指令。语法如下
<result> = shl <ty> <op1>, <op2>
举个例子
<result> = shl i32 4, %var ; yields i32: 4 << %var
<result> = shl i32 4, 2 ; yields i32: 16
<result> = shl i32 1, 10 ; yields i32: 1024
<result> = shl i32 1, 32 ; undefined
<result> = shl <2 x i32> < i32 1, i32 1>, < i32 1, i32 2> ; yields: result=<2 x i32> <i32 2,i32 4>
第四个指令爆了,所以undefined
lshr
lshr是整数逻辑右移指令,对应C中的>>号,右移后会在左侧补0。逻辑右移不管是有符号还是无符号数,一律当做无符号数处理。语法如下
<result> = lshr <ty> <op1>, <op2>
举个例子
<result> = lshr i324, 1 ; yields i32:result = 2
<result> = lshr i32 4, 2 ; yields i32:result = 1
<result> = lshr i8 4, 3 ; yields i8:result = 0
<result> = lshr i8 -2, 1 ; yields i8:result = 0x7F
<result> = lshr i32 1, 32 ; undefined
<result> = lshr <2 x i32> < i32 -2, i32 4>, <i32 1, i32 2> ; yields: result=<2 x i32><i32 0x7FFFFFF, i32 1>
看看第四句,把-2逻辑右移了1位,这里会把-2当做无符号数处理,右移后会得到0x7f
ashr
ashr是整数算术右移指令,右移后会在左侧补符号位(负数符号位是1,正数是0),意思就是说他把有符号和无符号数是分开来看待的。语法如下
<result> = ashr <ty> <op1>, <op2>
举个例子
<result> = ashr i324, 1 ; yields i32:result = 2
<result> = ashr i32 4, 2 ; yields i32:result = 1
<result> = ashr i8 4, 3 ; yields i8:result = 0
<result> = ashr i8 -2, 1 ; yields i8:result = -1
<result> = ashr i32 1, 32 ; undefined
<result> = ashr <2 x i32> < i32 -2, i32 4>, <i32 1, i32 2> ; yields: result=<2 x i32><i32 -1, i32 0>
可以发现,正数的情况下ashr与lshr一模一样,但是当负数的时候,ashr会按照负数进行运算
and
and是按位与运算指令,对应C中的&号。语法如下
<result> = and <ty> <op1>, <op2>
举个例子
<result> = and i32 4, %var ; yields i32:result = 4 & %var
<result> = and i32 15, 40 ; yields i32:result = 8
<result> = and i32 4, 8 ; yields i32:result = 0
or
or是按位或运算指令,对应C中的|号。语法如下
<result> = or <ty> <op1>, <op2>
举个例子
<result> = or i32 4, %var ; yields i32:result = 4 | %var
<result> = or i32 15, 40 ; yields i32:result = 47
<result> = or i32 4, 8 ; yields i32:result = 12
xor
xor是按位异或运算指令,对应C中的^号。语法如下
<result> = xor <ty> <op1>, <op2>
举个例子
<result> = xor i32 4, %var ; yields i32:result = 4 ^ %var
<result> = xor i32 15, 40 ; yields i32:result = 39
<result> = xor i32 4, 8 ; yields i32:result = 12
<result> = xor i32 %V, -1 ; yields i32:result = ~%V
第四条,如果与-1异或相当于对变量取反。
内存访问和寻址操作 Memory Access and Addressing Operations
标题这么长一看就很重要
首先我们要了解什么是静态单赋值
在编译器设计中,静态单赋值(Static Single Assignment, SSA),是 IR 的一种属性。简单来说,SSA 的特点是:在程序中一个变量仅能有一条赋值语句。静态的意思就是在整个静态程序,而非动态执行中的程序里,一个变量只能出现在一条赋值语句里。
LLVM IR 正是基于静态单赋值原则设计的。
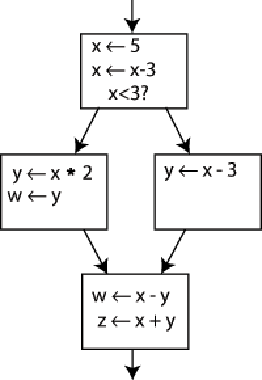
上面这个流程图内,x y w都被赋值了两次,他们都不满足SSA
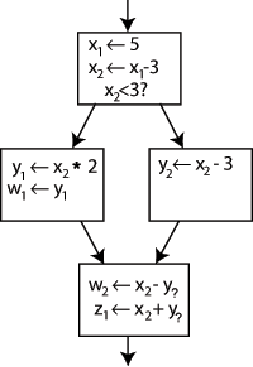
我们把他改写成这样,现在他就满足SSA了,每个变量只出现在了一条赋值语句里。
SSA的特性会带来一些问题。
#include <cstdio>
int main()
{
for (int i = 0; i < 100; ++i)
{
printf("Hello, %d\n", i);
}
}
例如这个程序,如果C++也是遵守静态单赋值原则的话,这个程序中i被赋值了100次,显然违反了SSA。
这里给出了一种改写方案
#include <cstdio>
int main()
{
int *i = (int *) malloc(4);
for (*i = 0; *i < 100; ++(*i))
{
printf("Hello, %d\n", *i);
}
}
i由int变量变成了int指针变量,我们在循环时直接通过指针i来操作内存。这样i就只被赋值了一次,也就是malloc处。后面的操作均是基于指针i对其指向的内存进行操作,而并没有修改变量i。这是符合SSA的。这种实现方法也是LLVM IR中所采用的。
alloca
alloca是内存分配指令,在栈中分配一块空间并获得指向该空间的指针,类似于C中的malloc()。不同的是,alloca是在栈中分配内存,而malloc()是在堆中分配内存。语法如下
<result> = alloca <type> [, <ty> <NumElements>] [, align <alignment>] ;分配sizeof(type)*NumElements字节的内存,分配的地址与alignment对齐
首先<type>要声明你分配的内存空间是什么类型的数据,比如是i32的数据,随后<NumElements>需要声明你要分配多少个这样的数据。align是对齐的意思,也就是说分配的内存空间会与alignment的对齐。例如alignment是1024,那么你分配的地址空间一定是1024的倍数。
举个例子
%ptr = alloca i32 ;分配4字节的内存并返回i32类型的指针
%ptr = alloca i32, i32 4 ;分配4*4字节的内存并返回i32类型的指针
%ptr = alloca i32, i32 4, align 1024 ;分配4*4字节的内存并返回i32类型的指针,分配的地址与1024对齐
%ptr = alloca i32, align 1024 ;分配4字节的内存并返回i32类型的指针,分配的地址与1024对齐
sizeof(i32)是4,i32 4是指定了要分配4个i32类型数据大小的空间,align 1024是指定对齐为1024
store
store是内存存储指令,向指针指向的内存中存储数据,类似于C中的指针解引用后的赋值操作。语法如下
store <ty> <value>, <ty>* <pointer> ; 向特定类型指针指向的内存存储相同类型的数据
首先指定一个类型ty,然后向一个相同类型的指针存入变量
举个例子
%ptr = alloca i32
store i32 3, i32* %ptr
首先由alloca分配给指针一个4字节的空间,然后通过store指令向ptr指针指向的内存写入相同类型(i32)的数据(3)。
load
load是内存读取指令,从指针指向的内存中读取数据,类似于C中的指针解引用操作。语法如下
load <ty> <value>, <ty>* <pointer> ; 从特定类型指针指向的内存中读取特定类型的数据
举个例子
%ptr = alloca i32 ; yields i32* :ptr
store i32 3, i32* ptr ; yields void
%val = load i32, i32* %ptr ; yields i32:val = i32 3
类型转换操作 Conversion Operations
trunc ... to
trunc...to是截断指令,将一种类型的变量截断为另一种类型的变量。对应C中大类型向小类型的强制转换(比如 long转int)。语法如下
<result> = trunc <ty> <value> to <ty2> ; 将ty类型的变量截断为ty2类型的变量
先定义一个ty类型的变量value,然后将他强制转化为ty2类型。非常简单的操作。
举个例子
%X = trunc i32 257 to i8 ; yields i8:1
%Y = trunc i32 123 to i1 ; yields i1:true
%Z = trunc i32 122 to i1 ; yields i1:false
%W = trunc <2 x i16> <i16 8, i16 7> to <2 x i8> ; yields <i8 8, i8 7>
第一条指令把i32类型的变量257截断为i8类型,那么只保留257的低8位,也就是1
后面都差不多
zext ... to
零拓展(Zero Extend)指令,将一种类型的变量拓展为另一种类型的变量,高位补0。对应C中小类型向大类型的强制转换(比如int转long)。语法如下
<result> = zext <ty> <value> to <ty2> ; 将ty类型的变量拓展为ty2类型的变量
举个例子
%X = zext i32 257 to i64 ; yields i64:257
%Y = zext i1 true to i32 ; yields i32:1
%Z = zext <2 x i16> <i16 8, i16 7> to <2 x i32> ; yields <i32 8, i32 7>
zext是高位补0,所以结果不变。
sext ... to
符号位拓展(Sign Extend)指令,通过复制符号位(最高位)将一种类型的变量拓展为另一种类型的变量。正数的符号位是0,那么对正数进行sext ... to的结果和zext ... to是一样的,但负数符号位是1,结果就不一样了。
语法如下
<result> = sext <ty> <value> to <ty2> ; 将ty类型的变量拓展为ty2类型的变量
举个例子
%X = sext i8 -1 to i16 ; yields i16:-1
%Y = sext i1 true to i32 ; yields i32:-1
%Z = sext <2 x i16> <i16 8, i16 7> to <2 x i32> ; yields <i32 8, i32 7>
看第一条指令,-1的二进制是10000001,然后把他转换为补码,除符号位之外取反再加1,变成11111111,然后符号位是1,sext ... to用符号位进行填充,i8到i16会变为11111111 11111111,这个补码转换为原码还是-1。
下面的跟着这个走一下就行,一个道理
其他操作 Other Operations
phi
我们在内存访问和寻址操作那里介绍了SSA,并且给出了两个流程图转换的例子。但是,我们注意到这种转换存在一个问题:转换后的最后一个基本块内,到底是用\(y_{1}\)还是\(y_{2}\)?如果程序是往左边走下来的那应该是\(y_{1}\),右边走下来的话就是\(y_{2}\)。
为了解决这种变量引用混乱的问题,SSA引入了φ函数的概念。φ函数的运算结果由前驱块决定。
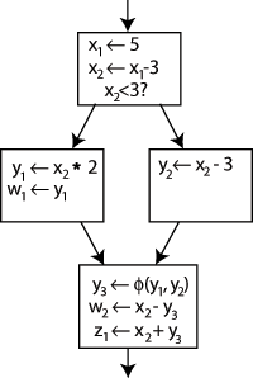
如果我们的程序从左边执行下来,那么φ的运算结果就是\(y_{1}\),右边执行下来结果就是\(y_{2}\)
这个φ函数就对应LLVM IR中的phi指令。phi 指令可以看做是为了解决SSA一个变量只能被赋值一次而引起的问题衍生出的指令,其计算结果由phi指令所在的基本块的前驱块确定。语法如下
<result> = phi <ty> [<val0>, <label0>], ... ;如果前驱块为label0,则result=val0 ...
首先得定义phi运算的结果的类型ty,然后定义了一系列的值以及对应的标签。如果phi指令对应的前驱块是label0,那phi的运算结果就是val0。
举个例子
Loop: ; Infinite loop that counts from 0 on up. . .
%indvar = phi i32 [ 0, %LoopHeader ], [ %nextindvar, %Loop ]
%nextindvar = add i32 %indvar, 1
br label %Loop
这是用phi实现for循环的一个实例,我们之前用内存访问来实现过满足SSA的for循环,这里来看看phi实现的是什么样子的。
第一句话就是phi,这里有两个标签和对应的值,如果是从外面进入循环的,那么phi运算的结果是0,也就是赋初值的操作,如果前驱块是Loop,也就是在循环中跳转来的,那运算结果就是上一个循环中的nextindvar变量,上一个循环的nextindvar就是当前的indvar的值加1。这样就实现了++i的操作并且遵循了SSA原则。
select
select指令类似于C中的三元运算符... ? ... : ...,语法如下
<result> = select i1 <cond>, <ty> <val1>, <ty> <val2> ;如果条件cond 成立,result=val1,否则result=val2
先定义一个bool类型的变量cond,如果是true则select的结果是val1,否则是val2
举个例子
%X = select i1 true, i8 17, i8 42; yields i8:17
call
call指令用来调用某个函数,对应C中的函数调用,与x86汇编中的call指令类似。语法如下
<result> = call <ty>|<fnty> <fnptrval>(<function args>) ;调用函数
举个例子
%retval = call i32 @test( i32 %argc) ; 调用test函数,参数为i32类型,返回值为i32类型
call i32 (i8*, ...)* @printf( i8* %msg, i32 12,i8 42) ; 调用printf函数,参数可变
实例分析
在LLVM PASS部分写了一个TestProgram.cpp,就以这个的.ll为实例
; ModuleID = 'TestProgram.cpp'
source_filename = "TestProgram.cpp"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-unknown-linux-gnu"
@input = dso_local global [100 x i8] zeroinitializer, align 16
@enc = dso_local global <{ [22 x i8], [78 x i8] }> <{ [22 x i8] c"\86\8A}\87\93\8BM\81\80\8AC\7FII\86q\7FbSi(\9D", [78 x i8] zeroinitializer }>, align 16
@.str = private unnamed_addr constant [25 x i8] c"Please input your flag: \00", align 1
@.str.1 = private unnamed_addr constant [3 x i8] c"%s\00", align 1
@.str.2 = private unnamed_addr constant [18 x i8] c"Congratulations~\0A\00", align 1
@.str.3 = private unnamed_addr constant [18 x i8] c"Sorry try again.\0A\00", align 1
; Function Attrs: noinline nounwind optnone uwtable mustprogress
define dso_local void @_Z7encryptPhPc(i8* %0, i8* %1) #0 {
%3 = alloca i8*, align 8
%4 = alloca i8*, align 8
%5 = alloca i32, align 4
%6 = alloca i32, align 4
store i8* %0, i8** %3, align 8
store i8* %1, i8** %4, align 8
%7 = load i8*, i8** %4, align 8
%8 = call i64 @strlen(i8* %7) #5
%9 = trunc i64 %8 to i32
store i32 %9, i32* %5, align 4
store i32 0, i32* %6, align 4
br label %10
10: ; preds = %31, %2
%11 = load i32, i32* %6, align 4
%12 = load i32, i32* %5, align 4
%13 = icmp slt i32 %11, %12
br i1 %13, label %14, label %34
14: ; preds = %10
%15 = load i8*, i8** %4, align 8
%16 = load i32, i32* %6, align 4
%17 = sext i32 %16 to i64
%18 = getelementptr inbounds i8, i8* %15, i64 %17
%19 = load i8, i8* %18, align 1
%20 = sext i8 %19 to i32
%21 = load i32, i32* %6, align 4
%22 = sub nsw i32 32, %21
%23 = add nsw i32 %20, %22
%24 = load i32, i32* %6, align 4
%25 = xor i32 %23, %24
%26 = trunc i32 %25 to i8
%27 = load i8*, i8** %3, align 8
%28 = load i32, i32* %6, align 4
%29 = sext i32 %28 to i64
%30 = getelementptr inbounds i8, i8* %27, i64 %29
store i8 %26, i8* %30, align 1
br label %31
31: ; preds = %14
%32 = load i32, i32* %6, align 4
%33 = add nsw i32 %32, 1
store i32 %33, i32* %6, align 4
br label %10, !llvm.loop !2
34: ; preds = %10
ret void
}
; Function Attrs: nounwind readonly willreturn
declare dso_local i64 @strlen(i8*) #1
; Function Attrs: noinline norecurse optnone uwtable mustprogress
define dso_local i32 @main(i32 %0, i8** %1) #2 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
%5 = alloca i8**, align 8
%6 = alloca [100 x i8], align 16
%7 = alloca i8, align 1
store i32 0, i32* %3, align 4
store i32 %0, i32* %4, align 4
store i8** %1, i8*** %5, align 8
%8 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([25 x i8], [25 x i8]* @.str, i64 0, i64 0))
%9 = call i32 (i8*, ...) @__isoc99_scanf(i8* getelementptr inbounds ([3 x i8], [3 x i8]* @.str.1, i64 0, i64 0), i8* getelementptr inbounds ([100 x i8], [100 x i8]* @input, i64 0, i64 0))
%10 = bitcast [100 x i8]* %6 to i8*
call void @llvm.memset.p0i8.i64(i8* align 16 %10, i8 0, i64 100, i1 false)
%11 = getelementptr inbounds [100 x i8], [100 x i8]* %6, i64 0, i64 0
call void @_Z7encryptPhPc(i8* %11, i8* getelementptr inbounds ([100 x i8], [100 x i8]* @input, i64 0, i64 0))
%12 = call i64 @strlen(i8* getelementptr inbounds ([100 x i8], [100 x i8]* @input, i64 0, i64 0)) #5
%13 = icmp eq i64 %12, 22
br i1 %13, label %14, label %19
14: ; preds = %2
%15 = getelementptr inbounds [100 x i8], [100 x i8]* %6, i64 0, i64 0
%16 = call i32 @memcmp(i8* %15, i8* getelementptr inbounds ([100 x i8], [100 x i8]* bitcast (<{ [22 x i8], [78 x i8] }>* @enc to [100 x i8]*), i64 0, i64 0), i64 22) #5
%17 = icmp ne i32 %16, 0
%18 = xor i1 %17, true
br label %19
19: ; preds = %14, %2
%20 = phi i1 [ false, %2 ], [ %18, %14 ]
%21 = zext i1 %20 to i8
store i8 %21, i8* %7, align 1
%22 = load i8, i8* %7, align 1
%23 = trunc i8 %22 to i1
br i1 %23, label %24, label %26
24: ; preds = %19
%25 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([18 x i8], [18 x i8]* @.str.2, i64 0, i64 0))
br label %28
26: ; preds = %19
%27 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([18 x i8], [18 x i8]* @.str.3, i64 0, i64 0))
br label %28
28: ; preds = %26, %24
%29 = load i32, i32* %3, align 4
ret i32 %29
}
declare dso_local i32 @printf(i8*, ...) #3
declare dso_local i32 @__isoc99_scanf(i8*, ...) #3
; Function Attrs: argmemonly nofree nosync nounwind willreturn writeonly
declare void @llvm.memset.p0i8.i64(i8* nocapture writeonly, i8, i64, i1 immarg) #4
; Function Attrs: nounwind readonly willreturn
declare dso_local i32 @memcmp(i8*, i8*, i64) #1
attributes #0 = { noinline nounwind optnone uwtable mustprogress "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #1 = { nounwind readonly willreturn "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #2 = { noinline norecurse optnone uwtable mustprogress "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "min-legal-vector-width"="0" "no-infs-fp-math"="false" "no-jump-tables"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #3 = { "disable-tail-calls"="false" "frame-pointer"="all" "less-precise-fpmad"="false" "no-infs-fp-math"="false" "no-nans-fp-math"="false" "no-signed-zeros-fp-math"="false" "no-trapping-math"="true" "stack-protector-buffer-size"="8" "target-cpu"="x86-64" "target-features"="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu"="generic" "unsafe-fp-math"="false" "use-soft-float"="false" }
attributes #4 = { argmemonly nofree nosync nounwind willreturn writeonly }
attributes #5 = { nounwind readonly willreturn }
!llvm.module.flags = !{!0}
!llvm.ident = !{!1}
!0 = !{i32 1, !"wchar_size", i32 4}
!1 = !{!"clang version 12.0.1"}
!2 = distinct !{!2, !3}
!3 = !{!"llvm.loop.mustprogress"}
这就是LLVM IR中的一个模块,头部给出了很多信息,比如source_filename表明了是从哪个文件编译来的。
下面有变量定义,比如叫input的大小为100的i8类型的数组。
再下面是函数定义,例如_Z7encryptPhPc,这个就是encrypt函数的定义。最开始的地方是入口块,是函数第一个执行的基本块,我们可以看到最后他有个终结指令 br label %10,跳转到10这个块。后面的块也差不多。34那里可以看到ret void,这里就是结束了。
我们还能看到函数的声明,引用库函数时LLVM IR会产生对应的声明。
; Function Attrs: nounwind readonly willreturn
declare dso_local i64 @strlen(i8*) #1
例如这里,我们调用了strlen,LLVM IR就产生了对于他的声明。
最后,attributes这里是LLVM IR模块的尾部信息,这是由编译器自动生成的,了解即可。
想要更进一步研究的话,我们可以自行阅读一下入口块、10和14这三个部分,对照源代码来理解一下每个语句在干什么。
LLVM PASS 常用API
LLVM PASS框架中最核心的三个类是Function, BasicBlock和Instruction,分别对应IR中的函数、基本块和指令。
Function
与Function有关的操作主要是获取函数的一些基本属性,例如函数名等,以及对函数中基本块的遍历
- F.getName(): 获取函数名称
- F.getEntryBlock(): 获取入口块
- 对基本块进行遍历
对基本块进行遍历可以采用foreach
// 遍历函数F中的基本块BB
bool runOnFunction(Function &F)
{
for (BasicBlock &BB: F)
{
// 对BB做点你想做的
}
}
BasicBlock
与BasicBlock有关的操作主要是基本块的克隆、分裂、移动,以及对基本块中指令的遍历等。
-
获取基本块的名称:BB.getName()
-
获取基本块的终结指令:BB.getTerminator()
遍历指令和上面那个差不多
// 遍历函数F中的基本块BB的指令I bool runOnFunction(Function &F) { for (BasicBlock &BB: F) { for (Instruction &I : BB) { // 对I做点你想做的 } } }
Instructions
他是可以有很多种子类的,我们前面写了一堆指令类型。与Instructions有关的操作主要是指令的创建、删除、修改以及操作数的遍历
遍历操作数就不能foreach了,我们通过I.getNumOperands()获取操作数的数量,通过I.getOperand(i)获取下标为i的操作数。
// 遍历函数F中的基本块BB的指令I的操作数V
bool runOnFunction(Function &F)
{
for (BasicBlock &BB: F)
{
for (Instruction &I : BB)
{
for (int i = 0; i < I.getNumOperands(); ++i)
{
Value *V = I.getOperand(i);
// 对V做点你想做的
}
}
}
}
注意到操作数的类型为Value,这是LLVM中的一个基本类,所有可以被当做指令操作数的类型都是Value的子类。
Value的子类有Constant, Argument, Instruction(运算结果), Function(指针), BasicBlock五种。
输出流
C++中我们会用到cout, cerr, clog来打印输出流,但是LLVM中,我们一般采用outs(), errs()和dbgs()来获取输出流并进行打印,分别打印一般信息、错误信息和调试信息。
