week4
列表生成器
看列表[0, 1, 2, 3, 4, 5, 6, 7, 8, 9],要求把列表里的每个值加1
1 >>> a = [i+1 for i in range(10)] 2 >>> a 3 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
列表生成器可以生成一个动态的列表,如 a = [1,2,3] 那么是写死的值
相当于
a = [] for i in range(10): a.append(i+2) print (a)
生成器
与列表生成器的区别,当调用的时候才会去生成对应数据,节省内存空间
只有一个__next__()方法
只记录当前的位置。写一个例子:
#生成器 x = (i*2 for i in range(10)) # 建立了算法,但只有调用时才会出现值 print(x) for j in x: #for 循环调用 print(j)
比如现在有一个斐波那契数 (任意前两个数相加等于下一个数,除了最开始的数字)
1,1,2,3,5,8,13,21,34,56。。。
”yield“
#yield 返回当前状态的值,停留函数再此位置可以随时回来
#生成斐波那契数列 def fib(max): n, a, b = 0, 0,1 while n <max: yield b #a ,b = 1,2 #相当于 t = (b,a+b) a = 1 b = 2 a+b = 3 #a = t[0] #b = t[1] a,b = b, a + b n = n + 1 #print(fib(10)) f = fib(10) print(f.__next__()) print("干点别的事此时") print("继续输出斐波那契数") print(f.__next__()) print(f.__next__()) print(f.__next__()) print(f.__next__())
牛逼之处:实现单线程下的并行效果(边吃边做包子实例):
import time def consunmer(name): print("%s 准备吃包子啦!" %name) while True: baozi = yield #yield 返回当前状态的值,停留函数再此位置可以随时回来 print("包子[%s]来了,被[%s]吃了!" %(baozi,name)) #c = consunmer("海州") #c.__next__() #唤醒停留的函数 #c.send("韭菜馅") #唤醒 停留的函数并且传入一个值进入 def producer(name): c = consunmer("海州") c2 = consunmer("丽佳") c.__next__() c2.__next__() print("老子开始做包子了!") for i in range(10): #循环 time.sleep(1) print("做了1个包子,分两半!") c.send(i) #遍历一次i的值给send方法做为参数,供它唤醒停留的生成器并且传入值给生成器 c2.send(i) #遍历一次i的值给send方法做为参数,供它唤醒停留的生成器并且传入值给生成器 producer("kim")
迭代器

如列表、字典、字符可直接作用于for循环
>>> from collections import Iterable >>> isinstance([],Iterable) True >>> isinstance({},Iterable) True >>> isinstance('abc',Iterable) True >>> isinstance((x for x in range(10)),Iterable) True >>> isinstance(100,Iterable) False >>>
可以用于for循环的对象统称为可迭代对象:Iterable
而生成器不但可以作用于for循环,还可以被.__next__() 函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了
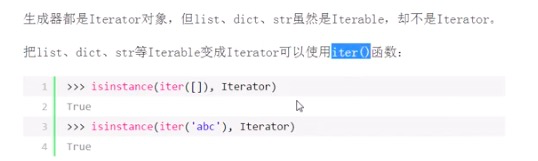
可以被next()函数不断调用并返回值的对象称为:迭代器 Iterator
>>> from collections import Iterator >>> isinstance([],Iterable) True >>> isinstance([],Iterator)

装饰器
本质为函数-都使用def关键字定义。为其他函数添加附加功能
原则一:不能修改被装饰的函数的源代码
原则二:不能修改被装饰的函数的调用方式
实例:
#Herbie Kim
#!/usr/bin/python
# -*-coding:utf-8-*-
import time
def timmer(fun):
def war(*args,**kwargs):
start_time=time.time()
fun()
stop_time=time.time()
print("记录上面程序运行的时长是%s" %(stop_time-start_time))
return war
@timmer
def test():
time.sleep(3)
print("3秒输出结果")
test()
实现装饰器的知识储备
1.函数即“变量”
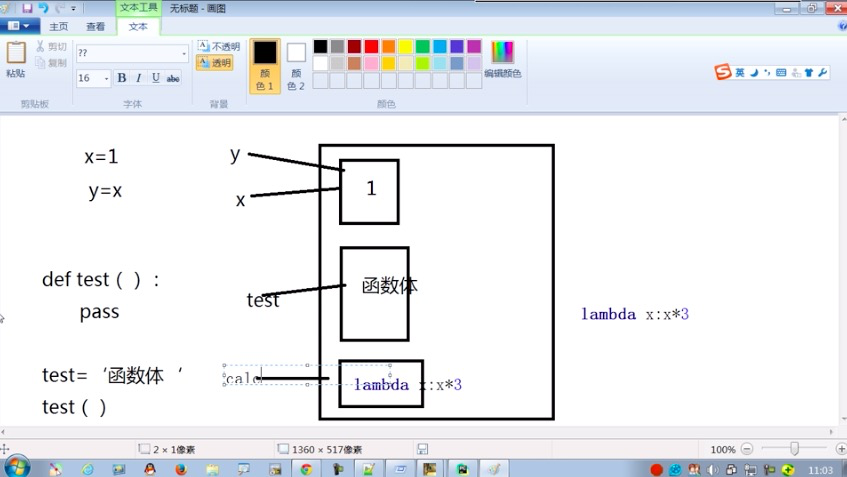
当x、y 被删除后内存会被回收,不删会一直存在
2.高阶函数
a. 把一个函数当做参数传递给下一个函数 ==》能满足装饰器之不修改被调用函数的源代码,但不满足于不修改被调用函数的调用方式


import time def bar(): time.sleep(3) print("in the bar") def fun(test): start_time =time.time() test() #run bar stop_time = time.time() print("the test run time is %s" %(stop_time-start_time)) fun(bar)
b.返回值中包含函数名 ==》满足不修改被调用函数的调用方式
import time def bar(): time.sleep(3) print("in the bar") def fun(test): start_time =time.time() stop_time = time.time() print("the test run time is %s" %(stop_time-start_time)) return test bar = fun(bar) bar()
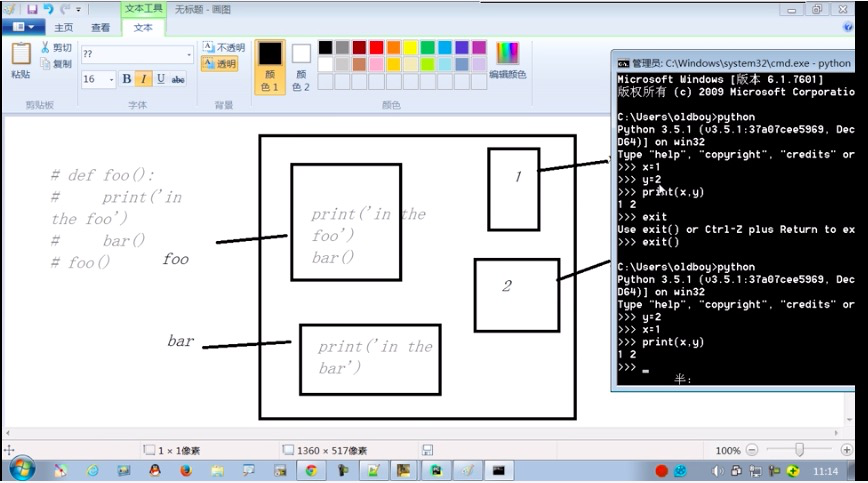
3.嵌套函数
就函数中再用def定义一个函数,被定义的函数相当于局部变量只作用在此,bar()调用的意义就是在嵌套,bar中的内容是被运行的;不调用就相当于无作为
def fun(): print("in the fun") def bar(): print("in the bar") bar() fun()
高阶函数+嵌套函数 ==》装饰器
装饰器案例分析1
未修改被装饰的函数的源代码;未修改被装饰的函数的调用方式
import time def timer(fun): #调timer(test1) , fun = test1 def doc(): start_time = time.time() fun() #run test1 函数 stop_time = time.time() print("in the func run is %s" %(stop_time-start_time)) return doc @timer #提供的符号代表,test1 = timer(test1) def test1(): time.sleep(3) print("the test1 running") @timer #提供的符号代表,test2 = timer(test2) def test2(): time.sleep(4) print("the test2 running") #test1=timer(test1) test1() #test2=timer(test2) test2()
装饰器案例分析2
当有参数需要传入使,进阶方法
import time def timmer(fun): def war(*args,**kwargs): #非固定参数,如果有参数就可以调用,没有参数也可以运行 start_time=time.time() fun(*args,**kwargs) stop_time=time.time() print("记录上面程序运行的时长是%s" %(stop_time-start_time)) return war #返回结果的内存地址,门牌号 @timmer #test = timmer(test) def test(name,age): time.sleep(3) print("3秒输出结果",name,age) test("kim",18)
Json与序列化
内存的数据转换为字符串的过程就是序列化过程
示列:
序列化
#Herbie Kim #!/usr/bin/python # -*-coding:utf-8-*- ''' info = { "name":"kim", "age":22 } f = open('kim.txt','w') f.write(str(info)) #内存的数据类型通过字符串存储在硬盘上 (序列化) f.close() ''' #import json import pickle # 和json一样 def func(name): print("hello",name) info = { 'name':'kim', 'age':18, 'func':func #json处理简单的数据类型,函数的内存地址无法序列化 #pickle 可以序列化所有数据类型,但可能反序列化时出错 } f = open('kim.txt','wb') pickle.dump(info,f) # ==f.write(pickle.dumps(info)) #f.write(pickle.dumps(info)) f.close()
反序列化
#Herbie Kim #!/usr/bin/python # -*-coding:utf-8-*- import pickle def func(name): print("hello",name) print('hello2',name) f = open('kim.txt','rb') data = pickle.loads(f.read()) # ==data = pickle.load(f) print(data['func']("licca"))# 函数名一样,内容可以不一样。所以序列化时是序列化整个数据对象,而不是函数的内存地址
软件目录结构规范
最后在制作小程序或脚本时,程序的结构化目录规范会增加代码的可读性等,还是要规范格式的


 浙公网安备 33010602011771号
浙公网安备 33010602011771号