Week2
模块初识
(已经存在的模板)
标准库:不需要安装即可安装 getpass
sys 模块
Sys.path #打印环境变量
Sys.argv #打印相对路径
os 模块
os.system(”ls”) 调后直接使用输出再屏幕,不保存屏幕,如果定义变量输出,显示0
import os
cmd_res = os.popen("ls -a").read()
print("--->",cmd_res)
可输出结果
调用脚本后,本地路径生成 .pyc文件
:Python 再程序运行后,编译的结果会位于内存的pycodeobject中,当Python程序运行结束,解释器会将pycodeObject写回》pyc文件中,当程序第二次运行时,程序会寻找此 pyc文件,如果找到直接载入
预编译完的半成品
数据类型:
数字 {整数、长整数、浮点数、复数
浮点型 表示型号:小数
布尔值 :真或假 1或0
第三方库:需要下载安装才能使用
字符串常用操作:


name = "my name" print(name.capitalize()) #首字母大写 print(name.count("i")) #计数 :i print(name.center(50,"-")) #name 放中间不够的使用 - 补充 print(name.endswith("m")) #判断name 字符串是否以此结尾 print(name[name.find("i"):3]) #字符串切片,取值 print(name.format(name = 'kim')) #输出结果为:my name is kim print(name.format_map({'name':'kim'})) #字典 print('ab12'.isalnum()) #判断字符是否包含阿拉伯数字和字母,不包含特殊字符 print('ab12'.isalpha()) #判断是否纯字母 print('12'.isdigit()) #判断是否为整数 print('1A'.isdecimal()) #判断是否为十进制 print('_a1'.isidentifier()) #判断是不是一个合法的标识符 print('aaa'.islower()) #判断是否小写 print('my'.isupper()) #判断是否大写 print('aaa22'.isnumeric()) #判断是不是只有数字 print(' '.isspace()) #判断是否空格 print('my is'.istitle()) #判断是否为标题(首字母大写) print('='.join(['kim','lnnac'])) #字符的形式连接后面列表 print(name.ljust(30,'*')) #第一个长度,字符不足长度以*代替,(后面接着补) print(name.rjust(30,'*')) #前面开始补 print('KIM'.lower()) #大写变小写 print('kim'.upper()) #小写变大写 print(' Kim\n'.strip()) #\n 换行,下一个输入去掉换行+空格 print('kim'.replace('i','I')) #替换 print('abcdeb'.rfind('b')) #找到最右边的字符 显示下标 print('a+b+c+d+e'.split('+')) #根据括号内的分隔符显示列表 print('a+b\n+c+d+e'.splitlines()) #根据换行来分 print('herbie KIM'.swapcase()) #大写变为小写,小写变为大写 print('herbie kim'.title()) #变为标题,首字母大写 print('herbie kim'.zfill(30)) #运算时不够以0补充
三元运算
a,b,c = 1,3,5
d = a if a <b else c
print(d)
d=1
二进制与十六进制数之间如何互相转换
https://jingyan.baidu.com/album/47a29f24292608c0142399cb.html?picindex=1
字符串 <—> 二进制 string <—> bytes
string 编码(encode)bytes bytes 解码(decode)bytes
字典是一种 key - value 的数据类型
语法:
people = {
'list1':"cang jingkong",
'list2':"Longze luola",
'list3':"xiaoze Maliya",
'list4':"sunwukong",
}
取值查找 :print(people[“list1”]) #但字典中无此key 索引就会报错
取值查找: print (people.get(‘list2’)) #字典中无此key返回 None
print (people.has_key("list1")) #查找keylist1是否存在,在返回true不在返回false .in py2.* print('list1' in people) .in py3.*
特点1:字典打印是无序的
增加:people[“list5”] = “kakaluote”
修改: people[“list2”] = “wutenglan”
删除1:del people[“list2”] #内置删除方法, 不止可删除字典
删除2:people.pop(“list2”)
删除3:people.popitem() 随机删除
People.values() 打印所有的值
people.keys() 打印key 的值
多级子弹嵌套及操作
av_catalog = { "欧美":{ "www.youporn.com": ["很多免费的,世界最大的","质量一般"], "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] }, "日韩":{ "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] }, "大陆":{ "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] } }
(来源:http://www.cnblogs.com/alex3714/articles/5717620.html)
setdefault : 在字典中查询如没有则增加,如有key 则返回值
av_catalog.setdefault("taiwan",{"baidu.com":[1,2]})
updata :字典infoa、字典b;
infoa.updata(b)
print (infoa) #合并,如B有重复A的key 则更新,没有的新增
A.fromkeys([])
print (infoa.items()) #将字典转换为列表
三级菜单实例(low版)
data = { '我':{ '佳佳':{ '口红':{ 'diao':{}, 'ysy':{}, 'yeye':{} }, '小吃':{ '猪蹄':{}, '鸭脖':{}, '臭豆腐':{}, }, '大盘鸡':{ '小份':{}, }, }, '算算':{ '沙河':{ '老男孩':{}, '北航':{}, }, '天通苑':{ '孙悟空':{}, }, }, }, '你':{ '利群':{ "阳光":{ '硬阳光':{} } }, '中华':{ '软中华':{ '硬中华':{} } }, }, } exit_flag = False while not exit_flag: for i in data: print(i) choice = input(">>选择进入第一层:") if choice in data: while not exit_flag: for i2 in data[choice]: print("\t",i2) choice2 = input(">>选择进入第二层:") if choice2 in data[choice]: while not exit_flag: for i3 in data[choice][choice2]: print("\t\t", i3) choice3 = input(">>选择进入第三层:") if choice3 in data[choice][choice2]: for i4 in data[choice][choice2][choice3]: print("\t\t",i4) choice4 = input("最后一次选择,按b返回:") if choice4 == "b": pass elif choice4 =="q": exit_flag = True if choice3 == "b": break elif choice3 =="q": exit_flag = True if choice2 =="b": break elif choice2 =="q": exit_flag = True
列表
列表 [] name=[] 中括号代替
比如多人存储到name中:name = ["zhangtang","guyun","hha"] 格式
name = ["zhangsan","lisi","jingkong","maliya","wukong"]
print (name[1:4]) #切片,顾头不顾尾
print(name[-1])#当不知道列表数时取最后的值
print (name[-2:]) #从后取切片,取最后两位数 0 可以忽略掉
name.append("kim") #将kim插入变量后面
name.insert(1,"hei") #想插入第几个位置就填写位置。计算机内是从0开始计数
name[2] = "xiedi" #覆盖,将jingkong改为xiedi
copy :浅复制;deepcopy:深复制
copy: 根据内存存储地址来记录,一个元素一个地址.被复制出的列表引用第一个列表的元素
deepcopy:完整克隆
import copy
name = ["zhangsan","lisi","jingkong",["xiaojin","xixu"],"maliya","wukong"]
name2 = copy.deepcopy(name)
name[3][0] = "MALIYA"
name[1] = "li"
print (name)
print (name2)
购物车实例:
#Herbie Kim #!/usr/bin/python # -*-coding:utf-8-*- shopping = [ ('iphone',6000), ('Mac pro',12000), ('watch',800), ('book',80), ('cat',100000) ] shopping_list = [] saleable = input("请输入你的工资:") if saleable.isdigit(): saleable = int(saleable) #判断输入是否为数字 while True: for index,item in enumerate(shopping): #打印商品列表,获取下标 print(index,item) user_choice = input("选择要买的商品:") if user_choice.isdigit(): #判断输入的必须为数字 user_choice = int(user_choice) if user_choice < len(shopping) and user_choice >= 0: #判断输入的数字是否和列表长度一样 p_item = shopping[user_choice] #通过下标取出商品 if p_item[1] <= saleable: #比较商品与工资,代表买的起 shopping_list.append(p_item) #添加到商品列表变量中 saleable -= p_item[1] #工资扣除商品 print("Added %s into shopping cart,你的余额是 \033[31;1m%s\033[0m" %(p_item,saleable)) else: print("\033[41;1m你的余额只剩[%s]啦,不能买了\033[0m" % saleable) else: print("商品列表[%s]不存在"% user_choice) elif user_choice =='q': print("--------shoping list------") for p in shopping_list: print(p) print("你的余额:",saleable) exit() else: print("输入有误,请输入数字")
集合
集合是一个无序的,不重复的数据组合
1、去重
#Herbie Kim #!/usr/bin/python # -*-coding:utf-8-*- list_1 = [1,2,3,3,2,6,7] list_1 = set (list_1) #集合,去重 list_2 = set ([0,2,6,4,22]) print(list_1,list_2,type(list_2))
2、关系运算
#Herbie Kim #!/usr/bin/python # -*-coding:utf-8-*- list_1 = [1,2,3,3,2,6,7] list_1 = set (list_1) #集合,去重 list_2 = set ([0,2,6,4,22]) print(list_1,list_2,type(list_2)) ''' print(list_1.intersection(list_2)) #交集 print(list_1.union(list_2)) #并集,将两个合集合并,去除重复 print(list_1.difference(list_2)) #差集,我这有你那没有的,例子是list1有,list2没有 list_3 = set ([2,3,3]) print(list_3.issubset(list_1)) #子集判断,list3是list1的子集 print(list_1.issuperset(list_3)) #父集判断,list_3是否被包含于list_1,list1是list3的父集 print(list_1.symmetric_difference(list_2)) #对称差集,将两个列表中都有的项去除 print("------------") print(list_2.isdisjoint(list_1)) #判断两个集合是否有交集 ''' #简单化 print(list_1 & list_2) #交集 print(list_1 | list_2) #并集 print(list_1 - list_2) #差集,in list_1 not in list_2 print(list_1 ^ list_2) #对称差集 。
集合中添加、删除
#list_1.add(99) #添加一项数据 list_1.update([10,11]) #添加多项 print(list_1) list_1.remove(11) #删除一项 print(list_1)
文件操作
读文件:
#Herbie Kim #!/usr/bin/python # -*-coding:utf-8-*- f = open("today2",'w',encoding="utf-8") #文件句柄 data = f.read() #读完了后光标停留在文本最后 print(data)
写文件:
W 模式以写的状态来打开一个文件,创建一个文件(会覆盖之前文件)
f = open("today2",'w',encoding="utf-8") #文件句柄
f.write("这是刚才写入的文档")
f.write("这是刚才写入的文档,\n") #换行
f.write("我需要换行写")
a 追加
f = open("today2",'a',encoding="utf-8")
打印前五行,小方法
f = open("today2",'r',encoding="utf-8") for i in range(5): print(f.readline())
循环读 文件(小文件)
f = open("today2",'r',encoding="utf-8") for index,line in enumerate(f.readlines()): #循环读一遍,取出每个元素下标 ,注意可读小文件 if index == 9: print('-----------分割线--------') continue print(line.strip()) #去空格,换行
大文件读
f = open("today2",'r',encoding="utf-8") ''' for index,line in enumerate(f.readlines()): #循环读一遍,取出每个元素下标 ,注意可读小文件 if index == 9: print('-----------分割线--------') continue print(line.strip()) #去空格,换行 #for i in range(5): # print(f.readline()) ''' count = 0 for line in f: #内存一行行读 if count == 9: print('-----我是分割线----') count += 1 continue print(line) count += 1
光标移动读
f = open("today2",'r',encoding="utf-8") print(f.tell()) #记录光标所读 print(f.readline()) print(f.tell()) f.seek(0) #光标返回到0位置重新读 print(f.readline())
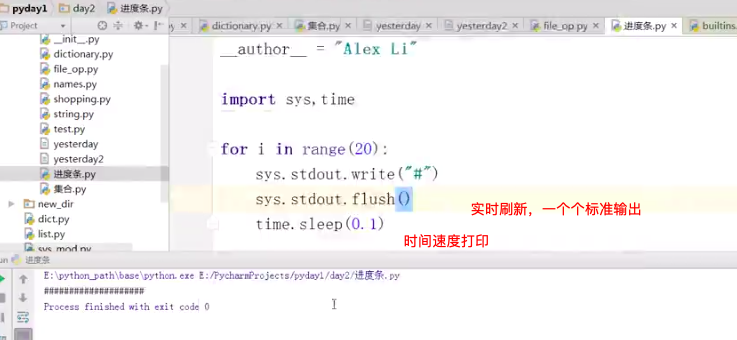
f.flush() # 以write 写时,实时刷新数据在内存上
进度条如下