
1.下载hadoop
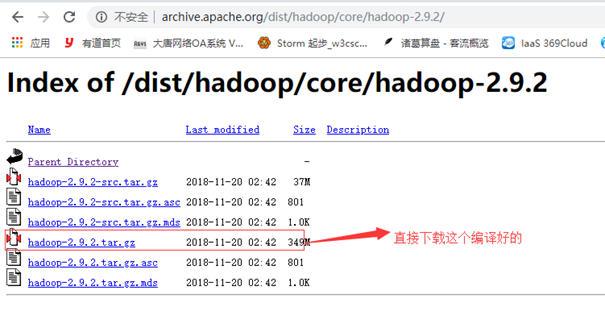
2.用ftp上传到CentOS 7
3.解压(安装)
命令:tar -zxvf hadoop-2.9.2.tar.gz

安装完成
4.配置hadoop-evn.sh
首先配置hadoop-evn.sh,先进入目录cd hadoop-2.9.2/etc/hadoop/,然后编辑vi hadoop-env.sh
在文件末尾加上
export JAVA_HOME=/soft/jdk1.8.0_161/jre #自己的jdk位置
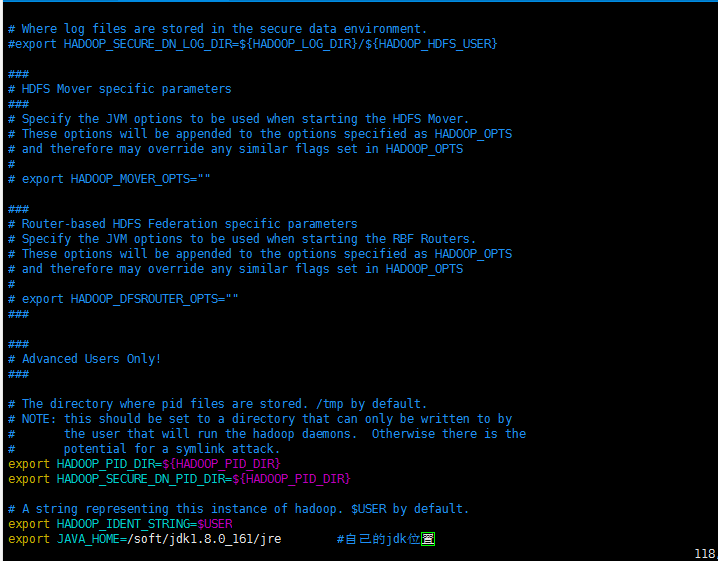
保存 退出
5.验证Hadoop是否可以运行
回到hadoop-2.9.2目录下 cd ../.. 输入bin/hadoop version

6.配置环境变量
vim ~/.bashrc(修改当前用户)或 vim /etc/profile(修改所有用户)
在文件尾部加上:
export HADOOP_HOME=/soft/hadoop-2.9.2 #自己安装的Hadoop路径
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
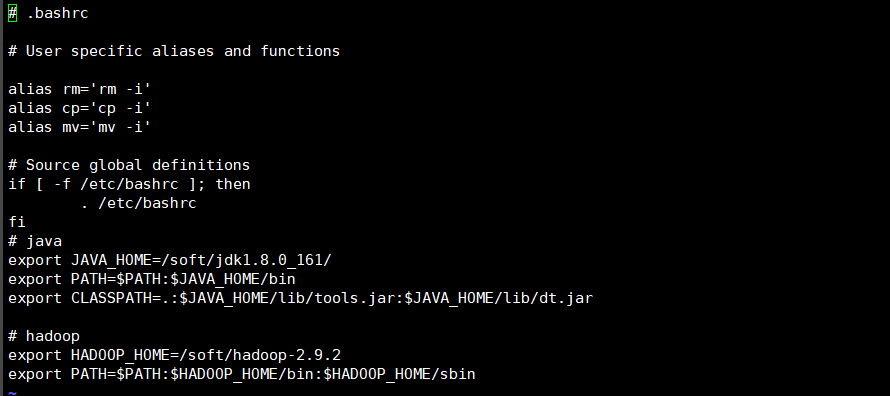
使.bashrc 生效source ~/.bashrc
验证 在任意目录下hadoop version(注意没有-,不是-version)

7.Hadoop核心文件配置
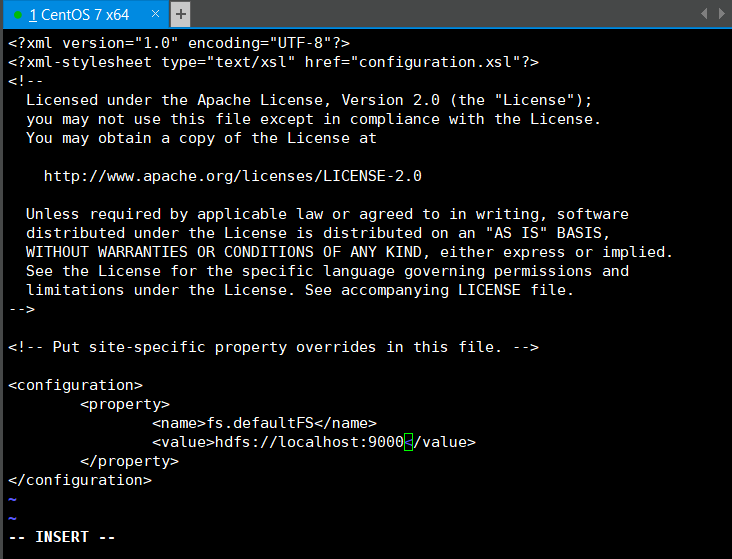
编辑core-site.xml文件 在Hadoop安装目录下vi ./etc/hadoop/core-site.xml
加入:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
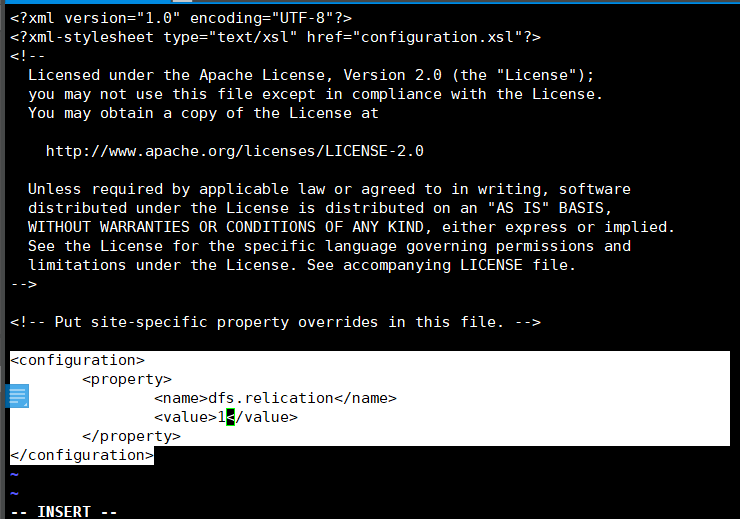
配置hdfs-site.xml文件 在Hadoop安装目录下 vi ./etc/hadoop/hdfs-site.xml
加入:
<configuration>
<property>
<name>dfs.relication</name>
<value>1</value>
</property>
</configuration>
8.ssh免密登录
检查当前系统能够免密登录到自己ssh localhost
如果提示输入密码就代表不支持免密登录,我们需要做相应的修改

- 首先我们需要先生成本地的密钥 在安装目录下输入`ssh-keygen`**(没有空格)**,然后一直回车
- 接下来将本机公钥添加到本机的受信文件中,这里我们使用一个方便的命令:`ssh-copy-id localhost`
- 我们再次使用ssh localhost 命令就不再会出现密码提示了,能够只能登录到系统自身
- 如果想退出系统自身的登录状态,可使用exit命令
(或者(不好使的话)可参考链接:https://blog.csdn.net/u014507244/article/details/53037379)
9.hdfs启动
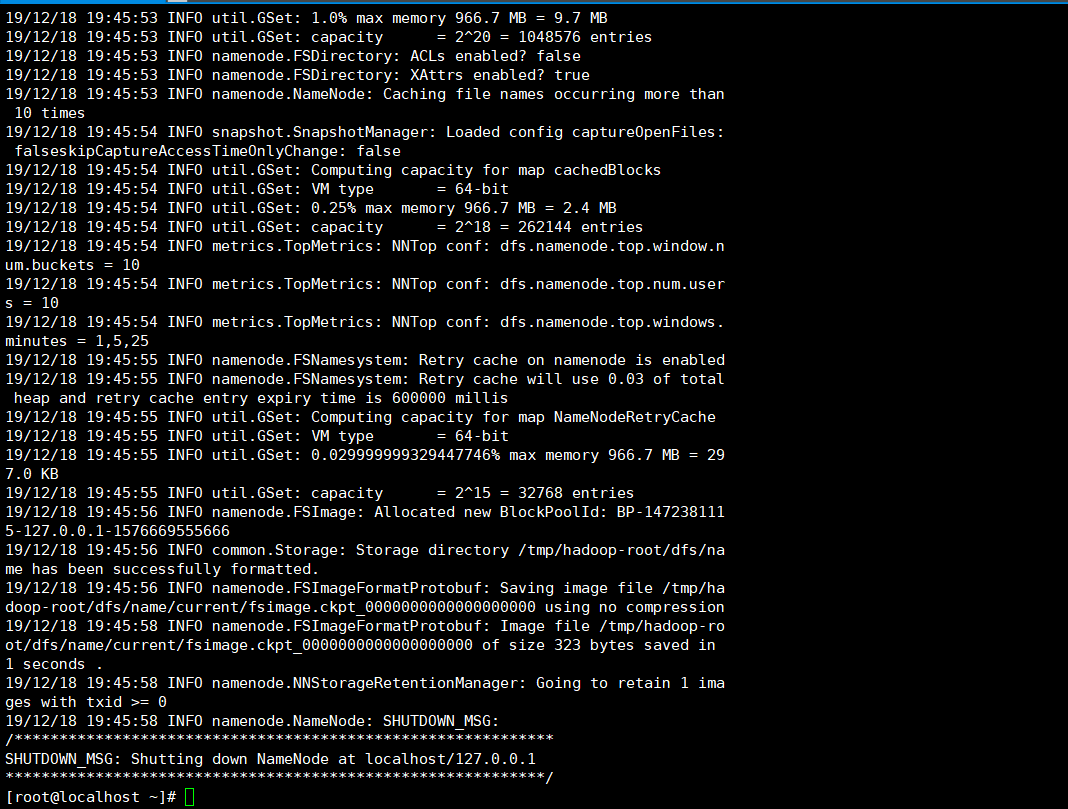
启动hdfs之前我们需要格式化文件系统,只要日志中不出现错误信息就代表格式化成功hdfs namenode -format
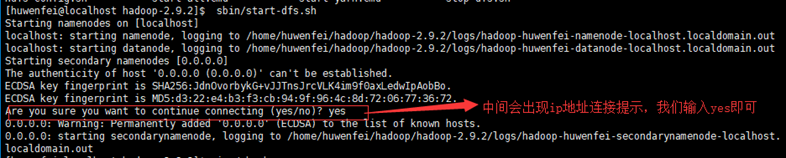
我们使用start-dfs.sh命令启动hdfs系统
启动成功后,我们进入Linux虚拟机,打开火狐浏览器,地址栏中输入localhost:50070就能看到hdfs的概况信息
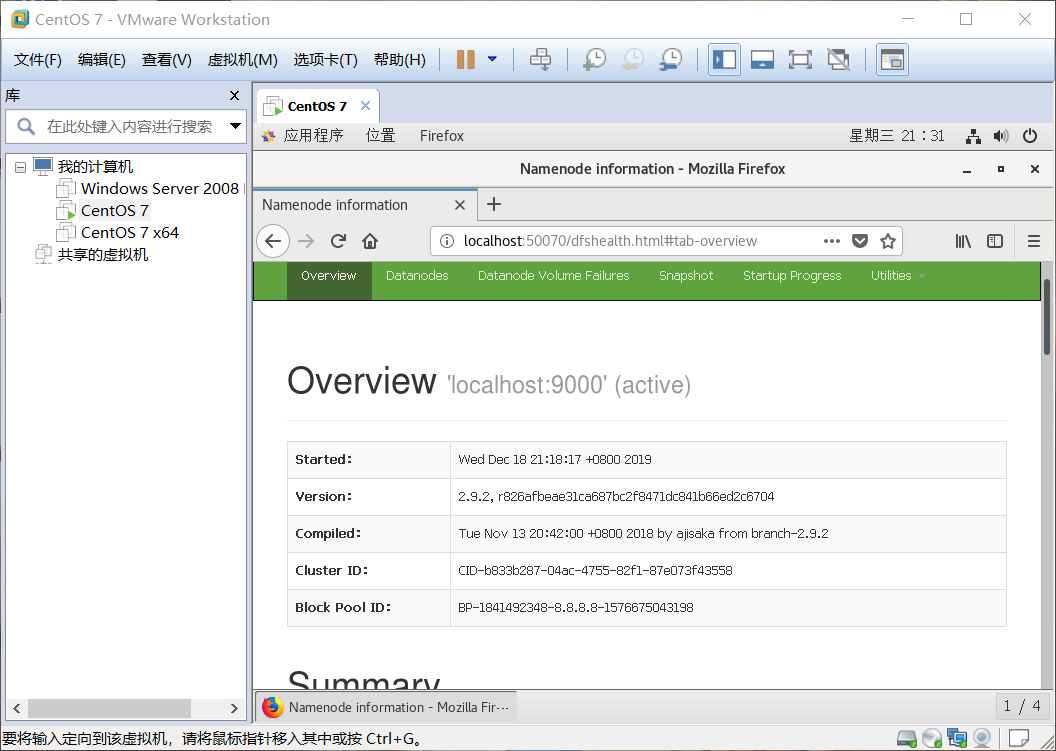
至此,一个最简单的Hadoop单机安装过程就完成了,以此单机环境为基础,我们可以练习一些Hadoop的常用shell命令与hdfs的常用shell命令,以及hdfs的java api
在后面我们会搭建更复杂更强大的Hadoop集群
人生之事岂能尽如人意,生活如戏,哭笑皆由人,悲喜自己定
