


TensorRT推理加速推断并提高吞吐量
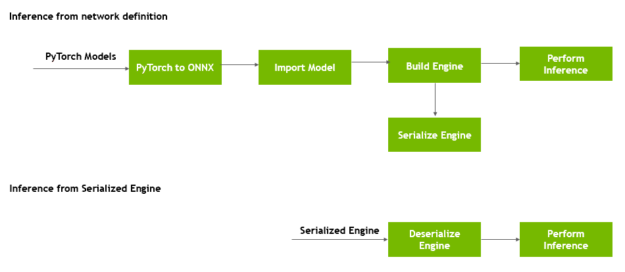
TensorRT 部署案例,四部曲
- 将预训练的pytorch模型转为.onnx模型
- 解析onnx到tensorRT network对象---onnx parser
- 对其优化并生成TensorRT推理引擎(根据输入模型、目标 GPU 平台和其他指定的配置参数)---builder
- 在GPU上实施推理Perform
TensorRT supports both C++ and Python API
吞吐量
batch_nums/sec * batch_size
TensorRT如何实现减少推断延时
- 强大的优化
- 低精度
- 高效内存利用
英伟达官网提供了集成了TensorRT的pytorch镜像
Logger:与engine和builder有关,用来记录生成引擎和推断过程中捕获错误、警告和其他信息
重要的API
createCudaEngine 函数解析 ONNX 模型并将其保存在网络对象
要处理推理时的动态输入维度,必须声明一个引擎生成配置文件。
优化配置文件使您能够设置配置文件的最佳输入、最小和最大尺寸。构建器选择输入张量维数运行时间最低的核,该核对介于最小维数和最大维数之间的所有输入张量维数有效。它还将网络对象转换为 TensorRT 引擎。
- setMaxBatchSize---批大小会影响吞吐量throughput,影响GPU的并行
- setMaxWorkspaceSize---这里可以显示的设置推断时可占用的显存占用空间,这个空间大小关系到TensorRT对模型的优化算法选择,可用空间越大则TensorRT会尝试更多的优化算法,也就更可能找到更快的推断模型优化算法
- execution context---创建引擎之后,还要创建一个 执行上下文 来保存在推理过程中生成的中间激活值
- launchInference
- cudaMemcpyAsync
在调用 launchInference 之后使用 cudaStreamSynchronize 同步函数可以确保 GPU 在访问结果之前完成计算。
可以使用 ICudaEngine 类中的函数查询输入和输出的数量,以及每个类的值和维度
Profile the application(如何评估你的推理引擎)
如何优化推理引擎
- 使用混合精度计算
- 更改工作空间(MaxWorkspaceSize)的大小
- 更改批大小(工作空间可以影响批大小,同时影响对引擎生成的优化)
- 因此,对于引擎的生成可以多次尝试不同的批次及工作空间大小来比较选择具有最大吞吐量的配置
- 重用引擎(对于同一个任务的部署,完成以上之后,只需要将引擎序列化存储,换一个相同的嵌入式硬件只需要直接加载引擎推理即可)------getCudaEngine 函数来加载并使用一个引擎
如果未指定,则默认批处理大小为1,这意味着引擎不会处理大于1的批处理大小
builder->setMaxBatchSize(batchSize);
设置好maxBatchsize之后引擎不接受更大的批量,但允许使用较小的批量。
CUDA 提供轻量级的事件 API 函数,用于创建、销毁和记录事件,以及计算事件之间的时间
可能需要考虑在推理初始化之前和推理完成之后在 GPU 和 CPU 之间传输数据所需的时间。
一般会预取数据到 GPU,然后计算与数据迁移同时进行,可以显著降低数据传输开销。
函数 cudaEventElapsedTime 返回在 CUDA 流中两个过程交叠进行的时间----->即实际计算用时。
launchInference(context, stream, inputTensor, outputTensor, bindings, batchSize);
//Wait until the work is finished
cudaStreamSynchronize(stream);
doInference(context.get(), stream, inputTensor, outputTensor, bindings, batchSize);
// Number of times to run inference and calculate average timeconstexpr int ITERATIONS = 10;
void doInference(IExecutionContext* context, cudaStream_t stream, vector<float> const& inputTensor, vector<float>& outputTensor, void** bindings, int batchSize)
{
CudaEvent start;
CudaEvent end;
double totalTime = 0.0;
for (int i = 0; i < ITERATIONS; ++i)
{
float elapsedTime;
// Measure time that it takes to copy input to GPU, run inference, and move output back to CPU
cudaEventRecord(start, stream);
launchInference(context, stream, inputTensor, outputTensor, bindings, batchSize);
cudaEventRecord(end, stream);
// Wait until the work is finished
cudaStreamSynchronize(stream);
cudaEventElapsedTime(&elapsedTime, start, end);
totalTime += elapsedTime;
}
cout << "Inference batch size " << batchSize << " average over " << ITERATIONS << " runs is " << totalTime / ITERATIONS << "ms" << endl;
}

