编译器,解释器及混合编译
我们编写代码时会得到一个.py结尾的文件,要想运行执行此文件就需要python解释器。
返回顶部
python解释器的构成及其各部分功能
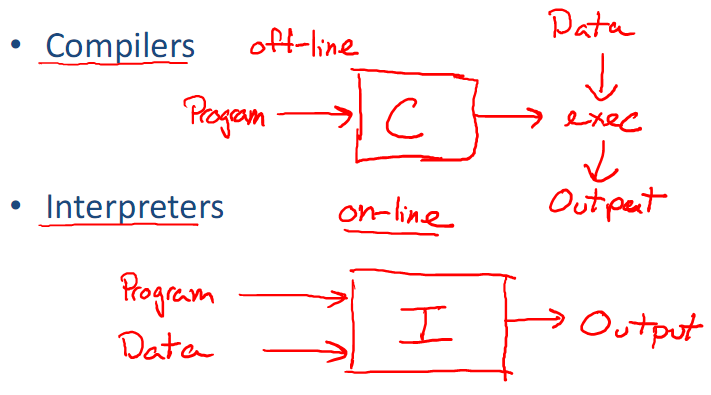
解释器由一个编译器和一个虚拟机构成,编译器负责将源代码转换成字节码文件,而虚拟机负责执行字节码。
所以,解释型语言其实也有编译过程,只不过这个编译过程并不是直接生成目标代码,而是中间代码(字节码),然后再通过虚拟机来逐行解释执行字节码
cpython:是解释器,即我们正在用的python就是cpython解释器
解释器有多种,在ipython窗口就是Ipython解释器.
返回顶部
执行过程原理
- 执行 python XX.py 后,将会启动 Python 的解释器
- python解释器的编译器会将.py源文件编译(解释)成字节码生成PyCodeObject字节码对象存放在内存中。
- python解释器的虚拟机将执行内存中的字节码对象转化为机器语言,虚拟机与操作系统交互,使机器语言在机器硬件上运行。
- 运行结束后python解释器则将PyCodeObject写回到pyc文件中。当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
pyc文件,文件中包含python的magic number(来说明编译时使用的python版本号)、源文件的mtime(使pyc和py文件保持同步)、编译出的code对象
总结
cpu不管你是什么语言,只能运行最终的机器码---最低级的指令集.
Python语言 是:被一个 C 写的解释器CPython解释成机器码由cpu执行,从头到尾都没生成 C 代码。---解释型
而pyx语言(先转换成 .C 中间代码)再被编译成pyd文件,是生成了最终的dll文件的-----编译型
cython:是一种python的扩展语言(支持python和c混编---编写代码中同时含有c和python),可以让python调用C++容器,例如vector. cython混合语言在python中典型代表就是.pyx文件--------编译型语言和解释型共存
Cython 会先把 .PXD .PY .PYW .PYX 文件转换成 .C 中间代码, 再编译成 .PYD 模块文件(最终的dll文件),就可以被python import引入调用了.
编译pyx程序需要的是cl.exe及cython包
包含pyd和python语言的程序就是编译型语言和解释型语言共同执行的情况.
.cu文件
nvcc本质上就是个驱动,去调用cuda tools来完成.cu文件的编译,可以认为nvcc就是编译cuda程序(.cu)的编译器. 而cuda c(.cu)是c语言的扩展,因此也要依赖windows上的c编译器cl.exe.
总结:
nvcc编译cuda程序(.cu)依赖的是cl.exe和cuda tools
总结:
-
基于cpu的python扩展.pyx用gcc编译
-
基于gpu的python扩展.cu用nvcc编译 (nvcc就是cuda程序-cu文件 编译器,底层基于cl.exe(gcc)和cuda tools)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号