


深度估计
自然场景(三维)投射到图片或视频(两维)缺失的维度就是深度depth
包含深度信息的作用:
-
机器人的运动轨迹估计---后续控制策略的基础
-
AR---如宜家物品的售前AR展示

-
图像去雾

-
手机肖像模式

深度信息的获取方式:
- 硬件方式
- 软件方式
硬件方式
双摄像头技术Dual camera technology
双目视觉----通过不同角度的两个相距几mm的摄像头 捕获两张图像(立体图像对),来计算深度信息。(现在手机就是多相机)

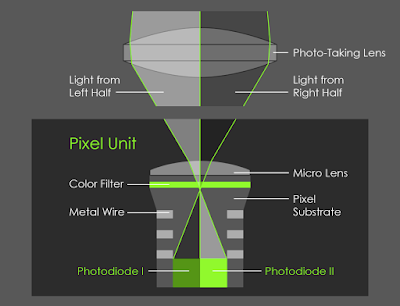
双像素技术,如Dual Pixel Autofocus (DPAF)
每个像素处有两个光电二极管(距离小于1mm),分别捕获图像信号得到立体图像对。 如Google Pixel 2
深度传感器----如红外投射器,激光雷达,超声波传感器等
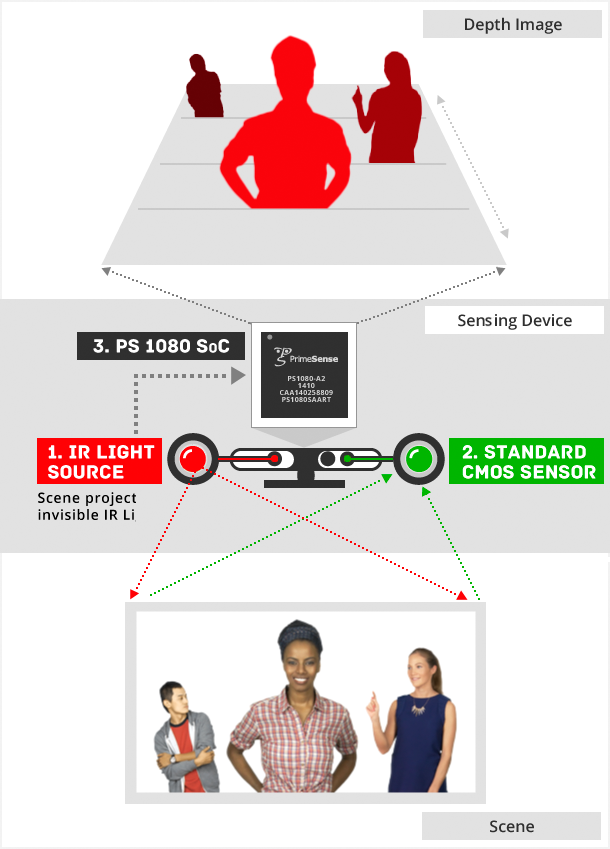
红外投射器:
如Kinect一代利用红外投射仪,在空间投射将红外图案,然后单色CMOS传感器(相距几厘米)接收反射的光线。
计算预期的和接收的IR点位置之间的差以产生深度信息。
激光雷达:
测距原理:激光的飞行时间,同时还会计算激光波的波长变化,提供精确的深度信息
缺点:贵,大

超声波:
测距:波的飞行时间
缺点:受环境噪声影响大
优点:便宜

软件方式
- 多图像方法
相机移动,获取不同位置的两张图像,通过两张图像的关键点匹配重建三维场景,为了更鲁棒还可以通过测量相机方位的变化(用加速计和陀螺仪)来计算两张图像的物理距离。 - 单图像方法
- 2.1 监督学习方法
方法一:
通过RGB-D标签数据训练,也可以是雾图(雾浓度是深度的函数)训练。如利用类似U-net的语义分割网络
改进:用结构化注意力机制 引导条件随机场进行不同尺度特征图的融合,来作为最后卷积层的输入。-----Structured Attention Guided Convolutional Neural Fields for Monocular Depth Estimation

方法二:
将深度估计考虑成image-to-image的翻译问题,常规的图像翻译方法:pix2pix
改进之处:通过 gradient penalty, self-attention and perceptual loss来提高GAN的稳定性及输出质量

- 2.2 无监督学习方法
无监督模型:输入任何左侧图像,输出右侧图像。
再计算两个图像之间的视差:右图像中像素(或块)相对于其在左图像中的位置的位移。使用视差,再根据相机的焦距和两个图像之间的距离来计算深度信息。

局限性
监督方法:
基于学习的方法(尤其是监督方法)的局限性在于泛化能力不好,可能无法很好地推广到所有用例。
分析方法可能没有足够的信息来根据单个图像创建鲁棒的深度图。但是,在某些情况下,合并领域知识可以帮助提取深度信息。
例如,考虑基于暗通道先验的除雾方法-----作者观察到大多数模糊图像局部图像至少在一个通道中具有低强度像素,利用这些信息创建了一种分析性除雾方法。由于雾度是深度的函数,因此通过将去雾后的图像与原始图像进行比较,可以轻松恢复深度。
无监督方法:
无监督方法的明显局限性在于,它们需要其他附加信息,例如相机焦距和传感器数据来测量图像的位移。但从理论上讲,它们确实比受监督的方法提供了更好的泛化能力。

