移动端和边缘端的深度学习概述
某些应用场景要求低延时,高安全性及考虑长期成本效益,此时将模型托管在云端就不再是最好的解决方案。
边缘计算相比云计算的优势
- 带宽和时延
显然调用云端服务会有一个信息往返的时间花费。
比如自动驾驶,大的延时可能会引发事故,因为一个突然出现的目标可能仅仅在几帧的时间内。
因此英伟达提供定制化的板载计算设备来进行边缘端的推理。
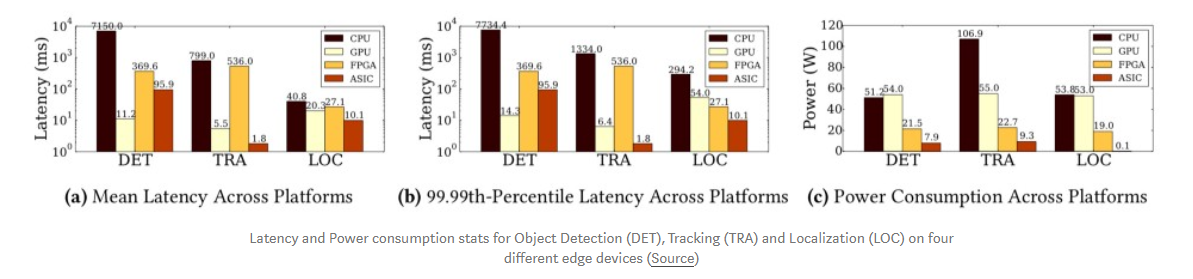
当多个设备连接在同一个网络中时,由于天然的信道竞争导致有效带宽降低。边缘计算则可显著减少此问题。

eg:
- 视频会议需要2M带宽
- 两路视频监控需要5-25M带宽
- 360°全景视频需要10-50带宽
以多路设备的视频数据处理为例,云计算需要上传到云端推理计算,带宽需要很大,边缘计算优势显著。
- 安全性及去中心化
云服务器易受黑客攻击,且数据上传云端有安全性问题。
多个边缘设备的部署相比云服务,拥有去中心化的优势,更难被攻击。
- 特定作业情况(定制化)
如工业场景需要多个不同模型的情况,如果采用云计算则需要托管多个模型,会带来费用的明显增加。
- 边缘端并行训练
多边缘端的数据可以在线学习并行训练
- 冗余性
边缘部署 保证了功能的健壮性。一个节点(边缘设备)故障不影响其他设备
- 长远的经济效益
边缘端更小,尤其可批量定制的边缘设备。
边缘设备的特点
内存及算力不足
DL网络的显著特点:大模型,高算力需求
解决方案
推理方面
-
关闭训练时产生的Graph
深度学习框架如TF,在训练时会大量建图来加速训练,但是对于推理却无用,推理时关闭图可以减小模型。 -
剪枝和截断
- 训练后的模型中有大部分没用的神经元(接近0),通过对这类节点的剪枝可以节省内存。 谷歌的Learn2Compress发现可以在保持97%准确率的前提下,将模型压缩一倍。
- 大部分框架采用32位精度训练,边缘端进行精度截取比如采用8位就可以压缩4倍空间。
通常,精度截断如果是完全随机的,误差很有可能互相抵消。但是,零广泛用于填充、辍学和 ReLU。在低精度浮点格式中无法精确表示零,因此可能会在性能中引入整体偏差。
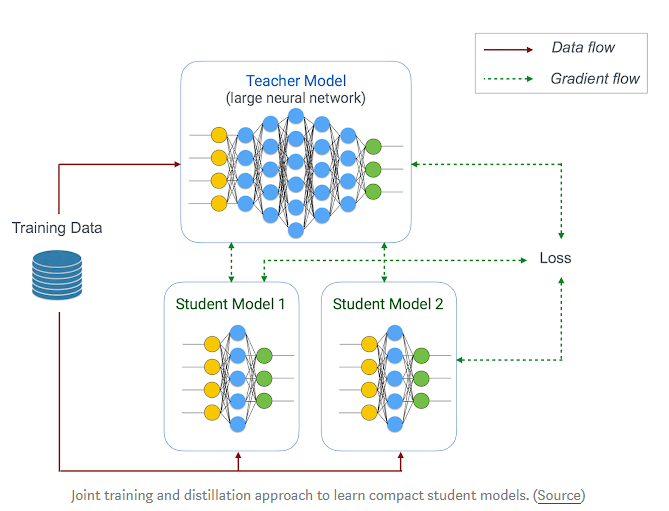
- 模型蒸馏
本质上就是用训练出的大模型(真值)去训练出小模型(预测模型)
Learn2Compress也用到了这个手段做模型压缩,结合迁移学习,可以在不损失太多精度的情况下压缩模型
- 采用优化的芯片设计
- Vision Processing Units (VPUs):例如google的kits及intel的Neural Compute Stick,号称低功耗 高性能
- FPGA: 比GPU功耗低,可接受<32位的精度,但是性能比GPU差
- ASIC:对于大规模部署来说,最好的解决方案---特定场景定制的专用芯片(CPU是通用计算芯片)一般是AI芯片,如阿里的含光800,地平线征程系列。设计类似Nvidia V100微处理器架构来加速矩阵乘法。----高研发时间成本
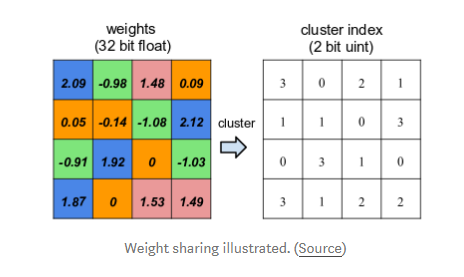
- 权值共享
首先对权重量化,然后采用2位的索引查询一个共享数据来降低模型占用
-
编码
在模型剪枝和量化后,还可以再用霍夫曼编码以低bit位的方式表示权重中的高频权值,因为霍夫曼编码后的字符串占用比普通字符串小。
现在有一些有损压缩和无损压缩的深度压缩研究,但是编码增加了额外的解码时间。 -
实现了上述方法的推理工具
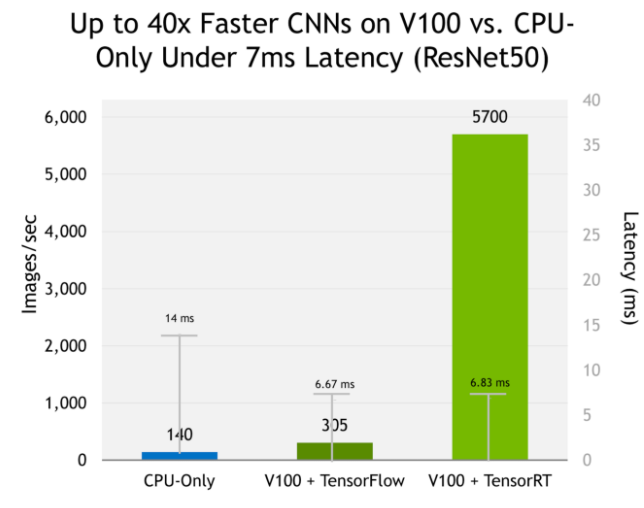
Tensor-RT:
训练方面
- 神经网络架构设计
高效的参数网络:
- 深度卷积:如1*1卷积减少输入下层的通道数
- NxN 卷积因子化为 Nx1 和 1xN 卷积的组合。节省大量空间,同时提高计算速度
如MobileNet, SqueezeNet
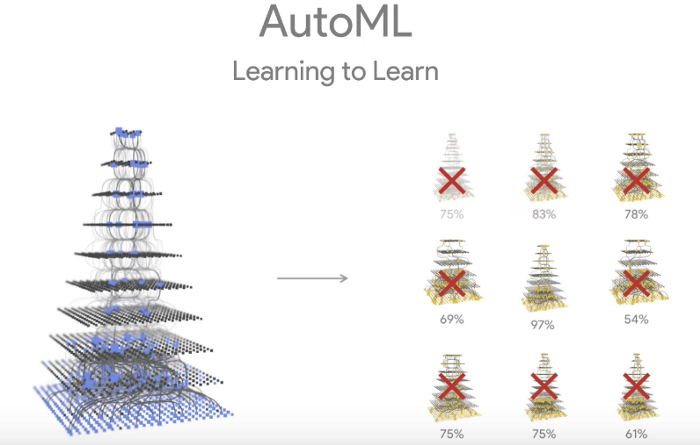
Neural Architecture Search-----神经网络架构搜索
如NAS-Net
搜索目标:高精确率,高速,低内存占用
如Google的AUto-ML项目:
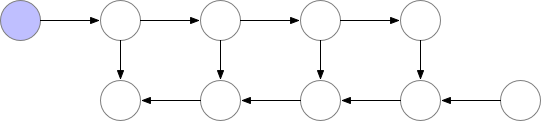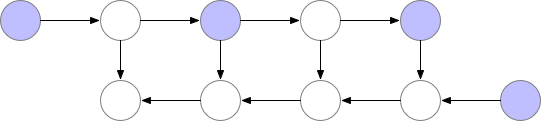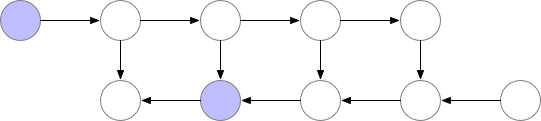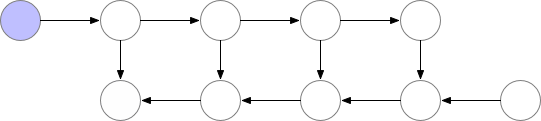
- 保存部分 梯度检查节点---checkpoint
通常训练时,前向传播过程中会保存全部值,占用大量内存;可以考虑不保存正向传播的中间值,只在反向传播时根据需要重计算。
缺点:随着网络加深及复杂化,需要的再计算算力剧增
折中的方法:保存部分中间值---checkpoints,大大减小网络的内存占用。
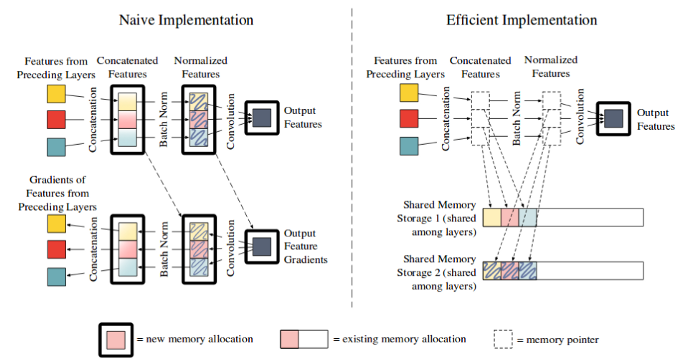
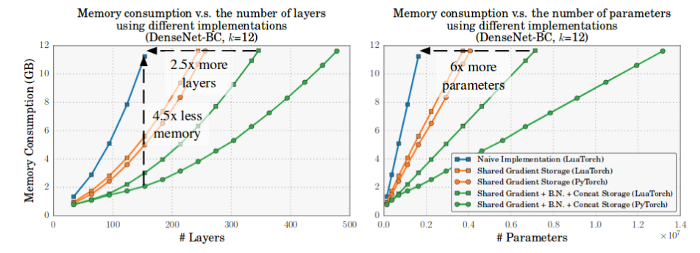
- 空间换时间
典型的如DenseNet中的拼接及BN的高效实现。GPU卷积的高效计算 需要数据的连续存储,因此:
- 对于不是时间密集型操作的拼接操作及BN操作,可以用再计算来代替直接存储,节省内存
- 采用索引共享内存空间的形式连续存储