
anchor free 目标检测(二)----基于keypoints的CenterNet
将目标检测框的检测定义为其边界框中心点,利用 关键点估计 寻找中心点,然后其他的属性(如单目3D定位,姿势估计以及方向等)都基于中心点信息直接回归。
不需要像cornerNet那样去group和separate.
但是3D目标检测的深度depth和航向Orientation都不容易直接回归。
航向:作者回归了两组变量,每组4个标量,一对用来分类,一对用来回归这个组的角度。
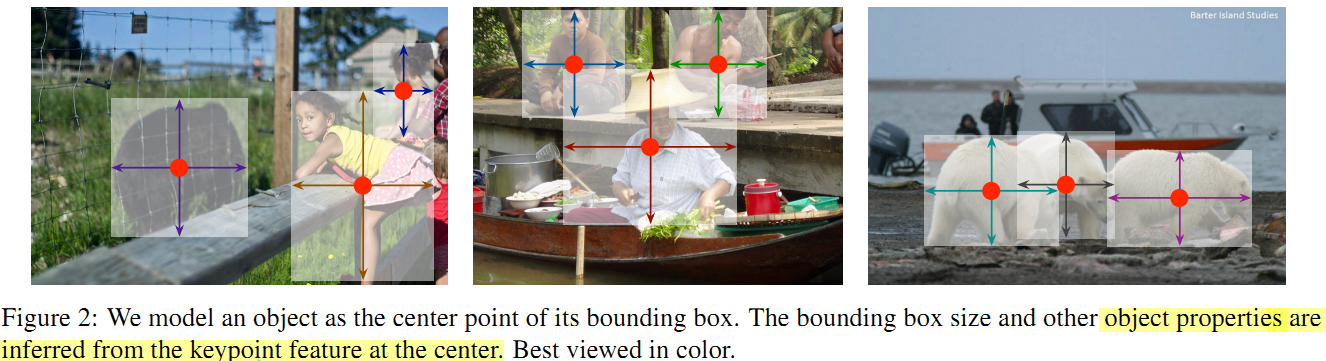
For 3D bounding box estimation, we regress to the object absolute depth, 3D bounding box dimensions, and object orientation. For human pose estimation, we consider the 2D joint locations as offsets from the center and directly regress to them at the center point location。
对3D边界框估计:我们回归得到目标绝对深度,3D框的尺寸,目标的方向角。
对于人体姿势估计: 我们通过直接回归2D关节点到中心点的偏移距离得到。

在本文中作者也测试了deformable convolution----可变形卷积
传统的卷积都是直接对应滑窗覆盖卷积,可变行卷积是指:如一个3*3的核卷积时,每个元素可以去卷积对应位置的某个偏移位置的像素点。并不是卷积核变形了,而是卷积核在特征图上的采样点可以自由变化。
KITTI:3D检测
COCO:人体姿势
F. Yu, D. Wang, E. Shelhamer, and T. Darrell. Deep layer aggregation. In CVPR, 2018.
优势:
**基于关键点估计网络(backbone:DLA-34D)寻找目标中心点并回归得到尺寸。**
**算法简单高效准确,不需任何NMS后处理端到端微分。**
**思路通用,应用广泛,可以在一次前向传播得到如姿势估计,3D航向,深度,尺寸等**

