


pytorch(三)建立模型(网络)
前置知识:OOP-面向对象编程(核心:继承和多态)
我们知道,程序分为代码code和数据data两部分,而类完成了这两部分的封装。
面向对象的代表就是类,类的属性attribute即是封装的数据data,类的方法method即是封装的代码code.
神经网络中每一层就是面向对象编程的最好代表:层既涉及有数据(属性)的权重,又有变换操作的代码(方法)。
(类实例化就会自动调用构造函数,但是类的方法要调用方法才会执行。)
所有特殊的面向对象编程的python方法名称前后都有“__”。
- __init__: 对象属性初始化
- __repr__: 对象的字符串表达(print(object_name)输出的结果)
- __call__: 调用类实例就会自动调用的特殊方法,很有用,pytorch在__call__方法下实现了self.forward的调用,pytorch的模型(包括layer和network)的实现都利用了__call__方法.
简而言之,建立模型只需3步:
- extend the nn.Module base class-----nn.Module
- define layers as class attributes-----torch.nn
- implement forward method------nn.functional
class Network(nn.Module):#1.扩展基类。继承基类的格式-----跟一个带基类名称的括号
def __init__(self):#2.在初始化函数里,通过torch.nn定义类的layer属性
super().__init__()
#这个super().__init__()是指调用父类的构造函数,其最大的优势是在多继承的时候。会逐级的遍历调用父类的构造函数,如果是多个父类继承自一个爷爷类,那么只会调用一次爷爷类的构造函数。
#如果不用super(),而是用显示的写法去调用父类的构造函数,在多继承时会重复写多次,每个级别每个父类都要写一行代码,如base.__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=12, kernel_size=5)
self.fc1 = nn.Linear(in_features=12 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=60)
self.out = nn.Linear(in_features=60, out_features=10)
def forward(self, t):#3.通过属性配合nn.functional--API实现forward方法
# implement the forward pass
return t
CNN的Layer
每个layer都封装了两部分东西:
- layer前向传播函数的定义
- layer上附着的权重tensor
nn.Module类实现了对每个layer上tensor的追踪,因此只要我们是扩展继承nn.Module类得到的模型,那么我们给模型分配的属性layer,模型都会将其上tensor注册为可学习参数,并且追踪。
CNN中的parameter
Parameter:就是占位符,在训练的时候会有数值(argument)传入.
Hyperparameters are parameters whose values are chosen manually and arbitrarily.
超参又分为数据依赖型超参和独立超参:
- 第一个卷积层的input channel
- 最后一个全连接层的输出长度
实例化之前定义的Network
network = Network()
print(network)
"""
#这里就是nn.module类通过 **覆写** 基类(python的对象)的__repr__方法实现的,字符表达函数。
#覆写: 子类觉得基类的一个方法不够满足要求,去重新定义一个同名的方法。
Network(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 12, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=192, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=60, bias=True)
(out): Linear(in_features=60, out_features=10, bias=True)
)
"""
访问网络中的layer
network.conv1#通常用 点符号 来打开一个对象,获取内部的信息。
network.fc1
访问网络中的权重weights
network.conv1.weight
Parameter containing:#这里是如何实现的??? parameter类是继承的pytorch的tensor类,nn,module会寻找追踪所有的parameter实例。而nn.module类的属性如con2d和linear,weight tensor和bias tensor都是parameter类的实例,tensor只是他们的父类。
tensor([[[[ 0.0692, 0.1029, -0.1793, 0.0495, 0.0619],
[ 0.1860, 0.0503, -0.1270, -0.1240, -0.0872],
[-0.1924, -0.0684, -0.0028, 0.1031, -0.1053],
[-0.0607, 0.1332, 0.0191, 0.1069, -0.0977],
[ 0.0095, -0.1570, 0.1730, 0.0674, -0.1589]]],
[[[-0.1392, 0.1141, -0.0658, 0.1015, 0.0060],
[-0.0519, 0.0341, 0.1161, 0.1492, -0.0370],
[ 0.1077, 0.1146, 0.0707, 0.0927, 0.0192],
[-0.0656, 0.0929, -0.1735, 0.1019, -0.0546],
[ 0.0647, -0.0521, -0.0687, 0.1053, -0.0613]]],
[[[-0.1066, -0.0885, 0.1483, -0.0563, 0.0517],
[ 0.0266, 0.0752, -0.1901, -0.0931, -0.0657],
[ 0.0502, -0.0652, 0.0523, -0.0789, -0.0471],
[-0.0800, 0.1297, -0.0205, 0.0450, -0.1029],
[-0.1542, 0.1634, -0.0448, 0.0998, -0.1385]]],
[[[-0.0943, 0.0256, 0.1632, -0.0361, -0.0557],
[ 0.1083, -0.1647, 0.0846, -0.0163, 0.0068],
[-0.1241, 0.1761, 0.1914, 0.1492, 0.1270],
[ 0.1583, 0.0905, 0.1406, 0.1439, 0.1804],
[-0.1651, 0.1374, 0.0018, 0.0846, -0.1203]]],
[[[ 0.1786, -0.0800, -0.0995, 0.1690, -0.0529],
[ 0.0685, 0.1399, 0.0270, 0.1684, 0.1544],
[ 0.1581, -0.0099, -0.0796, 0.0823, -0.1598],
[ 0.1534, -0.1373, -0.0740, -0.0897, 0.1325],
[ 0.1487, -0.0583, -0.0900, 0.1606, 0.0140]]],
[[[ 0.0919, 0.0575, 0.0830, -0.1042, -0.1347],
[-0.1615, 0.0451, 0.1563, -0.0577, -0.1096],
[-0.0667, -0.1979, 0.0458, 0.1971, -0.1380],
[-0.1279, 0.1753, -0.1063, 0.1230, -0.0475],
[-0.0608, -0.0046, -0.0043, -0.1543, 0.1919]]]],
requires_grad=True
)
#可以看到pytorch源码中parameter类对__repr__的重写
def __repr__(self):
return 'Parameter containing:\n' + super(Parameter, self).__repr__() #这里调用了parameter所有父类的__repr__方法。
权重tensor的shape
network.conv1.weight.shape
torch.Size([6, 1, 5, 5]) #依次是out_channels(number of filters),input_channels(其实就是本层卷积核的深度depth),filter-heigth,filter-width
Matrix Muliplication
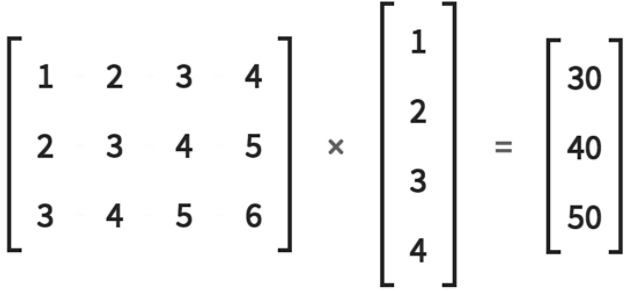
w * x = y
以第一线性层为例,线性层w是一个矩阵,其行数就是输入x被(一个三维的空间基向量,w每行就是一个基向量)线性映射后降低的维数。一个4维的vec经线性映射后被降到3维。
获取网络中的参数
#method 1
for param in network.parameters():
print(param.shape)
#output:
torch.Size([6, 1, 5, 5])
torch.Size([6])
torch.Size([12, 6, 5, 5])
torch.Size([12])
torch.Size([120, 192])
torch.Size([120])
torch.Size([60, 120])
torch.Size([60])
torch.Size([10, 60])
torch.Size([10])
# method2
for name, param in network.named_parameters():
print(name, '\t\t', param.shape)
conv1.weight torch.Size([6, 1, 5, 5])
conv1.bias torch.Size([6])
conv2.weight torch.Size([12, 6, 5, 5])
conv2.bias torch.Size([12])
fc1.weight torch.Size([120, 192])
fc1.bias torch.Size([120])
fc2.weight torch.Size([60, 120])
fc2.bias torch.Size([60])
out.weight torch.Size([10, 60])
out.bias torch.Size([10])
callable的layer和network
都是通过覆写了python面向对象的__call__方法实现。
比如nn.module以及所有的layer(如conv,linear)中的__call__方法调用了self.forward(),但是并没有实现这个方法,是个抽象类。
因此我们继承nn.module需要实现这个forward方法,继而实现了调用网络实例(Network,而不是Network.forward())或者layer 类实例(self.conv(tensor),而不是self.conv.forward(tensor))就可以直接前向传播的效果。
测试时关闭梯度跟踪
torch.set_grad_enabled(False) #pytorch是动态图,关闭梯度跟踪可以减少内存花费
单个batch数据的前向传播过程
"""
按传统的多层神经网络来看,输入层就是1张图片的像素,输出层是1张图片的类别预测向量。
一个batch的完成实际是被分成多层神经网络并行化执行batch次完成的。
"""
data_loader = torch.utils.data.DataLoader(
train_set, batch_size=10)
batch = next(iter(data_loader))
images, labels = batch
images.shape
#torch.Size([10, 1, 28, 28])
labels.shape
#torch.Size([10])
preds = network(images)
preds.shape
#torch.Size([10, 10])
preds
#tensor(
[
[ 0.1072, -0.1255, -0.0782, -0.1073, 0.1048, 0.1142, -0.0804, -0.0087, 0.0082, 0.0180],
[ 0.1070, -0.1233, -0.0798, -0.1060, 0.1065, 0.1163, -0.0689, -0.0142, 0.0085, 0.0134],
[ 0.0985, -0.1287, -0.0979, -0.1001, 0.1092, 0.1129, -0.0605, -0.0248, 0.0290, 0.0066],
[ 0.0989, -0.1295, -0.0944, -0.1054, 0.1071, 0.1146, -0.0596, -0.0249, 0.0273, 0.0059],
[ 0.1004, -0.1273, -0.0843, -0.1127, 0.1072, 0.1183, -0.0670, -0.0162, 0.0129, 0.0101],
[ 0.1036, -0.1245, -0.0842, -0.1047, 0.1097, 0.1176, -0.0682, -0.0126, 0.0128, 0.0147],
[ 0.1093, -0.1292, -0.0961, -0.1006, 0.1106, 0.1096, -0.0633, -0.0163, 0.0215, 0.0046],
[ 0.1026, -0.1204, -0.0799, -0.1060, 0.1077, 0.1207, -0.0741, -0.0124, 0.0098, 0.0202],
[ 0.0991, -0.1275, -0.0911, -0.0980, 0.1109, 0.1134, -0.0625, -0.0391, 0.0318, 0.0104],
[ 0.1007, -0.1212, -0.0918, -0.0962, 0.1168, 0.1105, -0.0719, -0.0265, 0.0207, 0.0157]
]
)
preds.argmax(dim = 1)
# tensor([5, 5, 5, 5, 5, 5, 4, 5, 5, 4])
labels
# tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])
#计算batch内预测标签正确的个数
pres.argmax(dim = 1).eq(labels)
# tensor([0, 0, 0, 0, 0, 0, 0, 0, 1, 0], dtype=torch.uint8)
pres.argmax(dim = 1).eq(labels).sum()
# tensor(1.)
pres.argmax(dim = 1).eq(labels).sum().item() #get_number_correct
# 1

