Python3 Scrapy 框架学习
1.安装scrapy 框架
windows 打开cmd输入
pip install Scrapy2.新建一个项目:
比如这里我新建的项目名为first
scrapy startproject first然后看一些目录结构
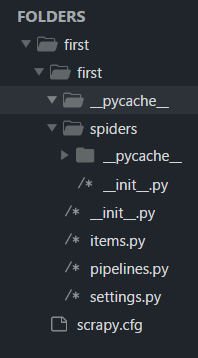
首先在项目目录下有一个scrapy.cfg 文件,这个文件是关于整个项目的一些配置,这个具体后面再说
然后是一个项目同名的文件夹,里面具体文件作用如下:
__init__.py 初始化信息
items.py 作为爬虫项目的数据容器文件,主要用来定义我们要获取的数据
pipelines.py 爬虫项目的管道文件,主要用来对items 里面定义的数据进行进一步的加工处理
settings.py 文件为爬虫项目的设置文件,主要为爬虫项目的一些设置信息
然后下一层的spiders 文件夹里面放置一些爬虫,当然现在里面什么都没有,因为我们还没有新建一个爬虫
这里介绍一下全局命令 和项目 命令
全局命令:不在scrapy项目里就可以使用的命令
项目命令:必须在scrapy项目中才可以使用的命令
全局命令:
注意网址一定要加上http://
fetch : scrapy fetch 网址(不显示调试信息可以加 --nolog 参数)
runspider: scrapy runspider 爬虫(现在项目中没有爬虫,后面具体再讲)
settings:scrapy settings --get 配置项(后面具体再讲)
shell:scrapy shell 网址(在shell终端里面处理爬下来的数据)
view:scrapy view 网址 (将网址数据趴下来并在浏览器中打开)
项目命令:
bench:scrapy bench(测试本地硬件的性能)
genspider:scrapy genspider 爬虫的文件名 定义爬取的域名(scrapy genspider baidu baidu.com)
另外:
-l :查看可以使用的模板 (scrapy genspider -l)
-d:查看模板内容 (scrapy genspider -d basic)
-t:使用模板 (scrapy genspider -t basic 爬虫名 定义爬取的域名)
check:scrapy check 爬虫名(使用合同contract的方式对爬虫进行测试)
crawl:scrapy crawl 爬虫名(启动爬虫,不显示调试信息可以加--nolog参数)
list:scrapy list(显示项目中有哪些爬虫)
edit (这个命令在windows上用不了所以我就不介绍了)
持续更新。。。。。。。。。
本文来自博客园,作者:Hello_wshuo,转载请注明原文链接:https://www.cnblogs.com/Hellowshuo/p/15622297.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号