基于node实现CSDN博客导出为markdown
目录
前言
这段时间准备搭建自己的博客挂到服务器上,于是想着把博客平台的文章导出,然而CSDN没有博客导出功能,在网上搜的方式是用博客搬家导入博客园然后导出为xml文件,由于xml文件也需要解析,而且操作方式并不简单,所以写了一个服务将CSDN的博客导出为md格式文件
准备工作
- node环境
依赖:
- axios(http请求)
- cheerio(html解析)
- html-to-md(HTML转换成md)
- single-line-log(单行显示log,用于进度条加载)
实现过程
问题一:通过community/home-api/v1/get-business-list接口可以获取到个人博客的列表,请求采用分页懒加载,并且分页大小是20,请求详情时会做请求并发拦截,同一个ip短时间只能请求一次,所以在拿数据时需要做个延时,或者一篇一篇请求(我这里加了个进度条,一篇一篇请求)
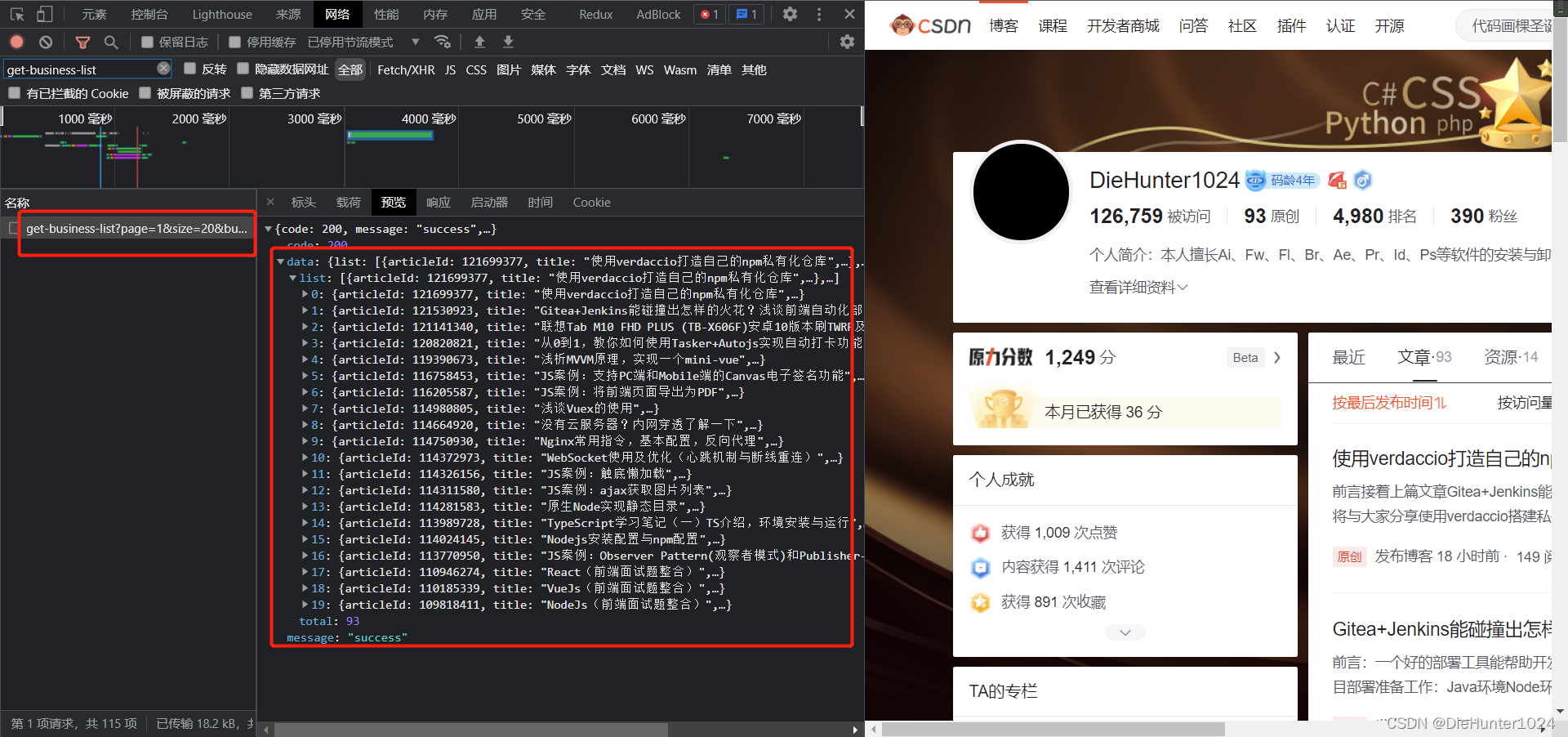
问题二:生成markdown文件名时注意标题,Windows系统文件名不支持“\/:*?\"<>|”等特殊字符

此外暂时没遇到其他问题
下面进入到实现过程
- 运行前使用node环境传递参数
在package.json脚本中配置启动命令:node server -type:csdn -id:time_____
其中type表示博客导出平台方便后续拓展,id是用户名 - 通过process.argv获取node环境下上述参数,并使用外观模式针对不同博客平台进行分离
- 初始化axios拦截器,并分页请求文章列表接口获取文章基本数据
- 拿到数据后爬取文章详情页面的博客内容
- 将博客信息转换成markdown格式文件并输出至文件夹
代码如下,其中引入的MessageCenter 是发布订阅消息中心
const axios = require("axios");
const cheerio = require("cheerio");
const html2md = require("html-to-md");
const singleLineLog = require("single-line-log").stdout;
const path = require("path");
const fs = require("fs");
const { MessageCenter } = require("./lib/MessageCenter");
// 配置默认值
const defaultVal = {
type: "csdn",
id: "time_____",
};
// 各类博客的配置项
let blogConfig = {
csdn: {
// 博客分页:page:第几页,size:分页大小,businessType:排序方式,blog表示博客
pageConfig: {
page: 1,
size: 20,
businessType: "blog",
},
totalPage: 1, //总页数
blogList: [],
// 博客列表
blogListUrl:
"https://blog.csdn.net/community/home-api/v1/get-business-list",
// 获取博客列表
getBlogList() {
return axios.get(this.blogListUrl, {
params: {
username: global.id,
...this.pageConfig,
},
});
},
getBlogItem(blog) {
return axios.get(blog);
},
// 爬取数据的标签,有兴趣自己可以加
getBlogInfo: {
getContent: ($) => $("#content_views").html(),
getTagsCategory: ($) => {
const target = $(".tag-link");
let tagsCategory = {
tags: [],
category: [],
};
for (let i = 0; i < target.length; i++) {
const tag = target[i].children[0]["data"];
// 通过属性data-report-click判断分类和标签
(Object.keys(target[i].attribs).includes("data-report-click") &&
tagsCategory["tags"].push(tag)) ||
tagsCategory["category"].push(tag);
}
return tagsCategory;
},
},
},
};
// 全局变量
let global = {};
// 异步函数
const asyncFunction = {
// 分页获取博客列表
getBlogList: async () => {
const { data } = await blogConfig[global.type].getBlogList();
blogConfig[global.type].totalPage = getTotalPage(
data.total,
blogConfig[global.type].pageConfig.size
);
blogConfig[global.type].blogList = concatList(
data.list,
blogConfig[global.type].blogList
);
data.list.forEach((_) => console.log(_.title));
if (isInTotalPage()) {
console.log(
`获取列表成功,共${blogConfig[global.type].blogList.length}篇文章`
);
return MessageCenter.emit(
"getBlogInfo",
blogConfig[global.type].blogList
);
}
await asyncFunction["getBlogList"]();
},
//批量获取博客详情
getBlogInfo: async (blogList, count = 0, total) => {
!total && (total = blogList.length);
const blogItem = blogList[count];
if (count++ >= total) {
console.log("获取文章内容成功");
return MessageCenter.emit("loadBlog", blogList);
}
// 进度条
progressBar("获取文章内容中", count / total);
blogItem.htmlContent = await blogConfig[global.type].getBlogItem(
blogItem.url
);
asyncFunction["getBlogInfo"](blogList, count, total);
},
// 生成博客文件
loadBlog: async (blogList) => {
const getTagsCategory = blogConfig[global.type].getBlogInfo.getTagsCategory;
const content = blogConfig[global.type].getBlogInfo.getContent;
await Promise.all(
blogList.map((_) => {
const $ = cheerio.load(_.htmlContent);
const { tags, category } = getTagsCategory($);
return createMdFile(_.title, content($), _.postTime, tags, category);
})
);
MessageCenter.emit("loadFinish");
},
loadFinish() {
console.log("导出成功");
},
};
// 初始化script参数
(function (argv) {
global.type = getValue(filterArgs(argv, "type")[0], ":") || defaultVal.type;
global.id = getValue(filterArgs(argv, "id")[0], ":") || defaultVal.id;
initAxios();
init();
MessageCenter.emit("getBlogList");
})(process.argv);
function init() {
MessageCenter.on("getBlogList", asyncFunction["getBlogList"]);
MessageCenter.on("getBlogInfo", asyncFunction["getBlogInfo"]);
MessageCenter.on("loadBlog", asyncFunction["loadBlog"]);
MessageCenter.on("loadFinish", asyncFunction["loadFinish"]);
}
// 生成进度条
function progressBar(label, percentage, totalBar = 50) {
const empty = "░";
const step = "█";
const target = (percentage * totalBar).toFixed();
let bar = [];
for (let i = 0; i < totalBar; i++) {
(target >= i && (bar[i] = step)) || (bar[i] = empty);
}
singleLineLog(
`${label || ""} ${bar.join("")}${(100 * percentage).toFixed(2)}%`
);
}
// 获取页数
function getTotalPage(total, size) {
return Math.round(total / size);
}
// 是否是最后一页
function isInTotalPage() {
return (
blogConfig[global.type].pageConfig.page++ >=
blogConfig[global.type].totalPage
);
}
// npm script参数判断
function filterArgs(args, key) {
return args.filter((_) => _.includes(key));
}
// 拆分字符串
function getValue(str, keyWord) {
return typeof str === "string" && str.split(keyWord)[1];
}
// 替换特殊字符
function replaceKey(str) {
const exp = /[`\/:*?\"<>|\s]/g;
// /[`~!@#$^&*()=|{}':;',\\\[\]\.<>\/?~!@#¥……&*()——|{}【】';:""'。,、?\s]/g;
return str.replace(exp, " ");
}
// 连接列表数组
function concatList(list, targetList) {
return [...targetList, ...list];
}
// 生成博客md,title文章标题, content文章内容, date文章时间, tags文章标签, category文章分类
function createMdFile(title, content, date, tags, category) {
return writeFile(
`${replaceKey(title)}.md`,
`${createMdTemplete(title, date, tags, category)}${html2md(content)}`,
"./blog/"
);
}
// md文件模板配置
function createMdTemplete(title, date, tags, category) {
return `---\ntitle: ${title} \ndate: ${date} \ntags: [${tags}] \ncategory: [${category}] \n---\n`;
}
// 写入文件
function writeFile(filename, data, dir) {
return new Promise((resolve, reject) => {
fs.writeFile(
path.join(__dirname, dir + filename),
data,
(err) => (err && reject(err)) || resolve(err)
);
});
}
//响应拦截器
function initAxios() {
axios.interceptors.response.use(
function ({ data, status }) {
if (data.code === 200 || status === 200) {
return data;
}
return Promise.reject(data);
},
function (error) {
// 对响应错误做点什么
console.log(error);
return Promise.reject(error);
}
);
}
实现效果
这里我只用了5篇博客做了个示范
 至此,使用node导出csdn博客的内容就实现完成
至此,使用node导出csdn博客的内容就实现完成
最后使用导出的md文件导入到自己的博客服务器吧
写在最后
脚本+Jenkins+hexo完整版:blog_website: 基于 node 编写的CSDN博客导出的爬虫脚本+hexo部署
感谢你看到这里,如果文章对你有帮助,请三连支持一下,你的支持是作者创作的动力

 浙公网安备 33010602011771号
浙公网安备 33010602011771号