B+树索引
数据源
/* Navicat MySQL Data Transfer Source Server : localHost Source Server Version : 50726 Source Host : localhost:3306 Source Database : liusongtest Target Server Type : MYSQL Target Server Version : 50726 File Encoding : 65001 Date: 2020-12-29 15:55:23 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for t1 -- ---------------------------- DROP TABLE IF EXISTS `t1`; CREATE TABLE `t1` ( `a` int(11) NOT NULL, `b` int(11) DEFAULT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, `e` varchar(20) COLLATE utf8_unicode_ci DEFAULT NULL, PRIMARY KEY (`a`), KEY `idx_t1_bcd` (`b`,`c`,`d`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci; -- ---------------------------- -- Records of t1 -- ---------------------------- INSERT INTO `t1` VALUES ('1', '1', '1', '1', 'a'); INSERT INTO `t1` VALUES ('2', '2', '2', '2', 'b'); INSERT INTO `t1` VALUES ('3', '3', '2', '2', 'c'); INSERT INTO `t1` VALUES ('4', '3', '1', '1', 'd'); INSERT INTO `t1` VALUES ('5', '2', '3', '5', 'e'); INSERT INTO `t1` VALUES ('6', '6', '4', '4', 'f'); INSERT INTO `t1` VALUES ('7', '4', '5', '5', 'g'); INSERT INTO `t1` VALUES ('8', '8', '8', '8', 'h');
索引的代价
- 空间上的代价
一个索引对应一棵B+树,树中每个节点都是一个数据页,一个页默认都会占用16kb的存储空间,所以一个索引也是会占用磁盘空间。
- 时间上的代价
索引是对数据的排序,那么对表中的数据都要进行增、删、改操作时,都需要去维护内容涉及到的B+树索引。所以进行增、删、该操作时可能需要额外的时间进行一些记录移动,页面分裂,页面回收等操作来维护好排序。
索引实例
- 创建聚集索引
create index idx_t1_bcd on t1(b, c, d);
- 全局匹配
查询优化器会分析这些查询条件,并且按照可以使用的索引列中的列顺序来决定先使用哪个查询条件
explain select * from t1 where b=1 and c=1 and d=1;

- 匹配左边的列
explain select*from t1 where b=1and c=1;

下面这个sql就用不到索引
select * from t1 where c=1;

- 匹配列前缀
explain select * from t1 where b like '%101%';
这种用不到索引,因为字符串中间有‘101’的字符串没有排好序,所以只能全表扫描了。

- 匹配范围值
explain select * from t1 where b>1 and b<20000;
查询过程
a. 找到b值为1的记录
b. 找到b值为20000的记录
c. 由于所有记录都是由链表连起来的(记录之间用单链表、数据页之间用双链表),所以他们之间记录都可以很容易的取出来。
d. 找到这些记录的主键值,再到聚簇索引中回表查找完整的记录。
这里出现这个是因为他的范围划的太大了,就和全表扫描一个意思,所以才会出现type=all

如果改成:explain select * from t1 where b>3 and b<20000; 这样又去筛选索引了。sql优化器会自主判断

- 精确匹配某-列并范围匹配另外一列.
对于同一个联合索引来说,虽然对多个列都进行范围查找时只能用到最左边那个索弓列,但是如果左边的列是精确查找,则右边的列可以进行范围查找,比方说这样:
explain select * from t1 where b=1 and c>1;
- 排序
先按照b,如果b相同,就按照c,如果c相同,就按照d排序。
explain select * from t1 order by b, c, d;
- 分组
这个查询语句相当于做了三次分组操作:
a. 先按b分组,值集中b
b. b中再按照c进行分组,将title值相同的记录放一个组
c. 再按照上一步产生的分组,分成更小的d组
explain select b, c, d count(*) from t1 group by b, c, d;
注意事项
1、order by的子句后面的列的顺序必须按照索引列的顺序给出,如果给出的order by c, b,d;这样的乱序,就用不了b+树
2、order b,order by b,c这种可以使用部分索引
3、左边为常量也可以使用后边的列进行排序
explain select * from t1 where b=1 order by c, d;
不可以使用索引进行排序或分组的几种情况
ASC、DESC混用
select * from t1 order by b asc, c desc;
索引总结
1、索引列的类型尽量小
2、利用索引字符串值的前缀
3、主键自增
4、定位并删除表中的重复和冗余索引
5、尽量使用覆盖索引进行查询,避免会标带来的性能损耗
B+树总结
1. 每个索引都对应一棵B+树。用户记录(数据库表中的数据)都存储在B+树的叶子节点,所有目录记录都存储在非叶子节点。
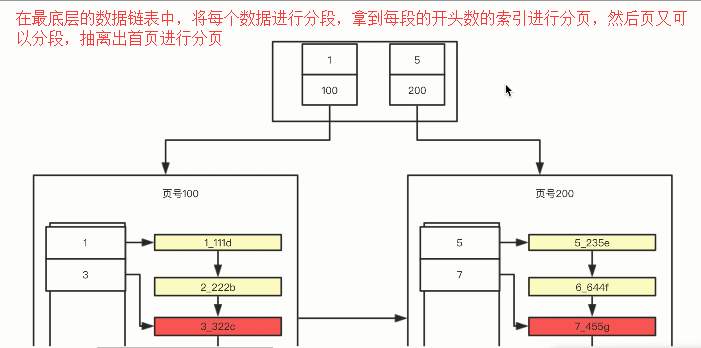
2. InnoDB存储引擎会自动为主键(如果没有它会自动帮我们添加)建立聚簇索引,聚簇索引的叶子节点包
含完整的用户记录。
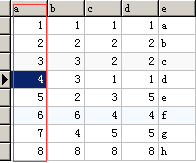
插入数据库后的数据主键是有序递增的
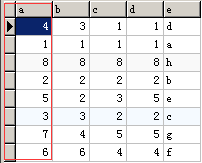
MyISAM存储引擎就是按照一条条数据,按照原始的数据顺序进行插入的。主键没有进行排序
3. 可以为指定的列建立二级索引,二级索引的叶子节点包含的用户记录由索引列 + 主键组成,所以如果想
通过二级索引来查找完整的用户记录的话,需要通过回表操作,也就是在通过二级索引找到主键值之后再
到聚簇索引中查找完整的用户记录。
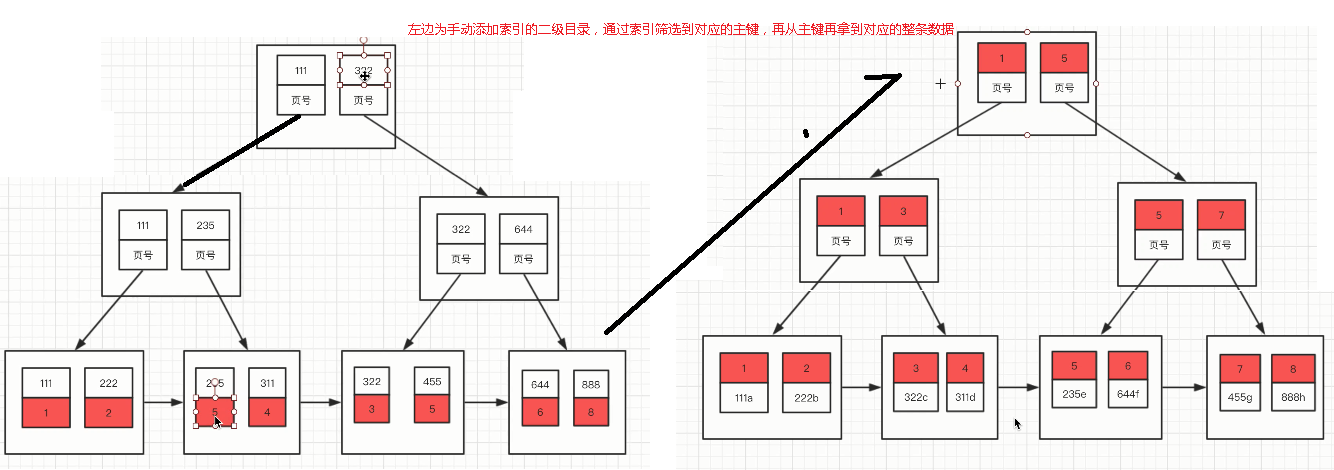
4. B+树中每层节点都是按照索引列值从小到大的顺序排序而组成了双向链表,而且每个页内的记录(不论
是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单链表。如果是联合索引
的话,则页面和记录先按照联合索引前边的列排序,如果该列值相同,再按照联合索引后边的列排序。
5. 通过索引查找记录是从B+树的根节点开始,一层一层向下搜索。由于每个页面都按照索引列的值建立了
页目录,所以在这些页面中的查找非常快

 浙公网安备 33010602011771号
浙公网安备 33010602011771号