0 开篇
(1)文件储存的基本单位是什么?
字节(1字节=8位)
(2)DOC、LZH和TXT这些扩展名中,哪一个是压缩文件的扩展名?
LZH (LZH是用LHA等工具压缩过的文件的扩展名)
(3)文件内容用“数据的值*循环次数”来表示的压缩方法时RLE算法还是哈夫曼算法?
RLE算法
(4)在Windows计算机经常使用的SHIFT JIS字符编码中,1个半角英数是用几个字节的数据来表示的?
1字节=8位
(5)BMP(BITMAP)格式的图像文件,是压缩过的吗?
没有压缩
(6)可逆压缩和非可逆压缩的不同点是什么?
压缩后的数据能复原的是可逆压缩,无法复原的是非可逆压缩。
1 文件以字节位单位保存
文件是将数据存储在磁盘等存储媒介中的一种形式。程序文件中存储数据的单位是字节。文件的大小之所以用xxKB、xxMB等来表示,就是因为文件是以字节(B=Byte)为单位来存储的。
文件就是字节数据的集合。用1字节(=8位)表示的字节数据有256种,用二进制数来表示的话,其范围就是00000000~11111111.如果文件中存储的数据时文字,那么该文件就是文本文件。如果是图形,那么该文件就是图像文件。在任何情况下,文件中的字节数据都是连续存储的。
2 RLE算法的机制
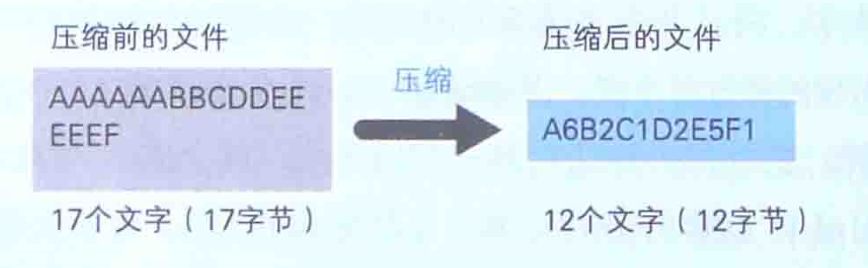
以示例来描述一下这个压缩机制:AAAAAABBCDDEEEEEF
由于半角字母中,1个字符是作为1个字节的数据被保存在文件中的。因此上述的文件大小就是17字节。好,那我们现在开始以“
字符*重复次数”这样的表现方式来压缩。上述文件内容就变为A6B2C1D2E5F1来表示,这样只剩12字节,因此结果就将原文件压缩了12字节/17字节=70% 。
上述的压缩方法称为RLE(Run Length Encoding,行程长度编码)算法。RLE算法是一种很好的压缩算法,经常被用于压缩传真的图像等。因为图像文件本质上也是字节数据的集合体。
3 RLE算法的缺点
然而,在实际的文本中,同样字符多次重复出现的情况并不多见。虽然针对相同数据经常连续出现的图像、文件等,RLE算法可以发挥不错的效果,但它并不适合文本文件的压缩。不过,因为该压缩机制非常简单,因此使用RLE算法的程序也相对更容易编写。
好,现在就来看一个反例:This is a pen.
这个文本采用RLE算法对其进行压缩后,就变成了T1h1i1s1 1i1s1 1a1p1e1n1.1,这样28个字符,是压缩前的2倍。由于文章中字符大量连续出现的情况并不多见,因此,使用RLE算法后,大部分字符后面都会加上1,这样一来,压缩后的文件自然变成了之前的2倍。
4 通过莫尔斯编码来看哈夫曼算法的基础
哈夫曼算法是哈夫曼于1952年提出来的压缩算法。
为了更好地理解哈夫曼算法,首先大家要抛弃掉“半角英文数字的1个字节是1个字节(8位)的数据”这个概念。文本文件是由不同类型的字符组合而成的,而且不同的字符出现的次数也是不同的。例如,在某一个文本文件中,A出现了100次左右,Q仅用到了3次,类似这样的情况是很常见的。而哈夫曼算法的关键就在于“多次出现的数据用小于8位的字节数来表示,不常用的数据则可以用超过8位的字节数来表示”。A和Q都用8位来表示时,原文件的大小就是100*8+3*8=824位,而假设A用2位,Q用10位来表示,压缩后的大小就是100*2+3*10=230位。
不过有一点需要注意,不管是不满8位的数据,还是超过8位的数据,最终都要以8位为单位保存到文件中。这时因为磁盘是以字节(8位)为单位来保存数据的。
为了更好地理解哈夫曼算法,先来看一下莫尔斯编码。莫尔斯编码不是通过语言,而是通过“嗒 嘀 嗒 嘀”这些长点和短点的组合来传递文本信息的。
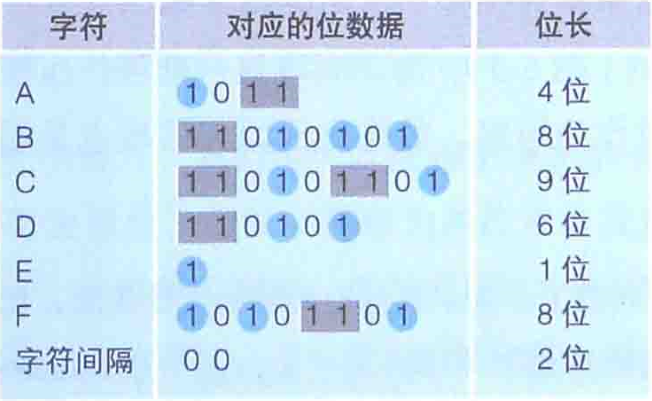
莫尔斯编码把一般文本中出现频率高的字符用短编码来表示。这里所说的出现频率,不是通过对出版物等文章进行统计调查得来的,而是根据印刷行业的印刷活字数目而确定的。如上表所示,假设表示短点的位是1,表示长点的位时11的话,那么E(嘀)这一字符的数据就可以用1位的1来表示,C(嗒嘀嗒嘀)这一字符的数据就可以用9位的110101101来表示。在实际的莫尔斯编码中。如果短点的长度是1,长点的长度就是3,短点和长点的间隔就是1.这里的长度指的是声音的长度。接下来,就让我们尝试一下用莫尔斯编码来表示前面提到的AAAAAABBCDDEEEEEF这个17个字符的文本。在莫尔斯编码中,各个字符之间需要加入表示间隔的符号。这里我们用00来进行区分。因此,就编程了A*6+B*2+C*1+D*2+E*5+F*1+字符间隔*16=4*6+8*2+9*1+6*2+1*5+8*1+2*16=106位=14字节。因为文件只能以字节位单位来存储数据,因此不满1字节的部分就要圆整成1个字节。如果所有字符占用的空间都是1个字节(8位),这样文本中列出来的17个字符=17字节,那么摩尔斯电码的压缩比率就是14/17=82%。
5 用二叉树实现哈夫曼编码
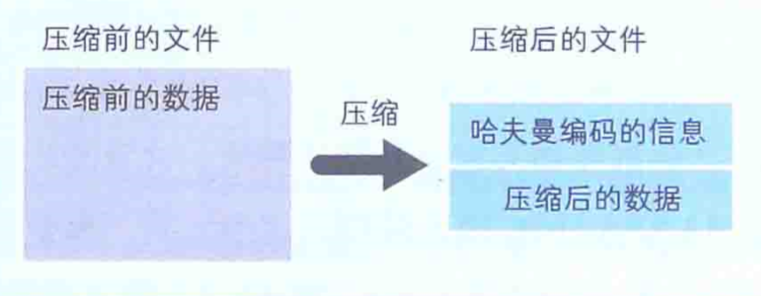
哈夫曼算法是指,为各压缩对象文件分别构造最佳的编码体系,并以该编码体系为基础来进行压缩。因此,用什么样式的编码(哈夫曼编码)对数据进行分割,就要由各个文件而定。用哈夫曼算法压缩过的文件中,存储着哈夫曼编码信息和压缩过的数据,如下图:
接下来,我们尝试一下把AAAAAABBCDDEEEEEF这些字符按照“出现频率高的字符用尽量少的位数编码来表示”这一原则进行整理。我们假定用下面的方案:

在上述的方案中,随着出现频率的降低,字符编码信息的数据位数也在逐渐增加,从开始的1位、2位依次增加到3位。不过这个编码体系是存在问题的,假设100这个3位的编码,它的意思是用1、0、0这3个编码来表示E、A、A呢?还是用10、0这两个编码来表示B、A呢?亦或是用100来表示C呢?这些都无法进行区分。因此,如果不加入用来区分字符的符号,这个编码就无法使用。
而在哈夫曼算法中,通过借助哈夫曼树构造编码体系,即使在不使用字符区分符号的情况下,也可以构建能够明确进行区分的编码体系。接下来我们就看一下如何制作哈夫曼树。




6 哈夫曼算法能够大幅提升压缩比率
使用哈夫曼树后,出现频率越高的数据所占用的数据位数就越少,而且数据的区分也可以很清晰地实现。
通过上一小节的介绍可以发现,在用枝条连接数据时,我们是从出现频率较低的数据开始的,这就意味着出现频率越低的数据到达根部的枝条数就越多,而枝条数越多,编码的位数也就随之增多了。从用哈夫曼算法压缩过的文件中读取数据后,就会以位为单位对该数据进行排查,并与哈夫曼树进行比较看是否到达了目标编码,这就是为什么哈夫曼算法可以对数据进行区分的原因。例如,10001这个使用上图所示的哈夫曼编码作成的5位数据,到达100时,对照哈夫曼树的数据,该数据表示的是B这个字符。好,介绍了这么多,让我们可以来看看哈夫曼算法的压缩比率:
用哈夫曼编码表示AAAAAABBCDDEEEEEF:0000000000001001001101011010101010101111,40位,压缩前位17字节,目前只需要5个字节,当然,这里不包括哈夫曼编码信息的情况。但这个也实现了很高的压缩比率了。
7 可逆压缩和非可逆压缩
Windows的标准图像数据形式为BMP,是完全未压缩的。除此之外,还有其他各种格式的图像数据形式。比如JPEG、TIFF、GIF格式等。与BMP格式不同的是,这些图像数据都会用一些技法来对数据进行压缩。
在大多数情况下,并不要求压缩后的图像文件必须还原到与压缩前同等的质量。与之相比,程序的EXE文件以及每个字符、数值都具有具体含义的文本文件则必须要还原到和压缩前同样的内容。而对于图像文件来说,即使有时无法还原到压缩前那样鲜明的图像状态,但只要肉眼看不出什么区别,有一些模糊也勉强可以接受。这里,我们把能还原到压缩前状态的压缩称为可逆压缩,无法还原到压缩前状态的压缩称为非可逆压缩。
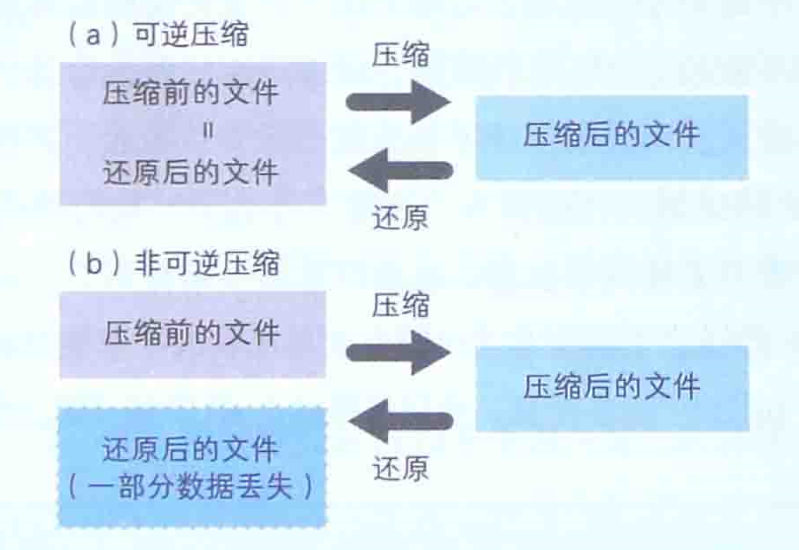
JPEG格式和GIF格式的图像文件有一些模糊,是因为他们是非可逆压缩,因此还原后会有一些模糊。而GIF格式的文件虽然是可逆压缩,但因为有色数不能超过256色的限制,所以还原后颜色信息会有一些缺失,进而导致了图像模糊。TIFF格式的图像文件虽然不模糊,但却比原始的BMP格式文件还要大,因为TIFF格式的文件中带有各种标签信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号