如何设计一个关系型数据库
如何设计一个关系型数据库
索引模块
为什么要使用索引
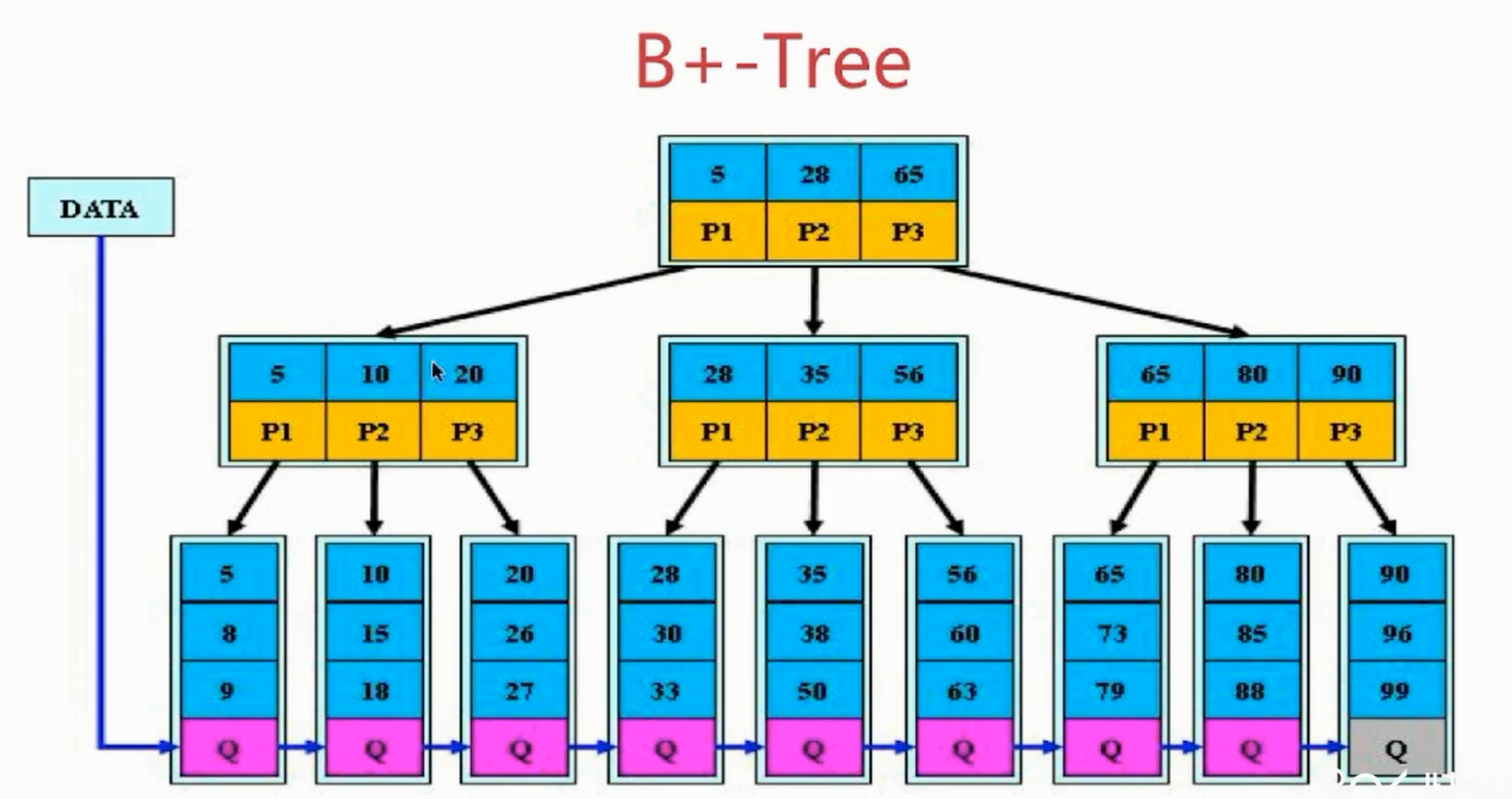
B+Tree

- 非叶子节点的字数指针与关键字的个数相同
- 非叶子节点的字数指针P[i],指向关键字值[K[i],K[i+1]]的子树
- 非叶子节点仅用来索引,数据保存在叶子节点中
- 所有叶子节点均有一个链指针指向下一个叶子节点(方便做索引)
结论
B+Tree更加适合用来做存储索引
- B+树的磁盘读写代价更低
- B+树的查询效率更加稳定
- B+树更有利于对数据库的扫描
Hash索引

buckets是桶
缺点
- 仅仅满足“=”,“IN”,不能用于范围查询
- 无法被用来避免数据的排序操作(hashcode是经过hash函数后得出的)
- 不能利用部分索引键查询
- 不能避免表扫描
- 遇到大量Hash相等的情况下不能比B-Tree的索引高
entries在Java中实现有红黑树和普通数组两种形式
BitMap索引
密集索引和稀疏索引的区别
- 密集索引文件中的每个搜索码都对应一个索引值
- 稀疏索引文件只为索引码的某些值创建索引项

InnoDB
- 若一个主键被定义,则该主键被作为密集索引
- 若没有主键被定义,该表的第一个唯一非空索引则作为密集索引
- 若不满足以上条件,innodb内部会自动生成一个隐藏主键(密集索引)
- 非主键索引存储相关键位和其对应的主键值,包含两次查找
![1549778755317].\mg\1549778755317.png)
如何定位并优化慢查询sql
如何优化mysql查询的查询效率
show variables like '%quer%';
show status like '%slow_queries%';
-- 设置
set global slow_query_log=on;
-- 修改最长查询时间
set global long_query_time = 1;
-- 查询
select name from person_info_large order by name desc;
Explain关键字段
type
index:为带有索引的扫描方式
all:为全表扫描的方式
排序的耗时从低到高的顺序:index>all
extra

联合索引的最左匹配原则的成因

Mysql创建联合索引(Union Index)时会以Order By A,Order By B的顺序,对于A来说所有data rows 都是有序的,但是对于B来说却不一定。所以必须准许最左匹配原则
对于联合索引(a,b,c,d)来说,在Mysql解析到(<,>,between and ,like)等范围查询语句后,如果后方还有列需要查询会放弃索引查询,例如a=1,b=2,c>3,d=5就不会采用索引的方式查询如果改为a=1,b=2,d=5,c>3就会采用索引,对于第一种情况Mysql的查询解析器会自动优化,也就是说abc是可以乱序的
缓存模块
MyISAM和InnoDB
- InnoDB默认为行级锁,支持表级
- MyISAM默认是表级,不支持行级锁
MyISAM适合的场景
- 频繁执行全表
count语句 - 对数据进行增删改的频率不高,查询很频繁的(这是因为读写锁的原因造成的,读锁是共享的
S锁,写锁是互斥的X锁) - 没有事务
InnoDB适合的场景
- 数据增删改查都非常频繁
- 可靠性高可以支持事务
数据库的锁分类
- 按锁的粒度划分,可分为表级锁、行级锁、叶级锁
- 按锁级别划分,可分为共享锁S、排它锁X
- 按加锁方式划分,可分为自动锁、显示锁
- 按操作划分,可划分为DML锁、DDL锁
- 按使用方式划分,可分为乐观锁(使用时间戳或者序列化号)、悲观锁
数据库事务的四大特性 ACID
- 原子性(Atomic):事务包含的操作要么全部完成要么不做
- 一致性(Consistency):事务必须使数据库从一个一致性状态变化到另一个一致性状态
- 隔离性(Isolation):一个事务的执行不能被其他事务干扰,多个事务的并发执行是不会相互干扰。
- 持久性(Durability):已提交事务对数据库的修改是永久存在的
数据库定义的错误类型
1、脏读
脏读是指在事务处理过程中读取了另一个未提交事务的数据。
当一个事务正在多次修改某个数据,而这个事务的多次修改均为提交,这时一个并发的事务访问该数据,就会造成两个事务获取的数据不一致。
2、不可重复读
不可重复读是指对于数据库的某个数据,一个事务范围内多次查询却返回了不同的值。
例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且事务提交给数据库,事务T1再次读取这个数据发现数据与之前的数据不相同,发生脏读。
3、幻读(虚读)
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中的所有行的某个数据项做了从“1”修改到“2”的操作,这是事务T2对表中插入一个数据项“1”,T1查看刚刚修改的数据,会发现还有一行没有修改,其实是T2添加进来的,就好像发生了幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交了的事务,所不同的是脏读针对的是对一个数据项(的观察),而幻读是对一批数据整体(比如数据个数)。
MySql数据库隔离级别
- Serializable(串行化):可避免脏读、不可重复读、幻读
- Repeatable Read (可重复读 MySQL默认级别):可避免脏读、不可重复读
- Read Committed (读已提交):可避免脏读
- Read Uncommitted (读未提交):最低级别,任何情况都不能保证
语法部分
Group By
- 满足“select字句中的列名必须为分组列或列函数“
- 列函数每组返回一个值
JVM
ClassLoader类型
- BootstrapClassLoader 系统类加载器:C++编写,加载
java.*,负责加载放在<JAVA_HOME>\lib目录中的,被-Xbootclasspath参数所指定的路径中,并且是虚拟机表示的类库,用户无法直接使用; - ExtClassLoader 拓展类加载器:Java编写,加载
javax.*,该类加载器由sun.misc.Launcher$AppClassLoader实现。负责加载<JAVA_HOME>\lib\ext目录中的,或者被java.ext.dirs系统变量中指定的目录的所有类库,用户可以直接使用; - AppClassLoader 用户类加载器:加载程序所在目录;
- 用户自定义类加载器:加载用户指定的目录;
Class.forName()和ClassLoader.loadClass();
主要区别在于是否进行链接(Java装入类中的一步)
Class.loadClass(className,false);
public static Class<?> forName(String name, boolean initialize,
ClassLoader loader)
throws ClassNotFoundException
Class.forName(className)方法,内部实际调用的方法是 Class.forName(className,true,classloader);
第2个boolean参数表示类是否需要初始化, Class.forName(className)默认是需要初始化。
一旦初始化,就会触发目标对象的 static块代码执行,static参数也也会被再次初始化。
ClassLoader.loadClass(className)方法,内部实际调用的方法是 ClassLoader.loadClass(className,false);
第2个 boolean参数,表示目标对象是否进行链接,false表示不进行链接,由上面介绍可以,
不进行链接意味着不进行包括初始化等一些列步骤,那么静态块和静态对象就不会得到执行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号